LangChain.js と Azure サービスを使用してインテリジェントな人事アシスタントを構築します。 このエージェントは、架空の NorthWind 企業の従業員が、会社のドキュメントを検索して人事に関する質問に対する回答を見つけるのに役立ちます。
Azure AI Search を使用して関連するドキュメントを検索し、Azure OpenAI を使用して正確な回答を生成します。 LangChain.js フレームワークは、エージェント オーケストレーションの複雑さを処理するため、特定のビジネス要件に集中できます。
ここでは、次の内容について学習します。
- Azure Developer CLI を使用して Azure リソースをデプロイする
- Azure サービスと統合する LangChain.js エージェントを構築する
- ドキュメント検索用に取得拡張生成 (RAG) を実装する
- ローカルおよび Azure でエージェントをテストおよびデバッグする
このチュートリアルの終わりまでに、会社のドキュメントを使用して人事に関する質問に回答する、動作する REST API が用意されています。
アーキテクチャの概要
NorthWind は、次の 2 つのデータ ソースに依存しています。
- すべての従業員がアクセスできる人事ドキュメント
- 機密性の高い従業員データを含む機密人事データベース。
このチュートリアルでは、パブリック人事ドキュメントを使用して従業員の質問に回答できるかどうかを決定する LangChain.js エージェントの構築に焦点を当てます。 その場合は、LangChain.js エージェントが直接回答を提供します。
[前提条件]
LangChain.js エージェントのビルドと実行など、 Codespace またはローカル開発コンテナーでこのサンプルを使用するには、次のものが必要です。
- アクティブな Azure アカウントアカウントがない場合、Azure 試用版にサインアップして、最大 10 件の無料 Mobile Apps を入手できます。 アカウントがない場合は、無料でアカウントを作成 します。
開発コンテナーを使用せずにサンプル コードをローカルで実行する場合は、次も必要です。
- Node.js LTS がシステムにインストールされています。
- TypeScript コードを記述およびコンパイルするための TypeScript。
- Azure Developer CLI (azd) がインストールおよび構成されています。
- LangChain.js エージェントをビルドするためのライブラリです。
- 省略可能: AI の使用状況を監視するための LangSmith 。 プロジェクト名、キー、エンドポイントが必要です。
- 省略可能: LangGraph チェーン と LangChain.js エージェントをデバッグするための LangGraph Studio。
Azure のリソース
次の Azure リソースが必要です。 この記事では、Azure Developer CLI と AzureVerified Modules (AVM) を使用した Bicep テンプレートを使用して作成します。 リソースは、学習目的でパスワードなしのアクセスとキー アクセスの両方を使用して作成されます。 このチュートリアルでは、パスワードレス認証にローカル開発者アカウントを使用します。
- Azure サービスに対するパスワードレス認証のマネージド ID。
- Node.js Fastify API サーバーの Docker イメージを格納する Azure Container Registry。
- Node.js Fastify API サーバーをホストする Azure Container App。
- ベクター検索用の Azure AI Search リソース。
- 次のモデルを使用する Azure OpenAI リソース:
-
text-embedding-3-smallなどの埋め込みモデル。 -
'gpt-4.1-miniのような大規模な言語モデル (LLM)。
-

エージェントのアーキテクチャ
LangChain.js フレームワークは、LangGraph としてインテリジェント なエージェントを構築するための意思決定フローを提供します。 このチュートリアルでは、Azure AI Search と Azure OpenAI と統合して人事関連の質問に回答する LangChain.js エージェントを作成します。 エージェントのアーキテクチャは、次の目的で設計されています。
- 質問が、すべての従業員が利用できる一般的な人事文書に関連しているかどうかを判断します。
- ユーザー クエリに基づいて、Azure AI Search から関連ドキュメントを取得します。
- Azure OpenAI を使用して、取得したドキュメントと LLM モデルに基づいて回答を生成します。
主要コンポーネント:
グラフ構造: LangChain.js エージェントはグラフとして表され、次のようになります。
- ノードは 、意思決定やデータの取得など、特定のタスクを実行します。
- エッジは ノード間のフローを定義し、操作のシーケンスを決定します。
Azure AI Search の統合:
- 埋め込みモデルを使用してベクトルを作成します。
- HR ドキュメント (*.md, *.pdf) をベクター ストアに挿入します。
ドキュメントには次のものが含まれます。
- 会社情報
- 従業員ハンドブック
- 特典ハンドブック
- 従業員役割ライブラリ
- ユーザー プロンプトに基づいて関連するドキュメントを取得します。
-
Azure OpenAI の統合:
