この記事では、Azure Machine Learning デザイナーでデータをビンにグループ化するコンポーネントを使用して、数値をグループ化したり、連続データの分布を変更したりする方法について説明します。
Group Data into Bins (データのビンへのグループ化) コンポーネントでは、データをビン分割するための複数のオプションがサポートされています。 ビンの境界を設定する方法と、値をビンに分配する方法はカスタマイズできます。たとえば、次のように操作できます。
- ビンの境界として機能する一連の値を手動で入力する。
- "分位点" またはパーセンタイル順位を使用して、ビンに値を割り当てる。
- 強制的に値をビンに均等に分散させる。
ビン分割とグループ化の詳細
データの "ビン分割" またはグループ化 ("量子化" と呼ばれることもあります) は、機械学習用の数値データを準備するうえで重要なツールです。 これは、次のようなシナリオで役立ちます。
連続する数値の列に含まれる一意の値が多すぎて、効果的にモデル化することができません。 そのため、自動または手動で値をグループに割り当てて、より小さな個別の範囲のセットを作成します。
数値の列を特定の範囲を表すカテゴリ値に置き換えます。
たとえば、ユーザーの人口統計に対して 1-15、16-22、23-30 などのカスタム範囲を指定することによって、年齢の列の値をグループ化することができます。
データセットには、予想範囲を大きく超えるいくつかの極値が含まれています。これらの値は、トレーニング済みモデルに大きな影響を与えます。 モデルの偏りを軽減するために、分位点メソッドを使用して、データを一様分布に変換することができます。
Group Data into Bins (データのビンへのグループ化) コンポーネントでは、このメソッドを使用して、ほぼ同じ数のサンプルが各ビンに入るように、理想的なビンの場所とビンの幅が決定されます。 次に、選択した正規化メソッドに応じて、ビンの値はパーセンタイルに変換されるか、ビン番号にマップされます。
ビン分割の例
次の図は、分位点メソッドを使用してビン分割する前と後の数値の分布を示しています。 左側の生データと比較して、データはビン分割され、単位法線スケールに変換されていることに注目してください。
データをグループ化するにはさまざまな方法があり、すべてカスタマイズ可能なため、さまざまなメソッドと値で試してみることをお勧めします。
Group Data into Bins の構成方法
デザイナーでパイプラインにデータをビンにグループ化するコンポーネントを追加します。 このコンポーネントはデータ変換カテゴリ内にあります。
数値データを含むデータセットをビンに接続します。 量子化は、数値データを含む列にのみ適用できます。
データセットに数値以外の列が含まれている場合は、Select Columns in Dataset コンポーネントを使用して、使用する列のサブセットを選択します。
ビン分割モードを指定します。 ビン分割モードでは、他のパラメーターが決定されるため、まず [Binning mode](ビン分割モード) オプションを選択してください。 次の種類のビン分割がサポートされています。
分位点:分位メソッドでは、パーセンタイル順位に基づいて値をビンに割り当てます。 この方法は、等高ビン分割とも呼ばれます。
等幅:このオプションでは、ビンの合計数を指定する必要があります。各ビンの開始値と終了値の間隔が同じになるように、データ列の値がビンに配置されます。 その結果、データが特定のポイント周辺に集中すると、一部のビンに多くの値が含まれることになる場合があります。
カスタム エッジ:各ビンの開始値を指定できます。 エッジ値は、常にビンの下方境界です。
たとえば、値を 2 つのビンにグループ化するとします。1 つは 0 より大きい値を持ち、1 つは 0 以下の値を持ちます。 このケースでは、ビンの境界に対して、 [Comma-separated list of bin edges](ビンの境界のコンマ区切りリスト) に「0」と入力します。 コンポーネントの出力は、各行の値のビン インデックスを示す 1 と 2 になります。 コンマ区切り値リストは、昇順 (1、3、5、7 など) にする必要があることに注意してください。
