Azure Machine Learningでは、バッチ エンドポイントとデプロイを実装して、機械学習モデルとパイプラインで実行時間の長い非同期推論を実行できます。 機械学習モデルまたはパイプラインをトレーニングするときは、他のユーザーが新しい入力データで使用して予測を生成できるように、それをデプロイする必要があります。 モデルまたはパイプラインを使用して予測を生成するこのプロセスは 、推論と呼ばれます。
バッチ エンドポイントは、データへのポインターを受け取り、コンピューティング クラスターでデータを並列に処理するためにジョブを非同期的に実行します。 バッチ エンドポイントは、詳細な分析のためにデータ ストアに出力を格納します。 バッチ エンドポイントは、次の場合に使用します。
- 実行に時間がかかるコストの高いモデルまたはパイプラインがあります。
- 機械学習パイプラインを運用化し、コンポーネントを再利用したいと考えています。
- 複数のファイルに分散された大量のデータに対して推論を実行する必要があります。
- 待機時間が短い要件はありません。
- モデルの入力は、ストレージ アカウントまたはAzure Machine Learningデータ資産に格納されます。
- 並列化を利用できます。
バッチデプロイ
デプロイは、エンドポイントが提供する機能を実装するために必要なリソースとコンピューティングのセットです。 エンドポイントは、それぞれ独自の構成を持つ複数のデプロイをホストでき、デプロイ実装の詳細からエンドポイント インターフェイスを切り離すことができます。 バッチ エンドポイントが呼び出されると、クライアントは既定のデプロイに自動的にルーティングされます。 この既定のデプロイは、いつでも構成および変更できます。