- 大規模な言語モデルを使用して次の処理を行います。
- 一般的な人事ドキュメントから質問に回答できるかどうかを判断します。
- ドキュメントとユーザーの質問のコンテキストを使用して、プロンプトで回答を生成します。
- 大規模な言語モデルを使用して次の処理を行います。
次の表には、一般的な人事ドキュメントから関連性があり、回答可能または不可なユーザーの質問例が示されています。
| 質問 | 関連した | Explanation |
|---|---|---|
Does the NorthWind Health Plus plan cover eye exams? |
イエス | 従業員ハンドブックなどの人事文書は、回答を提供する必要があります。 |
How much of my perks + benefits have I spent? |
いいえ | この質問には、このエージェントの範囲外の機密従業員データへのアクセスが必要です。 |
LangChain.js フレームワークを使用すると、エージェントと Azure サービス統合に通常必要なエージェント定型コードの多くを回避し、ビジネス ニーズに集中できます。
サンプル コード リポジトリを複製する
新しいディレクトリで、サンプル コード リポジトリを複製し、新しいディレクトリに変更します。
git clone https://github.com/Azure-Samples/azure-typescript-langchainjs.git
cd azure-typescript-langchainjs
このサンプルでは、セキュリティで保護された Azure リソースを作成し、Azure AI Search と Azure OpenAI を使用して LangChain.js エージェントを構築し、Node.js Fastify API サーバーからエージェントを使用するために必要なコードを提供します。
Azure CLI と Azure Developer CLI に対する認証
Azure Developer CLI を使用して Azure にサインインし、Azure リソースを作成して、ソース コードをデプロイします。 デプロイ プロセスでは Azure CLI と Azure Developer CLI の両方が使用されるため、Azure CLI にサインインし、Azure CLI からの認証を使用するように Azure Developer CLI を構成します。
az login
azd config set auth.useAzCliAuth true
Azure Developer CLI を使用してリソースを作成し、コードをデプロイする
azd up コマンドを実行して、デプロイ プロセスを開始します。
azd up
azd up コマンドの実行中に、次の質問に答えます。
-
新しい環境名:
langchain-agentなどの一意の環境名を入力します。 この環境名は、Azure リソース グループの一部として使用されます。 - Azure サブスクリプションを選択する: リソースが作成されるサブスクリプションを選択します。
-
リージョン (
eastus2など) を選択します。
デプロイには約 10 ~ 15 分かかります。 Azure Developer CLI は、 azure.yaml ファイルで定義されているフェーズとフックを使用してプロセスを調整します。
プロビジョニング フェーズ ( azd provisionと同等):
-
infra/main.bicepで定義されている Azure リソースを作成します。- Azure Container App
- OpenAI
- AI検索
- Container Registry
- マネージド ID
-
プロビジョニング後フック: Azure AI Search インデックス
northwindが既に存在するかどうかを確認します- インデックスが存在しない場合:
npm installとnpm run load_dataを実行し、LangChain.js PDF ローダーと埋め込みクライアントを使用してHRドキュメントをアップロードします。 - インデックスが存在する場合: 重複を回避するためにデータの読み込みをスキップします (インデックスを削除するか、
npm run load_dataを実行して手動で再読み込みできます) デプロイ フェーズ (azd deployと同等):
- インデックスが存在しない場合:
- 事前デプロイ フック: Fastify API サーバーの Docker イメージをビルドし、Azure Container Registry にプッシュします
- コンテナー化された API サーバーを Azure Container Apps にデプロイします
デプロイが完了すると、環境変数とリソース情報がリポジトリ ルートの .env ファイルに保存されます。
Azure portal でリソースを表示できます。
リソースは、学習目的でパスワードなしのアクセスとキー アクセスの両方を使用して作成されます。 この入門チュートリアルでは、パスワードレス認証にローカル開発者アカウントを使用します。 運用アプリケーションの場合は、マネージド ID でパスワードレス認証のみを使用します。 パスワードレス認証の詳細を確認します。
サンプル コードをローカルで使用する
Azure リソースが作成されたので、LangChain.js エージェントをローカルで実行できます。
依存関係のインストール
このプロジェクトの Node.js パッケージをインストールします。
npm installこのコマンドは、