注意
エントロピ MDL モードは Studio (クラシック) で定義されており、デザイナーでサポートするために利用できる対応するオープン ソース パッケージはまだありません。
[分位点] と [Equal Width](等幅) のビン分割モードを使用している場合は、 [ビンの数] オプションを使用して、作成するビン (つまり "分位点") の数を指定します。
[Columns to bin](ビン分割する列) には、列セレクターを使用して、ビン分割する値を持つ列を選択します。 列のデータ型は数値である必要があります。
選択したすべての適用可能な列に同じビン分割ルールが適用されます。 別の方法を使用していくつかの列をビン分割する必要がある場合は、列の各セットに対して Group Data into Bins (データのビンへのグループ化) コンポーネントの個別のインスタンスを使用します。
警告
許可された型ではない列を選択すると、実行時エラーが発生します。 このコンポーネントは、許可されていない型の列を検出するとすぐにエラーを返します。 エラーが発生した場合は、選択したすべての列を確認します。 このエラーでは、すべての無効な列が一覧表示されません。
出力モードの場合は、量子化された値を出力する方法を指定します。
追加: ビン分割された値を含む新しい列を作成し、入力テーブルに追加します。
Inplace:元の値をデータセット内の新しい値に置き換えます。
ResultOnly:結果の列のみを返します。
[分位点] ビン分割モードを選択した場合は、 [Quantile normalization](分位の正規化) オプションを使用して、分位点に並べ替える前に値を正規化する方法を決定します。 値を正規化すると、値が変換されますが、最終的なビンの数には影響しないことに注意してください。
次の正規化の種類がサポートされています。
Percent:値は [0,100] の範囲内で正規化されます。
PQuantile:値は [0,1] の範囲内で正規化されます。
QuantileIndex: 値は [1,ビン数] の範囲内で正規化されます。
[Custom Edges](カスタム エッジ) オプションを選択した場合は、 [Comma-separated list of bin edges](ビンの境界のコンマ区切りリスト) テキスト ボックスに "ビンの境界" として使用する数値のコンマ区切りリストを入力します。
この値を使用して、ビンを分割するポイントにマークします。たとえば、1 つのビンの境界値を入力すると、2 つのビンが生成されます。 2 つのビンの境界値を入力すると、3 つのビンが生成されます。
この値は、ビンが作成された順 (昇順) で並べ替える必要があります。
[Tag columns as categorical](列をカテゴリとしてタグを付ける) オプションを選択して、量子化された列をカテゴリ変数として扱う必要があることを示します。
パイプラインを送信します。
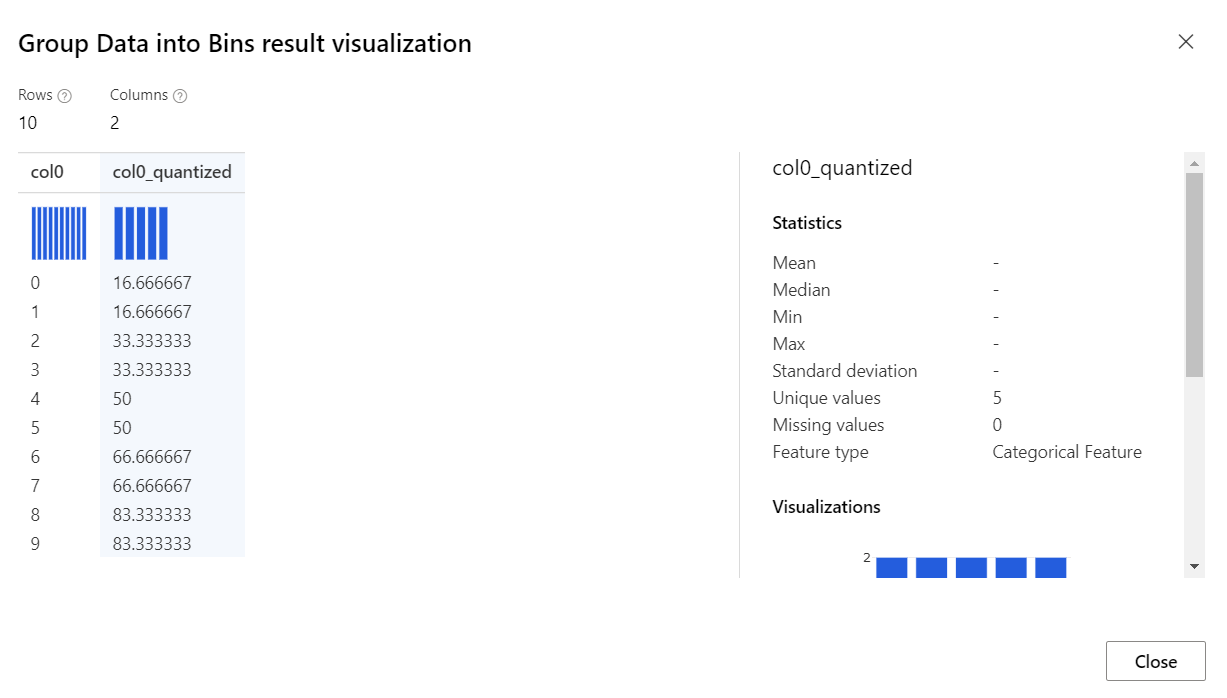
結果
Group Data into Bins (データのビンへのグループ化) コンポーネントから、指定されたモードに従って、各要素がビンに配置されたデータセットが返されます。
また、ビン分割変換も返されます。 その関数を Apply Transformation (変換の適用) コンポーネントに渡し、同じビン分割モードとパラメーターを使用してデータの新しいサンプルをビン分割することができます。
ヒント
トレーニング データにビン分割を使用する場合は、テストと予測に使用するデータに対して同じビン分割メソッドを使用する必要があります。 また、同じビンの場所とビンの幅を使用する必要があります。
常に同じビン分割方法を使用してデータが変換されるようにするには、有用なデータ変換を保存することをお勧めします。 次に、Apply Transformation (変換の適用) コンポーネントを使用してそれらを他のデータ セットに適用します。
次の手順
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。