Azure HDInsight クラスターを手動でスケーリングする
HDInsight は柔軟性を備えており、クラスター内のワーカー ノード数をスケールアップおよびスケールダウンするオプションがあります。 この柔軟性により、数時間後や週末にクラスターを縮小することができます。 また、ビジネス需要のピーク時に拡張できます。
定期的なバッチ プロセスの前には、クラスターをスケールアップしてクラスターに十分なリソースを確保するようにします。 プロセスが完了し、使用量が減少したら、HDInsight クラスターをスケールダウンしてワーカー ノードを減らします。
以下のいずれかの方法を使用して、クラスターを手動でスケーリングできます。 また、自動スケーリング オプションを使用して、特定のメトリックに応じて自動的にスケールアップおよびスケールダウンすることもできます。
注意
HDInsight バージョン 3.1.3 以降を使用しているクラスターのみがサポートされます。 クラスターのバージョンがわからない場合、[プロパティ] ページを確認できます。
クラスターをスケーリングするユーティリティ
Microsoft では、クラスターをスケーリングするための次のユーティリティを提供しています。
| ユーティリティ | 説明 |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Azure CLI | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Azure クラシック CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure Portal | HDInsight クラスターのウィンドウを開き、左側のメニューの [クラスター サイズ] を選択し、[クラスター サイズ] ウィンドウでワーカー ノードの数を入力して、[保存] を選択します。 |
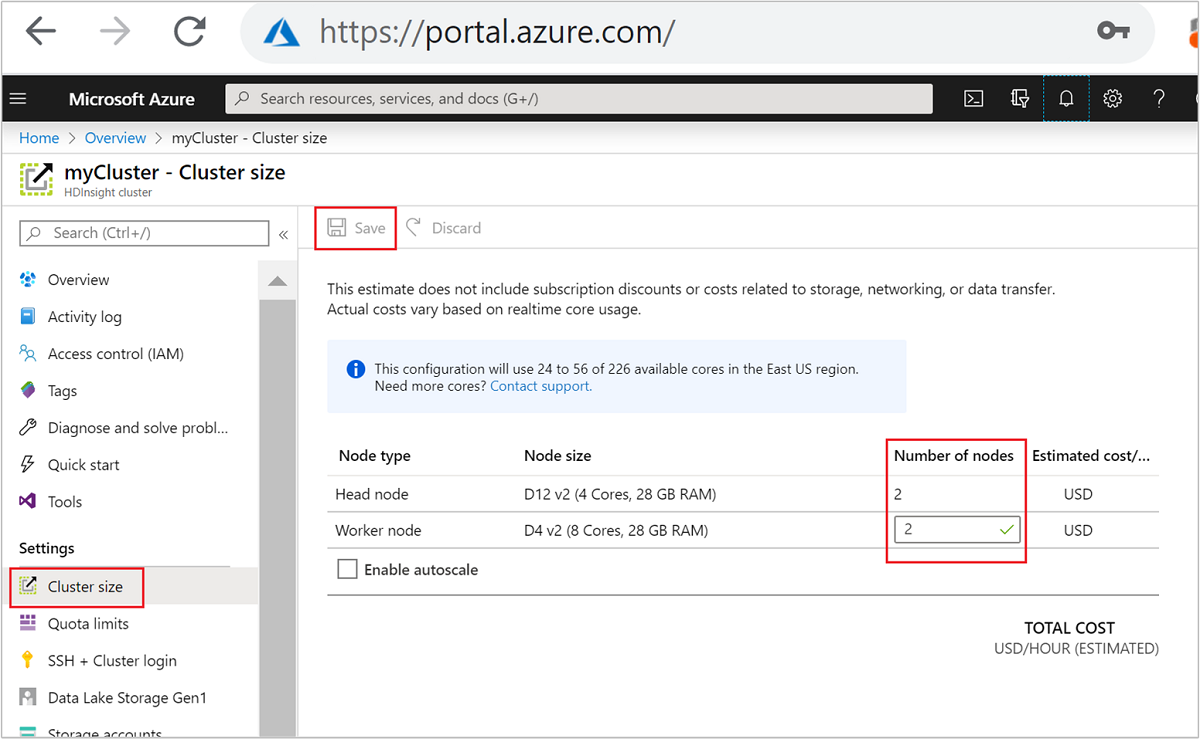
これらの方法のいずれかを使用すると、HDInsight クラスターを数分以内にスケールアップまたはスケールダウンできます。
重要
スケーリング操作の影響
実行中の HDInsight クラスターにノードを追加 (スケールアップ) しても、ジョブは影響を受けません。 スケーリング処理の実行中に新しいジョブを安全に送信できます。 スケーリング操作が失敗しても、その失敗がクラスターの機能状態に影響することはありません。
ノードを削除 (スケールダウン) すると、保留中または実行中のジョブは、スケーリング操作の完了時に失敗します。 この失敗の原因は、スケーリング処理中にいくつかのサービスが再起動されることにあります。 手動によるスケーリング操作中に、クラスターがセーフ モードで停止することがあります。
データ ノード数を変更した場合の影響は、HDInsight でサポートされているクラスターの種類ごとに異なります。
Apache Hadoop
ジョブに影響を与えることなく、実行中の Hadoop クラスター内のワーカー ノード数をシームレスに増やすことができます。 処理の進行中に新しいジョブを送信することもできます。 スケーリング操作の失敗は正常に処理されます。 クラスターは常に機能状態のままになります。
Hadoop クラスターのデータ ノード数を減らしてスケールダウンすると、一部のサービスは再起動されます。 この動作により、スケール設定処理の完了時に、実行中および保留中のすべてのジョブが失敗します。 ただし、処理が完了した後にジョブを再送信できます。
Apache HBase
実行中の HBase クラスターに対して、ノードの追加または削除をシームレスに実行できます。 地域サーバーは、スケール設定処理の完了の数分以内に自動的に分散されます。 ただし、リージョン サーバーの負荷分散を手動で調整することができます。 クラスター ヘッドノードにログインし、次のコマンドを実行します。
pushd %HBASE_HOME%\bin hbase shell balancerHBase シェルの使用の詳細については、「HDInsight で Apache HBase の例を使用する」を参照してください。
Note
Kafka クラスターでは適用できません。
Apache Hive LLAP
N個のワーカー ノードにスケーリングした後、HDInsight は自動的に以下の構成を設定し、Hive を再起動します。- 同時実行クエリの最大合計数:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Hive の LLAP で使用されるノードの数:
num_llap_nodes = N - Hive LLAP デーモンを実行するためのノードの数:
num_llap_nodes_for_llap_daemons = N
- 同時実行クエリの最大合計数:
クラスターを安全にスケールする方法
ジョブを実行してクラスターをスケールダウンする
スケールダウン操作中に実行中のジョブが失敗するのを回避するため、次の 3 つのことを試すことができます。
- ジョブが完了するのを待ってから、クラスターをスケールダウンする。
- ジョブを手動で終了する。
- スケーリング操作の完了後に、ジョブを再送信する。
保留中または実行中のジョブの一覧を表示するには、次の手順に従って YARN Resource Manager UI を使用できます。
Azure portal でご自身のクラスターを選択します。 このクラスターは、新しいポータル ページで開かれます。
メイン ビューから、 [クラスター ダッシュボード]>[Ambari ホーム] に移動します。 クラスターの資格情報を入力します。
Ambari UI から、左側のメニューにあるサービスの一覧で [YARN] を選択します。
[YARN] ページから [クイック リンク] を選択し、アクティブなヘッド ノードにポインターを置き、 [Resource Manager UI] を選択します。
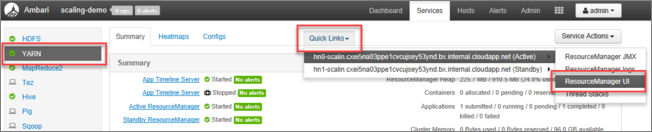
https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster を使用すると Resource Manager UI に直接アクセスできます。
ジョブの一覧が、現在の状態と共に表示されます。 このスクリーンショットでは、現在実行中のジョブが 1 つあります。
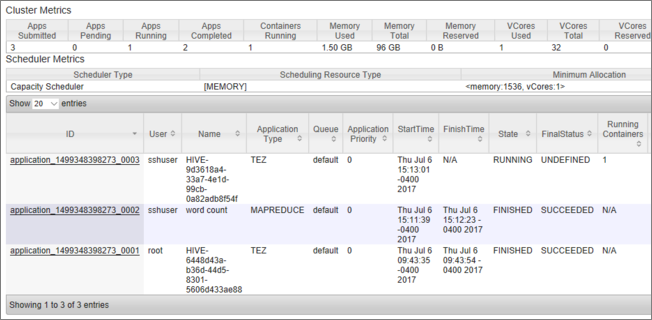
その実行中のアプリケーションを手動で中止するには、SSH シェルから次のコマンドを実行します。
yarn application -kill <application_id>
次に例を示します。
yarn application -kill "application_1499348398273_0003"
セーフ モードでスタックする
クラスターをスケールダウンすると、まず余分なワーカー ノードの使用を停止するために、HDInsight では Apache Ambari 管理インターフェイスが使用されます。 ノードによって、その HDFS ブロックが他のオンライン ワーカー ノードにレプリケートされます。 その後、HDInsight によってクラスターが安全にスケールダウンされます。 スケーリング操作時に HDFS はセーフ モードに切り替わります。 スケーリングが完了すると HDFS は復帰するはずです。 ただし、場合によっては、レプリケーション中のファイル ブロックが原因で、スケーリング操作中に HDFS がセーフ モードでスタックします。
既定では、HDFS は 1 の dfs.replication 設定 (各ファイル ブロックの使用可能なコピーの数を制御する) で構成されます。 ファイル ブロックの各コピーは、クラスターの別々のノードに格納されます。
想定されている数のブロックのコピーが使用できない場合、HDFS はセーフ モードになり、Ambari によってアラートが生成されます。 HDFS は、スケーリング操作のためにセーフ モードに切り替わる場合があります。 必要な数のノードがレプリケーション用に検出されない場合、クラスターはセーフ モードで停止する可能性があります。
セーフ モードがオンになっている場合のエラーの例
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
/var/log/hadoop/hdfs/ フォルダーから、クラスターがスケーリングされた時刻付近の名前ノード ログを確認すると、セーフ モードに入った時刻がわかります。 ログ ファイルの名前は Hadoop-hdfs-namenode-<active-headnode-name>.* です。
根本的な原因は、クエリの実行中に Hive が HDFS の一時ファイルに依存していることでした。 HDFS がセーフ モードになると、Hive は HDFS に書き込めなくなるため、クエリを実行できません。 HDFS 内の一時ファイルは、個々のワーカー ノード VM にマウントされているローカル ドライブに配置されます。 これらのファイルは、他のワーカー ノードの少なくとも 3 つのレプリカにレプリケートされます。
HDInsight がセーフ モードでスタックするのを防ぐ方法
