リアルタイムのビッグ データ ソリューションは、移動中のデータに作用します。 通常、このデータは到着時に最も価値があります。 受信データ ストリームがその時点で処理できる値を超える場合は、リソースの調整が必要になる場合があります。 または、HDInsight クラスターは、オンデマンドでノードを追加することで、ストリーミング ソリューションを満たすようにスケールアップできます。
ストリーミング アプリケーションでは、1 つ以上のデータ ソースが、有用な情報を削除することなく迅速に取り込む必要があるイベント (1 秒あたり数百万単位) を生成しています。 受信イベントは、Apache Kafka や Event Hubs などのサービスによって、ストリーム バッファリング (イベント キューとも呼ばれます) で処理されます。 イベントを収集したら、 ストリーム処理 レイヤー内のリアルタイム分析システムを使用してデータを分析できます。 処理されたデータは、 Azure Data Lake Storage などの長期的なストレージ システムに格納し、 Power BI、Tableau、カスタム Web ページなどのビジネス インテリジェンス ダッシュボードにリアルタイムで表示できます。
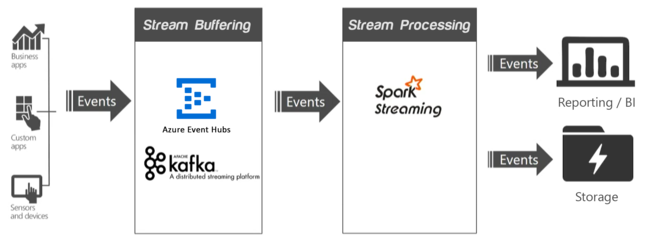
Apache Kafka
Apache Kafka は、高スループットで待ち時間の短いメッセージ キュー サービスを提供し、現在はオープン ソース ソフトウェア (OSS) の Apache スイートの一部です。 Kafka は、発行とサブスクライブのメッセージング モデルを使用し、パーティション分割されたデータのストリームを、分散されたレプリケートされたクラスターに安全に格納します。 Kafka は、スループットの増加に応じて直線的にスケーリングされます。
詳細については、 HDInsight での Apache Kafka の概要に関する記事を参照してください。
Spark Streaming
Spark Streaming は Spark の拡張機能であり、バッチ処理に使用するのと同じコードを再利用できます。 バッチ クエリと対話型クエリの両方を同じアプリケーションで組み合わせることができます。 Spark とは異なり、ストリーミングではステートフルな処理セマンティクスが 1 回だけ提供されます。 Kafka Direct API と組み合わせて使用することで、Spark ストリーミングで受信したすべての Kafka データを正確に 1 回処理することが保証されるため、エンドツーエンドの「exactly once」保証を実現することができます。 Spark Streaming の長所の 1 つはフォールト トレラント機能であり、クラスター内で複数のノードが使用されている場合に障害が発生したノードを迅速に復旧します。
詳細については、「 Apache Spark Streaming とは」を参照してください。
クラスターのスケーリング
作成中にクラスター内のノードの数を指定できますが、ワークロードに合わせてクラスターを拡大または縮小することもできます。 すべての HDInsight クラスターでは、 クラスター内のノード数を変更できます。 すべてのデータは Azure Storage または Data Lake Storage に格納されるため、Spark クラスターはデータを失う必要なく削除できます。
テクノロジを分離する利点があります。 たとえば、Kafka はイベント バッファリング テクノロジであるため、IO が非常に多く、処理能力があまり必要ありません。 これに対し、Spark Streaming などのストリーム プロセッサはコンピューティング集中型であり、より強力な VM が必要です。 これらのテクノロジを異なるクラスターに分離することで、VM を最大限に活用しながら、それらを個別にスケーリングできます。
ストリーム バッファリング レイヤーをスケーリングする
Event Hubs と Kafka のストリーム バッファリング テクノロジはどちらもパーティションを使用し、コンシューマーはそれらのパーティションから読み取ります。 入力スループットをスケーリングするには、パーティションの数をスケールアップする必要があり、パーティションを追加すると並列処理が増加します。 Event Hubs では、デプロイ後にパーティション数を変更できないため、ターゲット スケールを念頭に置いて開始することが重要です。 Kafka では、Kafka がデータを処理している間でもパーティションを 追加できます。 Kafka には、パーティションを再割り当てするツールが用意 kafka-reassign-partitions.sh。 HDInsight には、 パーティション レプリカの再調整ツール ( rebalance_rackaware.py) が用意されています。 この再調整ツールは、各レプリカが個別の障害ドメインと更新ドメイン内にあるように kafka-reassign-partitions.sh ツールを呼び出し、Kafka ラックを認識し、フォールト トレランスを高める方法です。
ストリーム処理レイヤーをスケーリングする
Apache Spark Streaming では、データの処理中でも、クラスターへのワーカー ノードの追加がサポートされます。
Apache Spark では、アプリケーションの要件に応じて、 spark.executor.instances、 spark.executor.cores、 spark.executor.memoryの 3 つの主要なパラメーターを使用して環境を構成します。
Executor は、Spark アプリケーション用に起動されるプロセスです。 Executor はワーカー ノード上で実行され、アプリケーションのタスクを実行する役割を担います。 各クラスターの Executor の既定の数と Executor のサイズは、ワーカー ノードの数とワーカー ノードのサイズに基づいて計算されます。 これらの番号は、各クラスター ヘッド ノードの spark-defaults.conffile に格納されます。
これら 3 つのパラメーターは、クラスター で実行されるすべてのアプリケーションに対してクラスター レベルで構成でき、個々のアプリケーションごとに指定することもできます。 詳細については、「 Apache Spark クラスターのリソースの管理」を参照してください。