この記事では、HDInsight クラスターで実行されている Apache Spark ジョブを追跡およびデバッグする方法について説明します。 Apache Hadoop YARN UI、Spark UI、Spark History Server を使用してデバッグします。 Spark クラスターで使用できるノートブックを使用して Spark ジョブを開始します。 機械学習: MLLib を使用した食品検査データに関する予測分析。 spark-submit などの他の方法を使用して送信したアプリケーションを追跡するには、次の手順を使用します。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
[前提条件]
HDInsight 上の Apache Spark クラスター。 手順については、 Azure HDInsight での Apache Spark クラスターの作成に関するページを参照してください。
MLLib を使用した食品検査データに関する予測分析であるノートブックの機械学習の実行を開始する必要があります。 このノートブックを実行する方法については、リンクをクリックしてください。
YARN UI でアプリケーションを追跡する
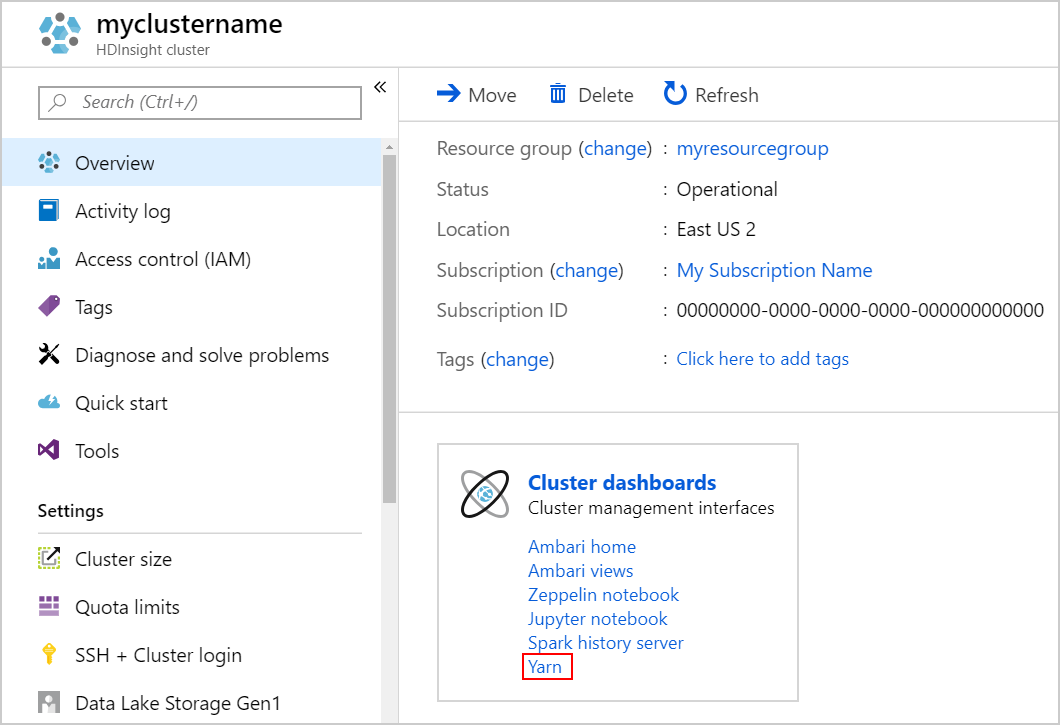
YARN UI を起動します。 クラスター ダッシュボードの [Yarn] を選択します。
ヒント
または、Ambari UI から YARN UI を起動することもできます。 Ambari UI を起動するには、[クラスター ダッシュボード] の下にある Ambari ホームを選択します。 Ambari UI から、アクティブな Resource Manager > の YARN>> に移動します。
Jupyter Notebooks を使用して Spark ジョブを開始したため、アプリケーションには remotesparkmagics という名前が付けられます (ノートブックから開始されたすべてのアプリケーションの名前)。 ジョブに関する詳細情報を取得するには、アプリケーション名に対してアプリケーション ID を選択します。 このアクションにより、アプリケーション ビューが起動します。
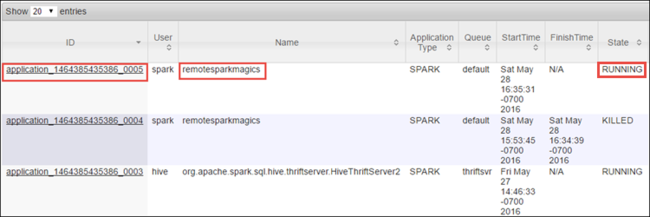
Jupyter Notebook から起動されるこのようなアプリケーションの場合、ノートブックを終了するまで、状態は常に RUNNING です 。
