適用対象:![]() Databricks SQL
Databricks SQL![]() Databricks Runtime
Databricks Runtime
Azure Databricks では、複数のルールを使用してデータ型間の競合を解決します。
- 昇格 により、型がより広い型に安全に拡張されます。
- 暗黙的なダウンキャストでは 、型が絞り込まれます。 上位変換の逆です。
- 暗黙的なクロスキャストは 、型を別の型ファミリの型に変換します。
また、次の多くの型間で明示的にキャストすることもできます。
- cast 関数 はほとんどの型間でキャストされ、キャストできない場合はエラーを返します。
- try_cast関数はキャスト関数と同様に機能しますが、無効な値を渡すと NULL を返します。
- その他の組み込み関数は、指定された形式ディレクティブを使用して型間でキャストされます。
型の昇格
型の上位変換は、1 つの型を、元の型の可能な値がすべて含まれる、同じ型ファミリの別の型にキャストするプロセスです。
したがって、型の上位変換は安全な操作です。 たとえば、TINYINT の範囲は -128 から 127 です。 これの可能な値すべてを安全に、INTEGER に上位変換できます。
型の優先順位リスト
型の優先順位リストでは、特定のデータ型の値を暗黙的に別のデータ型に上位変換できるかどうかを定義します。
| データの種類 | 優先順位リスト (最も狭いものから最も広いものへ) |
|---|---|
| TINYINT | TINYINT -> SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| SMALLINT | SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| INT | INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| BIGINT | BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| DECIMAL | DECIMAL(10進数)-> FLOAT(浮動小数点)(1) -> DOUBLE(倍精度浮動小数点) |
| FLOAT | FLOAT (1) -> DOUBLE |
| DOUBLE | DOUBLE |
| DATE | 日付 -> タイムスタンプ |
| 時間 | TIME (4) |
| TIMESTAMP | TIMESTAMP |
| ARRAY | ARRAY (2) |
| BINARY | BINARY |
| BOOLEAN | BOOLEAN |
| INTERVAL | INTERVAL |
| 地理学 | 地理(任意) |
| 幾何学 | GEOMETRY(ANY) |
| MAP | MAP (2) |
| STRING | STRING |
| STRUCT | STRUCT (2) |
| VARIANT | VARIANT |
| OBJECT | OBJECT (3) |
(1)最も一般的でない型の解像度ではFLOATはスキップされ、精度が失われるのを防ぎます。
(2) 複合型の場合、優先順位ルールはそのコンポーネント要素に再帰的に適用されます。
(3)OBJECT は VARIANT内にのみ存在します。
(4)TIME(n) と TIME(m) の最も一般的でない型が TIME(max(n, m))。
TIME は、 TIMESTAMP またはその他の型には昇格しません。
文字列と NULL
STRING と型指定されていない NULL には特殊なルールが適用されます。
-
NULLは、他の任意の型に上位変換できます。 -
