Azure での Ubuntu Data Science Virtual Machine を使用したデータ サイエンス
このチュートリアルでは、Ubuntu Data Science Virtual Machine (DSVM) を使用して、いくつかの一般的なデータ サイエンス タスクを実行する方法について説明します。 Ubuntu DSVM は Azure で使用できる仮想マシン イメージであり、データ分析と機械学習で一般的に使用されているツールのコレクションがプレインストールされています。 主なソフトウェア コンポーネントは、Ubuntu Data Science Virtual Machine のプロビジョニングに関する記事にまとめられています。 この DSVM イメージを使用すると、各ツールを個別にインストールして構成する必要がないため、データ サイエンスを数分で簡単に開始できます。 DSVM は、必要に応じて を簡単にスケールアップでき、使用しないときには停止できます。 DSVM リソースは柔軟性があるうえに、コスト効率が優れています。
このチュートリアルでは、spambase データセットを分析します。 spambase は、スパムまたはハム (スパムではない) のいずれかのマークが付けられているメールのセットです。 また、spambase には、メールの内容に関する統計情報も含まれています。 統計については、このチュートリアルで後ほど説明します。
前提条件
Linux DSVM を使用する前に、以下の前提条件を満たしている必要があります。
Azure サブスクリプション。 Azure サブスクリプションを取得するには、「無料の Azure アカウントを今すぐ作成しましょう」をご覧ください。
Ubuntu Data Science Virtual Machine 仮想マシンのプロビジョニングについては、Ubuntu Data Science Virtual Machine のプロビジョニングに関するページをご覧ください。
お使いのコンピューターに X2Go がインストールされており、XFCE セッションが開かれている。 詳細については、「X2Go クライアントをインストールして構成する」をご覧ください。
spambase データセットをダウンロードする
spambase データセットは、4601 件の例を含む比較的小さなデータセットです。 このデータセットは、リソース要件が中程度に抑えられるため、DSVM の主要な機能をいくつか示すのに便利なサイズです。
注意
このチュートリアルは、D2 v2 サイズの Linux DSVM を使用して作成されました。 このサイズの DSVM を使用して、このチュートリアルで説明する手順を実行できます。
ストレージ領域がもっと必要な場合は、追加のディスクを作成し、DSVM に接続できます。 これらのディスクでは永続的な Azure ストレージを使用します。そのため、サーバーがサイズ変更のために再プロビジョニングされた場合や、シャットダウンされた場合でも、データが保持されます。 ディスクを追加し、DSVM に接続するには、「Linux VM へのディスクの追加」の手順を実行してください。 ディスクを追加する手順では、Azure CLI を使用します。これは、DSVM に既にインストールされています。 この手順は、DSVM 自体から全て実行できます。 ストレージを増やす方法として、Azure Files を使用することもできます。
データをダウンロードするには、ターミナル ウィンドウを開き、次のコマンドを実行します。
wget --no-check-certificate https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/spambase.data
ダウンロードしたファイルにはヘッダー行がありません。 そのため、ヘッダーを含む別のファイルを作成します。 次のコマンドを実行して、適切なヘッダーを含むファイルを作成します。
echo 'word_freq_make, word_freq_address, word_freq_all, word_freq_3d,word_freq_our, word_freq_over, word_freq_remove, word_freq_internet,word_freq_order, word_freq_mail, word_freq_receive, word_freq_will,word_freq_people, word_freq_report, word_freq_addresses, word_freq_free,word_freq_business, word_freq_email, word_freq_you, word_freq_credit,word_freq_your, word_freq_font, word_freq_000, word_freq_money,word_freq_hp, word_freq_hpl, word_freq_george, word_freq_650, word_freq_lab,word_freq_labs, word_freq_telnet, word_freq_857, word_freq_data,word_freq_415, word_freq_85, word_freq_technology, word_freq_1999,word_freq_parts, word_freq_pm, word_freq_direct, word_freq_cs, word_freq_meeting,word_freq_original, word_freq_project, word_freq_re, word_freq_edu,word_freq_table, word_freq_conference, char_freq_semicolon, char_freq_leftParen,char_freq_leftBracket, char_freq_exclamation, char_freq_dollar, char_freq_pound, capital_run_length_average,capital_run_length_longest, capital_run_length_total, spam' > headers