package.jsonディレクトリ内の 2 つのpackages-v1ファイルに定義されている依存関係をインストールします。-
./packages-v1/server-api:- Web サーバーの Fastify
-
./packages-v1/langgraph-agent:- エージェントを構築するための LangChain.js
- Azure SDK クライアント ライブラリは、Azure AI Search リソースと統合するための
@azure/search-documents。 リファレンス ドキュメント はこちらです。
-
API サーバーと AI エージェントの 2 つのパッケージをビルドします。
npm run buildこのコマンドは、API サーバーが AI エージェントを呼び出すことができるように、2 つのパッケージ間にリンクを作成します。
API サーバーをローカルで実行する
Azure Developer CLI は、必要な Azure リソースを作成し、ルート .env ファイルに環境変数を構成しました。 この構成には、ベクター ストアにデータをアップロードするためのプロビジョニング後フックが含まれていました。 これで、LangChain.js エージェントをホストする Fastify API サーバーを実行できるようになりました。 Fastify API サーバーを起動します。
npm run dev
サーバーが起動し、ポート 3000 でリッスンします。 Web ブラウザーで [http://localhost:3000] に移動して、サーバーをテストできます。 サーバーが実行されていることを示すウェルカム メッセージが表示されます。
API を使用して質問する
REST クライアントやcurlなどのツールを使用して、質問を含む JSON 本文を使用して、/ask エンドポイントに POST 要求を送信できます。
rest クライアント クエリは、 packages-v1/server-api/http ディレクトリで使用できます。
curl の使用例:
curl -X POST http://localhost:3000/answer -H "Content-Type: application/json" -d "{\"question\": \"Does the NorthWind Health Plus plan cover eye exams?\"}"
LangChain.js エージェントからの回答を含む JSON 応答を受け取る必要があります。
{
"answer": "Yes, the NorthWind Health Plus plan covers eye exams. According to the Employee Handbook, employees enrolled in the Health Plus plan are eligible for annual eye exams as part of their vision benefits."
}
packages-v1/server-api/http ディレクトリには、いくつかの質問例があります。
REST クライアントを使用して Visual Studio Code でファイルを開き、すばやくテストします。
アプリケーション コードを理解する
このセクションでは、LangChain.js エージェントと Azure サービスの統合方法について説明します。 リポジトリのアプリケーションは、次の 2 つのメイン パッケージを含む npm ワークスペースとして編成されます。
Project Root
│
├── packages-v1/
│ │
│ ├── langgraph-agent/ # Core LangGraph agent implementation
│ │ ├── src/
│ │ │ ├── azure/ # Azure service integrations
│ │ │ │ ├── azure-credential.ts # Centralized auth with DefaultAzureCredential
│ │ │ │ ├── embeddings.ts # Azure OpenAI embeddings + PDF loading + rate limiting
│ │ │ │ ├── llm.ts # Azure OpenAI chat completion (key-based & passwordless)
│ │ │ │ └── vector_store.ts # Azure AI Search vector store + indexing + similarity search
│ │ │ │
│ │ │ ├── langchain/ # LangChain agent logic
│ │ │ │ ├── node_get_answer.ts # RAG: retrieves docs + generates answers
│ │ │ │ ├── node_requires_hr_documents.ts # Determines if HR docs needed
│ │ │ │ ├── nodes.ts # LangGraph node definitions + state management
│ │ │ │ └── prompt.ts # System prompts + conversation templates
│ │ │ │
│ │ │ └── scripts/ # Utility scripts
│ │ │ └── load_vector_store.ts # Uploads PDFs to Azure AI Search
