Azure HDInsight での Apache Hive クエリの最適化
この記事では、Apache Hive クエリのパフォーマンスを向上させるために使用できる、最も一般的なパフォーマンスの最適化について説明します。
クラスターの種類の選択
Azure HDInsight では、いくつかの異なるクラスター タイプに対して、Apache Hive クエリを実行できます。
ワークロードのニーズに合わせてパフォーマンスを最適化するには、次のように適切なクラスター タイプを選択します。
ad hoc対話型クエリ用に最適化するには、Interactive Query クラスター タイプを選択します。- バッチ処理として使用される Hive クエリ用に最適化するには、Apache Hadoop クラスター タイプを選択します。
- Spark および HBase クラスター型でも、Hive クエリを実行でき、これらのワークロードを実行している場合は、適切な場合があります。
Hive クエリを実行するための各種 HDInsight クラスター タイプについて詳しくは、「Azure HDInsight における Apache Hive と HiveQL」をご覧ください。
ワーカー ノードのスケール アウト
HDInsight クラスター内のワーカー ノードの数を増やすと、並列に実行される mapper や reducer を作業でより多く使用できるようになります。 HDInsight でスケールを向上させる方法が 2 つあります。
クラスターを作成する場合は、Azure portal、Azure PowerShell、またはコマンド ライン インターフェイスを使用してワーカー ノードの数を指定できます。 詳細については、HDInsight クラスターの作成に関するページを参照してください。 次のスクリーンショットは、Azure Portal 上に表示されたワーカー ノード構成を示しています。
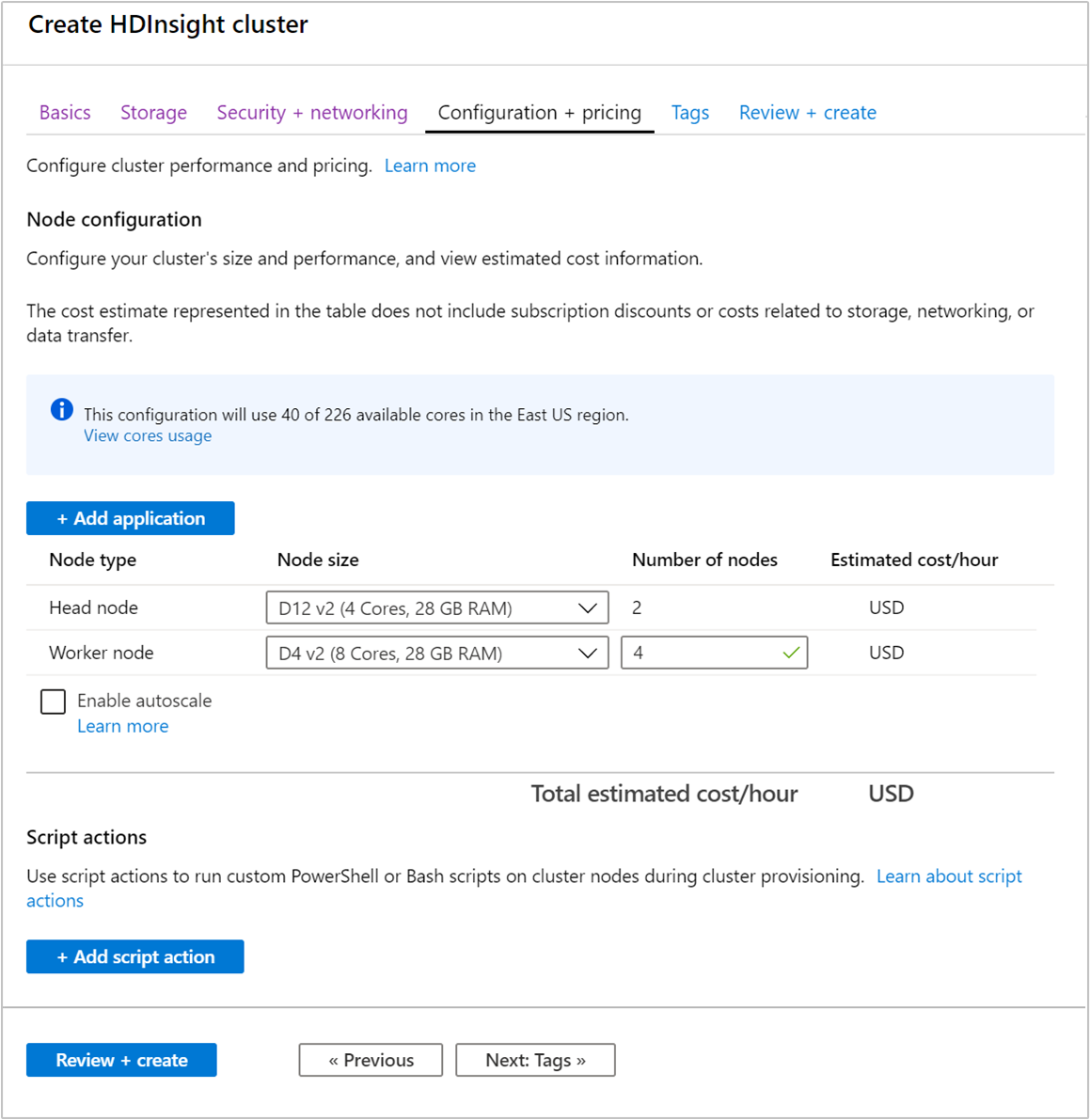
作成後にワーカー ノードの数を編集して、クラスターを再作成せずにスケールアウトすることもできます。
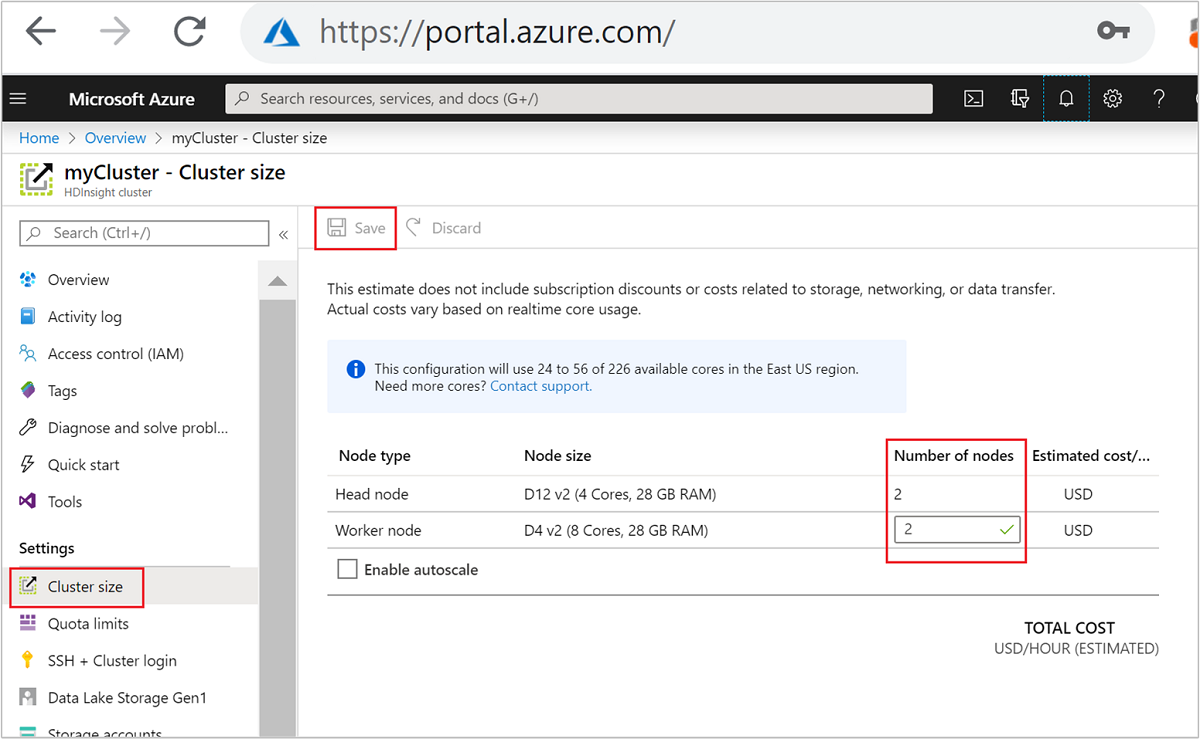
HDInsight のスケーリングについて詳しくは、HDInsight クラスターのスケーリングに関するページをご覧ください
Map Reduce の代わりに Apache Tez を使用する
Apache Tez は、MapReduce エンジンに代わる実行エンジンです。 Linux ベースの HDInsight クラスターでは、Tez は既定で有効になっています。

