Azure Databricksはバイナリ ファイル データ ソースをサポートしています。バイナリ ファイルを読み取り、各ファイルを、ファイルの生のコンテンツとメタデータを含む 1 つのレコードに変換します。 これは、ダウンストリーム処理や ML 推論のために、画像、オーディオ、PDF ファイルなどの非構造化データを読み込むのに一般的に使用されます。 バイナリ ファイルを読み取る場合は、データ ソース format を binaryFile として指定します。
前提条件
Azure Databricksでは、バイナリ ファイルを使用するために追加の構成は必要ありません。
オプション
バイナリ ファイル データ ソースを構成するには、.option()の.options()メソッドとDataFrameReaderメソッドを使用します。 サポートされているオプションの完全な一覧については、 Spark API オプションのリファレンスを参照してください。
出力スキーマ
バイナリ ファイルのデータ ソースでは、次の列とパーティション列を含む DataFrame が生成されます。
-
path (StringType): ファイルのパス。 -
modificationTime (TimestampType): ファイルの変更時刻。 一部の Hadoop FileSystem 実装では、このパラメーターが使用できない可能性があり、値は既定値に設定されます。 -
length (LongType): ファイルの長さ (バイト単位)。 -
content (BinaryType): ファイルの内容。
Usage
次の例では、Spark DataFrame API と SQL を使用したバイナリ ファイルの読み込み、ファイルの種類によるフィルター処理、画像のプレビューの表示、および読み取りパフォーマンスを向上させるために Delta テーブルに保存する方法を示します。
バイナリ ファイルの読み取り
Apache Spark DataFrame API を使用して、変換、表示、またはダウンストリーム処理のためにバイナリ ファイルを DataFrame に読み込みます。
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
display(df)
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
df.show()
SQL
SELECT path, length, modificationTime FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
読み取りオプションを構成する
パーティション検出の動作を維持しながら、特定の glob パターンに一致するパスを持つファイルを読み込むには、pathGlobFilter オプションを使用できます。 次のコードは、パーティション検出を使用して入力ディレクトリからすべての JPG ファイルを読み取ります。
Python
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
Scala
val df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg'
)