│ │ │
│ │ └── data/ # Source documents (PDFs) for vector store
│ │
│ └── server-api/ # Fastify REST API server
│ └── src/
│ └── server.ts # HTTP server with /answer endpoint
│
├── infra/ # Infrastructure as Code
│ └── main.bicep # Azure resources: Container Apps, OpenAI, AI Search, ACR, managed identity
│
├── azure.yaml # Azure Developer CLI config + deployment hooks
├── Dockerfile # Multi-stage Docker build for containerized deployment
└── package.json # Workspace configuration + build scripts
アーキテクチャに関する主な決定事項:
- Monorepo 構造体: npm ワークスペースでは、 共有依存関係とリンクされたパッケージが許可されます
-
懸念事項の分離: エージェント ロジック (
langgraph-agent) は API サーバーから独立しています (server-api) -
一元化された認証:
./langgraph-agent/src/azure内のファイルは、キーベースの認証とパスワードレス認証と Azure サービス統合の両方を処理します
Azure サービスへの認証
アプリケーションは、 SET_PASSWORDLESS 環境変数によって制御されるキーベースの認証方法とパスワードレス認証方法の両方をサポートしています。
Azure Identity ライブラリの DefaultAzureCredential API はパスワードレス認証に使用され、アプリケーションをローカルの開発環境と Azure 環境でシームレスに実行できます。 この認証は、次の コード スニペットで確認できます。
import { DefaultAzureCredential } from "@azure/identity";
export const CREDENTIAL = new DefaultAzureCredential();
export const SCOPE_OPENAI = "https://cognitiveservices.azure.com/.default";
export async function azureADTokenProvider_OpenAI() {
const tokenResponse = await CREDENTIAL.getToken(SCOPE_OPENAI);
return tokenResponse.token;
}
LangChain.js や OpenAI ライブラリなどのサード パーティ製ライブラリを使用して Azure OpenAI にアクセスする場合は、資格情報オブジェクトを直接渡す代わりに トークン プロバイダー関数 が必要です。 Azure Id ライブラリの getBearerTokenProvider 関数は、特定の Azure リソース スコープ (たとえば、 "https://cognitiveservices.azure.com/.default") の OAuth 2.0 ベアラー トークンを自動的にフェッチおよび更新するトークン プロバイダーを作成することで、この問題を解決します。 スコープはセットアップ時に 1 回構成し、トークン プロバイダーはすべてのトークン管理を自動的に処理します。 この方法は、マネージド ID や Azure CLI 資格情報など、Azure ID ライブラリの資格情報で機能します。 Azure SDK ライブラリは DefaultAzureCredential を直接受け入れますが、LangChain.js のようなサード パーティ製ライブラリでは、認証ギャップを埋めるためにこのトークン プロバイダー パターンが必要です。
Azure AI Search の統合
Azure AI Search リソースは、ドキュメント埋め込みを格納し、関連するコンテンツのセマンティック検索を可能にします。 アプリケーションでは、LangChain の AzureAISearchVectorStore を使用して、インデックス スキーマを定義しなくてもベクター ストアを管理します。
ベクター ストアは、ドキュメントの読み込みとクエリで異なる構成を使用できるように、管理者 (書き込み) 操作とクエリ (読み取り) 操作の両方の構成で作成されます。 これは、キーを使用しているか、マネージド ID でパスワードレス認証を使用しているかに関係なく重要です。
Azure Developer CLI のデプロイには、PDF ローダーと埋め込みクライアントを使用してベクター ストアにドキュメント LangChain.js アップロードするデプロイ後フックが含まれています。 このデプロイ後フックは、Azure AI Search リソースが作成された後の azd up コマンドの最後の手順です。 ドキュメント読み込みスクリプトでは、バッチ処理と再試行ロジックを使用してサービス レートの制限を処理します。
postdeploy:
posix:
sh: bash
run: |
echo "Checking if vector store data needs to be loaded..."