Azure Machine Learningバッチ エンドポイントでは、次の 2 種類のデプロイが可能です。
モデルの展開
モデルのデプロイにより、大規模なモデル推論の運用化が可能になり、待機時間が短く非同期的に大量のデータを処理できます。 Azure Machine Learningは、コンピューティング クラスター内の複数のノードにわたって推論プロセスを並列化することで、スケーラビリティを自動的にインストルメント化します。
次の条件に当てはまる場合、モデルデプロイを使用します。
- 推論の実行に長い時間が必要なコストの高いモデルがあります。
- 複数のファイルに分散された大量のデータに対して推論を実行する必要があります。
- 待機時間が短い要件はありません。
- 並列化を利用できます。
モデル デプロイの主な利点は、オンライン エンドポイントへのリアルタイム推論にデプロイされているのと同じ資産を使用できることですが、今度は、それらを大規模に一括して実行できます。 モデルで単純な前処理または後処理が必要な場合は、必要なデータ変換を実行する スコア付けスクリプトを作成 できます。
バッチ エンドポイントでモデル デプロイを作成するには、次の要素を指定する必要があります。
- モデル
- コンピューティング クラスター
- スコアリング スクリプト (MLflow モデルの場合は省略可能)
- 環境 (MLflow モデルの場合は省略可能)
パイプライン コンポーネントのデプロイ