次に、2 つのファイルを連結します。
cat spambase.data >> headers
mv headers spambaseHeaders.data
このデータセットには、各メールに関する何種類かの統計情報が含まれています。
- word_freq_WORD のような列は、メール内で WORD に一致する単語のパーセントを示しています。 たとえば、word_freq_make が 1 の場合は、メール内の全単語のうち 1% が make でした。
- char_freq_CHAR のような列は、メール内の全文字のうち CHAR であるもののパーセントを示しています。
- capital_run_length_longest は、大文字シーケンスの最大の長さを示しています。
- capital_run_length_average は、大文字シーケンスの平均の長さを示しています。
- capital_run_length_total は、すべての大文字シーケンスの合計長さを示しています。
- spam は、メールがスパムと判断されたかどうかを示しています (1 = スパム、0 = スパムではない)。
R Open を使用してデータセットを探索する
R を使用して、データを確認し、基本的な機械学習を実行してみましょう。DSVM には、CRAN R がプレインストールされています。
このチュートリアルで使用するコード サンプルのコピーを入手するには、git を使用して、 Azure-Machine-Learning-Data-Science リポジトリを複製します。 git は DSVM にプレインストールされています。 git コマンド ラインで次を実行します。
git clone https://github.com/Azure/Azure-MachineLearning-DataScience.git
ターミナル ウィンドウを開き、R の対話型コンソールで新しい R セッションを開始します。 データをインポートし、環境を設定するには、次を実行します。
data <- read.csv("spambaseHeaders.data")
set.seed(123)
各列に関する概要統計情報を表示するには、次を実行します。
summary(data)
データの別のビューを表示するには、次を実行します。
str(data)
このビューには、各変数の型とデータセット内の最初のいくつかの値が表示されます。
spam 列は整数として読み取られますが、実際にはカテゴリ変数 (factor) です。 型を設定するには、次を実行します。
data$spam <- as.factor(data$spam)
探索式の分析を行うには、 ggplot2 パッケージ (DSVM にプレインストールされている R の一般的なグラフ作成ライブラリ) を使用します。 先ほど表示した概要データに基づいて、感嘆符文字の出現頻度に関する概要統計情報があります。 次のコマンドを実行して、それらの頻度をプロットしてみましょう。
library(ggplot2)
ggplot(data) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
ゼロの棒があると、プロットにゆがみが生じるため、取り除きます。
email_with_exclamation = data[data$char_freq_exclamation > 0, ]
ggplot(email_with_exclamation) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
興味深い、1 を超える非自明な密度があります。 そのデータだけを見てみましょう。
ggplot(data[data$char_freq_exclamation > 1, ]) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
次に、スパムとハムに分けます。
ggplot(data[data$char_freq_exclamation > 1, ], aes(x=char_freq_exclamation)) +
geom_density(lty=3) +
geom_density(aes(fill=spam, colour=spam), alpha=0.55) +
xlab("spam") +
ggtitle("Distribution of spam \nby frequency of !") +
labs(fill="spam", y="Density")
これらの例は、同様のプロットを作成し、他の列のデータを探索するのに役立ちます。
機械学習モデルのトレーニングとテスト
データセット内のメールをスパムとハムに分類するように、いくつかの機械学習モデルをトレーニングしましょう。 このセクションでは、デシジョン ツリー モデルとランダム フォレスト モデルをトレーニングします。 次に、予測の精度をテストします。
注意
次のコードで使用する rpart (Recursive Partitioning and Regression Trees) パッケージは、DSVM に既にインストールされています。
まず、データセットをトレーニング セットとテスト セットに分割します。
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
次に、メールを分類するデシジョン ツリーを作成します。
require(rpart)
model.rpart <- rpart(spam ~ ., method = "class", data = trainSet)
plot(model.rpart)
text(model.rpart)
結果は次のとおりです。
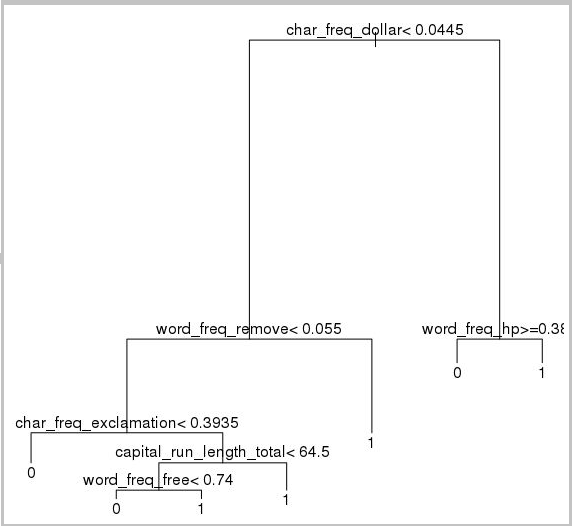
