Azure Databricks クラスターに対するリージョンのディザスター リカバリー
この記事では、Azure Databricks クラスターに適したディザスター リカバリー アーキテクチャと、その設計を実現する手順について説明します。
Azure Databricks のアーキテクチャ
Azure portal から Azure Databricks ワークスペースを作成すると、選択した Azure リージョン (たとえば、米国西部) に、ご利用のサブスクリプションの Azure リソースとしてマネージド アプリケーションがデプロイされます。 このアプライアンスは、ご利用のサブスクリプションで利用できる Azure Storage アカウントおよびネットワーク セキュリティ グループと共に Azure Virtual Network にデプロイされます。 この仮想ネットワークが Databricks ワークスペースに対する境界レベルのセキュリティを提供し、またネットワーク セキュリティ グループによって保護されることになります。 Databricks クラスターは、ワークスペース内でワーカーとドライバーの VM の種類、Databricks Runtime のバージョンを指定することによって作成できます。 永続化されたデータは、ストレージ アカウントで使用できます。 クラスターの作成後は、ノートブック、REST API、ODBC または JDBC のエンドポイントを特定のクラスターにアタッチすることにより、そのエンドポイントを介してジョブを実行することができます。
Databricks ワークスペース環境の管理と監視は、Databricks のコントロール プレーンで行います。 クラスターの作成をはじめとするすべての管理操作は、コントロール プレーンから開始されます。 スケジュールされたジョブなどのすべてのメタデータは、Azure Database に格納され、データベース バックアップは自動的にそれが実装されているペア リージョンに geo レプリケートされます。
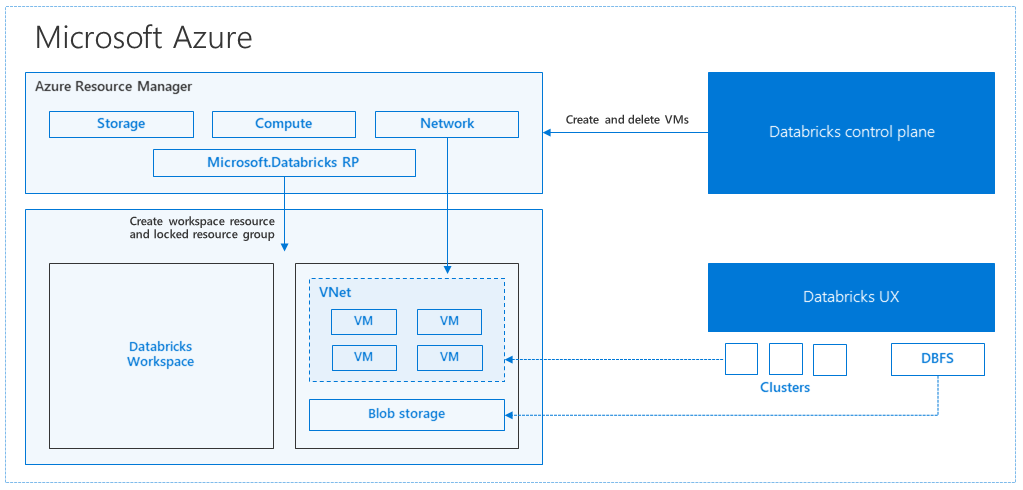
このアーキテクチャの利点の 1 つは、ユーザーがそのアカウントにある任意のストレージ リソースに Azure Databricks を接続できることです。 計算 (Azure Databricks) とストレージの両方を別々にスケーリングできることが主な利点となります。
リージョンのディザスター リカバリーのトポロジを作成する方法
前述したアーキテクチャの説明を見てもわかるように、Azure Databricks を使ったビッグ データ パイプラインには、Azure Storage、Azure Database などの各種データ ソースをはじめ、さまざまなコンポーネントが存在します。 Azure Databricks は、ビッグ データ パイプラインの "計算" をつかさどるコンポーネントです。 このコンポーネントは "一時性" を特徴としています。つまり、データはあくまで Azure Storage に格納されますが、不要なときには計算料金が課金されないよう、"計算" コンポーネント (Azure Databricks クラスター) を終了することができます。 ジョブの待ち時間が大きくならないよう、"計算" コンポーネント (Azure Databricks) とストレージ ソースは同じリージョン内に存在する必要があります。
リージョンのディザスター リカバリーのトポロジを独自に作成するには、次の要件を満たす必要があります。
複数の Azure Databricks ワークスペースは、別個の Azure リージョンにプロビジョニングします。 たとえば、米国東部にプライマリ Azure Databricks ワークスペースを作成します。 セカンダリ ディザスター リカバリー Azure Databricks ワークスペースは、別のリージョン (米国西部など) に作成する必要があります。 ペアになっている Azure リージョンの一覧については、「リージョン間レプリケーション」をご参照ください。 Azure Databricks リージョンについて詳しくは、「サポートされているリージョン」をご参照ください。
geo 冗長ストレージを使用します。 既定では、Azure Databricks に関連付けられているデータは Azure Storage に格納され、Databricks ジョブの結果は Azure Blob Storage に格納されます。そのため、処理済みのデータは永続的であり、クラスターが終了した後も高可用性が維持されます。 クラスター ストレージとジョブ ストレージは、同じ可用性ゾーンにあります。 リージョンの利用不可から保護するために、Azure Databricks ワークスペースでは既定で geo 冗長ストレージが使用されています。 geo 冗長ストレージでは、データは Azure ペア リージョンにレプリケートされます。 Databricks では、geo 冗長ストレージの既定値を維持することが推奨されますが、代わりにローカル冗長ストレージを使用する必要がある場合は、ワークスペースの ARM テンプレートで
