Apache Kafka と Azure Cosmos DB で Apache Spark 構造化ストリーミングを使用する
Apache Spark構造化ストリーミング を使って、Azure HDInsight 上で Apache Kafka からデータを読み込み、そのデータを Azure Cosmos DB に保存する方法を説明します。
Azure Cosmos DB は、グローバル分散型のマルチモデル データベースです。 この例では、Azure Cosmos DB for NoSQL データベース モデルを使用します。 詳細については、「Azure Cosmos DB の概要」のドキュメントを参照してください。
Spark 構造化ストリーミングは、Spark SQL に組み込まれたストリーミング処理エンジンであり、 静的データに対してバッチ計算と同様にストリーミング計算を表現できるようになります。 構造化ストリーミングの詳細については、Apache.org の「Structured Streaming Programming Guide」(構造化ストリーミングのプログラミング ガイド) をご覧ください。
重要
この例では、HDInsight 4.0 上で Spark 2.4 を使用します。
このドキュメントの手順では、HDInsight の Spark クラスターと HDInsight の Kafka クラスターの両方を含む Azure リソース グループを作成します。 これらのクラスターは両方とも、Spark クラスターが Kafka クラスターと直接通信できるように、Azure Virtual Network 内に配置します。
このドキュメントの手順を完了したら、余分に課金されないようにするためにクラスターは削除してください。
クラスターの作成
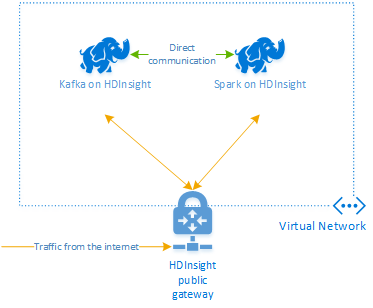
HDInsight 上の Apache Kafka では、パブリック インターネット経由の Kafka ブローカーへのアクセスは提供されません。 Kafka と通信するすべてのものは、Kafka クラスター内のノードと同じ Azure 仮想ネットワークに存在している必要があります。 この例では、Kafka クラスターと Spark クラスターの両方を Azure 仮想ネットワーク内に配置します。 次の図に、クラスター間の通信フローを示します。
Note
Kafka サービスは、仮想ネットワーク内の通信に制限されます。 SSH や Ambari など、クラスター上の他のサービスは、インターネット経由でアクセスできます。 HDInsight で使用できるパブリック ポートの詳細については、「HDInsight で使用されるポートと URI」を参照してください。
Azure 仮想ネットワーク、Kafka、および Spark クラスターは手動で作成できますが、Azure Resource Manager テンプレートを使用する方が簡単です。 次の手順に従って、Azure 仮想ネットワーク、Kafka クラスター、および Spark クラスターを Azure サブスクリプションにデプロイします。
次のボタンを使用して Azure にサインインし、Azure Portal でテンプレートを開きます。

Azure Resource Manager テンプレートは、このプロジェクトの GitHub リポジトリにあります (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb)。
このテンプレートでは、次のリソースを作成します。
HDInsight 4.0 クラスター上の Kafka。
HDInsight 4.0 クラスター上の Spark。
Azure Virtual Network (HDInsight クラスターを含む) テンプレートによって作成された仮想ネットワークは、10.0.0.0/16 アドレス空間を使用します。
Azure Cosmos DB for NoSQL のデータベース。
重要
この例で使用する構造化ストリーミングのノートブックでは、HDInsight 4.0 上に Spark が必要です。 HDInsight 上で以前のバージョンの Spark を使用している場合は、ノートブックを使用するとエラーを受信します。
以下の情報を使用して、 [カスタム デプロイ] セクションに各エントリを入力します。