トレーニング セットに対するパフォーマンスを確認するには、次のコードを使用します。
trainSetPred <- predict(model.rpart, newdata = trainSet, type = "class")
t <- table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
テスト セットに対するパフォーマンスを確認するには、次のコードを使用します。
testSetPred <- predict(model.rpart, newdata = testSet, type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
ランダム フォレスト モデルも試してみましょう。 ランダム フォレストは、さまざまなデシジョン ツリーをトレーニングし、個々のデシジョン ツリーすべてからの分類のモードであるクラスを出力します。 これらは、トレーニング データセットが過剰適合されるデシジョン ツリー モデルの傾向を修正するため、より強力な機械学習アプローチを提供します。
require(randomForest)
trainVars <- setdiff(colnames(data), 'spam')
model.rf <- randomForest(x=trainSet[, trainVars], y=trainSet$spam)
trainSetPred <- predict(model.rf, newdata = trainSet[, trainVars], type = "class")
table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
testSetPred <- predict(model.rf, newdata = testSet[, trainVars], type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
ディープ ラーニングのチュートリアル
フレームワーク ベースのサンプルに加えて、包括的なチュートリアルのセットも提供されています。 これらのチュートリアルは、イメージやテキスト/言語の理解などの分野でディープ ラーニング アプリケーションの開発をすぐに開始するのに役立ちます。
さまざまなフレームワークでのニューラル ネットワークの実行: あるフレームワークから別のフレームワークにコードを移行する方法を示す包括的なチュートリアルです。 フレームワーク間でモデルと実行時のパフォーマンスを比較する方法も示します。
イメージ内で製品を検出するエンド ツー エンド ソリューションを構築するための攻略ガイド:イメージ検出は、イメージ内のオブジェクトを特定して分類する手法です。 このテクノロジには、多くの現実のビジネス分野に大きなメリットをもたらす可能性があります。 たとえば、小売り業者は、この手法を使用して、顧客が棚から選ぶ製品を判断できます。 この情報は、店舗が製品在庫を管理するのに役立ちます。
音声のディープ ラーニング: このチュートリアルでは、都市音声データセットの音声イベントを検出するためのディープ ラーニング モデルをトレーニングする方法を説明します。 また、音声データを操作する方法の概要についてもこのチュートリアルで説明します。
テキスト ドキュメントの分類: このチュートリアルでは、2 つの異なるニューラル ネットワーク アーキテクチャを構築してトレーニングする方法を示します。Hierarchical Attention Network と Long Short Term Memory (LSTM) です。 これらのニューラル ネットワークでは、ディープ ラーニング用の Keras API を使用して、テキスト ドキュメントを分類します。 Keras は、最も普及している 3 つのディープ ラーニング フレームワーク (Microsoft Cognitive Toolkit、TensorFlow、および Theano) のフロントエンドです。
その他のツール
残りのセクションでは、Linux DSVM にインストールされているツールの一部について、その使用方法を示します。 これらのツールについて説明します。
- XGBoost
- Python
- JupyterHub
- Rattle
- PostgreSQL と SQuirreL SQL
- Azure Synapse Analytics (旧称 SQL DW)
XGBoost
XGBoost は、迅速かつ正確なブースト ツリー実装を提供します。
require(xgboost)
data <- read.csv("spambaseHeaders.data")
set.seed(123)
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
bst <- xgboost(data = data.matrix(trainSet[,0:57]), label = trainSet$spam, nthread = 2, nrounds = 2, objective = "binary:logistic")
pred <- predict(bst, data.matrix(testSet[, 0:57]))
accuracy <- 1.0 - mean(as.numeric(pred > 0.5) != testSet$spam)
print(paste("test accuracy = ", accuracy))
また、XGBoost は Python またはコマンド ラインから呼び出すことができます。
Python
Python 開発用に、Anaconda Python ディストリビューション 3.5 および 2.7 が DSVM インストールにされています。
注意
Anaconda ディストリビューションには Conda が含まれています。 Conda を使用すると、さまざまなバージョンまたはパッケージがインストールされているカスタムの Python 環境を作成できます。