STRINGは、BIGINT、BINARY、BOOLEAN、DATE、DOUBLE、INTERVAL、TIME、およびTIMESTAMPに昇格できます。 実際の文字列値を最小共通型にキャストできない場合、Azure Databricks でランタイムエラーが発生します。INTERVALに上位変換する場合、文字列値は間隔の単位と一致している必要があります。
型の優先順位図
これは、型の優先順位リストと文字列と NULL のルールを組み合わせて、優先順位の階層をグラフィカルに示したものです。
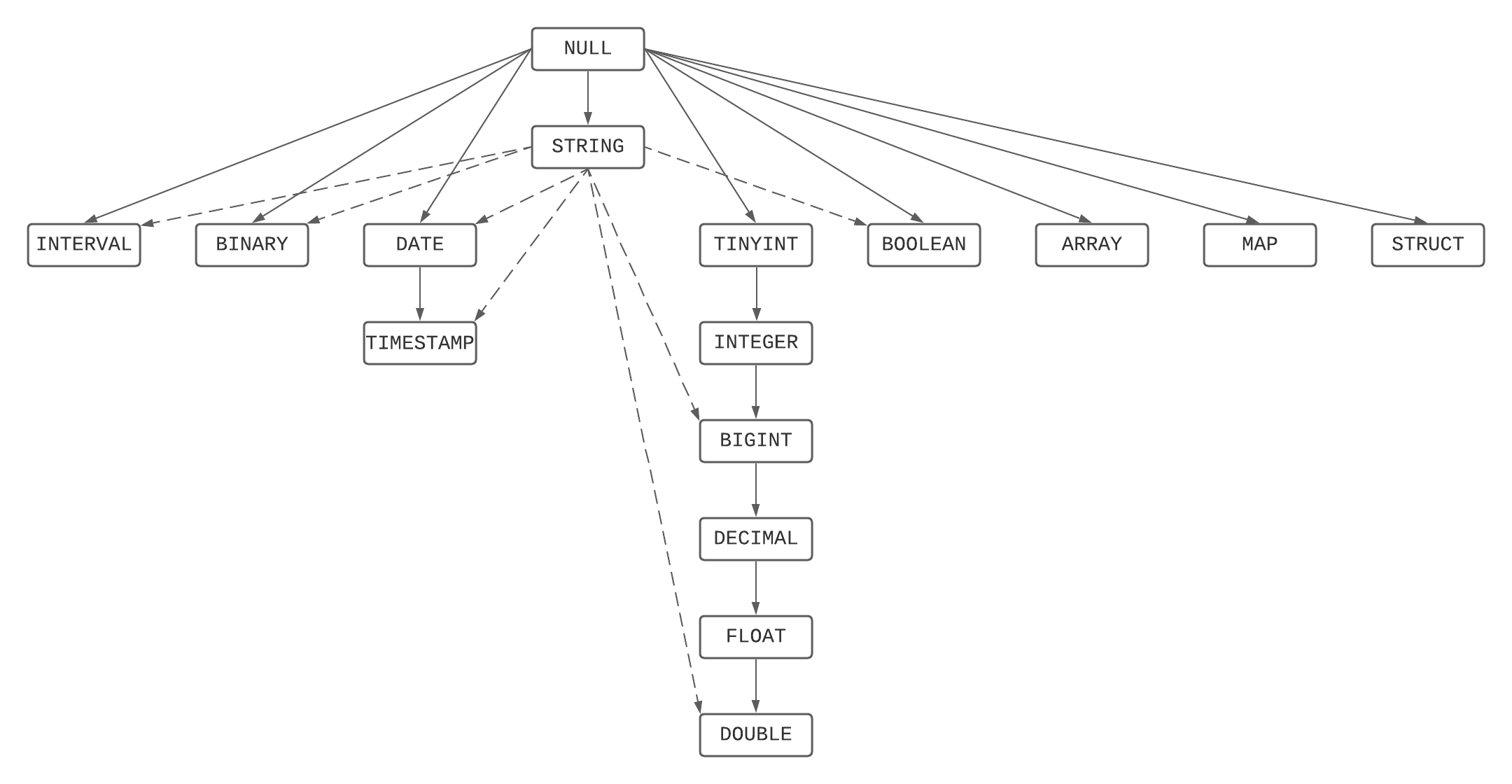
最小共通型の解決
一連の型のうちの最小共通型とは、型の優先順位図で、一連の型のすべての要素が到達できる最も狭い型です。
最も一般的でない型解決は、次の場合に使用します。
- ある型のパラメーターを必要としている関数を、より狭い型の引数を使用して呼び出すことができるかどうかを決定する。
- 関数coalesce、in、least、greatestのように、複数のパラメーターに対して共有される引数型を必要とする関数の引数型を導き出します。
- 算術演算や比較などの演算子のオペランド型を派生させます。
- case 式などの式から結果の型を導き出します。
- 配列コンストラクターとマップ コンストラクターの要素、キー、または値の型を派生させます。
- UNION、INTERSECT、EXCEPT のセット演算子の結果型を派生させる。
パラメーター化された型
一部のデータ型は、その精度またはスケールに影響を与えるパラメーターを持ちます。 最も一般的でない型にパラメーター化された型が含まれる場合、結果パラメーターが計算され、両方の入力型の値を損失なく表すことができます。
10進数(p, s)
DECIMAL(p1, s1)とDECIMAL(p2, s2)の最も一般的でない型は、スケールと精度が両方の型のすべての値に対応するDECIMALです。
resultScale = max(s1, s2)
maxIntegerDigits = max(p1 - s1, p2 - s2)
resultPrecision = min(38, resultScale + maxIntegerDigits)
resultScale + maxIntegerDigits
38 (最大 DECIMAL 精度) を超えた場合、有効桁数は38で制限され、小数点以下桁数は小さくなり、整数の数字が保持されます。
たとえば、DECIMAL(10, 2)とDECIMAL(12, 5)の最も一般的でない型はDECIMAL(15, 5)です。小数点以下桁数と整数max(2, 5) = 5桁数max(8, 7) = 813の有効桁数が必要であり、小数点以下 5 桁の有効桁数15保持するために8 + 5 = 13に拡大されます。
TIME(p)
TIME(n)とTIME(m)の最も一般的でない型はTIME(max(n, m))。
たとえば、最も一般的でない種類の TIME(0) と TIME(6) は TIME(6)。
その他の規則
最小共通型が FLOAT に解決される場合は、特殊なルールが適用されます。 寄与する型のいずれかが正確な数値型 (TINYINT、SMALLINT、INTEGER、BIGINT、または DECIMAL) であると、桁数が失われないように、最小共通型は DOUBLE にされます。
最も一般的でない型が STRING の場合、照合順序は照合順序優先順位ルールに従って計算されます。
暗黙的なダウンキャストとクロスキャスト
Azure Databricks では、暗黙的なキャストのこれらの形式を、関数と演算子の呼び出しに対してのみ、かつ意図を明確に判定できる場所についてのみ使用します。
暗黙的なダウンキャスト
