この記事では、Azure HDInsight で最適なパフォーマンスを得るために Apache Spark クラスターのメモリ管理を最適化する方法について説明します。
概要
Spark は、データをメモリに配置することによって動作します。 そのため、メモリ リソースの管理は、Spark ジョブの実行を最適化するための重要な側面です。 クラスターのメモリを効率的に使用するために適用できる手法がいくつかあります。
- 小さいデータ パーティションを優先し、パーティション分割戦略でデータのサイズ、種類、および分散を要因とします。
- 既定の Java シリアル化ではなく、より新しく効率的な
Kryo data serializationを検討してください。 - YARN はバッチで
spark-submitを分離しているため、YARN の使用を優先します。 - Spark 構成設定を監視し、チューニングします。
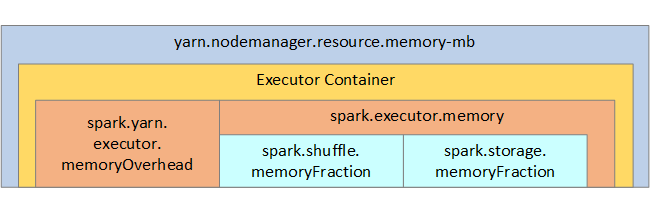
参考までに、Spark のメモリ構造と一部の重要な実行プログラムのメモリ パラメーターを、次のイメージで示します。
Spark メモリに関する考慮事項
Apache Hadoop YARN を使用している場合、YARN は各 Spark ノード上のすべてのコンテナーで使用されるメモリを制御します。 次の図は、重要なオブジェクトとそれらの関連性を示しています。
''メモリ不足'' のメッセージに対処するには、次を試してください。
- DAG 管理の変更を確認します。 マップ側の reduce 処理、ソース データの事前パーティション分割 (またはバケット化)、1 つのシャッフルの最大化、および送信されるデータ量の削減によって削減します。
-
ReduceByKeyに固定メモリ制限があるGroupByKeyを優先します。これは集計、ウィンドウ化、その他の関数を提供しますが、無制限のメモリ制限があります。 - 実行プログラムやパーティションでより多くの操作を実行する
TreeReduceを、すべての操作をドライバーで実行するReduceより優先します。 - 下位レベルの RDD オブジェクトではなく、DataFrame を使用します。
- "上位 N"、各種の集計、ウィンドウ化操作などのアクションをカプセル化する、ComplexTypes を作成します。
その他のトラブルシューティング手順については、 Azure HDInsight の Apache Spark の OutOfMemoryError 例外に関するページを参照してください。