storageAccountSkuNameをStandard_LRSに設定できます。セカンダリ リージョンの作成後、ユーザー、ユーザーのフォルダー、ノートブック、クラスター構成、ジョブ構成、ライブラリ、ストレージ、初期化スクリプトを移行し、アクセスの制御を再構成する必要があります。 その他詳しい情報については、次のセクションで取り上げます。
地域的な災害
それぞれの地域で発生する災害に備えるために、別の Azure Databricks ワークスペースのセットをセカンダリ リージョンに明示的に維持する必要があります。 「ディザスター リカバリー」を参照してください。
ディザスター リカバリーに推奨されるツールは、主に Terraform (インフラ レプリケーション用) と Delta Deep Clone (データ レプリケーション用) です。
詳細な移行手順
Databricks CLI をインストールする
この記事の例では、Azure Databricks REST API の使いやすいラッパーである Databricks コマンド ライン インターフェイス (CLI) を使用します。
移行手順を実施する前にローカル コンピューターまたは仮想マシンに Databricks CLI をインストールしてください。 詳しくは、「Databricks CLI のインストール」に関するページをご覧ください。
Note
この記事で提供されている Python スクリプトは、Python 2.7 以降で動作します。
2 つのプロファイルを構成する
_ の手順に従い、1 つはプライマリ ワークスペース用に、もう 1 つはセカンダリ ワークスペース用に 2 つのプロファイルを構成します。
databricks configure --profile primary databricks configure --profile secondary以降、この記事の各手順に出現するコード ブロックでは、対応するワークスペース コマンドを使ってプロファイルを切り替えます。 コード ブロックごとに、実際に作成するプロファイルの名前で置き換えてください。
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"必要であれば、コマンド ラインから手動で切り替えることもできます。
databricks workspace list --profile primary databricks workspace list --profile secondaryMicrosoft Entra ID (旧称 Azure Active Directory) のユーザーを移行する
プライマリ ワークスペースに存在するのと同じ Microsoft Entra ID (旧称 Azure Active Directory) ユーザーをセカンダリ ワークスペースに手動で追加します。
ユーザー フォルダーとノートブックを移行する
以下の Python コードを使用して、サンドボックス化されたユーザー環境を移行します。この環境に、ユーザーごとの入れ子になったフォルダー構造やノートブックが含まれます。
Note
この手順でライブラリはコピーされません。この操作は、基になる API でサポートされていません。
次の Python スクリプトをコピーしてファイルに保存し、コマンド ラインで実行します。 たとえば、
python scriptname.pyのようにします。import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "list", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")クラスターの構成を移行する
ノートブックの移行後、必要に応じてクラスターの構成を新しいワークスペースに移行することができます。 これは、選択的クラスター構成の移行を行う場合を 除き、Databricks CLI を使用してほぼ完全に自動化された手順です。
Note
クラスター構成の作成エンドポイントは存在しません。また、このスクリプトは、各クラスターを直ちに作成しようと試みます。 ご利用のサブスクリプションで使用できるコア数が不足していた場合、クラスターの作成に失敗します。 構成が正常に転送されれば、このエラーは無視してしてかまいません。
次に示したスクリプトは、以前のクラスター ID から新しいクラスター ID へのマッピングを出力します。このマッピングは、後からジョブ (既存のクラスターを使うように構成されたジョブ) の移行に使用します。
次の Python スクリプトをコピーしてファイルに保存し、コマンド ラインで実行します。 たとえば、
python scriptname.pyのようにします。import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")).splitlines() print("Printing Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append(cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")ジョブの構成を移行する
