MirrorMaker を使用して HDInsight 上の Kafka に Apache Kafka トピックをレプリケートする
Apache Kafka のミラーリング機能を使用して、セカンダリ クラスターにトピックをレプリケートする方法について説明します。 ミラーリングはクラスター間でデータを移行するために、継続的なプロセスとして実行したり断続的に実行したりすることができます。
この記事では、ミラーリングを使用して、2 つの HDInsight クラスター間でトピックをレプリケートします。 これらのクラスターは、異なるデータセンター内の異なる仮想ネットワーク内にあります。
警告
フォールトトレランスを実現するための手段としてミラーリングを使用しないでください。 トピック内の項目へのオフセットは、プライマリ クラスターとセカンダリ クラスターによって異なるため、クライアントはこれら 2 つを入れ替えて使用することはできません。 フォールト トレランスを考慮する場合は、クラスター内のトピックをレプリケートする設定にします。 詳しくは、「HDInsight での Apache Kafka の概要」をご覧ください。
Apache Kafka のミラーリングのしくみ
ミラーリングは、Apache Kafka に含まれている MirrorMaker ツールを使用して動作します。 MirrorMaker はプライマリ クラスター上のトピックからレコードを取り込んで、セカンダリ クラスター上にローカル コピーを作成します。 MirrorMaker では、プライマリ クラスターから読み取りを行う 1 つ (あるいは複数) のコンシューマーと、ローカル (セカンダリ) クラスターへの書き込みを行うプロデューサーを使用します。
ディザスター リカバリーに最も役立つミラーリングの設定では、異なる Azure リージョンの Kafka クラスターを使用します。 これを実現するには、クラスターが存在する仮想ネットワークをピアリングします。
次の図は、ミラーリング プロセスとクラスター間で通信がどのように流れるかを示しています。
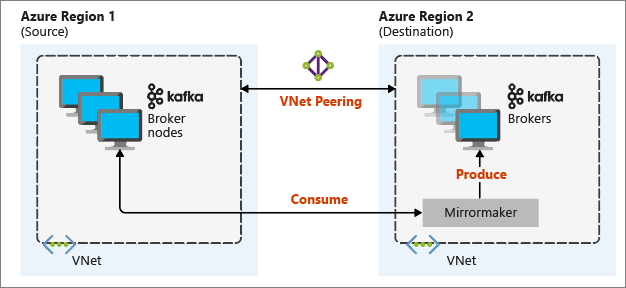
プライマリ クラスターとセカンダリ クラスターでは、ノードとパーティションの数、およびトピック内のオフセットが異なります。 ミラーリングではパーティション分割に使用するキー値が保持されるため、レコードの順序はキー単位で保存されます。
ネットワーク境界を超えたミラーリング
異なるネットワークの Kafka クラスター間でミラーリングの必要がある場合には、次の追加の考慮事項があります。
ゲートウェイ:ネットワークは、TCP/IP レベルで通信できる必要があります。
サーバー アドレス指定: IP アドレスまたは完全修飾ドメイン名を使用して、クラスター ノードのアドレスを指定することができます。
IP アドレス: IP アドレスのアドバタイジングを使用するように Kafka クラスターを構成する場合は、ブローカー ノードと ZooKeeper ノードの IP アドレスを使用してミラーリングのセットアップを続行することができます。
ドメイン名: IP アドレスのアドバタイジングを行うように Kafka クラスターを構成しない場合、クラスターは完全修飾ドメイン名 (FQDN) を使用して相互に接続できる必要があります。 そのためには、要求を他のネットワークに転送するように構成された各ネットワークに、ドメイン ネーム システム (DNS) サーバーが必要です。 Azure Virtual Network を作成するときに、ネットワークで自動的に提供される DNS を使用せず、カスタムの DNS サーバーおよびサーバーの IP アドレスを指定する必要があります。 仮想ネットワークを作成したら、その IP アドレスを使用する Azure 仮想マシンを作成する必要があります。 そこに DNS ソフトウェアをインストールして構成します。
重要
