Azure Storage は、堅牢な汎用ストレージ ソリューションであり、HDInsight とシームレスに統合されます。 HDInsight では、クラスターの既定のファイル システムとして、Azure Storage 内の BLOB コンテナーを使用できます。 HDInsight のすべてのコンポーネントは、BLOB として格納された構造化データまたは非構造化データを HDFS インターフェイスを介して直接操作できます。
既定のクラスター ストレージとビジネス データには、個別のストレージ コンテナーを使用することをお勧めします。 この分離は、HDInsight ログと一時ファイルを自分のビジネス データから隔離するために行います。 また、アプリケーション ログとシステム ログが含まれている既定の BLOB コンテナーは、ストレージ コストを削減するために、それぞれのログを使用した後に削除することもお勧めしています。 コンテナーを削除する前に、ログを取り出してください。
[選択されたネットワーク] で [ファイアウォールと仮想ネットワーク] に関する制限を使用してストレージ アカウントをセキュリティで保護するように選択した場合、 [信頼された Microsoft サービスによる...] の例外を有効にしてください。この例外は、HDInsight でストレージ アカウントにアクセスできるようにするためです。
HDInsight のストレージ アーキテクチャ
次の図は、Azure Storage のHDInsight アーキテクチャを示しています。
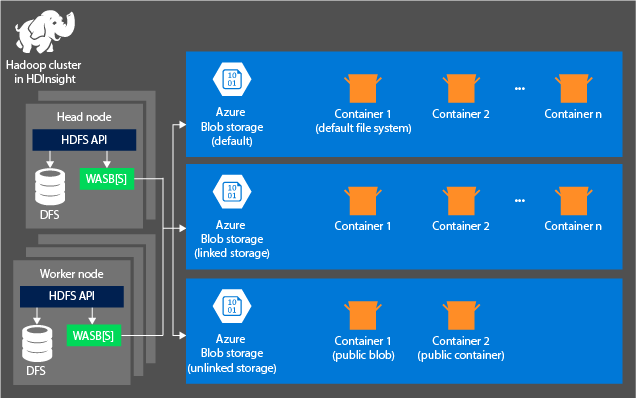
HDInsight では、それぞれのコンピューティング ノードにローカルに割り当てられている分散ファイル システムにアクセスします。 このファイル システムには、完全修飾 URI を使用してアクセスできます。次に例を示します。
hdfs://<namenodehost>/<path>
HDInsight を介して、Azure Storage 内のデータにアクセスすることもできます。 構文は次のとおりです。
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
階層型名前空間を持つアカウント (Azure Data Lake Storage Gen2) の場合、構文は次のようになります。
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
HDInsight クラスターで Azure Storage アカウントを使用するときには、次の原則を考慮してください。
クラスターに接続されているストレージ アカウント内のコンテナー: アカウントの名前とキーは作成中にクラスターと関連付けられるため、これらのコンテナー内の BLOB に対するフル アクセス許可が与えられます。
クラスターに接続されていないストレージ アカウント内のパブリック コンテナーまたはパブリック BLOB: コンテナー内の BLOB に対する読み取り専用のアクセス許可が与えられます。
注意
パブリック コンテナーの場合、そのコンテナー内に配置されているすべての BLOB のリストとコンテナー メタデータを取得できます。 パブリック BLOB の場合、正確な URL がわかっているときのみ、その BLOB にアクセスできます。 詳細については、「 コンテナーと BLOB への匿名読み取りアクセスを管理する」を参照してください。
クラスターに接続されていないストレージ アカウント内のプライベート コンテナー: WebHCat ジョブを送信するときにストレージ アカウントを定義しない限り、コンテナー内の BLOB にはアクセスできません。
作成プロセスで定義されたストレージ アカウントとそのキーは、クラスター ノードの %HADOOP_HOME%/conf/core-site.xml に格納されます。 既定では、HDInsight は core-site.xml ファイルに定義されたストレージ アカウントを使用します。 この設定は、Apache Ambari を使用して変更できます。 core-site.xml ファイルで変更または配置可能なストレージ アカウントの設定については、以下の記事を参照してください。
