Unity Catalog のモデルの例
この例では、Unity Catalog のモデルを使用し、風力発電所の毎日の電力出力を予測する機械学習アプリケーションをビルドする方法を示します。 この例では、次のことを行っています。
- MLflow によるモデルの追跡とログ記録
- Unity Catalog にモデルを登録する
- モデルについて説明し、エイリアスを使用した推論のためにモデルをデプロイする
- 登録済みモデルと運用アプリケーションの統合
- Unity Catalog でモデルを検索して見つける
- モデルのアーカイブと削除
この記事では、MLflow Tracking と Unity Catalog のモデルの UI と API を使用し、これらの手順を実行する方法について説明します。
必要条件
[要件] のすべての要件を満たしていることを確認します。 さらに、この記事のコード例では、次の特権があることを前提としています。
mainカタログのUSE CATALOG特権。main.defaultスキーマのCREATE MODEL特権とUSE SCHEMA特権。
ノートブック
この記事のすべてのコードは、次のノートブックで提供されています。
「Unity Catalog のモデルの例」ノートブック
MLflow Python クライアントをインストールする
この例では、MLflow Python クライアント バージョン 2.5.0 以降と TensorFlow が必要です。 ノートブックの先頭に次のコマンドを追加し、これらの依存関係をインストールします。
%pip install --upgrade "mlflow-skinny[databricks]>=2.5.0" tensorflow
dbutils.library.restartPython()
データセットの読み込み、モデルのトレーニング、Unity Catalog への登録
このセクションでは、風力発電所のデータセットを読み込み、モデルをトレーニングし、Unity Catalog にモデルを登録する方法を示します。 モデルのトレーニング実行とメトリクスは実験実行で追跡されます。
データセットを読み込む
次のコードは、気象データと米国内の風力発電所の電力出力情報を含むデータセットをロードします。 このデータセットには、6 時間ごと (00:00 に 1 回、08:00 に 1 回、16:00 に 1 回) にサンプリングされる wind direction、wind speed、air temperature の各特徴と、数年間にわたる 1 日の合計電力出力 (power) が含まれます。
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Unity Catalog のモデルにアクセスするように MLflow クライアントを構成する
既定では、MLflow Python クライアントにより、Azure Databricks でワークスペース モデル レジストリにモデルが作成されます。 Unity Catalog のモデルにアップグレードするには、Unity Catalog のモデルにアクセスするようにクライアントを構成します。
import mlflow
mlflow.set_registry_uri("databricks-uc")
モデルのトレーニングと登録
次のコードでは、TensorFlow Keras を使用してニューラル ネットワークをトレーニングし、データセット内の気象特徴に基づいて電力出力を予測し、MLflow API を使用して適合モデルを Unity Catalog に登録します。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
MODEL_NAME = "main.default.wind_forecasting"
def train_and_register_keras_model(X, y):
with mlflow.start_run():
model = Sequential()
model.add(Dense(100, input_shape=(X.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X, y, epochs=100, batch_size=64, validation_split=.2)
example_input = X[:10].to_numpy()
mlflow.tensorflow.log_model(
model,
artifact_path="model",
input_example=example_input,
registered_model_name=MODEL_NAME
)
return model
X_train, y_train = get_training_data()
model = train_and_register_keras_model(X_train, y_train)
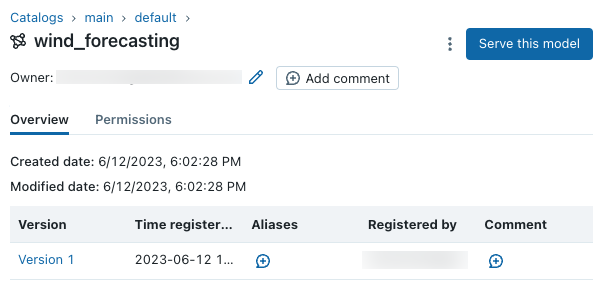
UI でモデルを表示する
Catalog Explorer を使用して、Unity Catalog の登録済みモデルとモデル バージョンを表示および管理できます。 作成したばかりのモデルを main カタログと default スキーマの下で探します。
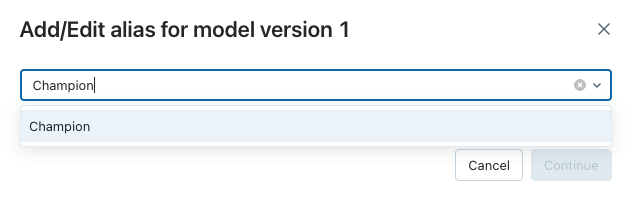
推論のためにモデル バージョンをデプロイする
Unity Catalog のモデルでは、モデル デプロイの エイリアスがサポートされています。 エイリアスは、登録されているモデルの特定のバージョンに、変更可能な名前付き参照 (たとえば、"Champion" や "Challenger") を提供します。 ダウンストリーム推論ワークフローでこのようなエイリアスを利用し、モデル バージョンを参照したり、ターゲットにしたりできます。
データ エクスプローラーで登録済みのモデルまで移動したら、[エイリアス] 列の下を選択し、"Champion" エイリアスを最新バージョンのモデルに割り当て、[続行] を押して変更を保存してください。
API を使用したモデル バージョンの読み込み
MLflow モデル コンポーネントでは、複数の機械学習フレームワークからモデルを読み込むための関数が定義されています。 たとえば、MLflow 形式で保存された TensorFlow モデルを読み込むには、mlflow.tensorflow.load_model() を使用します。また、MLflow 形式で保存された scikit-learn モデルを読み込むには、mlflow.sklearn.load_model() を使用します。
これらの関数では、Unity Catalog モデルからモデルを読み込むことができます。
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_champion_uri = "models:/{model_name}@Champion".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_champion_uri))
champion_model = mlflow.pyfunc.load_model(model_champion_uri)