パイプライン コンポーネントのデプロイを使用すると、処理グラフ (またはパイプライン) 全体の運用化を使用して、短い待機時間と非同期の方法でバッチ推論を実行できます。
パイプライン コンポーネントのデプロイは、次の場合に使用します。
- 複数のステップに分解できる完全なコンピューティング グラフを運用化する必要があります。
- 推論パイプラインでトレーニング パイプラインのコンポーネントを再利用する必要があります。
- 待機時間が短い要件はありません。
パイプライン コンポーネントデプロイの主な利点は、プラットフォームに既に存在するコンポーネントの再利用性と、複雑な推論ルーチンを運用可能にする機能です。
バッチ エンドポイントでパイプライン コンポーネントのデプロイを作成するには、次の要素を指定する必要があります。
- パイプライン コンポーネント
- コンピューティング クラスターの構成
バッチ エンドポイントを使用すると、 既存のパイプライン ジョブからパイプライン コンポーネントのデプロイを作成することもできます。 その場合、Azure Machine Learningはジョブからパイプライン コンポーネントを自動的に作成します。 これにより、これらの種類のデプロイの使用が簡略化されます。 ただし、 MLOps のプラクティスを合理化するために、常にパイプライン コンポーネントを明示的に作成することをお勧めします。
コスト管理
バッチ エンドポイントを呼び出すと、非同期バッチ推論ジョブがトリガーされます。 Azure Machine Learningは、ジョブの開始時にコンピューティング リソースを自動的にプロビジョニングし、ジョブの完了時に自動的に割り当てを解除します。 この方法では、コンピューティングを使用した場合にのみ料金が発生します。
