Azure HDInsight における Apache Hive メモリ不足エラーの解決
大きなテーブルを処理するときに Apache Hive で発生するメモリ不足 (OOM) エラーを、Hive のメモリ設定を構成することによって解決する方法を紹介します。
大きなテーブルに対して Apache Hive クエリを実行する
ユーザーが次の Hive クエリを実行したとします。
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
このクエリの特徴:
- T1 は、STRING 型の列が多数ある大きなテーブル TABLE1 のエイリアスです。
- その他のテーブルはそれほど大きくはありませんが、多数の列があります。
- すべてのテーブルは相互に結合されています。場合によっては、TABLE1 などのテーブルにある複数の列によって結合されています。
この Hive クエリは、24 ノードの A3 HDInsight クラスターで完了までに 26 分かかりました。 ユーザーは、次の警告メッセージを確認しています。
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Apache Tez 実行エンジンを使用したところ、 同じクエリの実行時間が 15 分となり、次のエラーがスローされました。
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
より大きな仮想マシン (D12 など) を使ってもエラーは解消されません。
メモリ不足エラーのデバッグ
弊社サポート チームとエンジニアリング チームが共同で調査にあたったところ、メモリ不足エラーを引き起こしている問題の 1 つは、Apache JIRA で説明されている既知の問題であることを発見しました。
"hive.auto.convert.join.noconditionaltask = true の場合は noconditionaltask.size を確認し、マップ結合のテーブルサイズの合計が noconditionaltask.size よりも小さい場合、プランによってマップ結合が生成されます。ここで問題は、計算では異なるハッシュテーブル実装によって発生するオーバーヘッドを考慮しないため、その結果、入力サイズが nonconditionaltask のサイズより少しでも小さい場合、クエリは OOM をヒットします。
hive-site.xml ファイルの hive.auto.convert.join.noconditionaltask が true に設定されていました。
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Java ヒープ領域のメモリ不足エラーの原因は、おそらく Map Join にあると考えられます。 HDInsight の Hadoop Yarn メモリ設定に関するブログの投稿で説明したように、Tez 実行エンジンを使用すると、使用されるヒープ領域は、実際には Tez コンテナーに属します。 Tez コンテナー メモリについて説明した次の図を参照してください。
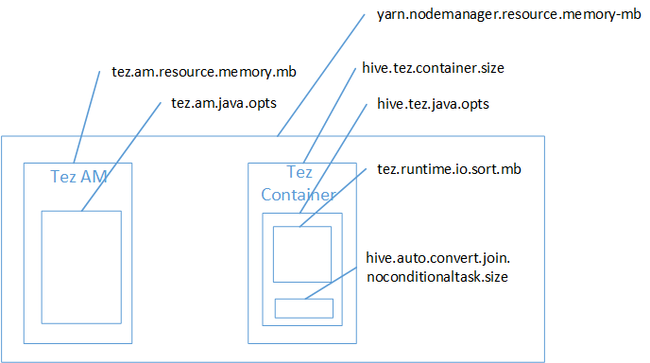
ブログの投稿で提案したように、hive.tez.container.size と hive.tez.java.opts という 2 つのメモリ設定で、ヒープのコンテナー メモリを定義しています。 経験から判断すると、メモリ不足例外の原因は、コンテナー サイズが小さすぎることではありません。 Java ヒープ サイズ (hive.tez.java.opts) が小さすぎることが原因です。 そのため、メモリ不足エラーが発生する場合は、hive.tez.java.opts を増やしてみてください。 必要に応じて、 hive.tez.container.sizeも増やす必要があります。 java.opts 設定は、container.size の約 80% にすることをお勧めします。
注意
hive.tez.java.opts は、常に hive.tez.container.size よりも小さく設定する必要があります。
D12 コンピューターには 28 GB のメモリがあるので、10 GB (10,240 MB) のコンテナー サイズを使用し、80% を java.opts に割り当てることにしました。
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
この新しい設定では、クエリが 10 分間未満で正常に実行されました。
次のステップ
OOM エラーの原因は、必ずしもコンテナー サイズが小さすぎるためではありません。 コンテナー サイズではなくヒープ サイズを増やし、コンテナー メモリ サイズの 80% 以上を割り当てるようにメモリ設定を構成することをお勧めします。 Hive クエリの最適化については、「HDInsight の Apache Hadoop に対する Apache Hive クエリの最適化」を参照してください。