カスタム DNS サーバーの作成と構成は、HDInsight を仮想ネットワークにインストールする前に行うようにします。 HDInsight が仮想ネットワーク用に構成された DNS サーバーを使用するために必要な、追加の構成はありません。
2 つの Azure 仮想ネットワークを接続する方法の詳細については、接続の構成に関する記事を参照してください。
ミラーリング アーキテクチャ
このアーキテクチャの特徴は、リソース グループと仮想ネットワークが異なる 2 つのクラスター、すなわちプライマリとセカンダリがあることです。
作成手順
2 つの新しいリソース グループを作成します。
Resource group 場所 kafka-primary-rg 米国中部 kafka-secondary-rg 米国中北部 kafka-primary-rg に新しい仮想ネットワーク kafka-primary-vnet を作成します。 既定の設定のままにします。
kafka-secondary-rg に新しい仮想ネットワーク kafka-secondary-vnet を作成します。こちらも既定の設定を使用します。
2 つの新しい Kafka クラスターを作成します。
クラスター名 Resource group 仮想ネットワーク ストレージ アカウント kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage 仮想ネットワークのピアリングを作成します。 この手順では、2 つのピアリングを作成します。1 つは kafka-primary-vnet から kafka-secondary-vnet に向かうもの、もう 1 つは kafka-secondary-vnet から kafka-primary-vnet に戻るものです。
kafka-primary-vnet 仮想ネットワークを選択します。
[設定] で [ピアリング] を選択します。
[追加] を選択します。
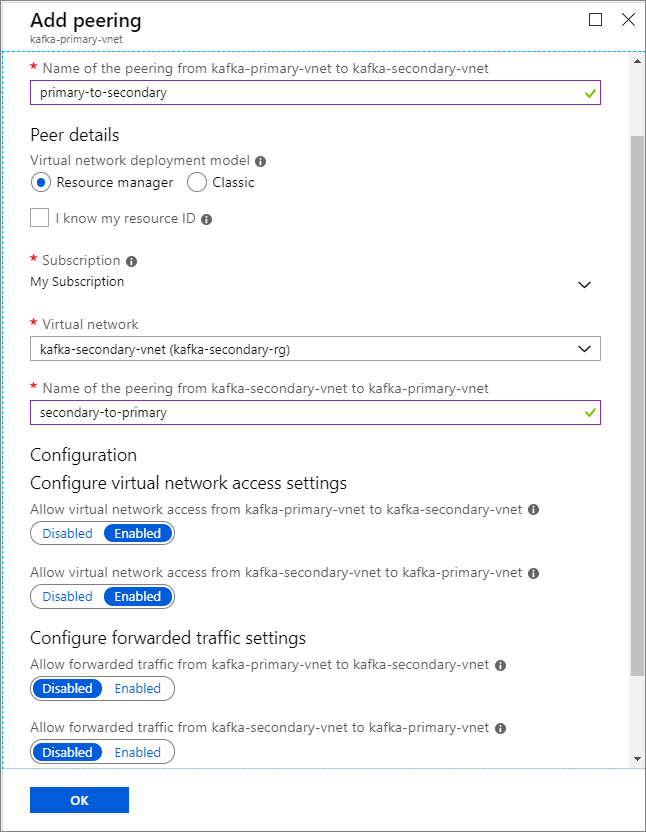
[ピアリングの追加] 画面で、次のスクリーンショットに示すように詳細を入力します。
IP アドバタイズを構成する
クライアントでドメイン名の代わりにブローカー IP アドレスを使用して接続を行えるように、IP アドバタイズを構成します。
https://PRIMARYCLUSTERNAME.azurehdinsight.netからプライマリ クラスターの Ambari ダッシュボードに移動します。[サービス]>[Kafka] を選択します。 [Configs] タブをクリックします。
kafka env テンプレート セクションの一番下に次の構成行を追加します。 [保存] を選択します。
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.properties[構成の保存] 画面でメモを入力し、[保存] を選択します。
構成の警告が表示された場合は、[Proceed Anyway](警告を無視して続行) を選択します。
[Save Configuration Changes](構成の変更を保存) の [OK] を選択します。
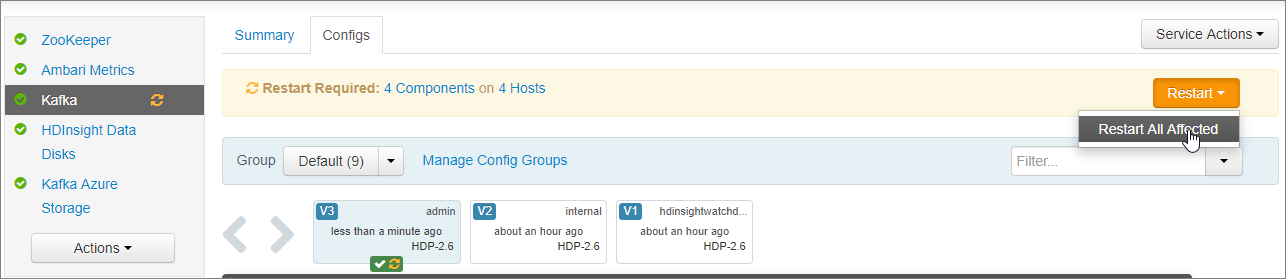
再起動が必要通知の [Restart](再起動)>[Restart All Affected](影響を受けるものをすべて再起動) を選択します。 続けて、[Confirm Restart All](すべて再起動) を選択します。
すべてのネットワーク インターフェイスをリッスンするように Kafka を構成する
-
[サービス]>[Kafka] の [構成] タブにとどまります。
[Kafka Broker](Kafka ブローカー) セクションで、リスナー プロパティを
PLAINTEXT://0.0.0.0:9092に設定します。 - [保存] を選択します。