ヒント
モデルをデプロイするときに、個々のバッチ推論ジョブごとに コンピューティング リソースの設定 (インスタンス数など) と詳細設定 (ミニ バッチ サイズ、エラーしきい値など) をオーバーライドできます。 これらの特定の構成を利用することで、実行を高速化し、コストを削減できる場合があります。
バッチ エンドポイントは、優先順位の低い VM でも実行できます。 バッチ エンドポイントは、割り当て解除された VM から自動的に復旧し、推論用のモデルをデプロイするときに残された場所から作業を再開できます。 優先順位の低い VM を使用してバッチ推論ワークロードのコストを削減する方法の詳細については、「バッチ エンドポイントで優先順位の低い VM を使用する」を参照してください。
最後に、Azure Machine Learningはバッチ エンドポイントやバッチ デプロイ自体に対して課金されないため、シナリオに最も適したエンドポイントとデプロイを整理できます。 エンドポイントとデプロイでは、独立したクラスターまたは共有クラスターを使用できるため、ジョブが消費するコンピューティングをきめ細かく制御できます。 クラスターで 0 へのスケールを 使用して、リソースがアイドル状態のときに消費されないようにします。
MLOps プラクティスを効率化する
Batch エンドポイントは、同じエンドポイントの下で複数のデプロイを処理できるため、コンシューマーが呼び出しに使用する URL を変更することなく、エンドポイントの実装を変更できます。
エンドポイント自体に影響を与えることなく、デプロイの追加、削除、更新を行うことができます。
