Azure HDInsight は、マネージドの、全範囲に対応した、クラウド上のオープンソースのエンタープライズ向け分析サービスです。 HDInsight を使用すると、Azure 環境で Apache Spark、Apache Hive、LLAP、Apache Kafka、Hadoop などのオープン ソース フレームワークを使用できます。
HDInsight および Hadoop テクノロジ スタックとは
Azure HDInsight は、Apache Spark、Apache Hive、LLAP、Apache Kafka、Apache Hadoop などのビッグ データ フレームワークを Azure 環境で簡単に実行できるようにするマネージド クラスター プラットフォームです。 大量のデータを高速かつ効率的に処理できるように設計されています。
どのようなときに Azure HDInsight を使用するか
| 機能 | 説明 |
|---|---|
| クラウド ネイティブ | Azure HDInsight を使うと、Spark、Interactive query (LLAP)、Kafka、HBase、Hadoop のための最適化されたクラスターを Azure 上に作成できます。 また、HDInsight は、あらゆる運用環境のワークロードについてエンド ツー エンドの SLA を提供します。 |
| 低コストでスケーラブル | HDInsight では、ワークロードをスケールアップまたはスケールダウンできます。 クラスターをオンデマンドで作成し、実際に使用する分にのみ支払うことでコストを削減できます。 データ パイプラインを作成して、必要なジョブを運用化することもできます。 コンピューティングとストレージが分離され、より高いパフォーマンスと柔軟性が実現されています。 |
| セキュリティとコンプライアンス | HDInsight を使用すると、Azure Virtual Network、暗号化、Microsoft Entra ID との統合によって、企業のデータ資産を保護することができます。 また HDInsight は、業界や行政上の最も一般的なコンプライアンス基準を満たしています。 |
| 監視 | Azure HDInsight と Azure Monitor ログの統合によって、すべてのクラスターを監視できる一元化されたインターフェイスが得られます。 |
| グローバル対応 | HDInsight は、他のあらゆるビッグ データ分析サービスより多くのリージョンで提供されています。 Azure HDInsight は、Azure Government、Azure China、Azure Germany でも提供されており、独自の法令が施行されている地域における企業のニーズに応えます。 |
| 生産性 | Azure HDInsight を使用すると、お好みの開発環境で Hadoop および Spark 向けの豊富な生産性ツールを利用できます。 これらの開発環境には、Visual Studio、VS Code、Eclipse、および IntelliJ for Scala、Python、Java、.NET サポートが含まれます。 |
| 拡張性 | スクリプト アクションを使ったり、エッジ ノードを追加したり、定評のある他のビッグ データ アプリケーションと連携したりすることで、インストールされたコンポーネント (Hue、Presto など) で HDInsight のクラスターを拡張することができます。 HDInsight は、特に普及率の高いビッグ データ ソリューションとワンクリック デプロイでシームレスに連携します。 |
ビッグ データとは
収集されるビッグ データの量は膨れ上がっています。その勢いはしだいに増し、以前よりも形式も多様化しています。 ビッグ データの種類には、履歴データ (つまり、保存されたデータ) とリアルタイム データ (つまり、ソースからストリーミングされるデータ) があります。 ビッグ データの最も一般的な使用例については、「HDInsight を使用するシナリオ」をご覧ください。
HDInsight でのクラスターの種類