チャンピオン モデルで電力出力を予測する
このセクションでは、チャンピオン モデルを使用し、風力発電所の天気予報データを評価します。 forecast_power() アプリケーションでは、指定されたステージから予測モデルの最新バージョンを読み込み、それを使用して、今後 5 日間の電力生産を予測します。
from mlflow.tracking import MlflowClient
def plot(model_name, model_alias, model_version, power_predictions, past_power_output):
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nwith alias '%s' (Version %d)" % (model_name, model_alias, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_alias):
import pandas as pd
client = MlflowClient()
model_version = client.get_model_version_by_alias(model_name, model_alias).version
model_uri = "models:/{model_name}@{model_alias}".format(model_name=MODEL_NAME, model_alias=model_alias)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_alias, int(model_version), power_predictions, past_power_output)
forecast_power(MODEL_NAME, "Champion")
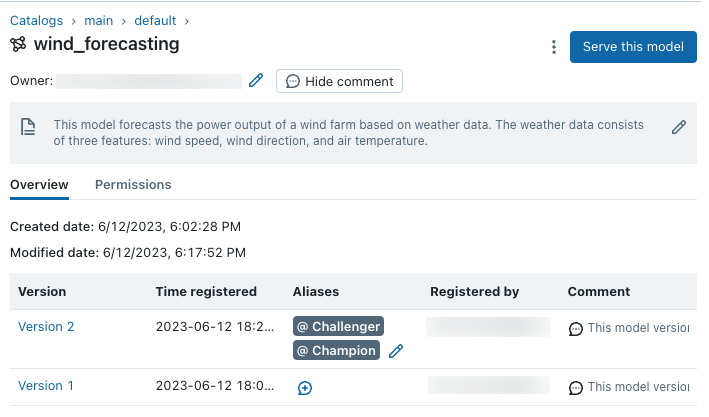
API を使用してモデルとモデル バージョンの説明を追加する
このセクションのコードは、MLflow API を使用してモデルとモデルのバージョンの説明を追加する方法を示しています。
client = MlflowClient()
client.update_registered_model(
name=MODEL_NAME,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=MODEL_NAME,
version=1,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
新しいモデル バージョンを作成する
従来の機械学習手法は、電力予測にも有効です。 次のコードでは、scikit-learn を使用してランダム フォレスト モデルをトレーニングし、mlflow.sklearn.log_model() 関数を使用して Unity Catalog にそれを登録します。
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
example_input = val_x.iloc[[0]]
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model to <UC>. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
input_example=example_input,
registered_model_name=MODEL_NAME
)
新しいモデルのバージョン番号を取得する
次のコードは、モデル名に対して最新のモデル バージョン番号を取得する方法を示しています。
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % MODEL_NAME)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
新しいモデル バージョンに説明を追加する
client.update_model_version(
name=MODEL_NAME,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
新しいモデル バージョンに Challenger のマークを付け、モデルをテストする
モデルをデプロイして運用環境トラフィックにサービスを提供する前に、運用環境データのサンプルでテストすることがベスト プラクティスになっています。 以前は、"Champion" エイリアスを使用し、運用環境ワークロードの大部分にサービスを提供するモデル バージョンを示しました。 次のコードでは、新しいモデル バージョンに "Challenger" エイリアスを割り当て、そのパフォーマンスを評価します。
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Challenger",
version=new_model_version
)
forecast_power(MODEL_NAME, "Challenger")
新しいモデル バージョンを Champion モデル バージョンとしてデプロイする
新しいモデル バージョンがテストでうまくいくことが確認されたら、次のコードにより、新しいモデル バージョンに “Champion” エイリアスが割り当てられ、「チャンピオン モデルを使用して電力出力を予測する」セクションとまったく同じアプリケーション コードを使用して電力が予測されます。
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Champion",
version=new_model_version
)
forecast_power(MODEL_NAME, "Champion")
これで予測モデルのモデル バージョンが 2 つになりました。Keras モデルでトレーニングされたバージョンと scikit-learn でトレーニングされたバージョンです。 “Challenger” エイリアスは新しい scikit-learn モデル バージョンに割り当てられままであり、“Challenger” モデル バージョンをターゲットにするダウンストリーム ワークロードは引き続き正常に実行されることにご留意ください。
モデルのアーカイブと削除
あるモデル バージョンが不要になったら、削除してもかまいません。 登録済みモデル全体を削除することもできます。その場合、関連付けられているすべてのモデル バージョンが削除されます。 モデル バージョンを削除すると、モデル バージョンに割り当てられているすべてのエイリアスが消去されることにご注意ください。
MLflow API を使用して Version 1 を削除する
client.delete_model_version(
name=MODEL_NAME,
version=1,
)
MLflow API を使用してモデルを削除する
client = MlflowClient()
client.delete_registered_model(name=MODEL_NAME)
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示