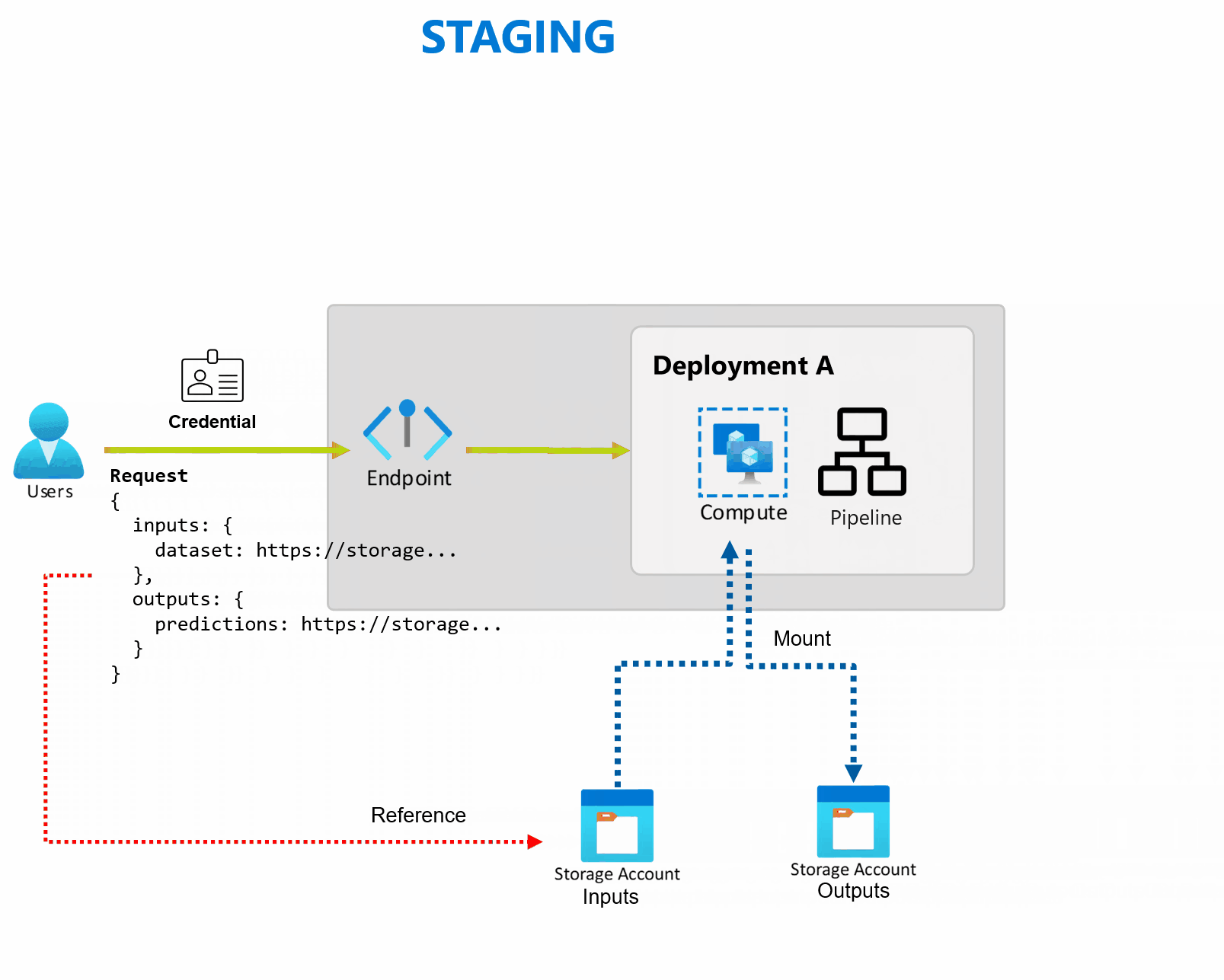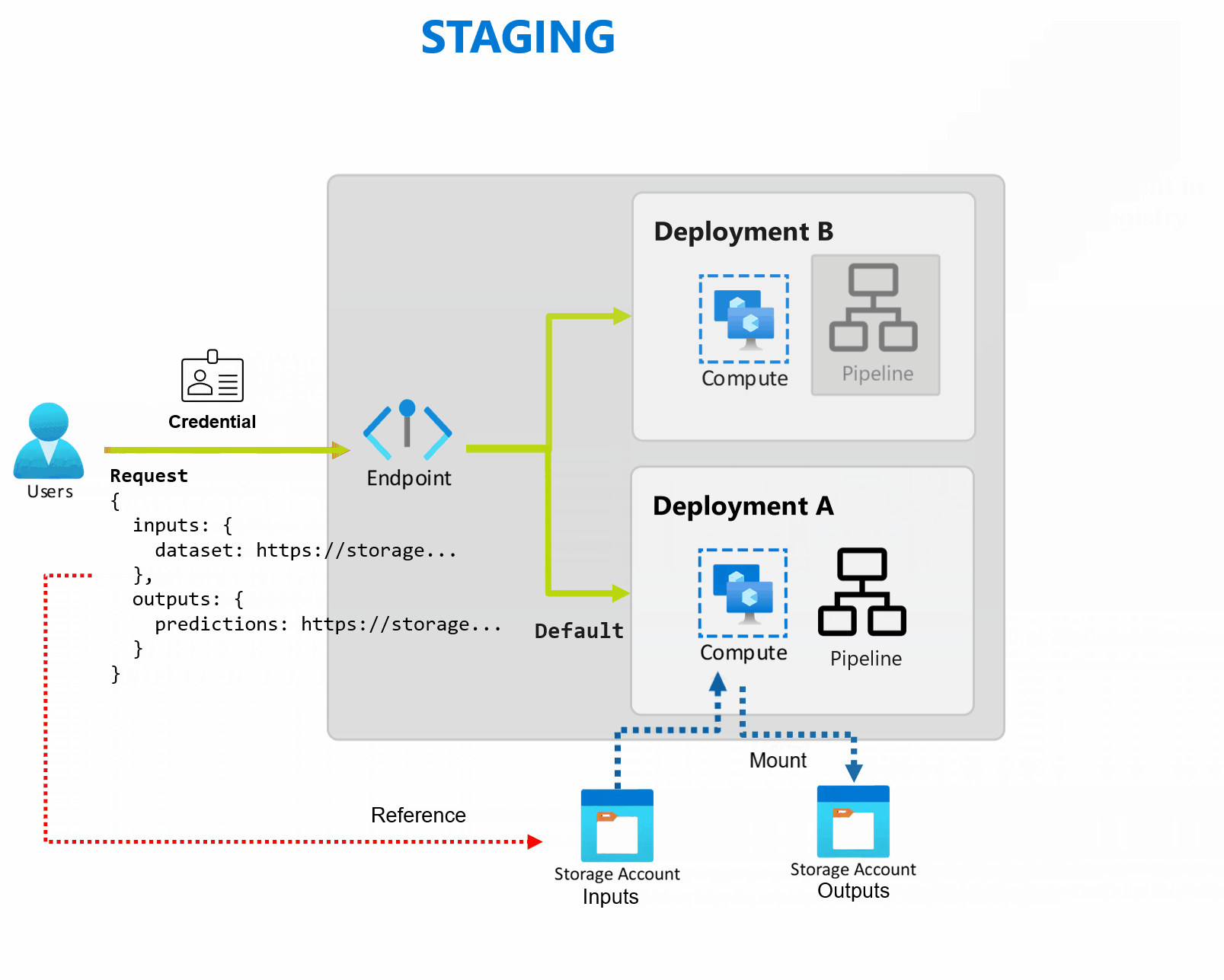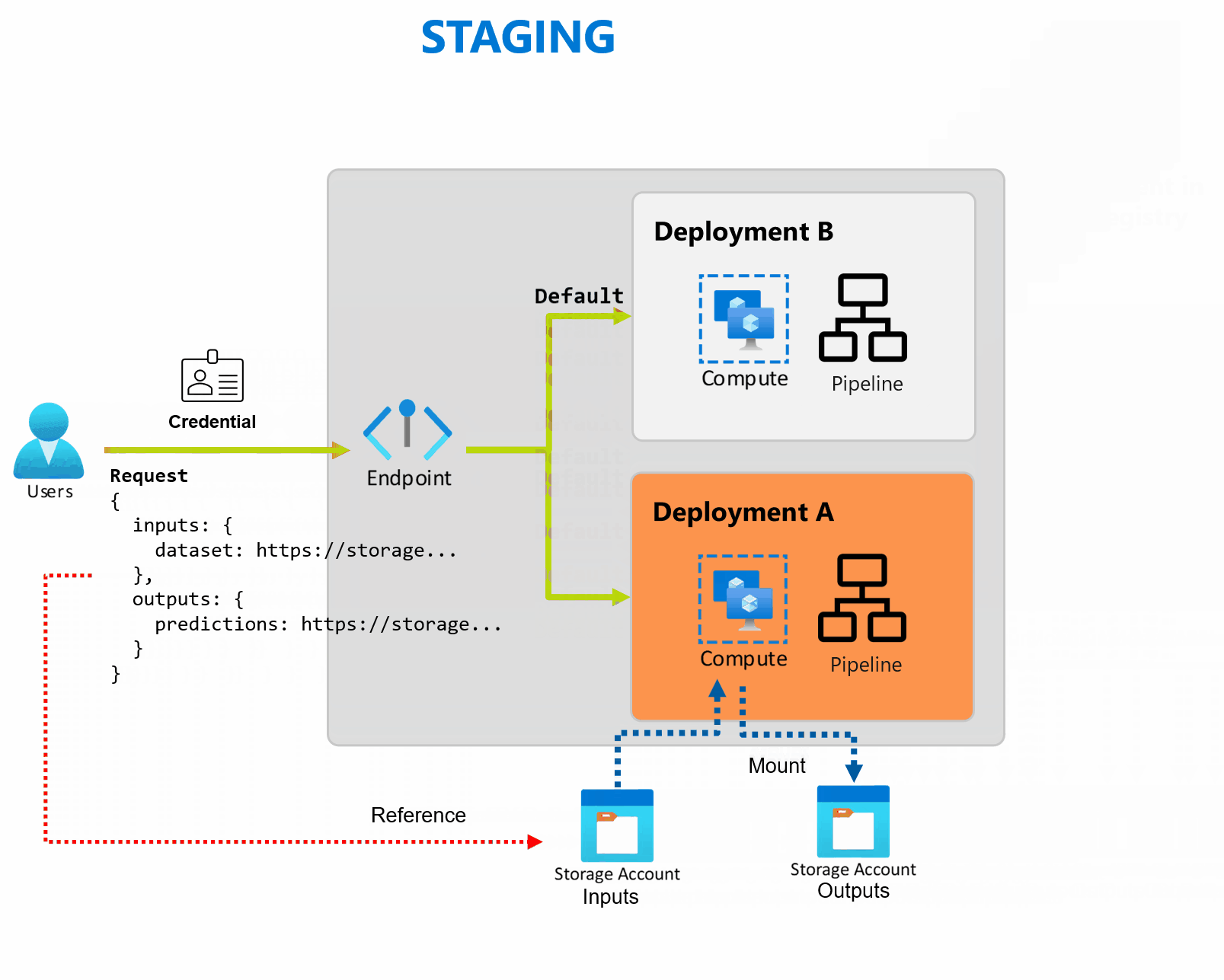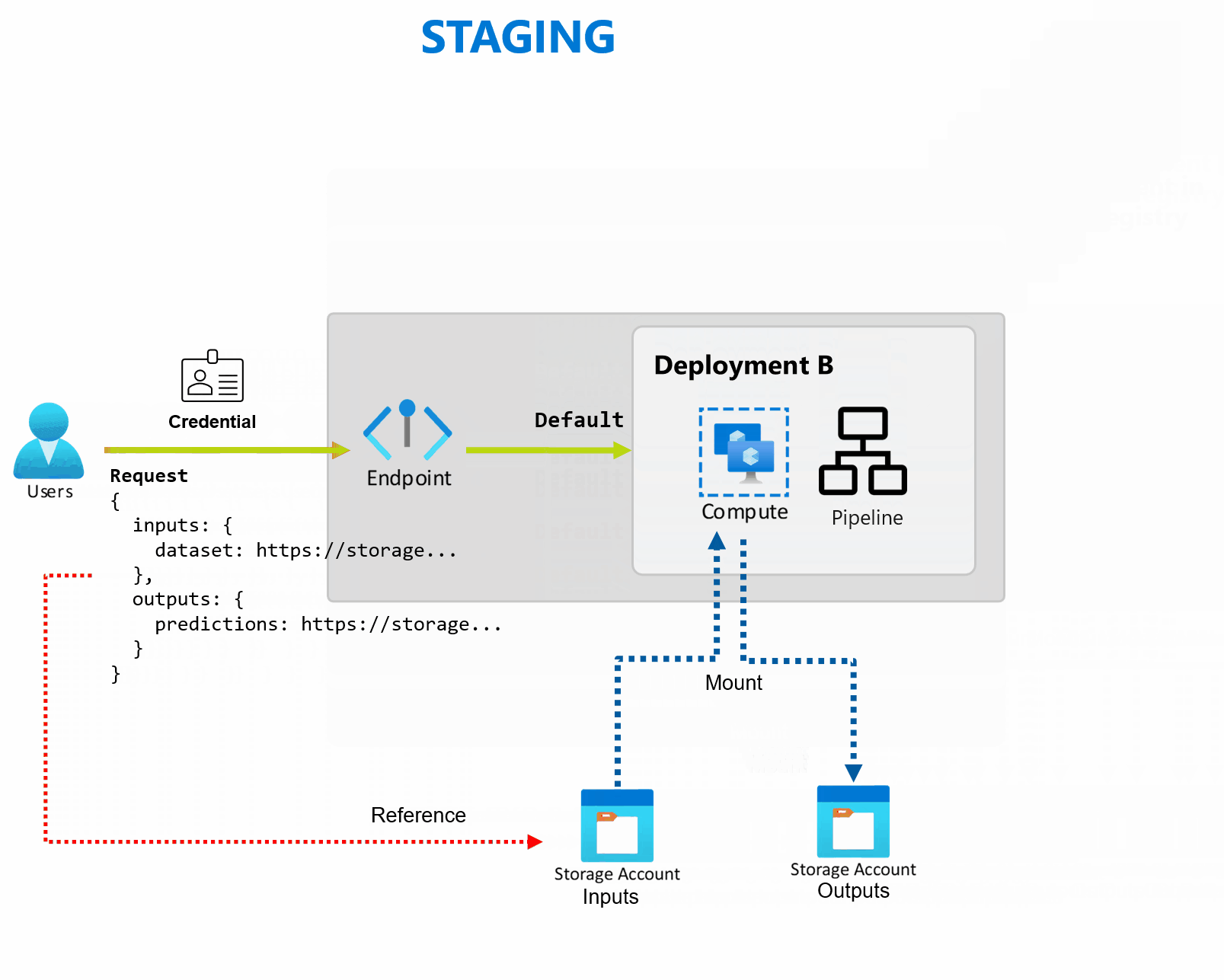
柔軟なデータ ソースとストレージ
バッチ エンドポイントは、ストレージから直接データの読み取りと書き込みを行います。 Azure Machine Learningデータストア、Azure Machine Learningデータ資産、またはストレージ アカウントを入力として指定できます。 サポートされている入力オプションとその指定方法の詳細については、「 ジョブの作成とバッチ エンドポイントへのデータの入力」を参照してください。
セキュリティ
Batch エンドポイントは、エンタープライズ設定で運用レベルのワークロードを運用するために必要なすべての機能を提供します。 セキュリティで保護されたワークスペースでプライベートネットワーキングとMicrosoft Entra 認証をサポートします。ユーザー プリンシパル (ユーザー アカウントなど) またはサービス プリンシパル (マネージド ID やアンマネージド ID など) を使用します。 バッチ エンドポイントによって生成されたジョブは、呼び出し元の ID で実行されるため、任意のシナリオを柔軟に実装できます。 バッチ エンドポイントの使用中の承認の詳細については、「バッチ エンドポイント で認証する方法」を参照してください。