前の手順でクラスターの構成を移行した場合、必要であれば、ジョブの構成を新しいワークスペースに移行することができます。 これは、Databricks CLI を使用して完全に自動化された手順です。ただし、すべてのジョブに対して行うのではなく、選択的なジョブ構成の移行を行う場合を除きます。
Note
スケジュールされたジョブの構成には、"スケジュール" 情報も含まれています。そのため既定では、移行後すぐに、構成されているタイミングで動作が開始されます。 したがって、以前のワークスペースと新しいワークスペースが重複して実行されるのを防ぐため、次のコード ブロックでは、スケジュール情報を移行中にすべて削除しています。 そのようなジョブについては、切り替えの準備が完了した後で、スケジュールを構成してください。
ジョブの構成には、新しいクラスターまたは既存のクラスターの設定が必要です。 既存のクラスターが使用されている場合、以下のスクリプト/コードは、以前のクラスター ID を新しいクラスター ID に置き換えようと試みます。
以下の Python スクリプトをファイルにコピーして保存してください。
old_cluster_idとnew_cluster_idの値は、前の手順 (クラスターの移行) で得られた出力内容に置き換えてください。 たとえば、python scriptname.pyコマンド ラインで実行します。import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate " + str(job)) job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id " + str(job_req_settings_json['existing_cluster_id'])) continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")ライブラリを移行する
現在、ライブラリをワークスペース間で直接移行する方法はありません。 そうしたライブラリは、新しいワークスペースに手動で再インストールする必要があります。 これを自動化するには、Databricks CLI を使用してカスタム ライブラリをワークスペースにアップロードします。
Azure Blob Storage と Azure Data Lake Storage のマウントを移行する
Notebook ベースのソリューションを使って、Azure Blob Storage と Azure Data Lake Storage (Gen 2) のマウント ポイントをすべて手動で再マウントします。 プライマリ ワークスペースにはストレージ リソースがマウント済みかと思いますので、それをセカンダリ ワークスペースについても行う必要があります。 マウントのための外部 API は存在しません。
クラスター初期化スクリプトを移行する
すべてのクラスター初期化スクリプトは、Databricks CLI を使用して、以前のワークスペースから新しいワークスペースに移行できます。 まず、必要なスクリプトをローカル デスクトップまたは仮想マシンにコピーします。 次に、それらのスクリプトを新しいワークスペースに同じパスでコピーします。
Note
DBFS に格納されている初期化スクリプトがある場合は、最初にサポートされている場所に移行します。 _ を参照してください。
// Primary to local databricks fs cp dbfs:/Volumes/my_catalog/my_schema/my_volume/ ./old-ws-init-scripts --profile primary // Local to Secondary workspace databricks fs cp old-ws-init-scripts dbfs:/Volumes/my_catalog/my_schema/my_volume/ --profile secondaryアクセスの制御を手動で再構成して再適用する
既存のプライマリ ワークスペースが Premium または Enterprise レベル (SKU) を使用するように構成されている場合は、アクセスの制御も使用している可能性があります。
アクセスの制御を使用する場合は、リソース (ノートブック、クラスター、ジョブ、テーブル) にアクセスの制御を手動で再適用してください。
Azure エコシステムのディザスター リカバリー
他の Azure サービスを使用している場合は、それらのサービスにもディザスター リカバリーのベスト プラクティスを必ず実装してください。 たとえば、外部の Hive metastore インスタンスを使用する場合は、Azure SQL Database、Azure HDInsight、Azure Database for MySQL のいずれかまたはすべてのディザスター リカバリーを検討する必要があります。 ディザスター リカバリーの全般的な情報については、「Azure アプリケーションのディザスター リカバリー」を参照してください。
次の手順
詳しくは、Azure Databricks のドキュメントをご覧ください。