HDInsight には、特定のクラスターの種類のほか、コンポーネント、ユーティリティ、および言語を追加する機能などのクラスター カスタマイズ機能が含まれています。 HDInsight は、次のクラスターの種類を提供します。
| クラスターの種類 | 説明 | 作業を開始する |
|---|---|---|
| Apache Hadoop | HDFS、YARN によるリソース管理、およびシンプルな MapReduce プログラミング モデルを使用して、バッチ データを同時に処理および分析するフレームワークです。 | Apache Hadoop クラスターを作成する |
| Apache Spark | ビッグ データ分析アプリケーションのパフォーマンスを向上させるメモリ内処理をサポートする、オープンソースの並列処理フレームワークです。 HDInsight での Apache Spark の概要に関する記事を参照してください。 | Apache Spark クラスターの作成 |
| Apache HBase | Hadoop 上に構築された NoSQL データベースです。数十億行 x 数百万列に達する可能性のある大量の非構造化データや半構造化データへのランダム アクセスと厳密な整合性を実現します。 HDInsight での HBase の概要に関する記事を参照してください。 | Apache HBase クラスターを作成する |
| Apache 対話型クエリ | 対話型で高速な Hive クエリのメモリ内キャッシュです。 HDInsight での対話型クエリの使用に関する記事を参照してください。 | 対話型クエリ クラスターの作成 |
| Apache Kafka | オープンソース プラットフォームは、ストリーミング データ パイプラインおよびアプリケーションを構築するために使用されます。 Kafka には、データ ストリームの発行とサブスクライブを可能にするメッセージ キュー機能も用意されています。 「HDInsight での Apache Kafka の概要」を参照してください。 | Apache Kafka クラスターを作成する |
HDInsight を使用するシナリオ
Azure HDInsight は、ビッグ データ 処理のさまざまなシナリオに使用できます。 ビッグ データは履歴データ (既に収集され保存されているデータ) である場合もあれば、リアルタイム データ (ソースから直接ストリーミングされるデータ) である場合もあります。 そのようなデータの処理に関するシナリオは、次のカテゴリに集約することができます。
バッチ処理 (ETL)
ETL (抽出、変換、読み込み) は、異種データ ソースから非構造化データまたは構造化データを抽出する処理です。 その後、構造化された形式に変換して、データ ストアに読み込みます。 変換後のデータは、データ サイエンスやデータ ウェアハウジングに使用することができます。
データ ウェアハウス
HDInsight を使用して、あらゆる形式の構造化データや非構造化データに対話型クエリをペタバイト規模で実行することができます。 それらを BI ツールに接続するモデルを作成することもできます。
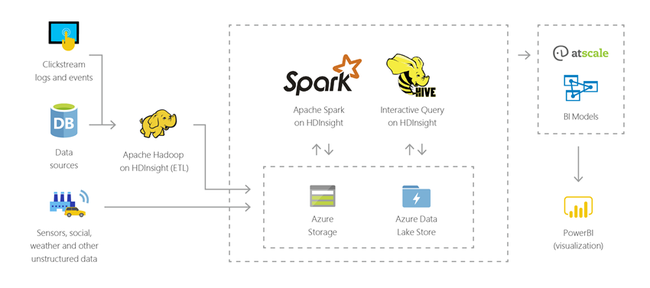
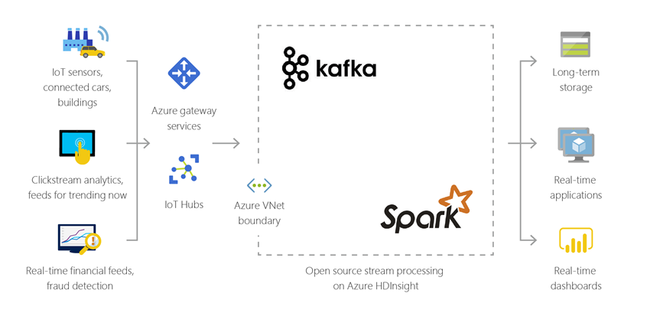
モノのインターネット(IoT)
さまざまなデバイスからリアルタイムで受信したストリーミング データを HDInsight を使用して処理することができます。 詳細については、Azure マネージド ディスクを使用した HDInsight での Apache Kafka のパブリック プレビューを知らせる Azure のブログ記事を参照してください。
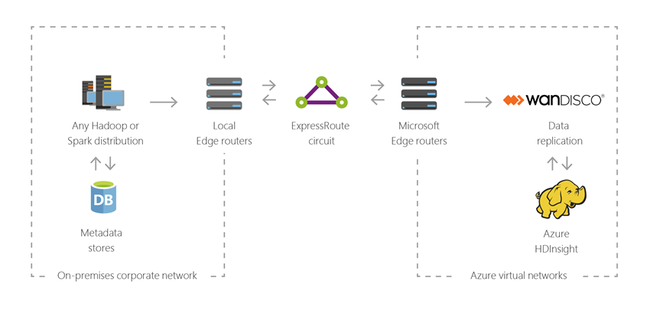
ハイブリッド
HDInsight を使用して、既にあるオンプレミスのビッグ データ インフラストラクチャを Azure にまで拡張し、そのクラウドの高度な分析機能を適用できます。
HDInsight のオープンソース コンポーネント