# Check if already loaded
INDEX_CREATED=$(azd env get-values | grep INDEX_CREATED | cut -d'=' -f2 || echo "false")
if [ "$INDEX_CREATED" = "true" ]; then
echo "Index already created. Skipping data load."
echo "Current document count: $(azd env get-values | grep INDEX_DOCUMENT_COUNT | cut -d'=' -f2)"
else
echo "Loading vector store data..."
npm install
npm run build
npm run load_data
# Get document count from the index
SEARCH_SERVICE=$(azd env get-values | grep AZURE_AISEARCH_ENDPOINT | cut -d'/' -f3 | cut -d'.' -f1)
DOC_COUNT=$(az search index show --service-name $SEARCH_SERVICE --name northwind --query "documentCount" -o tsv 2>/dev/null || echo "0")
# Mark as loaded
azd env set INDEX_CREATED true
azd env set INDEX_DOCUMENT_COUNT $DOC_COUNT
echo "Data loading complete! Indexed $DOC_COUNT documents."
fi
Azure Developer CLI によって作成されたルート .env ファイルを使用します。Azure AI Search リソースに対して認証を行い、 AzureAISearchVectorStore クライアントを作成できます。
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
const adminKey = process.env.AZURE_AISEARCH_ADMIN_KEY;
const queryKey = process.env.AZURE_AISEARCH_QUERY_KEY;
export const QUERY_DOC_COUNT = 3;
const MAX_INSERT_RETRIES = 3;
const shared_admin = {
endpoint,
indexName,
};
export const VECTOR_STORE_ADMIN_KEY: AzureAISearchConfig = {
...shared_admin,
key: adminKey,
};
export const VECTOR_STORE_ADMIN_PASSWORDLESS: AzureAISearchConfig = {
...shared_admin,
credentials: CREDENTIAL,
};
export const VECTOR_STORE_ADMIN_CONFIG: AzureAISearchConfig =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_ADMIN_PASSWORDLESS
: VECTOR_STORE_ADMIN_KEY;
const shared_query = {
endpoint,
indexName,
search: {
type: AzureAISearchQueryType.Similarity,
},
};
// Key-based config
export const VECTOR_STORE_QUERY_KEY: AzureAISearchConfig = {
key: queryKey,
...shared_query,
};
export const VECTOR_STORE_QUERY_PASSWORDLESS: AzureAISearchConfig = {
credentials: CREDENTIAL,
...shared_query,
};
export const VECTOR_STORE_QUERY_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_QUERY_PASSWORDLESS
: VECTOR_STORE_QUERY_KEY;
クエリを実行すると、ベクター ストアはユーザーのクエリを埋め込みに変換し、同様のベクター表現を持つドキュメントを検索し、最も関連性の高いチャンクを返します。
export function getReadOnlyVectorStore(): AzureAISearchVectorStore {
const embeddings = getEmbeddingClient();
return new AzureAISearchVectorStore(embeddings, VECTOR_STORE_QUERY_CONFIG);
}
export async function getDocsFromVectorStore(
query: string,
): Promise<Document[]> {
const store = getReadOnlyVectorStore();
// @ts-ignore
//return store.similaritySearchWithScore(query, QUERY_DOC_COUNT);
return store.similaritySearch(query, QUERY_DOC_COUNT);
}
ベクター ストアは LangChain.jsの上に構築されるため、ベクター ストアと直接やり取りする複雑さが抽象化されます。 LangChain.js ベクター ストア インターフェイスを学習したら、後で他のベクター ストアの実装に簡単に切り替えることができます。
Azure OpenAI の統合
アプリケーションは、埋め込みと大規模言語モデル (LLM) 機能の両方に Azure OpenAI を使用します。 LangChain.js の AzureOpenAIEmbeddings クラスは、ドキュメントとクエリの埋め込みを生成するために使用されます。 埋め込みクライアントを作成すると、LangChain.js はそれを使用して埋め込みを作成します。
埋め込み用の Azure OpenAI 統合
Azure Developer CLI によって作成されたルート .env ファイルを使用して、Azure OpenAI リソースに対する認証を行い、 AzureOpenAIEmbeddings クライアントを 作成します。
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiEmbeddingsDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
dimensions: 1536, // for text-embedding-3-small
batchSize: EMBEDDING_BATCH_SIZE,
maxRetries: 7,
timeout: 60000,
};