Tez はより高速です。それは次の理由によります。
- MapReduce エンジンで、有向非巡回グラフ (DAG) を 1 つのジョブとして実行します。 DAG では、mapper の各セットの後に 1 セットの reducer が続く必要があります。 この要件により、Hive クエリごとに複数の MapReduce ジョブがスピンオフされます。 Tez にはこのような制約がなく、複雑な DAG を 1 つのジョブとして処理できるため、ジョブ起動のオーバーヘッドが最小限に抑えられます。
- 不要な書き込みを回避できます。 MapReduce エンジンでは、同じ Hive クエリを 処理するために複数のジョブが使用されます。 各 MapReduce ジョブの出力は、中間データとして HDFS に書き込まれます。 Tez によって各 Hive クエリのジョブの数が最小限に抑えられるので、不要な書き込みを回避することができます。
- 起動時の遅延を最小限に抑えられます。 Tez は、開始に必要な mapper の数を削減することによって、また全体的な最適化を向上させることによって、起動時の遅延を最小限に抑えることができます。
- コンテナーを再利用できます。 コンテナーの起動からの待ち時間が確実に削減されるように、Tez では可能なときは常にコンテナーを再利用します。
- 継続的な最適化手法を使用します。 これまで、最適化はコンパイル フェーズで行われていました。 しかし最適化を向上させるための入力に関する詳細は、実行時に入手できます。 Tez は、実行時フェーズでプランをさらに最適化する継続的な最適化手法を使用します。
この概念の詳細については、Apache TEZ のサイトを参照してください。
次の set コマンドでクエリにプレフィックスを付けることで、Hive クエリで Tez を有効にできます。
set hive.execution.engine=tez;
Hive パーティション分割
I/O 操作は、Hive クエリを実行するための主なパフォーマンスのボトルネックです。 読み取る必要があるデータの量を削減することで、パフォーマンスを向上することができます。 既定では、Hive クエリは、全 Hive テーブルをスキャンします。 少量のデータのみのスキャンが必要なクエリ (フィルターを使用するクエリなど) では、不要なオーバーヘッドが発生します。 Hive パーティション分割では、Hive クエリは Hive テーブルの必要な量のデータだけにアクセスします。
Hive パーティション分割は、生データを新しいディレクトリに再編成することによって実装されます。 各パーティションには、独自のファイル ディレクトリが編成されます。 パーティション分割はユーザーが定義します。 次の図は、列 Year による Hive テーブルのパーティション分割を示しています。 年ごとに新しいディレクトリが作成されます。
