HDInsight 上の Apache Kafka を用いた Apache Spark ストリーミング (DStream) の例
Apache Spark を使用して、HDInsight 上の Apache Kafka に対して DStreams による送信または受信ストリーミングを行う方法について説明します。 この例では、Spark クラスター上で実行する Jupyter Notebook を使用します。
注意
このドキュメントの手順では、HDInsight の Spark クラスターと HDInsight の Kafka クラスターの両方を含む Azure リソース グループを作成します。 これらのクラスターは両方とも、Spark クラスターが Kafka クラスターと直接通信できるように、Azure Virtual Network 内に配置します。
このドキュメントの手順を完了したら、余分に課金されないようにするためにクラスターは削除してください。
重要
この例では DStreams を使用します。DStreams は古い Spark ストリーミング テクノロジです。 新しい Spark ストリーミング機能を使用する例については、Apache Kafka を使った Spark 構造化ストリーミングに関するドキュメントを参照してください。
クラスターの作成
HDInsight 上の Apache Kafka では、パブリック インターネット経由の Kafka ブローカーへのアクセスは提供されません。 Kafka と通信するすべてのものは、Kafka クラスター内のノードと同じ Azure 仮想ネットワークに存在している必要があります。 この例では、Kafka クラスターと Spark クラスターの両方を Azure 仮想ネットワーク内に配置します。 次の図に、クラスター間の通信フローを示します。
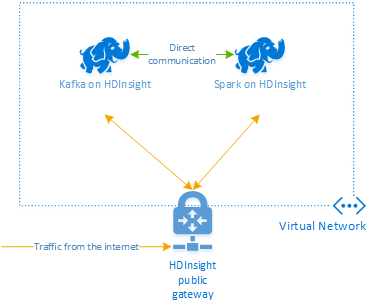
Note