暗黙的なダウンキャストでは、より広い型が、より狭い型に自動的にキャストされ、開発者がキャストを明示的に指定する必要がありません。 ダウンキャストは便利ですが、狭い型で実際の値を表現できない場合に予期しないランタイム エラーが発生するリスクが伴います。
ダウンキャストでは、型の優先順位リストが逆の順序で適用されます。
GEOGRAPHYとGEOMETRYのデータ型はダウンキャストされません。
暗黙的なクロスキャスト
暗黙的なクロスキャストでは、キャストを明示的に指定しなくても、ある型ファミリから別の型ファミリに値がキャストされます。
Azure Databricks では、以下の暗黙的なクロスキャストがサポートされています。
-
BINARYGEOGRAPHY、GEOMETRY、STRINGを除く任意の単純型。 -
STRINGおよびGEOGRAPHYを 除く、任意の単純型へのGEOMETRY。
-
関数呼び出し時のキャスト
解決される関数や演算子があると、パラメーターと引数のペアごとに、列挙されている順序で以下のルールが適用されます。
サポートされているパラメーター型が引数の 型の優先順位グラフの一部である場合、Azure Databricks は引数をそのパラメーター型に 昇格 させます。
ほとんどの場合、関数の説明には、サポートされている型またはチェーン ("任意の数値型" など) が明示的に記述されています。
たとえば、 sin(expr) は
DOUBLEで動作しますが、任意の数値を受け入れます。想定されるパラメーター型が
STRINGで、引数が単純型の場合、Azure Databricks は引数を文字列パラメーター型に クロスキャスト します。たとえば、substr(str, start, len) では
strはSTRINGであると想定されています。 代わりに、数値型または datetime 型を渡すことができます。引数の型が
STRINGで、予期されるパラメーター型が単純型の場合、Azure Databricks は文字列引数をサポートされている最も広いパラメーター型に クロスキャスト します。たとえば、date_add(日付、日)には、
DATEとINTEGERが必要です。date_add()を 2 つのSTRINGと共に呼び出すと、Azure Databricks は最初のをSTRINGしてDATEに変換し、2 番目をSTRINGしてINTEGERに変換します。関数が数値型 (
INTEGER、またはDATE型など) を受け取るが、引数がより一般的な型 (DOUBLEやTIMESTAMPなど) である場合、Azure Databricks は引数をそのパラメーター型に暗黙的に ダウンキャスト します。たとえば、date_add(日付、日)には、
DATEとINTEGERが必要です。date_add()、TIMESTAMP、BIGINTの順に呼び出した場合、Azure Databricks はから時間コンポーネントを削除してTIMESTAMPにダウンキャストし、DATEをBIGINTに変換します。それ以外の場合は、Azure Databricks でエラーが発生します。
Examples
coalesce関数は、最も一般的な型を共有している限り、引数の型のセットを受け入れます。
結果の型は、引数の最小共通型です。
-- The least common type of TINYINT and BIGINT is BIGINT
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
-- INTEGER and DATE do not share a precedence chain or support crosscasting in either direction.