Scikit-learn のサポート ベクター マシンを使用して、spambase データセットの一部を読み取り、メールを分類してみましょう。
import pandas
from sklearn import svm
data = pandas.read_csv("spambaseHeaders.data", sep = ',\s*')
X = data.ix[:, 0:57]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
予測を行うには、次を実行します。
clf.predict(X.ix[0:20, :])
Azure Machine Learning エンドポイントを発行する方法を示すために、より基本的なモデルを作成します。 前に R モデルを発行したときに使用した 3 つの変数を使用します。
X = data[["char_freq_dollar", "word_freq_remove", "word_freq_hp"]]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
JupyterHub
DSVM の Anaconda ディストリビューションには、Jupyter Notebook (Python、R、または Julia のコードと分析を共有するためのクロスプラットフォーム環境) が付属しています。 Jupyter Notebook には JupyterHub からアクセスします。 ローカルの Linux ユーザー名とパスワードを使用して、 https://<DSVM の DNS 名または IP アドレス>:8000/ でサインインします。 JupyterHub のすべての構成ファイルは、 /etc/jupyterhub にあります。
注意
現在のカーネルの Jupyter Notebook から (pip コマンドを通して) Python Package Manager を使用するには、コード セルでこのコマンドを使用します。
import sys
! {sys.executable} -m pip install numpy -y
現在のカーネルの Jupyter Notebook から (conda コマンドを通して) Conda インストーラーを使用するには、コード セルでこのコマンドを使用します。
import sys
! {sys.prefix}/bin/conda install --yes --prefix {sys.prefix} numpy
いくつかのサンプル ノートブックは、DSVM に既にインストールされています。
- サンプルの Python ノートブック:
- サンプルの R ノートブック:
注意
Linux DSVM のコマンド ラインから Julia 言語を使用することもできます。
Rattle
Rattle (RAnalytical Tool To Learn Easily) は、データ マイニング用のグラフィカル R ツールです。 Rattle には、直感的なインターフェイスが用意され、データの読み込み、探索、変換のほか、モデルの構築と評価を簡単に行うことができます。 「Rattle:R 向けのデータ マイニング GUI」に、Rattle の機能を説明するチュートリアルが記載されています。
Rattle をインストールして起動するには、これらのコマンドを実行します。
if(!require("rattle")) install.packages("rattle")
require(rattle)
rattle()
注意
DSVM に Rattle をインストールする必要はありません。 ただし、Rattle を開いたときに、追加のパッケージをインストールするように求められる場合があります。
Rattle では、タブベースのインターフェイスを使用します。 タブのほとんどは、 Team Data Science Process に関する記事の手順に対応しています (データの読み込みや探索など)。 データ サイエンス プロセスは、タブの左から右へと進んで行きます。 最後のタブには、Rattle で実行された R コマンドのログが含まれます。
データセットを読み込んで構成するには:
- ファイルを読み込むには、 [Data](データ) タブを選択します。
- [Filename](ファイル名) の横にあるセレクターを選択し、spambaseHeaders.data を選択します。
- ファイルを読み込むには、 [Execute](実行) を選択します。 各列の概要 (識別されたデータ型、その列が入力、ターゲット、またはその他の種類の変数かどうか、一意の値の数など) が表示されます。
- Rattle では、 spam 列がターゲットとして正しく識別されます。 spam 列を選択し、 [Target Data Type](ターゲットのデータ型) を [Categoric](分類) に設定します。
データを探索するには:
- [Explore (探索)] タブをクリックします。
- 変数の型に関する情報と概要統計情報を表示するには、 [Summary](概要)>[Execute](実行) を選択します。
- 各変数に関する他の種類の統計情報を表示するには、 [Describe](説明) や [Basics](基本) などの他のオプションを選択します。
[Explore](探索) タブを使用して、洞察を得られるプロットを生成することもできます。 データのヒストグラムをプロットするには:
- [Distributions (ディストリビューション)] を選択します。
- word_freq_remove と word_freq_you については、 [Histogram](ヒストグラム) を選択します。
- [実行] を選択します。 1 つのグラフ ウィンドウに両方の密度プロットが表示され、メールには you という単語が remove よりもはるかに頻繁に出現していることが明らかです。
相関関係プロットも興味深いものです。 プロットを作成するには:
- [Type](種類) で [Correlation](相関関係) を選択します。
- [実行] を選択します。
- 推奨される変数の最大数が 40 である旨の警告が表示されます。 [Yes (はい)] を選択して、プロットを表示します。
興味深い相関関係が表示されます。たとえば、technology は HP および labs と強い相関があります。 また、650 とも強い相関があります。これは、データセットの提供者の市外局番が 650 であるためです。
単語間の相関関係の数値は、 [Explore](探索) ウィンドウで確認できます。 興味深いことに、たとえば、technology は your および money と負の相関があります。
Rattle では、データセットを変換して、一般的な問題の一部を処理することができます。 たとえば、特徴のスケール変更、欠落値の補完、外れ値の処理、およびデータが欠落している変数または観測値の削除を行うことができます。 また、Rattle は観測値と変数の間の相関ルールを特定することもできます。 これらのタブについては、この入門チュートリアルでは説明しません。
Rattle では、クラスター分析を実行することもできます。 出力を読みやすくするために、いくつかの特徴を除外してみましょう。 [Data](データ) タブで、これらの 10 個の項目以外の各変数の横にある [Ignore](無視) を選択します。
- word_freq_hp
- word_freq_technology
- word_freq_george
- word_freq_remove
- word_freq_your
- word_freq_dollar
- word_freq_money
- capital_run_length_longest
- word_freq_business
- spam
[Cluster](クラスター) タブに戻ります。 [KMeans] を選択し、 [Number of clusters](クラスターの数) を 4 に設定します。 [実行] を選択します。 結果が出力ウィンドウに表示されます。 1 つのクラスターには高い頻度で george と hp が含まれているため、おそらく本物の仕事のメールでしょう。
基本的なデシジョン ツリー機械学習モデルを作成するには:
- [Model (モデル)] タブをクリックします。
- [Type](種類) で [Tree](ツリー) を選択します。
- [Execute (実行)] を選択して、出力ウィンドウにテキスト形式でツリーを表示します。
- [Draw (描画)] をクリックして、グラフィカル バージョンを表示します。 このデシジョン ツリーは、rpart を使用して前に作成したツリーに似ています。
Rattle の便利な機能に、複数の機械学習メソッドを実行し、それらをすばやく評価する機能があります。 手順は次のようになります。
- [Type](種類) で [All](すべて) を選択します。
- [実行] を選択します。
- Rattle の実行が完了すると、SVM のような任意の [Type](種類) の値を選択し、結果を表示できます。
- また、 [Evaluate](評価) タブを使用して、検証セットに対する各モデルのパフォーマンスを比較することもできます。たとえば、 [Error Matrix (誤差マトリックス)] を選択すると、検証セットに対する各モデルの混同行列、全体の誤差、および平均クラス誤差が表示されます。 また、ROC 曲線のプロット、感度解析の実行、および他の種類のモデル評価を行うこともできます。
モデルの構築が完了したら、 [Log](ログ) タブを選択して、セッション中に Rattle によって実行された R コードを表示します。 [Export (エクスポート)] をクリックすると、保存することができます。
注意
現在のリリースの Rattle にはバグがあります。 スクリプトを変更したり、スクリプトを使って後で手順を繰り返したりするには、ログのテキストの「Export this log ...」の前に # 文字を挿入する必要があります。
PostgreSQL と SQuirreL SQL
DSVM には、PostgreSQL がインストールされています。 PostgreSQL は、高度なオープン ソース リレーショナル データベースです。 このセクションでは、PostgreSQL に spambase データセットを読み込んでそのクエリを実行する方法を示します。
データを読み込む前に、localhost からのパスワード認証を許可する必要があります。 コマンド プロンプトで、次のコマンドを実行します。
sudo gedit /var/lib/pgsql/data/pg_hba.conf
構成ファイルの下部付近に、許可される接続の詳細を記述している複数の行があります。
# "local" is only for Unix domain socket connections:
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 ident
# IPv6 local connections:
host all all ::1/128 ident
ユーザー名とパスワードを使用してログインできるように、「IPv4 local connections」という行を、ident の代わりに md5 を使用するように変更します。
# IPv4 local connections:
host all all 127.0.0.1/32 md5
次に、PostgreSQL サービスを再起動します。
sudo systemctl restart postgresql
psql (PostgreSQL の対話型ターミナル) を組み込みの postgres ユーザーとして起動するには、このコマンドを実行します。
sudo -u postgres psql
ログインに使用した Linux アカウントのユーザー名を使用して、新しいユーザー アカウントを作成します。 パスワードを作成します。