複数の WebHCat ジョブ (Apache Hive を含む)。 また、MapReduce、Apache Hadoop ストリーミング、Apache Pig では、ストレージ アカウントの説明とメタデータを伝達できます。 (このことは、現在、ストレージ アカウントを使用した Pig に当てはまりますが、メタデータの場合はそうではありません)。詳細については、「代替のストレージ アカウントとメタストアでの HDInsight クラスターの使用」を参照してください。
BLOB は、構造化データと非構造化データに使用できます。 BLOB コンテナーには、"キーと値のペア" としてデータが格納されます。ディレクトリ階層はありません。 ただし、キー名にスラッシュ (/) を含めると、ファイルがディレクトリ階層に保存されているように見せかけることができます。 たとえば、BLOB のキーが input/log1.txt であるとします。 実際には input というディレクトリは存在しませんが、キー名のスラッシュにより、キーがファイル パスのように見えます。
Azure Storage の利点
コンピューティング クラスターとストレージ リソースを同じ場所に併置しないと、パフォーマンスの低下が懸念されます。 こうした懸念は、Azure リージョン内のストレージ アカウント リソースの近くにコンピューティング クラスターを作成することで軽減されます。 このリージョンでは、コンピューティング ノードは Azure Storage 内の高速ネットワークを介してデータに効率的にアクセスできます。
HDFS ではなく、Azure Storage にデータを格納すると、いくつかの利点があります。
データの再使用と共有: HDFS のデータはコンピューティング クラスター内に配置されます。 HDFS API を使用してデータを操作できるのは、コンピューティング クラスターへのアクセスが許可されているアプリケーションだけです。 対照的に、Azure Storage 内のデータには、HDFS API または Blob Storage REST API のどちらかを使用してアクセスできます。 これにより、さまざまなアプリケーション (その他の HDInsight クラスターを含む) やツールを使用してデータの生成と利用ができます。
データのアーカイブ: Azure Storage にデータを格納した場合、計算で使用する HDInsight クラスターを削除してもユーザー データは失われません。
データ ストレージ コスト: DFS にデータを長期間保存すると、Azure Storage にデータを格納するよりもコストが高くなります。 コンピューティング クラスターのコストは Azure Storage のコストより高いためです。 また、コンピューティング クラスターを生成するたびにデータを再読み込みする必要がないため、データの読み込みコストも節約されます。
柔軟なスケールアウト: HDFS は大規模なファイル システムを提供しますが、規模を拡張するにはクラスターに対して作成するノードの数を増やさなければならないので、作業が複雑になります。 スケールの変更は、Azure Storage にもともと備わっている柔軟なスケール機能とよりも複雑になる場合があります。
geo レプリケーション: Azure Storage は、別の拠点に geo レプリケートできます。 geo レプリケーションにより、災害発生時には別の拠点でデータを回復でき、データの冗長性が高まりますが、geo レプリケーションした別拠点へのフェールオーバーはパフォーマンスに大きな影響を与え、追加コストが発生する可能性もあります。 このため、geo レプリケーションを利用するときは、追加コストがかかっても保護する価値のあるデータかどうかを十分に考慮してください。
MapReduce の一部のジョブやパッケージでは中間結果が生成されますが、Azure Storage には保存したくない場合もあります。 このような場合、中間結果データをローカルの HDFS に保存できます。 HDInsight では、Hive ジョブやその他のプロセスで生成される中間結果の一部が DFS に格納されます。
注意
ほとんどの HDFS コマンド (ls、copyFromLocal、mkdir など) は、Azure Storage で想定どおりに機能します。 ただし、fschk や dfsadmin など、HDFS ネイティブ実装 (DFS) に固有のコマンドについては、Azure Storage 上で実行した場合に動作が異なります。