Python を使用して Computer Vision モデルをトレーニングするために AutoML を設定する (v1)
適用対象:  Python SDK azureml v1
Python SDK azureml v1
重要
この記事の Azure CLI コマンドの一部では、Azure Machine Learning 用に azure-cli-ml、つまり v1 の拡張機能を使用しています。 v1 拡張機能のサポートは、2025 年 9 月 30 日に終了します。 その日付まで、v1 拡張機能をインストールして使用できます。
2025 年 9 月 30 日より前に、ml (v2) 拡張機能に移行することをお勧めします。 v2 拡張機能の詳細については、Azure ML CLI 拡張機能と Python SDK v2 に関するページを参照してください。
重要
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー バージョンは、サービス レベル アグリーメントなしに提供されます。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、Azure Machine Learning Python SDK の自動 ML を使用して、画像データに対する Computer Vision モデルをトレーニングする方法を説明します。
自動 ML では、画像分類、物体検出、インスタンス セグメント化などの Computer Vision タスク用のモデル トレーニングがサポートされています。 現在、Computer Vision タスク用の AutoML モデルの作成は、Azure Machine Learning Python SDK を介してサポートされています。 結果として得られる実験の実行、モデル、出力には、Azure Machine Learning スタジオ UI からアクセスできます。 画像データに対する Computer Vision タスク用の自動 ML の詳細を確認します。
Note
Computer Vision タスク用の自動 ML は、Azure Machine Learning Python SDK を介してのみ使用できます。
前提条件
Azure Machine Learning ワークスペース。 ワークスペースを作成するには、「ワークスペース リソースの作成」を参照してください。
Azure Machine Learning Python SDK がインストールされていること。 SDK をインストールするには、次のいずれかを行います。
コンピューティング インスタンスを作成します。これにより、SDK が自動的にインストールされ、ML ワークフロー用に事前構成されます。 詳細については、「Azure Machine Learning コンピューティング インスタンスの作成と管理」を参照してください。
SDK の既定のインストールが含まれる、
automlパッケージを自分でインストールします。
Note
Python 3.7 と 3.8 のみ、Computer Vision タスクの自動 ML のサポートと互換性があります。
タスクの種類の選択
画像の自動 ML では、次のタスクの種類がサポートされています。
| タスクの種類 | AutoMLImage 構成構文 |
|---|---|
| 画像の分類 | ImageTask.IMAGE_CLASSIFICATION |
| 画像分類の複数ラベル | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| 画像の物体検出 | ImageTask.IMAGE_OBJECT_DETECTION |
| 画像インスタンスのセグメント化 | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
このタスクの種類は必須のパラメーターであり、AutoMLImageConfig の task パラメーターを使用して渡されます。
次に例を示します。
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
データをトレーニングして検証する
Computer Vision モデルを生成するには、ラベル付き画像データを Azure Machine Learning TabularDataset の形式でモデル トレーニングの入力として取り込む必要があります。 データ ラベル付けプロジェクトからエクスポートした TabularDataset を使用するか、ラベル付けされたトレーニング データで新しい TabularDataset を作成できます。
トレーニング データの形式が異なる (pascal VOC や COCO など) 場合は、サンプル ノートブックに含まれるヘルパー スクリプトを適用して、データを JSONL に変換できます。 自動 ML で Computer Vision タスク用にデータを準備する方法の詳細を確認してください。
警告
JSONL 形式のデータからの TabularDatasets の作成は、この機能用の SDK を使用した場合にのみサポートされます。 現時点では、UI によるデータセットの作成はサポートされていません。 現時点では、UI は StreamInfo データ型 (JSONL 形式の画像 URL に使用されるデータ型) を認識しません。
Note
AutoML の実行を送信できるようにするには、トレーニング データセットに少なくとも 10 個の画像が含まれている必要があります。
JSONL スキーマのサンプル
TabularDataset の構造は、手元のタスクによって異なります。 Computer Vision タスクの種類の場合、次のフィールドで構成されます。
| フィールド | 説明 |
|---|---|
image_url |
StreamInfo オブジェクトとしてファイルパスが含まれます |
image_details |
画像メタデータ情報は、高さ、幅、および形式で構成されます。 このフィールドは省略可能であるため、存在する場合と存在しない場合があります。 |
