Azure HDInsight ゲートウェイ (ゲートウェイ) は、HDInsight クラスターの HTTPS フロントエンドです。 ゲートウェイは、最新の分散システムに必要な認証、ホスト解決、サービス検出、およびその他の便利な機能を担当します。 ゲートウェイで提供される機能のため、このドキュメントで、それらについて参照すべきベスト プラクティスを説明するといういくらかの負担が発生します。 ゲートウェイのトラブルシューティング方法についても説明します。
HDInsight ゲートウェイ
HDInsight ゲートウェイは、インターネット経由でパブリックにアクセスできる HDInsight クラスターの唯一の部分です。 ゲートウェイ サービスには、パブリック インターネットを経由せずに、clustername-int.azurehdinsight.net 内部ゲートウェイ エンドポイントを使用してアクセスできます。 内部ゲートウェイ エンドポイントによって、クラスターの仮想ネットワークを終了せずに、ゲートウェイ サービスへの接続を確立できます。 ゲートウェイでは、クラスターに送信されたすべての要求を処理し、そのような要求を正しいコンポーネントおよびクラスター ホストに転送します。
次の図は、HDInsight 内のさまざまなすべてのホスト解決の可能性の前に、ゲートウェイがどのように抽象化を提供するかを大ざっぱに示しています。
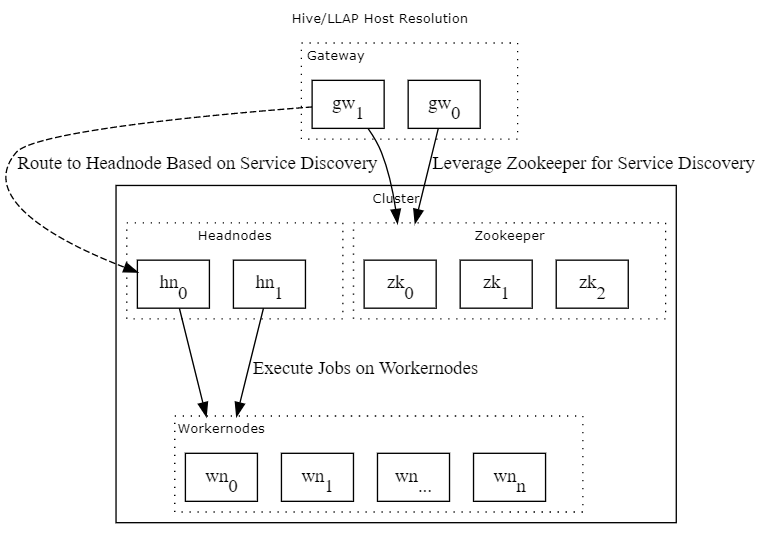
目的
HDInsight クラスターの前にゲートウェイを配置する目的は、サービス検出とユーザー認証のためのインターフェイスを提供することです。 ゲートウェイによって提供される認証メカニズムは、特に ESP 対応のクラスターに関連しています。
サービス検出の場合、ゲートウェイの利点は、多数の host:port のペアとは対照的に、クラスター内の各コンポーネントに、ゲートウェイ Web サイト (clustername.azurehdinsight.net/hive2) でさまざまなエンドポイントとしてアクセスできることです。
認証の場合、ゲートウェイによって、ユーザーは username:password 資格情報のペアを使用して、認証できます。 ESP 対応クラスターの場合、この資格情報はユーザーのドメイン ユーザー名とパスワードになります。 ゲートウェイ経由での HDInsight クラスターへの認証では、クライアントが kerberos チケットを取得する必要はありません。 ゲートウェイは username:password の資格情報を受け入れ、ユーザーに代わってユーザーの Kerberos チケットを取得するため、(ESP) クラスターと異なる AA DDS ドメインに参加しているクライアントなど、任意のクライアント ホストからゲートウェイへのセキュリティで保護された接続を確立できます。
ベスト プラクティス
ゲートウェイは、要求の転送と認証を担当する単一のサービス (2 つのホスト間で負荷分散された) です。 ゲートウェイは、特定のサイズを超えるハイブ クエリ対して、スループットのボトルネックになる可能性があります。 ODBC または JDBC を介して、きわめて大きな SELECT クエリがゲートウェイで実行されると、クエリ パフォーマンスの低下が見られることがあります。 "きわめて大きい" とは、行または列に対して 5 GB を超えるデータで構成されるクエリを意味します。 このクエリには、長い行のリストや幅広い列数が含まれている可能性があります。
大きなサイズのクエリに関するゲートウェイのパフォーマンスの低下は、基になるデータ ストア (ADLS Gen2) から、HDInsight Hive サーバー、ゲートウェイ、最終的に JDBC または ODBC ドライバーを介して、クライアント ホストまでデータを転送する必要があるためです。
次の図は、SELECT クエリで必要な手順を示しています。
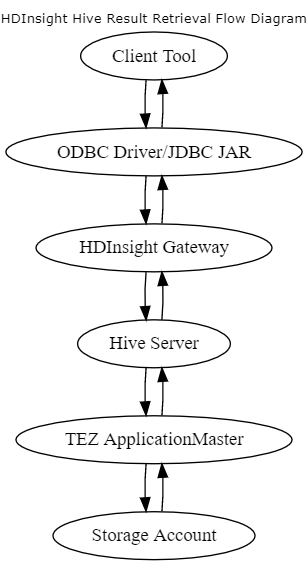
Apache Hive は、HDFS と互換性のあるファイルシステム上のリレーショナル抽象化です。 この抽象化は、Hive 内の SELECT ステートメントが、ファイルシステム上の READ 操作に対応することを意味します。 READ 操作は、ユーザーに報告される前に適切なスキーマに変換されます。 このプロセスの待機時間は、データのサイズとエンド ユーザーに到達するために必要な合計ホップ数によって増加します。