export const EMBEDDINGS_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const EMBEDDINGS_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const EMBEDDINGS_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? EMBEDDINGS_CONFIG_PASSWORDLESS
: EMBEDDINGS_KEY_CONFIG;
export function getEmbeddingClient(): AzureOpenAIEmbeddings {
return new AzureOpenAIEmbeddings({ ...EMBEDDINGS_CONFIG });
}
LLM 用の Azure OpenAI 統合
Azure Developer CLI によって作成されたルート .env ファイルを使用して、Azure OpenAI リソースに対する認証を行い、 AzureChatOpenAI クライアントを作成します。
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
maxTokens: maxTokens ? parseInt(maxTokens, 10) : 1000,
maxRetries: 7,
timeout: 60000,
temperature: 0,
};
export const LLM_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const LLM_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const LLM_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? LLM_CONFIG_PASSWORDLESS
: LLM_KEY_CONFIG;
アプリケーションは、LangChain.js AzureChatOpenAI の@langchain/openai クラスを使用して、Azure OpenAI モデルと対話します。
export const callChatCompletionModel = async (
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> => {
const llm = new AzureChatOpenAI({
...LLM_CONFIG,
});
const completion = await llm.invoke(state.messages);
completion;
return {
messages: [
...state.messages,
{
role: "assistant",
content: completion.content,
},
],
};
};
LangGraph エージェントのワークフロー
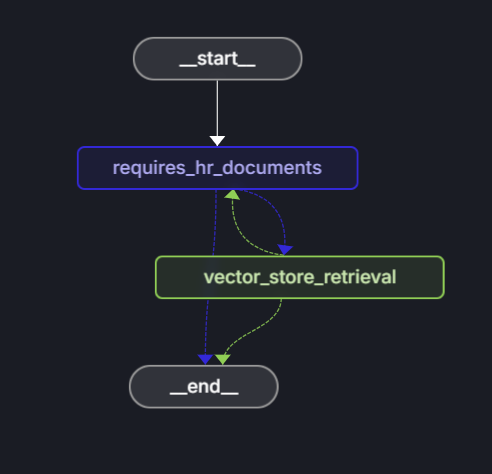
エージェントは LangGraph を使用して、HR ドキュメントを使用して質問に回答できるかどうかを決定する決定ワークフローを定義します。
グラフ構造:
import { StateGraph } from "@langchain/langgraph";
import {
START,
ANSWER_NODE,
DECISION_NODE,
route as endRoute,
StateAnnotation,
} from "./langchain/nodes.js";
import { getAnswer } from "./langchain/node_get_answer.js";
import {
requiresHrResources,
routeRequiresHrResources,
} from "./langchain/node_requires_hr_documents.js";
const builder = new StateGraph(StateAnnotation)
.addNode(DECISION_NODE, requiresHrResources)
.addNode(ANSWER_NODE, getAnswer)
.addEdge(START, DECISION_NODE)
.addConditionalEdges(DECISION_NODE, routeRequiresHrResources)
.addConditionalEdges(ANSWER_NODE, endRoute);
export const hr_documents_answer_graph = builder.compile();
hr_documents_answer_graph.name = "Azure AI Search + Azure OpenAI";
ワークフローは、次の手順で構成されます:
- 開始: ユーザーが質問を送信します。
- requires_hr_documentsノード: LLM は、質問が一般的な人事ドキュメントから回答できるかどうかを判断します。
-
条件付きルーティング:
- "はい" の場合は、ノード
get_answer進みます。 - いいえの場合は、質問に個人の人事データが必要なメッセージを返します。
- "はい" の場合は、ノード
- get_answer ノード: ドキュメントを取得し、回答を生成します。
- 終了: ユーザーに回答を返します。
人事に関するすべての質問に一般的なドキュメントから回答できるわけではないため、この関連性チェックは重要です。 "持っている PTO の量" のような個人的な質問には、個々の従業員データを含む従業員データベースへのアクセスが必要です。 最初に関連性を確認することで、エージェントは、アクセスできない個人情報が必要な質問に対して幻のような答えを避けることができます。
質問に人事文書が必要かどうかを判断する
requires_hr_documents ノードは LLM を使用して、一般的な人事ドキュメントを使用してユーザーの質問に回答できるかどうかを判断します。 質問の関連性に基づいて、 YES または NO で応答するようにモデルに指示するプロンプト テンプレートを使用します。 ワークフローに沿って渡すことができる構造化されたメッセージで回答を返します。 次のノードでは、この応答を使用して、ワークフローを END または ANSWER_NODEにルーティングします。
// @ts-nocheck
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { RunnableConfig } from "@langchain/core/runnables";
import { BaseMessage } from "@langchain/core/messages";
import { ANSWER_NODE, END } from "./nodes.js";
const PDF_DOCS_REQUIRED = "Answer requires HR PDF docs.";
export async function requiresHrResources(
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> {
const lastUserMessage: BaseMessage = [...state.messages].reverse()[0];
let pdfDocsRequired = false;
if (lastUserMessage && typeof lastUserMessage.content === "string") {