プロパティ 値 サブスクリプション Azure サブスクリプションを選択します。 Resource group グループを作成するか、または既存のグループを選択します。 このグループに HDInsight クラスターが含まれます。 Azure Cosmos DB のアカウント名 この値が、Azure Cosmos DB アカウントの名前として使用されます。 名前に含めることができるのは、英小文字、数字、ハイフン (-) のみです。 長さは 3 文字から 31 文字でなければなりません。 Base Cluster Name (ベース クラスター名) この値は、Spark クラスターと Kafka クラスターのベース名として使用されます。 たとえば、「myhdi」と入力すると、spark-myhdi という名前の Spark クラスターと、kafka-myhdi という名前の Kafka クラスターが作成されます。 クラスターのバージョン HDInsight クラスターのバージョン。 この例は HDInsight 4.0 でテストされており、その他の種類のクラスターでは機能しないことがあります。 [Cluster Login User Name](クラスター ログイン ユーザー名) Spark クラスターと Kafka クラスターの管理者のユーザー名。 [クラスター ログイン パスワード] Spark クラスターと Kafka クラスターの管理者のユーザー パスワード。 SSH ユーザー名 Spark クラスターと Kafka クラスターの作成に使用する SSH ユーザー。 SSH パスワード Spark クラスターと Kafka クラスター用の SSH ユーザーのパスワード。 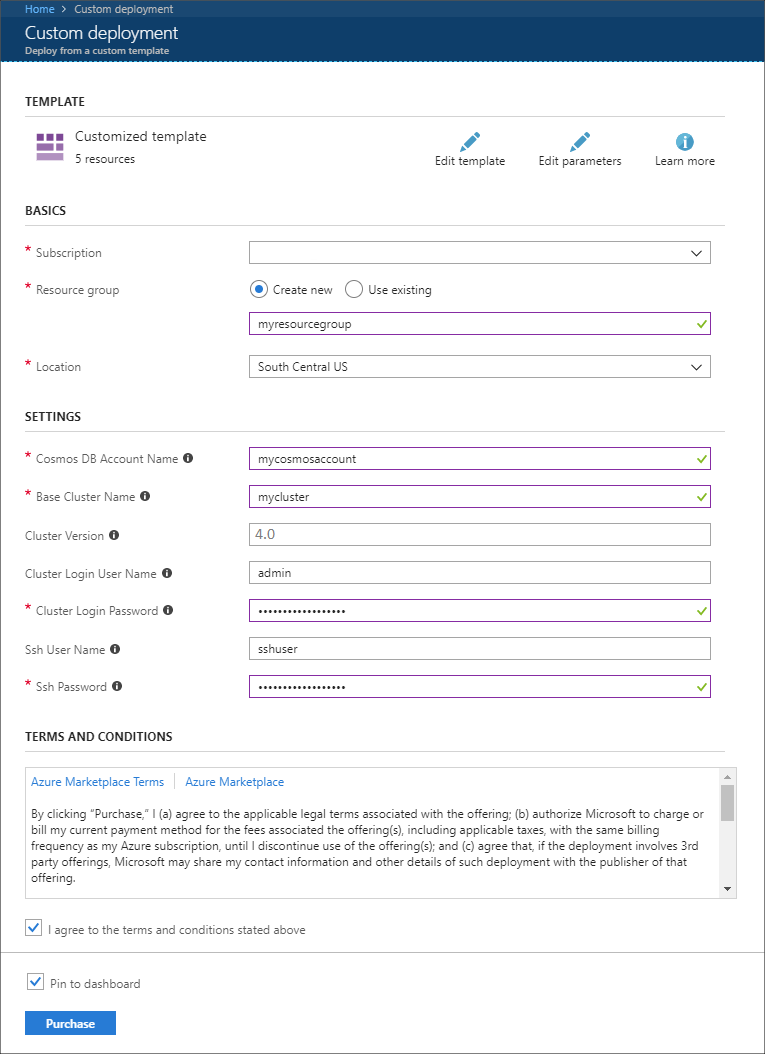
使用条件を読み、 [上記の使用条件に同意する] をオンにします。
最後に、 [購入] を選択します。 クラスター、仮想ネットワーク、および Azure Cosmos DB アカウントを作成するまで、最大で 45 分間かかる場合があります。
Azure Cosmos DB データベースとコレクションを作成する
このドキュメントで使用するプロジェクトでは、データを Azure Cosmos DB に格納します。 コードを実行する前に、お使いの Azure Cosmos DB インスタンス内に、まず "データベース" と "コレクション" を作成する必要があります。 ドキュメントのエンドポイントと、Azure Cosmos DB に対する要求の認証に使用される "キー" も取得する必要があります。
これを実行する方法の 1 つとして、Azure CLI を使用します。 次のスクリプトでは、kafkadata という名前のデータベースと kafkacollection という名前のコレクションを作成します。 その後、プライマリ キーが返されます。
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
ドキュメントのエンドポイントとプライマリ キーの情報は、次のテキストのようになっています。
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
重要
Jupyter Notebook で必要とされるため、エンドポイントとキーの値を保存します。
ノートブックを取得する
このドキュメントで説明した例のコードは、https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb で入手できます。
ノートブックをアップロードする
プロジェクトから HDInsight クラスター上の Spark へノートブックをアップロードするには、以下の手順を使用します。
Web ブラウザーで、Spark クラスターの Jupyter Notebook に接続します。 次の URL の
CLUSTERNAMEをお使いの Spark クラスターの名前に置き換えます。https://CLUSTERNAME.azurehdinsight.net/jupyterプロンプトが表示されたら、クラスターの作成時に使用したログイン (管理者) パスワードを入力します。
ページの右上隅の [アップロード] ボタンを使用して、Stream-taxi-data-to-kafka.ipynb ファイルをクラスターにアップロードします。 [開く] を選択して、アップロードを開始します。
ノートブックの一覧で Stream-taxi-data-to-kafka.ipynb エントリを検索し、横にある [アップロード] ボタンを選択します。
手順 1. ~ 3. を繰り返して、Stream-data-from-Kafka-to-Cosmos-DB.ipynb ノートブックを読み込みます。
タクシー データを Kafka に読み込む
ファイルをアップロードした後、Stream-taxi-data-to-kafka.ipynb エントリを選択してノートブックを開きます。 ノートブックの手順に従って Kafka にデータを読み込みます。
Spark 構造化ストリーミングを使用してタクシー データを処理する
Jupyter Notebook のホーム ページから、Stream-data-from-Kafka-to-Cosmos-DB.ipynb エントリを選択します。 ノートブックの手順に従い、Spark 構造化ストリーミングを使って Kafka から Azure Cosmos DB にデータをストリーミングします。
次のステップ
この記事では、Apache Spark 構造化ストリームの使用方法を説明しました。Apache Spark、Apache Kafka、および Azure Cosmos DB の操作に関する詳細については、以下のドキュメントをご覧ください。