これらのコマンドは、基になるファイル システムの WRITE 操作に対応するため、大きなデータの CREATE または INSERT ステートメントの実行時に、同様の動作が発生する可能性があります。 生の ORC などのデータを、INSERT または LOAD を使用して読み込むのではなく、filesystem/datalake に書き込むことを検討してください。
Enterprise Security Pack 対応のクラスターでは、十分に複雑な Apache Ranger ポリシーによって、クエリのコンパイル時間に遅延が発生し、ゲートウェイのタイムアウトにつながる可能性があります。 ESP クラスターでゲートウェイのタイムアウトが検出された場合、Ranger ポリシーの数を減らしたり、組み合わせたりすることを検討してください。
トラブルシューティングの手法
上記の行動の一部として、パフォーマンスの問題の緩和と理解を達成できる複数の場所があります。 HDInsight ゲートウェイでクエリ パフォーマンスの低下が発生している場合は、次のチェックリストを使用します。
大きな SELECT クエリを実行する場合は、LIMIT 句を使用します。 LIMIT 句によって、クライアント ホストに報告される合計行数が減少します。 LIMIT 句は、結果の生成にのみ影響し、クエリ プランを変更しません。 LIMIT 句をクエリ プランに適用するには、構成
hive.limit.optimize.enableを使用します。 LIMIT は、引数形式 x, y を使用して、オフセットと組み合わせることができます。SELECT * を使用する代わりに SELECT クエリを実行する場合、目的の列に名前を付けます。 選択する列が少ないほど、読み取られるデータの量が少なくなります。
Apache Beeline を使用して、目的のクエリを実行してみてください。 Apache Beeline による結果の取得に長時間かかる場合、外部ツールによって同じ結果を取得する際に、遅延が予想されます。
基本的な Hive クエリをテストして、HDInsight ゲートウェイへの接続を確立できることを確認します。 複数の外部ツールから基本的なクエリを実行して、個々のツールが問題なく動作することを確認してください。
Apache Ambari アラートを確認して、HDInsight サービスが正常であることを確認します。 Ambari アラートは、レポートと分析のために Azure Monitor と統合できます。
外部 Hive メタストアを使用している場合、Hive メタストアの Azure SQL DB DTU が制限に達していないことを確認します。 DTU が上限に近づいている場合は、データベースのサイズを増やす必要があります。
PBI や Tableau などのサードパーティ製ツールで、テーブルやデータベースを表示するために、改ページ位置の自動修正を使用していることを確認します。 改ページ位置の自動修正に役立つこれらのツールについては、サポート パートナーにお問い合わせください。 改ページ位置の自動修正に使用される主なツールは、JDBC
fetchSizeパラメーターです。 フェッチ サイズが小さいと、ゲートウェイのパフォーマンスが低下する可能性がありますが、フェッチ サイズが大きすぎるとゲートウェイのタイムアウトが発生する可能性があります。 フェッチ サイズのチューニングは、ワークロード単位で実行する必要があります。データ パイプラインで、HDInsight クラスターの基になるストレージから大量のデータを読み取る必要がある場合は、Azure Data Factory などの Azure Storage と直接やり取りするツールを使用することを検討してください
LLAP はクエリ結果を迅速に返すためのよりスムーズなエクスペリエンスを提供できるため、対話型ワークロードを実行するときは Apache Hive LLAP を使用することを検討してください
hive.server2.thrift.max.worker.threadsを使用して、Hive メタストア サービスで使用可能なスレッドの数を増やすことを検討してください。 この設定は、多数の同時実行ユーザーがクラスターにクエリを送信している場合に特に関連があります任意の外部ツールからゲートウェイに到達するために使用される再試行の回数を減らします。 複数の再試行を使用する場合は、指数関数的バックオフによる再試行ポリシーに従うことを検討してください
hive.exec.compress.outputとhive.exec.compress.intermediateの構成を使用して、圧縮 Hive を有効にすることを検討してください。