HDInsight がセーフ モードのままにならないようにする方法はいくつかあります。
- HDInsight をスケールダウンする前にすべての Hive ジョブを停止します。 または、実行中の Hive ジョブとの競合を回避するようにスケールダウン処理をスケジュールします。
- スケールダウンする前に、HDFS 内にある Hive のスクラッチ
tmpディレクトリ ファイルを手動でクリーンアップします。 - HDInsight を最低 3 つのワーカー ノードにスケールダウンするだけです。 ワーカー ノードが 1 つにならないようにします。
- 必要に応じて、セーフ モードを終了するコマンドを実行します。
以下のセクションでは、これらのオプションについて説明します。
すべての Hive ジョブを停止する
すべての Hive ジョブを停止してから、1 つのワーカー ノードにスケールダウンします。 ワークロードがスケジュールされている場合は、Hive の処理が完了した後でスケールダウンします。
スケーリングの前に Hive ジョブを停止することで、tmp フォルダー内のスクラッチ ファイルの数を最小限に抑えることができます。
Hive のスクラッチ ファイルを手動でクリーンアップする
Hive で一時ファイルが残っている場合は、これらのファイルを手動でクリーンアップしてからスケールダウンすることで、セーフ モードを回避できます。
hive.exec.scratchdir構成プロパティを見て、Hive の一時ファイルに使用されている場所を確認します。 このパラメーターは/etc/hive/conf/hive-site.xml内で設定されます。<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Hive サービスを停止し、すべてのクエリとジョブが完了していることを確認します。
上記で見つかったスクラッチ ディレクトリ
hdfs://mycluster/tmp/hive/のコンテンツを一覧表示して、ファイルが含まれているかどうかを確認します。hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveファイルが存在する場合の出力例は次のとおりです。
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoHive がこれらのファイルの処理を終了していることがわかっている場合は、これらを削除できます。 Yarn Resource Manager UI のページを見て、Hive で実行中のクエリがないことを確認してください。
HDFS からファイルを削除するコマンドラインの例:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
HDInsight を 3 つ以上のワーカー ノードにスケーリングする
ワーカー ノードを 3 つ未満にスケールダウンすると、クラスターがセーフ モードで頻繁に停止する場合は、3 つ以上のワーカー ノードを保持します。
3 つのワーカー ノードを持つことは、1 つのワーカー ノードのみにスケールダウンするよりもコストがかかります。 しかし、このアクションにより、クラスターがセーフ モードで停止するのを防ぐことができます。
HDInsight を 1 つのワーカー ノードにスケール ダウンする
クラスターのノード数を 1 個までスケールダウンしても、ワーカー ノード 0 は存続します。 ワーカー ノード 0 を使用停止にすることはできません。
セーフ モードを終了するコマンドを実行する
最後のオプションは、セーフ モードを終了するコマンドを実行することです。 レプリケーション対象の Hive ファイルがあるために HDFS がセーフ モードに切り替わった場合は、次のコマンドを実行してセーフ モードを終了します。
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Apache HBase クラスターをスケールダウンする
リージョン サーバーは、スケーリング操作の完了から数分以内に自動的に調整されます。 リージョン サーバーを手動で調整するには、次の手順を完了します。
SSH を使用して HDInsight クラスターに接続します。 詳細については、HDInsight での SSH の使用に関するページを参照してください。
HBase シェルを起動します。
hbase shell次のコマンドを使用して、リージョン サーバーを手動で調整します。
balancer
次のステップ
HDInsight クラスターのスケーリングに関する具体的な情報については、以下を参照してください。