CREATE USER <username> WITH CREATEDB;
CREATE DATABASE <username>;
ALTER USER <username> password '<password>';
\quit
psql にログインします。
psql
新しいデータベースにデータをインポートします。
CREATE DATABASE spam;
\c spam
CREATE TABLE data (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer);
\copy data FROM /home/<username>/spambase.data DELIMITER ',' CSV;
\quit
ここで、SQuirreL SQL (JDBC ドライバー経由でデータベースの操作に使用できるグラフィカル ツール) を使用して、データを探索し、いくつかのクエリを実行してみましょう。
開始するには、 [Applications](アプリケーション) メニューから SQuirreL SQL を開きます。 ドライバーを設定するには:
- [Windows]>[View Drivers](ドライバーの表示) を選択します。
- [PostgreSQL] を右クリックし、 [Modify Driver](ドライバーの変更) を選択します。
- [Extra Class Path](その他のクラス パス)>[Add](追加) を選択します。
- [File Name](ファイル名) に「 /usr/share/java/jdbcdrivers/postgresql-9.4.1208.jre6.jar」と入力します。
- [Open (開く)] を選択します。
- [List Drivers](ドライバーの一覧表示) を選択します。 [Class Name](クラス名) で、org.postgresql.Driver を選択し、 [OK] を選択します。
ローカル サーバーへの接続を設定するには:
- [Windows]>[View Aliases](エイリアスの表示) を選択します。
- + ボタンを選択して、新しいエイリアスを作成します。 新しいエイリアス名として、「Spam database」と入力します。
- [Driver](ドライバー) で、 [PostgreSQL] を選択します。
- URL を「jdbc:postgresql://localhost/spam」に設定します。
- ユーザー名とパスワードを入力します。
- [OK] を選択します。
- [Connection (接続)] ウィンドウを開くには、Spam database エイリアスをダブルクリックします。
- [接続] を選択します。
クエリを実行するには:
- [SQL] タブをクリックします。
- [SQL] タブの上部にある クエリ ボックスに、基本的なクエリ (
SELECT * from data;など) を入力します。 - Ctrl + Enter キーを押して、クエリを実行します。 既定では、SQuirreL SQL はクエリから先頭の 100 行を返します。
このデータを探索するために実行できるクエリは他にもたくさんあります。 たとえば、 make という単語の出現頻度がスパムとハムでどのように異なるかを調べるには、次のクエリを実行します。
SELECT avg(word_freq_make), spam from data group by spam;
また、3d が高い頻度で含まれるメールの特徴を調べます。
SELECT * from data order by word_freq_3d desc;
3d が高い頻度で含まれるメールのほとんどは、明らかにスパムです。 この情報は、メールを分類する予測モデルの構築に役立つ可能性があります。
PostgreSQL データベースに格納されたデータを使用して機械学習を実行する場合は、MADlib の使用を検討してください。
Azure Synapse Analytics (旧称 SQL DW)
Azure Synapse Analytics は、クラウドベースのスケールアウト データベースであり、リレーショナルか非リレーショナルかを問わず、大規模なデータを処理できます。 詳細については、Azure Synapse Analytics に関する記事をご覧ください。
データ ウェアハウスに接続し、テーブルを作成するには、コマンド プロンプトから次のコマンドを実行します。
sqlcmd -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -I
sqlcmd プロンプトで、このコマンドを実行します。
CREATE TABLE spam (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer) WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN);
GO
bcp を使用してデータをコピーします。
bcp spam in spambaseHeaders.data -q -c -t ',' -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -F 1 -r "\r\n"
注意
ダウンロードしたファイルには、Windows 形式の行の終わりが含まれています。 bcp ツールは、Unix 形式の行の終わりを想定します。 -r フラグを使用して bcp に指示します。
次に、sqlcmd を使用してクエリを実行します。
select top 10 spam, char_freq_dollar from spam;
GO
SQuirreL SQL を使用してクエリを実行することもできます。 SQL Server JDBC ドライバーを使用して PostgreSQL の場合と同様の手順を実行します。 JDBC ドライバーは /usr/share/java/jdbcdrivers/sqljdbc42.jar フォルダーにあります。