- [Restart](再起動)>[Confirm Restart All](すべて再起動) を選択します。
プライマリ クラスターのブローカーの IP アドレスと ZooKeeper アドレスを記録します。
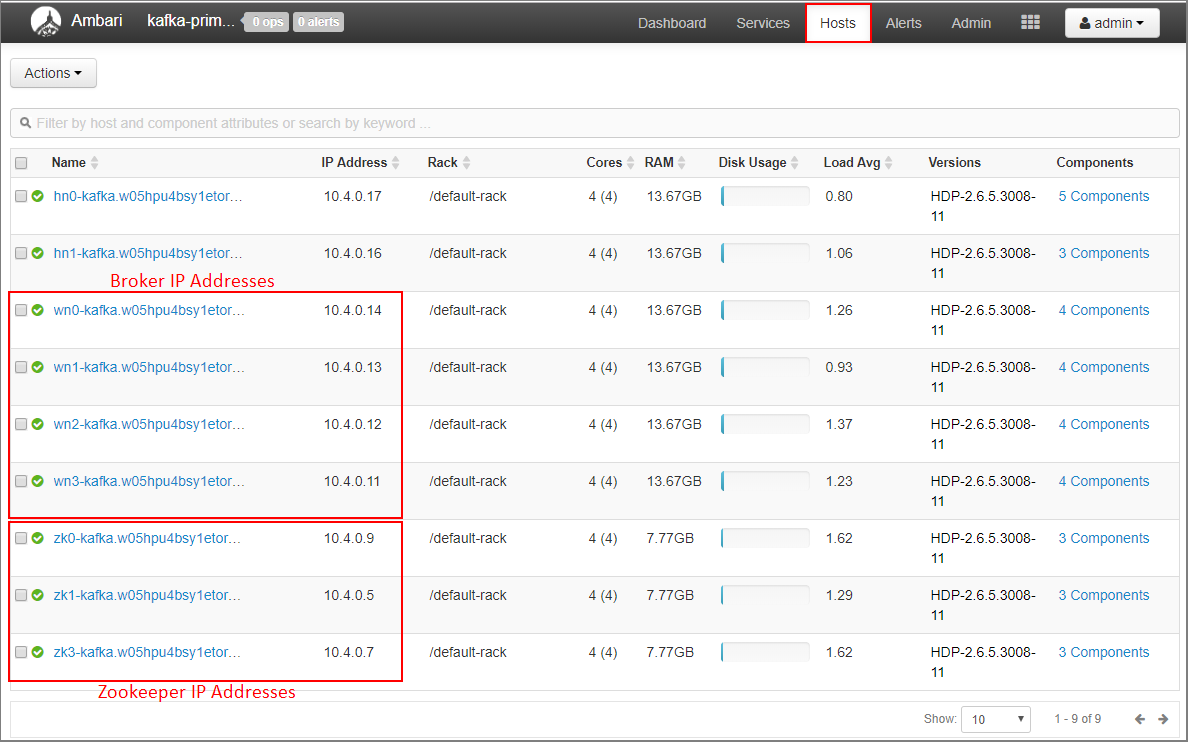
Ambari ダッシュボードの [ホスト] を選択します。
ブローカーと ZooKeeper の IP アドレスをメモしておきます。 ブローカー ノードのホスト名の最初の 2 文字は wnZooKeeper ノードのホスト名の最初 2 文字は zk です。
2 番目のクラスター kafka-secondary-cluster に対して前の 3 つの手順を繰り返します。IP アドバタイズを構成し、リスナーを設定して、ブローカーと ZooKeeper の IP アドレスをメモします。
トピックの作成
SSH を使用してプライマリ クラスターに接続します。
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netsshuserは、クラスターの作成時に使用した SSH ユーザー名に置き換えます。PRIMARYCLUSTERは、クラスターの作成時に使用したベース名に置き換えます。詳細については、HDInsight での SSH の使用に関するページを参照してください。
次のコマンドを使用して、プライマリ クラスターの Apache ZooKeeper ホストとブローカー ホストを格納した 2 つの環境変数を作成します。
ZOOKEEPER_IP_ADDRESS1などの文字列は、10.23.0.11や10.23.0.7など、先ほど記録した実際の IP アドレスに置き換える必要があります。 同じことがBROKER_IP_ADDRESS1にも当てはまります。 カスタム DNS サーバーで FQDN 解決を使用している場合は、こちらの手順に従ってブローカーと ZooKeeper の名前を取得します。# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'testtopicという名前のトピックを作成するには、次のコマンドを使います。/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSトピックが作成されたことを確認するには、次のコマンドを使用します。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTS応答には
testtopicが含まれます。次を使用して、この (プライマリ) クラスターのブローカー ホスト情報を表示します。
echo $PRIMARY_BROKERHOSTS次のテキストのような情報が返されます。
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092この情報は保存してください。 これは、次のセクションで使用されます。
ミラーリングの構成
別の SSH セッションを使用してセカンダリ クラスターに接続します。
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netsshuserは、クラスターの作成時に使用した SSH ユーザー名に置き換えます。SECONDARYCLUSTERは、クラスターの作成時に使用した名前に置き換えます。詳細については、HDInsight での SSH の使用に関するページを参照してください。
consumer.propertiesファイルを使用して、プライマリ クラスターとの通信を構成します。 ファイルを作成するには、次のコマンドを使います。nano consumer.propertiesconsumer.propertiesファイルの内容として、次のテキストを使用します。bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupPRIMARY_BROKERHOSTSは、プライマリ クラスターのブローカー ホストの IP アドレスに置き換えてください。このファイルには、プライマリ Kafka クラスターからの読み取りに使用するコンシューマー情報を記述します。 詳細については、