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: DATATYPE_MISMATCH.DATA_DIFF_TYPES
-- Both are ARRAYs and the elements have a least common type
> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)))
ARRAY<BIGINT>
-- The least common type of INT and FLOAT is DOUBLE
> SELECT typeof(coalesce(1, 1F))
DOUBLE
> SELECT typeof(coalesce(1L, 1F))
DOUBLE
> SELECT typeof(coalesce(1BD, 1F))
DOUBLE
-- The least common type between an INT and STRING is BIGINT
> SELECT typeof(coalesce(5, '6'));
BIGINT
-- The least common type is a BIGINT, but the value is not BIGINT.
> SELECT coalesce('6.1', 5);
Error: CAST_INVALID_INPUT
-- The least common type between a DECIMAL and a STRING is a DOUBLE
> SELECT typeof(coalesce(1BD, '6'));
DOUBLE
-- Two distinct explicit collations result in an error
> SELECT collation(coalesce('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE));
Error: COLLATION_MISMATCH.EXPLICIT
-- The resulting collation between two distinct implicit collations is indeterminate
> SELECT collation(coalesce(c1, c2))
FROM VALUES('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE) AS T(c1, c2);
NULL
-- The resulting collation between a explicit and an implicit collations is the explicit collation.
> SELECT collation(coalesce(c1 COLLATE UTF8_BINARY, c2))
FROM VALUES('hello',
'world' COLLATE UNICODE) AS T(c1, c2);
UTF8_BINARY
-- The resulting collation between an implicit and the default collation is the implicit collation.
> SELECT collation(coalesce(c1, 'world'))
FROM VALUES('hello' COLLATE UNICODE) AS T(c1, c2);
UNICODE
-- The resulting collation between the default collation and the indeterminate collation is the default collation.
> SELECT collation(coalesce(coalesce('hello' COLLATE UTF8_BINARY, 'world' COLLATE UNICODE), 'world'));
UTF8_BINARY
-- Least common type between GEOGRAPHY(srid) and GEOGRAPHY(ANY)
> SELECT typeof(coalesce(st_geogfromtext('POINT(1 2)'), to_geography('POINT(3 4)'), NULL));
geography(any)
-- Least common type between GEOMETRY(srid1) and GEOMETRY(srid2)
> SELECT typeof(coalesce(st_geomfromtext('POINT(1 2)', 4326), st_geomfromtext('POINT(3 4)', 3857), NULL));
geometry(any)
-- Least common type between GEOMETRY(srid1) and GEOMETRY(ANY)
> SELECT typeof(coalesce(st_geomfromtext('POINT(1 2)', 4326), to_geometry('POINT(3 4)'), NULL));
geometry(any)
-- Least common type between DECIMAL(10,2) and DECIMAL(12,5): precision accommodates both
> SELECT typeof(coalesce(CAST(1 AS DECIMAL(10,2)), CAST(1 AS DECIMAL(12,5))));
DECIMAL(15,5)
-- Least common type between TIME(0) and TIME(6) is the wider precision
> SELECT typeof(coalesce(TIME'10:30:00', CAST(TIME'10:30:00.123456' AS TIME(6))));
TIME(6)
substring関数は、文字列にはSTRING型の引数を、start パラメーターと length パラメーターにはINTEGER型の引数を期待します。
-- Promotion of TINYINT to INTEGER
> SELECT substring('hello', 1Y, 2);
he
-- No casting
> SELECT substring('hello', 1, 2);
he
-- Casting of a literal string
> SELECT substring('hello', '1', 2);
he
-- Downcasting of a BIGINT to an INT
> SELECT substring('hello', 1L, 2);
he
-- Crosscasting from STRING to INTEGER
> SELECT substring('hello', str, 2)
FROM VALUES(CAST('1' AS STRING)) AS T(str);
he
-- Crosscasting from INTEGER to STRING
> SELECT substring(12345, 2, 2);
23
||(CONCAT) では、文字列への暗黙的なクロスキャストが許可されます。
-- A numeric is cast to STRING
> SELECT 'This is a numeric: ' || 5.4E10;
This is a numeric: 5.4E10
-- A date is cast to STRING
> SELECT 'This is a date: ' || DATE'2021-11-30';
This is a date: 2021-11-30
暗黙のダウンキャストにより、 または TIMESTAMP を使用して BIGINT を呼び出すことができます。
> SELECT date_add(TIMESTAMP'2011-11-30 08:30:00', 5L);
2011-12-05
date_add は、暗黙的なクロスキャストのために STRINGで呼び出すことができます。
> SELECT date_add('2011-11-30 08:30:00', '5');
2011-12-05