Kafka 自体は仮想ネットワーク内の通信に制限されていますが、クラスターの SSH や Ambari などの他のサービスにはインターネット経由でアクセスすることができます。 HDInsight で使用できるパブリック ポートの詳細については、「HDInsight で使用されるポートと URI」を参照してください。
Azure 仮想ネットワーク、Kafka、および Spark クラスターは手動で作成できますが、Azure Resource Manager テンプレートを使用する方が簡単です。 次の手順に従って、Azure 仮想ネットワーク、Kafka クラスター、および Spark クラスターを Azure サブスクリプションにデプロイします。
次のボタンを使用して Azure にサインインし、Azure Portal でテンプレートを開きます。

警告
HDInsight で Kafka の可用性を保証するには、クラスターに少なくとも 4 つのワーカー ノードが必要です。 このテンプレートは、4 つのワーカー ノードが含まれる Kafka クラスターを作成します。
このテンプレートは、Kafka と Spark の両方の HDInsight 4.0 クラスターを作成します。
以下の情報を使用して、 [カスタム デプロイ] セクションに各エントリを入力します。
プロパティ 値 Resource group グループを作成するか、または既存のグループを選択します。 Location 地理的に近い場所を選択します。 Base Cluster Name (ベース クラスター名) この値は、Spark クラスターと Kafka クラスターのベース名として使用されます。 たとえば、「hdistreaming」と入力すると、spark-hdistreaming という名前の Spark クラスターと、kafka-hdistreaming という名前の Kafka クラスターが作成されます。 [Cluster Login User Name](クラスター ログイン ユーザー名) Spark クラスターと Kafka クラスターの管理者のユーザー名。 [クラスター ログイン パスワード] Spark クラスターと Kafka クラスターの管理者のユーザー パスワード。 [SSH ユーザー名] Spark クラスターと Kafka クラスターの作成に使用する SSH ユーザー。 [SSH パスワード] Spark クラスターと Kafka クラスター用の SSH ユーザーのパスワード。 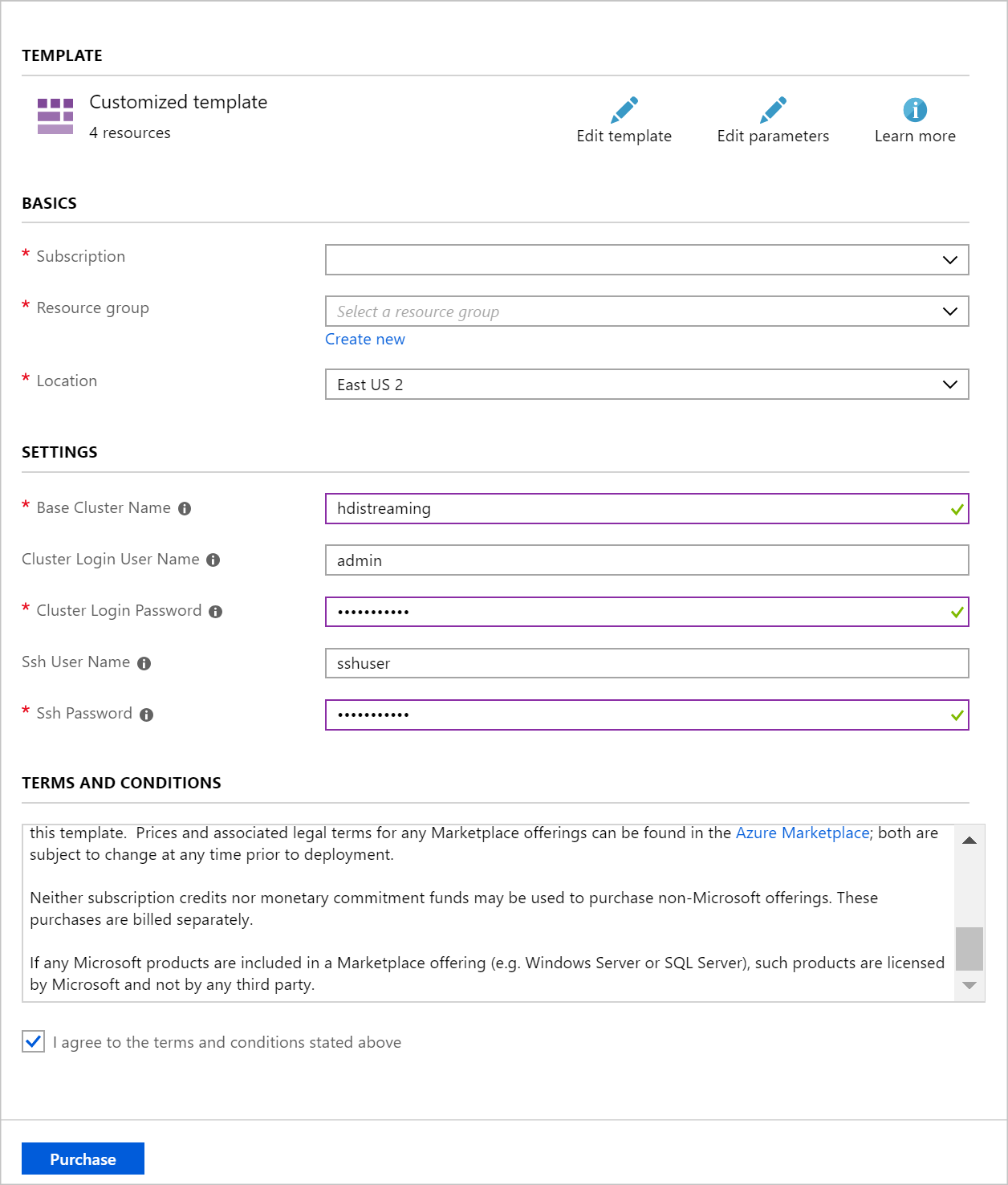
使用条件を読み、 [上記の使用条件に同意する] をオンにします。
最後に、 [購入] を選択します。 クラスターの作成には約 20 分かかります。
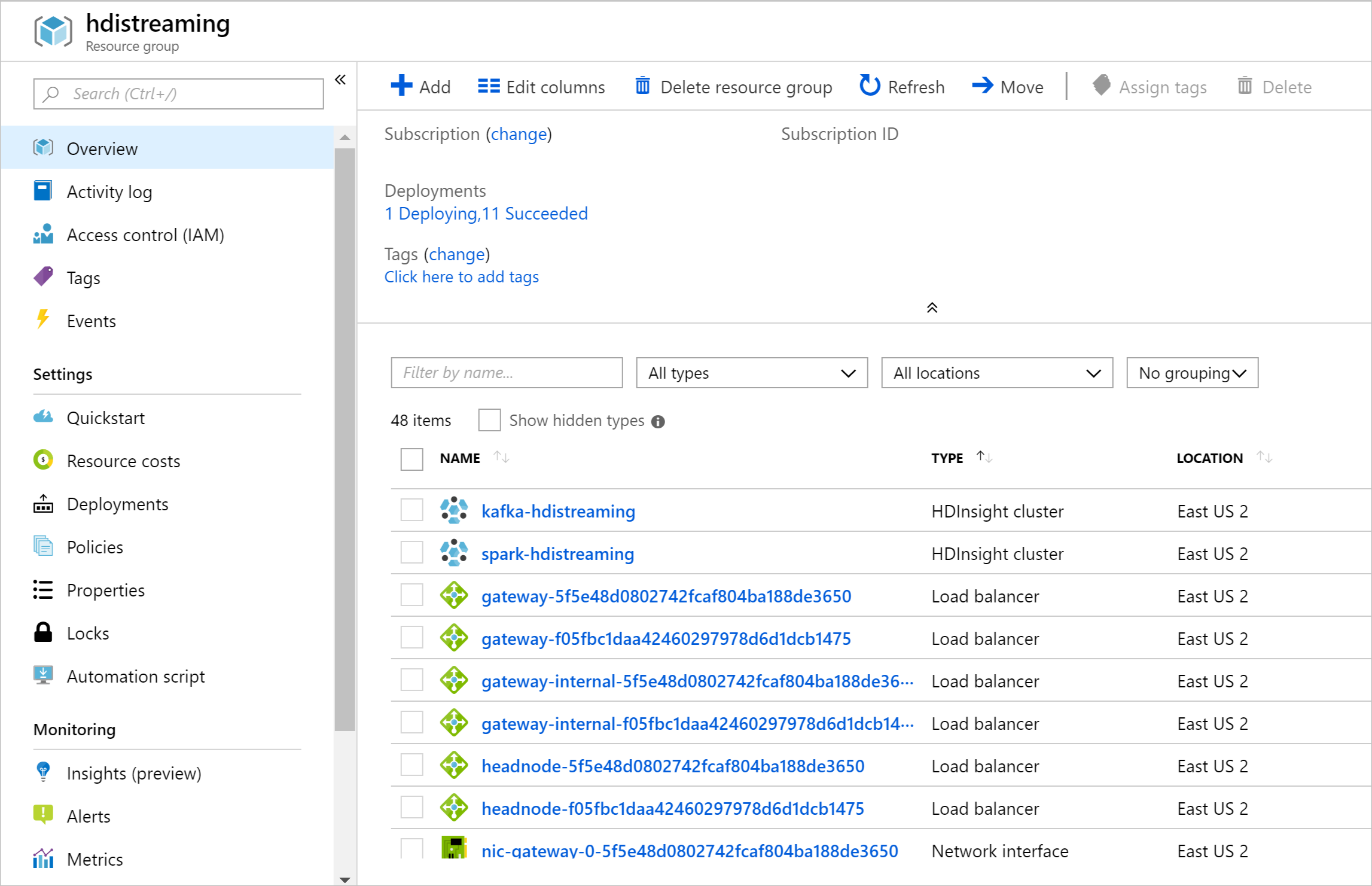
リソースが作成されると、概要ページが表示されます。
重要
各 HDInsight クラスターの名前が spark-BASENAME および kafka-BASENAME であることに注目してください。BASENAME はテンプレートで指定した名前です。 これらの名前は、後の手順でクラスターに接続するときに使用します。
ノートブックを使用する
このドキュメントで説明した例のコードは、https://github.com/Azure-Samples/hdinsight-spark-scala-kafka で入手できます。
クラスターを削除する
警告
HDInsight クラスターの料金は、そのクラスターを使用しているかどうかに関係なく、分単位で課金されます。 使用後は、クラスターを必ず削除してください。 「HDInsight クラスターを削除する方法」をご覧ください。
このドキュメントの手順では両方のクラスターを同じ Azure リソース グループに作成したため、Azure Portal でこのリソース グループを削除するだけで済みます。 グループを削除することにより、このドキュメントに従って作成したすべてのリソース、Azure Virtual Network、クラスターで使用したストレージ アカウントが削除されます。
次のステップ
この例では、Spark を使用して Kafka に対するデータの読み取りと書き込みを行う方法について説明しました。 次のリンクを使用することで、Kafka のその他の活用方法を知ることができます。