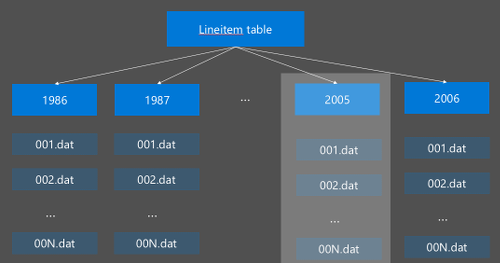
パーティション分割に関するいくつかの考慮事項:
- パーティションの数を少なくしすぎない - 少数の値しかない列をパーティション分割すると、パーティションの数が少なくなる場合があります。 たとえば、性別をパーティション分割すると 2 つのパーティション (男性と女性) しか作成されないため、待ち時間は最大で半分しか短縮されません。
- パーティションの数を多くしすぎない - もう一方の極端な例として、一意の値 (userid など) を含む列でパーティションを作成すると、複数のパーティションが生成されます。 これでは、多数のディレクトリを処理する必要があるため、クラスター namenode に多大なストレスを与えることになります。
- データのスキューを回避する - すべてのパーティションのサイズが均等になるよう、注意深くパーティショニング キーを選択します。 たとえば、State 列をパーティション分割すると、データの分布が偏る可能性があります。 カリフォルニア州の人口はバーモント州の約 30 倍なので、パーティションのサイズが偏り、パフォーマンスの差が大変大きくなる可能性があります。
パーティション テーブルを作成するには、 Partitioned By 句を使用します。
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
パーティション テーブルが作成されれば、静的パーティションまたは動的パーティションのいずれかを作成できるようになります。
静的パーティション分割とは、データを適切なディレクトリに既にシャード化していることを意味します。 静的パーティションでは、ディレクトリの場所に基づいて Hive パーティションを手動で追加します。 次のコード スニペットに例を示します。
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'動的パーティション分割 では、Hive に自動的にパーティションを作成させます。 ステージング テーブルからパーティショニング テーブルを既に作成しているので、あとはパーティション テーブルにデータを挿入するだけです。
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
詳細については、「Partitioned Tables (パーティション テーブル)」を参照してください。
ORCFile 形式の使用
