この記事では Azure Machine Learning デザイナーのコンポーネントについて説明します。
Preprocess Text (テキストの前処理) コンポーネントを使用して、テキストをクリーンして簡素化します。 次の一般的なテキスト処理操作がサポートされています。
- ストップワードの削除
- 正規表現を使用して特定の対象文字列を検索して置換する
- レンマ化 (複数の関連する単語を 1 つの正規形式に変換する)
- 大文字と小文字の正規化
- 数字、特殊文字、および繰り返し文字のシーケンス (たとえば、"aaaa") など、特定のクラスの文字の削除
- 電子メールと URL の識別と削除
現在、Preprocess Text (テキストの前処理) コンポーネントでは英語のみがサポートされます。
テキストの前処理を構成する
Azure Machine Learning 内で Preprocess Text (テキストの前処理) コンポーネントをパイプラインに追加します。 このコンポーネントは、Text Analytics にあります。
テキストを含む列が少なくとも 1 列あるデータセットを接続します。
[言語] ドロップダウン リストから言語を選択します。
Text column to clean (クリーンアップするテキスト列) :前処理する列を選択します。
Remove stop words (ストップワードの削除) :定義済みのストップワード リストをテキスト列に適用する場合は、このオプションを選択します。
ストップワード リストは言語に依存し、カスタマイズ可能です。
Lemmatization (レンマ化) :正規形式で単語を表示する場合は、このオプションを選択します。 このオプションは、類似するテキスト トークンの一意の出現回数を減らすのに役立ちます。
レンマ化処理は、言語に大きく依存しています。
文の検出: 分析の実行時にコンポーネントによって文の境界マークを挿入する場合は、このオプションを選択します。
このコンポーネントは、一連の 3 本のパイプ文字
|||を使用して、文の終端記号を表します。正規表現を使用して、オプションの検索と置換の操作を実行します。 正規表現は他のすべての組み込みオプションの前に、最初に処理されます。
- Custom regular expression (カスタム正規表現) :検索するテキストを定義します。
- Custom replacement string (カスタム置換文字列) :1 つの置換値を定義します。
Normalize case to lowercase (大文字を小文字に正規化) :ASCII の大文字を小文字の形式に変換する場合は、このオプションを選択します。
文字が正規化されていない場合は、大文字と小文字の同一の単語が 2 つの異なる単語と見なされます。
また、処理された出力テキストから、次の種類の文字または文字シーケンスを削除することもできます。
Remove numbers (数字の削除) :このオプションを選択すると、指定した言語のすべての数字が削除されます。 ID 番号はドメインに依存し、言語に依存します。 数字が既知の単語の不可欠の部分である場合、その数字は削除されない可能性があります。 詳細については「テクニカル ノート」を参照してください。
Remove special characters (特殊文字の削除) :英数字以外の特殊文字をすべて削除するには、このオプションを使用します。
Remove duplicate characters (重複する文字の削除) :このオプションを選択すると、3 回以上繰り返されているシーケンス内の余分な文字が削除されます。 たとえば、"aaaaa" のようなシーケンスは "aa" に短縮されます。
Remove email addresses (メール アドレスの削除) :
<string>@<string>の形式のシーケンスをすべて削除するには、このオプションを選択します。Remove URLs (URL の削除) :次の URL プレフィックスを含むシーケンスをすべて削除するには、このオプションを選択します:
http、https、ftp、www
Expand verb contractions (動詞の短縮形を展開) :このオプションは、動詞の短縮形を使用している言語 (現在、英語のみ) に適用されます。
たとえば、このオプションを選択することにより、 "wouldn't stay there" という句を "would not stay there" に置き換えることができます。
Normalize backslashes to slashes (バックスラッシュをスラッシュに正規化) :
\\のすべてのインスタンスを/にマップするには、このオプションを選択します。Split tokens on special characters (特殊文字でトークンを分割) :
&や-などの文字で単語を分割する場合は、このオプションを選択します。 このオプションはまた、特殊文字が 3 回以上繰り返される場合にその文字を減らすことができます。たとえば、文字列
MS---WORDは、3 つのトークンMS、-、WORDに分割されます。パイプラインを送信します。
テクニカル ノート
Studio (クラシック) とデザイナーの Preprocess Text (テキストの前処理) コンポーネントでは、異なる言語モデルが使用されます。 デザイナーでは、spaCy のマルチタスク CNN のトレーニング済みモデルが使用されます。 モデルが異なれば、トークナイザーと品詞タガーも異なり、結果も異なります。
次にいくつかの例を示します。
| 構成 | 出力結果 |
|---|---|
| すべてのオプションが選択された状態 説明: 'WC-3 3test 4test' の '3test' のような場合、デザイナーによって '3test' という単語全体が削除されます。このコンテキストでは、品詞タガーによってこのトークン '3test' が数字として指定されているため、品詞に従って、コンポーネントでそれが削除されます。 |
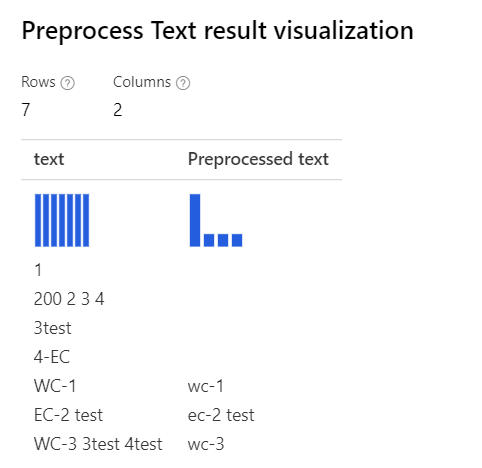
|
Removing number のみが選択された状態 説明: '3test'、'4-EC' のようなケースの場合、デザイナー トークナイザーではこれらのケースは分割されず、トークン全体として扱われます。 そのため、これらの単語の数値は削除されません。 |

|
また、正規表現を使用して、カスタマイズされた結果を出力することもできます。
| 構成 | 出力結果 |
|---|---|
| カスタム正規表現 選択されているすべてのオプション: (\s+)*(-|\d+)(\s+)*カスタム置換文字列: \1 \2 \3 |

|
カスタム正規表現Removing number選択されているのみ: カスタム置換文字列 (\s+)*(-|\d+)(\s+)*: \1 \2 \3 |
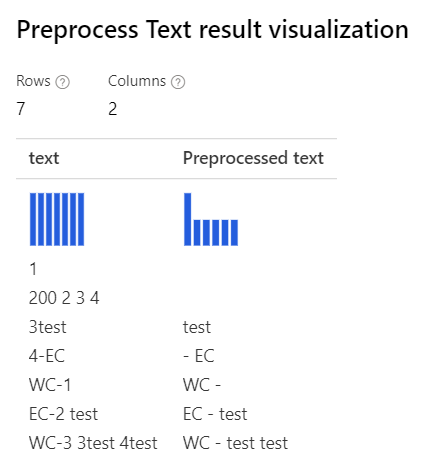
|
次の手順
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。