Azure HDInsight では、Spark、Hive、LLAP、Kafka、Hadoop、HBase などのオープンソース フレームワークを使ってクラスターを作成できます。 これらのクラスターには、既定で、Apache Ambari、Avro、Apache Hive 3、HCatalog、Apache Hadoop MapReduce、Apache Hadoop YARN、Apache Phoenix、Apache Pig、Apache Sqoop、Apache Tez、Apache Oozie、Apache ZooKeeper などのさまざまなオープンソース コンポーネントが含まれています。
HDInsight のプログラミング言語
HDInsight クラスター (Spark、HBase、Kafka、Hadoopなど) は多数のプログラミング言語をサポートします。 既定でインストールされないプログラミング言語があります。 既定でインストールされないライブラリ、モジュール、またはパッケージは、スクリプト アクションを使用してコンポーネントをインストールします。
| プログラミング言語 | Information |
|---|---|
| 既定のプログラミング言語のサポート | 既定では、HDInsight クラスターは以下をサポートします。
|
| Java 仮想マシン (JVM) 言語 | Java 以外の多くの言語を Java 仮想マシン (JVM) で実行できます。 ただし、これらの言語の一部を実行する場合は、クラスターにさらに多くのコンポーネントをインストールする必要があります。 次の JVM ベースの言語が HDInsight クラスターでサポートされます。
|
| Hadoop 固有言語 | HDInsight クラスターでは、Hadoop テクノロジ スタックに固有の次の言語をサポートしています。
|
HDInsight 用の開発ツール
HDInsight のデータ クエリやジョブは、Azure とシームレスに統合された HDInsight の開発ツール (IntelliJ、Eclipse、Visual Studio Code、Visual Studio) を使用して作成、送信することができます。
- Azure toolkit for IntelliJ 10
- Azure toolkit for Eclipse 6
- Azure HDInsight tools for VS Code 13
- Azure data lake tools for Visual Studio 9
HDInsight のビジネス インテリジェンス
Power Query アドインまたは Microsoft Hive ODBC ドライバーを使用すれば、使い慣れたビジネス インテリジェンス (BI) ツールを HDInsight と連携して、データの取得、分析、レポート生成を行うことができます。
Azure HDInsight の Microsoft Power BI で Apache Hive データを視覚化する
Power Query を使用した Excel から Apache Hadoop への接続 (Windows が必要)
Microsoft Hive ODBC Driver を使用した Excel から Apache Hadoop への接続 (Windows が必要)
リージョンのデータ所在地
Spark、Hadoop、LLAP は、顧客データを格納しないため、これらのサービスは、Azure グローバル インフラストラクチャ サイトで指定されているリージョン内のデータ所在地要件を自動的に満たします。
Kafka と HBase は顧客データを格納します。 このデータは、Kafka および HBase によって 1 つのリージョンに自動的に格納されるため、このサービスは、Azure グローバル インフラストラクチャ サイトで指定されているリージョンのデータ所在地の要件を満たします。
Power Query アドインまたは Microsoft Hive ODBC ドライバーを使用すれば、使い慣れたビジネス インテリジェンス (BI) ツールを HDInsight と連携して、データの取得、分析、レポート生成を行うことができます。
次のステップ
- HDInsight で Apache Hadoop クラスターを作成する
- Apache Spark クラスターの作成 - ポータル
- Azure HDInsight のエンタープライズ セキュリティ