const question = `Does the following question require general company policy information that could be found in HR documents like employee handbooks, benefits overviews, or company-wide policies, then answer yes. Answer no if this requires personal employee-specific information that would require access to an individual's private data, employment records, or personalized benefits details: '${lastUserMessage.content}'. Answer with only "yes" or "no".`;
const llm = getLlmChatClient();
const response = await llm.invoke(question);
const answer = response.content.toLocaleLowerCase().trim();
console.log(`LLM question (is HR PDF documents required): ${question}`);
console.log(`LLM answer (is HR PDF documents required): ${answer}`);
pdfDocsRequired = answer === "yes";
}
// If HR documents (aka vector store) are required, append an assistant message to signal this.
if (!pdfDocsRequired) {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content:
"Not a question for our HR PDF resources. This requires data specific to the asker.",
},
],
};
return updatedState;
} else {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content: `${PDF_DOCS_REQUIRED} You asked: ${lastUserMessage.content}. Let me check.`,
},
],
};
return updatedState;
}
}
export const routeRequiresHrResources = (
state: typeof StateAnnotation.State,
): typeof END | typeof ANSWER_NODE => {
const lastMessage: BaseMessage = [...state.messages].reverse()[0];
if (lastMessage && !lastMessage.content.includes(PDF_DOCS_REQUIRED)) {
console.log("go to end");
return END;
}
console.log("go to llm");
return ANSWER_NODE;
};
必要な人事ドキュメントを取得する
質問に HR ドキュメントが必要であると判断されると、ワークフローは getAnswer を使用してベクター ストアから関連ドキュメントを取得し、それらをプロンプトの コンテキスト に追加し、プロンプト全体を LLM に渡します。
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "./nodes.js";
import { AIMessage } from "@langchain/core/messages";
import { getReadOnlyVectorStore } from "../azure/vector_store.js";
const EMPTY_STATE = { messages: [] };
export async function getAnswer(
state: typeof StateAnnotation.State = EMPTY_STATE,
): Promise<typeof StateAnnotation.Update> {
const vectorStore = getReadOnlyVectorStore();
const llm = getLlmChatClient();
// Extract the last user message's content from the state as input
const lastMessage = state.messages[state.messages.length - 1];
const userInput =
lastMessage && typeof lastMessage.content === "string"
? lastMessage.content
: "";
const docs = await vectorStore.similaritySearch(userInput, 3);
if (docs.length === 0) {
const noDocMessage = new AIMessage(
"I'm sorry, I couldn't find any relevant information to answer your question.",
);
return {
messages: [...state.messages, noDocMessage],
};
}
const formattedDocs = docs.map((doc) => doc.pageContent).join("\n\n");
const prompt = ChatPromptTemplate.fromTemplate(`
Use the following context to answer the question:
{context}
Question: {question}
`);
const ragChain = prompt.pipe(llm);
const result = await ragChain.invoke({
context: formattedDocs,
question: userInput,
});
const assistantMessage = new AIMessage(result.text);
return {
messages: [...state.messages, assistantMessage],
};
}
関連するドキュメントが見つからない場合、エージェントは HR ドキュメントに回答が見つからなかったことを示すメッセージを返します。
トラブルシューティング
手順に関する問題については、サンプル コード リポジトリで問題を作成します
リソースをクリーンアップする
Azure AI Search リソースと Azure OpenAI リソースを保持するリソース グループを削除するか、Azure Developer CLI を使用して、このチュートリアルで作成されたすべてのリソースをすぐに削除できます。
azd down --purge