パーティション検出を無視し、入力ディレクトリのファイルを再帰的に検索する場合は、recursiveFileLookup オプションを使用します。 このオプションでは、その名前が パーティションの命名規則(date=2019-07-01 など)に従っていなくても、入れ子になったディレクトリも検索対象に含めます。
次のコードは、入力ディレクトリからすべての JPG ファイルを再帰的に読み取り、パーティションの検出を無視します。
Python
df = (spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/"))
Scala
val df = spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg',
recursiveFileLookup => true
)
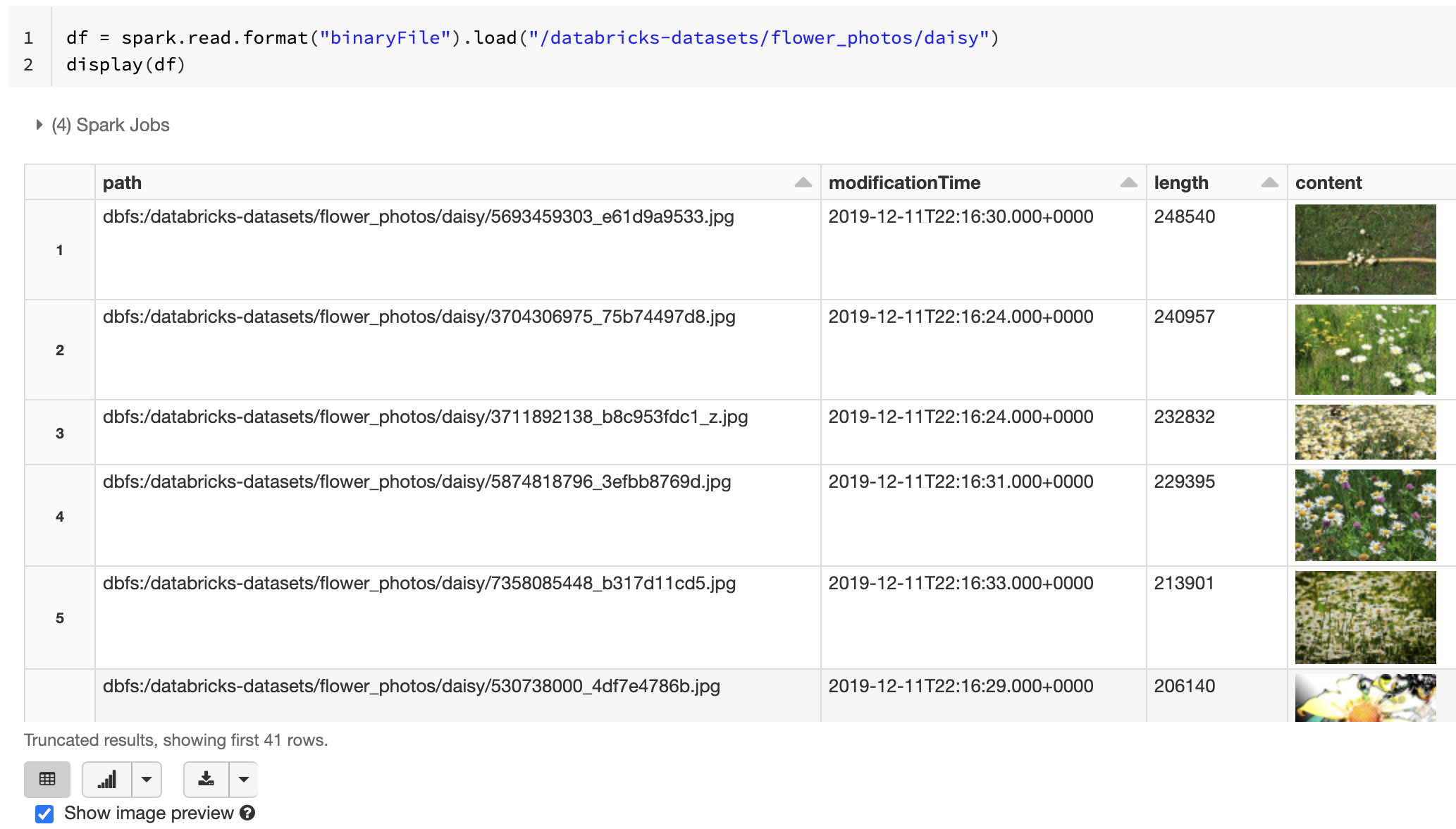
画像を読み込んで表示する
Databricks では、バイナリ ファイル データ ソースを使用して、画像データを読み込むことが推奨されています。 Databricks display 関数では、バイナリ データ ソースを使用して読み込まれた画像データの表示がサポートされています。
読み込まれたすべてのファイルに、画像の拡張子を持つファイル名がある場合、画像プレビューは自動的に有効になります。
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df) # image thumbnails are rendered in the "content" column
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
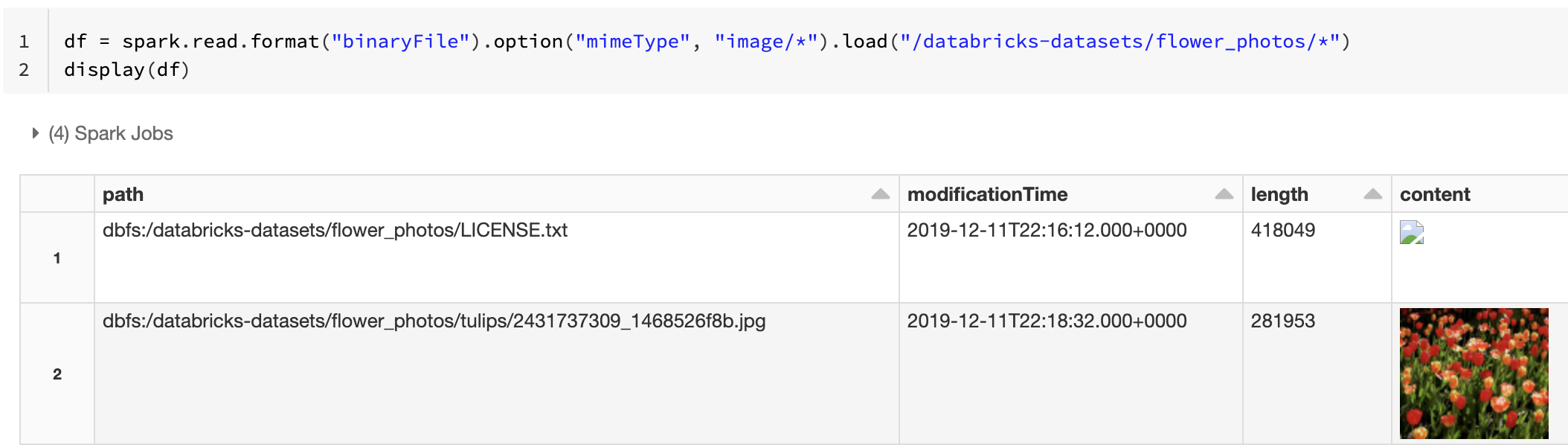
または、mimeType オプションと文字列値 "image/*" を使用してバイナリ列に注釈を付けることで、イメージ プレビュー機能を強制することもできます。 画像は、バイナリ コンテンツ内のフォーマット情報に基づいてデコードされます。 サポートされている画像の種類は bmp、gif、jpeg、および png です。 サポートされていないファイルは、壊れた画像アイコンとして表示されます。
Python
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df)
Scala
val df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
mimeType => 'image/*'
)
イメージ データを処理するために推奨されるワークフローについては、「イメージ アプリケーションのリファレンス ソリューション」を参照してください。
Delta テーブルに保存
データを読み込み戻すときの読み取りパフォーマンスを向上させるには、バイナリ ファイルから読み込まれたデータを Delta テーブルに保存することをお勧Azure Databricks。
Python
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Scala
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
その他のリソース
- イメージ ファイルの読み取り: ワークロードで生バイトではなく、高さ、幅、チャネル データなどの構造化されたイメージ フィールドが必要な場合、イメージ データ ソースはデコードされたスキーマを提供します。