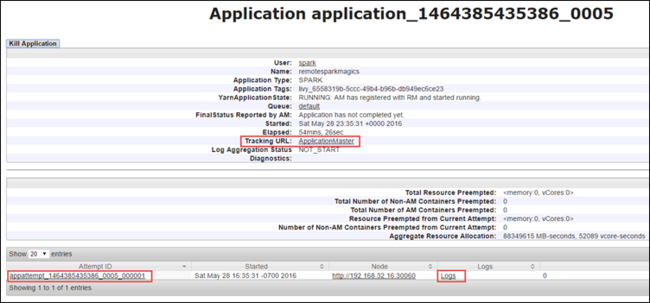
アプリケーション ビューからさらにドリルダウンして、アプリケーションに関連付けられているコンテナーとログ (stdout/stderr) を確認できます。 次に示すように、 追跡 URL に対応するリンクをクリックして Spark UI を起動することもできます。
Spark UI でアプリケーションを追跡する
Spark UI では、前に開始したアプリケーションによって生成された Spark ジョブにドリルダウンできます。
Spark UI を起動するには、上の画面キャプチャに示すように、アプリケーション ビューから 追跡 URL に対するリンクを選択します。 Jupyter Notebook で実行されているアプリケーションによって起動されたすべての Spark ジョブを確認できます。
![[Spark History Server jobs]\(Spark 履歴サーバー ジョブ\) タブ。](media/apache-spark-job-debugging/view-apache-spark-jobs.png)
[ Executor ] タブを選択すると、各 Executor の処理とストレージの情報が表示されます。 スレッド ダンプ リンクを選択して、呼び出し履歴を取得することもできます。
![Spark 履歴サーバーの [エグゼキュータ] タブ。](media/apache-spark-job-debugging/view-spark-executors.png)
[ ステージ ] タブを選択すると、アプリケーションに関連付けられているステージが表示されます。
![Spark History Server の [ステージ] タブ。](media/apache-spark-job-debugging/view-apache-spark-stages.png)
各ステージには、次に示すように、実行統計を表示できる複数のタスクを含めることができます。
![Spark History Server の [ステージ] タブの詳細。](media/apache-spark-job-debugging/view-spark-stages-details.png)
ステージの詳細ページから、DAG 視覚化を起動できます。 次に示すように、ページの上部にある [DAG 視覚化 ] リンクを展開します。
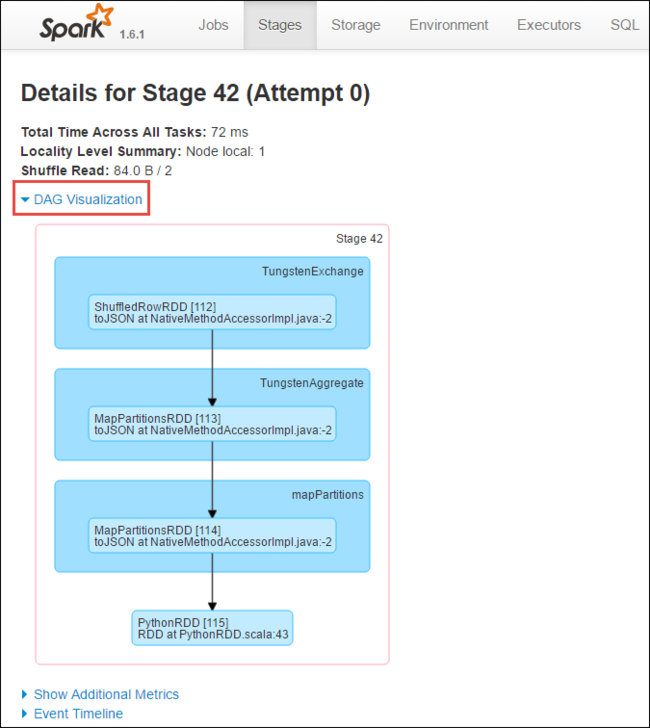