Hive は、さまざまなファイル形式をサポートしています。 次に例を示します。
- テキスト: 既定のファイル形式で、ほとんどのシナリオで使用できます。
- Avro: 相互運用性シナリオで使用できます。
- ORC/Parquet: 最も高いパフォーマンスを発揮します。
ORC (最適化行多桁式) 形式は、Hive データを格納する非常に効率的な方法です。 他の形式と比べて、ORC には次の利点があります。
- 複合型 (DateTime、複合構造化型、および半構造化型を含む) のサポート。
- 最大で 70% の圧縮。
- 10,000 行ごとのインデックス作成 (これにより行のスキップが可能)。
- 実行時の実行の大幅な削除。
ORC 形式を有効にするにはまず、 Stored as ORC句でテーブルを作成します。
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
次に、データをステージング テーブルから ORC テーブルに挿入します。 次に例を示します。
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
ORC 形式の詳細については、Apache Hive 言語マニュアルで説明されています。
ベクター化
ベクター化により、Hive は、一度に 1 行を処理する代わりに、1024 行を一括処理することができます。 つまり、単純な操作では、実行に必要な内部コードが少なくなるため、処理が速くなります。
Hive クエリのベクター化プレフィックスを有効にするには、次の設定を使用します。
set hive.vectorized.execution.enabled = true;
詳細については、「Vectorized query execution (ベクター化されたクエリ実行)」を参照してください。
その他の最適化の方法
その他にも考慮できる最適化の方法がいくつかあります。たとえば、次のような方法です。
- Hive のバケット: 大きなデータ セットをクラスター化またはセグメント化してクエリのパフォーマンスを最適化するための手法です。
- 結合の最適化: 結合の効率を向上させユーザー ヒントの必要性を少なくするための Hive のクエリ実行プランの最適化です。 詳しくは、「Join optimization (結合の最適化)」を参照してください。
- Reducer の増加。
次のステップ
この記事ではいくつかの一般的な Hive クエリの最適化方法を説明しました。 詳細については、以下の記事をお読みください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示