kafka.apache.orgの「コンシューマーの構成」を参照してください。ファイルを保存するには、Ctrl + X キー、Y キー、Enter キーの順に押します。
セカンダリ クラスターと通信するプロデューサーを構成する前に、セカンダリ クラスターのブローカーの IP アドレスに使用する変数を設定します。 以下のコマンドを使用して、この変数を作成します。
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'コマンド
echo $SECONDARY_BROKERHOSTSは、次のテキストのような情報を返します。10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092セカンダリ クラスターと通信するには、
producer.propertiesファイルを使用します。 ファイルを作成するには、次のコマンドを使います。nano producer.propertiesproducer.propertiesファイルの内容として、次のテキストを使用します。bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=none前の手順で使用したブローカーの IP アドレスで
SECONDARY_BROKERHOSTSを置き換えます。詳細については、
kafka.apache.orgの「プロデューサーの構成」を参照してください。セカンダリ クラスターの ZooKeeper ホストの IP アドレスを格納する環境変数を作成するには、次のコマンドを使用します。
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'HDInsight の Kafka に使用される既定の構成では、トピックの自動作成が許可されません。 ミラーリング プロセスを開始する前に、次のいずれかの方法を選択する必要があります。
セカンダリ クラスターにトピックを作成する:この方法を選択した場合、パーティション数とレプリケーション係数も設定することができます。
次のコマンドを使用して事前にトピックを作成することができます。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTStesttopicは、作成するトピックの名前に置き換えます。トピックを自動的に作成するようにクラスターを構成する: この方法を選択した場合、MirrorMaker によって自動的にトピックが作成されます。 ただし、それらと共に作成されるパーティションの数またはレプリケーション係数が、プライマリのトピックとは異なる場合があります。
トピックを自動的に作成するようにセカンダリ クラスターを構成するには、次の手順を実行します。
-
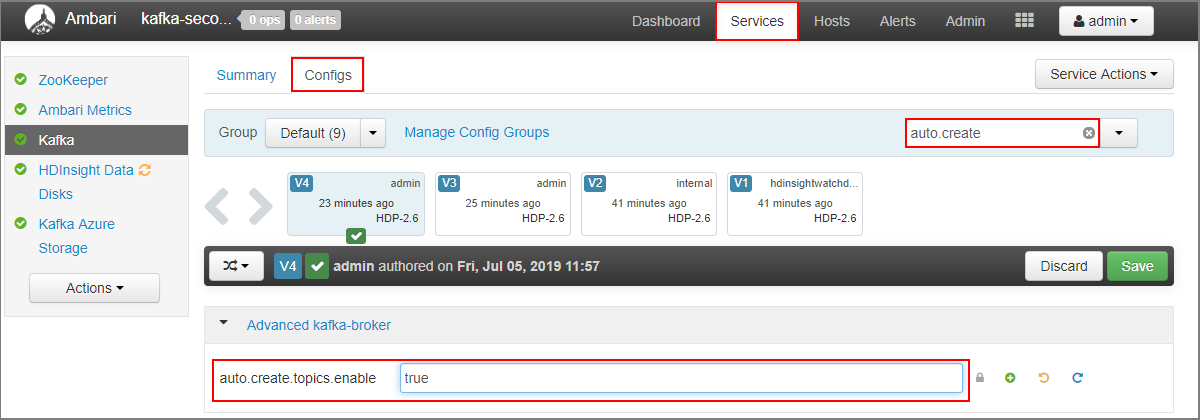
https://SECONDARYCLUSTERNAME.azurehdinsight.netからセカンダリ クラスターの Ambari ダッシュボードに移動します。 - [サービス]>[Kafka] を選択します。 次に、[Configs](構成) タブを選択します。
-
[フィルター] フィールドに
auto.createの値を入力します。 プロパティの一覧にフィルターが適用されてauto.create.topics.enable設定が表示されます。 -