DAG または Direct Aclyic Graph は、アプリケーションのさまざまなステージを表します。 グラフ内の各青いボックスは、アプリケーションから呼び出された Spark 操作を表します。
ステージの詳細ページから、アプリケーションタイムラインビューを起動することもできます。 次に示すように、ページの上部にある [イベント タイムライン ] リンクを展開します。
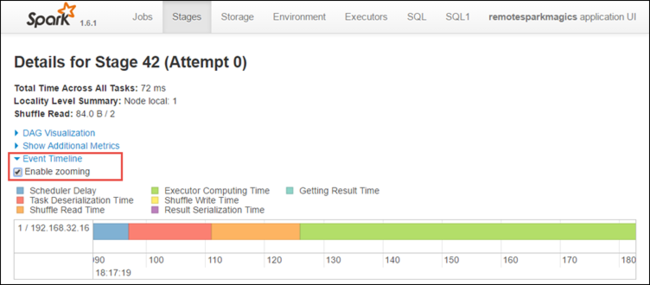
この画像には、タイムラインの形式で Spark イベントが表示されます。 タイムライン ビューは、ジョブ間、ジョブ内、ステージ内の 3 つのレベルで使用できます。 上の画像は、特定のステージのタイムライン ビューをキャプチャします。
ヒント
[ ズームを有効にする ] チェック ボックスをオンにすると、タイムライン ビューを左右にスクロールできます。
Spark UI の他のタブでも、Spark インスタンスに関する有用な情報が提供されます。
- [ストレージ] タブ - アプリケーションで RDD を作成する場合は、[ストレージ] タブで情報を見つけることができます。
- [環境] タブ - このタブには、次のような Spark インスタンスに関する有用な情報が表示されます。
- Scala バージョン
- クラスターに関連付けられているイベント ログ ディレクトリ
- アプリケーションの Executor コアの数
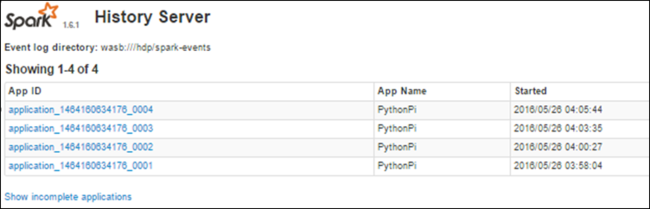
Spark History Server を使用して完了したジョブに関する情報を検索する
ジョブが完了すると、ジョブに関する情報は Spark History Server に保持されます。
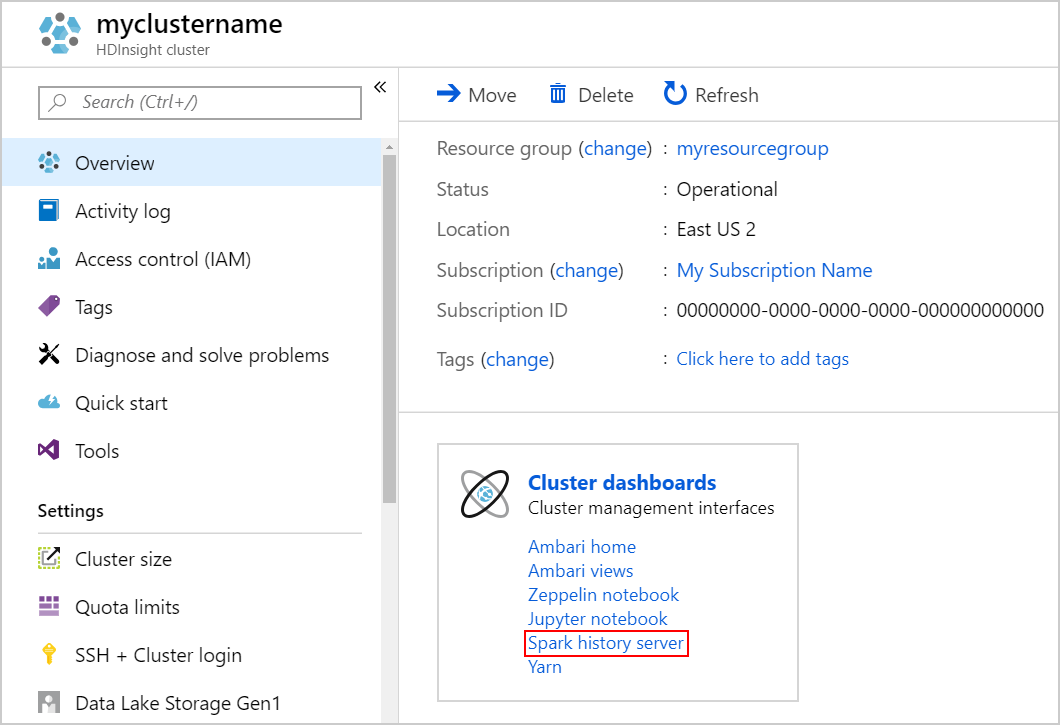
Spark History Server を起動するには、[概要] ページの [クラスター ダッシュボード] で Spark 履歴サーバーを選択します。
ヒント
または、Ambari UI から Spark History Server UI を起動することもできます。 Ambari UI を起動するには、[概要] ブレードで、[クラスター ダッシュボード] の下にある Ambari ホームを選択します。 Ambari UI から、 Spark2>Quick Links>Spark2 History Server UI に移動します。
完成したすべてのアプリケーションが一覧表示されます。 詳細については、アプリケーション ID を選択してアプリケーションにドリルダウンします。