auto.create.topics.enableの値をtrueに変更して、[保存] を選択します。 ノートを追加して、もう一度 [保存] を選択します。 - Kafka サービスを選択し、 [Restart](再起動) を選択して、 [Restart all affected](影響を受けるものをすべて再起動) を選択します。 メッセージが表示されたら、 [Confirm restart all](すべて再起動) を選択します。
-
MirrorMaker の開始
Note
この記事には、Microsoft が使用しなくなった用語への言及が含まれています。 この用語は、ソフトウェアから削除された時点でこの記事から削除されます。
セカンダリ クラスターに SSH で接続してから、次のコマンドを使用して MirrorMaker プロセスを開始します。
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4この例で使用するパラメーターは次のとおりです。
パラメーター 説明 --consumer.configコンシューマーのプロパティを格納するファイルを指定します。 これらのプロパティは、プライマリ Kafka クラスターから読み取りを行うコンシューマーの作成に使用します。 --producer.configプロデューサーのプロパティを格納するファイルを指定します。 これらのプロパティは、セカンダリ Kafka クラスターへの書き込みを行うプロデューサーの作成に使用します。 --whitelistMirrorMaker がプライマリ クラスターからセカンダリ クラスターにレプリケートするトピックの一覧。 --num.streams作成するコンシューマー スレッドの数。 現在、セカンダリ ノードのコンシューマーは、メッセージの受信を待機しています。
プライマリ クラスターに SSH で接続してから、次のコマンドを使用して、プロデューサーを起動し、トピックにメッセージを送信します。
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicカーソル付きの空白行が表示されたら、テキスト メッセージを数個入力します。 これらのメッセージは、プライマリ クラスター上のトピックに送信されます。 操作が完了したら、Ctrl + C キーを押してプロデューサーのプロセスを終了します。
セカンダリ クラスターに SSH で接続してから、Ctrl + C キーを押して MirrorMaker プロセスを終了します。 このプロセスは、終了までに数秒かかる場合があります。 メッセージがセカンダリにレプリケートされたことを確認するには、次のコマンドを使います。
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningこれで、MirrorMaster がトピックをプライマリ クラスターからセカンダリにミラーリングしたときに作成された
testtopicが、トピックの一覧に含まれるようになりました。 このトピックから取得するメッセージは、プライマリ クラスターで入力したものと同じです。
クラスターを削除する
警告
HDInsight クラスターの料金は、そのクラスターを使用しているかどうかに関係なく、分単位で課金されます。 使用後は、クラスターを必ず削除してください。 「HDInsight クラスターを削除する方法」をご覧ください。
この記事の手順では、別の Azure リソース グループにクラスターを作成しました。 作成されたすべてのリソースを削除するには、作成した 2 つのリソース グループ kafka-primary-rg および kafka-secondary-rg を削除します。 リソース グループを削除すると、この記事に従って作成したすべてのリソースが削除されます。これには、クラスター、仮想ネットワーク、ストレージ アカウントなどが含まれます。
次のステップ
この記事では、MirrorMaker を使用して Apache Kafka クラスターのレプリカを作成する方法について説明しました。 次のリンクを使用することで、Kafka のその他の活用方法を知ることができます。