label |
タスクの種類に基づく画像ラベルの JSON 表現。 |
画像分類のサンプル JSONL ファイルを次に示します。
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
次のコードは、物体検出のサンプル JSONL ファイルです。
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
データの使用
データが JSONL 形式になったら、次のコードを使用して TabularDataset を作成できます。
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
自動 ML では、Computer Vision タスク用のトレーニングまたは検証データ サイズに制約がありません。 データセットの最大サイズは、データセットの背後にあるストレージ レイヤー (つまり BLOB ストア) によってのみ制限されます。 画像またはラベルの最小数はありません。 ただし、出力モデルが十分にトレーニングされるように、ラベルあたり少なくとも 10 から 15 のサンプルから開始することが推奨されます。 ラベルやクラスの合計数が多いほど、ラベルごとに必要なサンプルが多くなります。
トレーニング データは必須であり、training_data パラメーターを使用して渡されます。 必要に応じて、AutoMLImageConfig の validation_data パラメーターで、モデルに使用する検証データセットとして別の TabularDataset を指定できます。 検証データセットを指定していない場合、別の値で validation_size 引数を渡さない限り、トレーニング データの 20% が既定で検証に使用されます。
次に例を示します。
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
実験を実行するために計算する
モデル トレーニングを実施する自動 ML のコンピューティング ターゲットを指定します。 Computer Vision タスク用の自動 ML モデルでは、GPU SKU が必要であり、NC ファミリと ND ファミリがサポートされています。 トレーニングを高速化するには NCsv3 シリーズ (v100 GPU 搭載) が推奨されます。 マルチ GPU VM SKU を使用するコンピューティング ターゲットで、複数の GPU を利用することでもトレーニングが高速化されます。 さらに、複数のノードでコンピューティング ターゲットを設定する場合に、モデルのハイパーパラメーターを調整するときに、並列処理を使用してモデルのトレーニングを高速化できます。
注意
コンピューティング先としてコンピューティング インスタンスを使っている場合は、複数の AutoML ジョブが同時に実行されていないことを確認してください。 また、実験リソースで max_concurrent_iterations が 1 に設定されていることを確認してください。
コンピューティング ターゲットは必須のパラメーターであり、AutoMLImageConfig の compute_target パラメーターを使用して渡されます。 次に例を示します。
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
モデル アルゴリズムとハイパーパラメーターを構成する
Computer Vision タスクのサポートによって、モデル アルゴリズムを制御して、ハイパーパラメーターをスイープできます。 これらのモデル アルゴリズムとハイパーパラメーターは、スイープのためのパラメーター空間として渡されます。
モデル アルゴリズムは必須であり、model_name パラメーターを使用して渡されます。 1 つの model_name を指定するか、複数から選択できます。
サポートされているモデル アルゴリズム
次の表は、各 Computer Vision タスクでサポートされているモデルをまとめたものです。
| タスク | モデル アルゴリズム | 文字列リテラル構文default_model* を * で示す |
|---|---|---|
| 画像の分類 (複数クラスおよび複数ラベル) |
MobileNet: モバイル アプリケーション用の軽量モデル ResNet: 残差ネットワーク ResNeSt: スプリット アテンション ネットワーク SE-ResNeXt50: スクイーズおよび励起ネットワーク ViT: Vision Transformer ネットワーク |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (小) vitb16r224* (基本) vitl16r224 (大) |
| オブジェクトの検出 | YOLOv5: 1 ステージ オブジェクト検出モデル Faster RCNN ResNet FPN: 2 ステージ オブジェクト検出モデル RetinaNet ResNet FPN: Focal Loss によってクラスの不均衡に対処する 注: YOLOv5 モデルのサイズについては、 model_sizeハイパーパラメーターを参照してください。 |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| インスタンスのセグメント化 | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
モデル アルゴリズムの制御に加えて、モデルのトレーニングに使用されるハイパーパラメーターを調整できます。 公開されているハイパーパラメーターの多くはモデルに依存しませんが、ハイパーパラメーターがタスク固有またはモデル固有である場合があります。 これらのインスタンスで使用できるハイパーパラメーターの詳細について確認してください。
データの拡張
一般に、ディープ ラーニング モデルのパフォーマンスは、多くの場合にデータが多いほど向上する可能性があります。 データの拡張は、データのサイズとデータセットの多様性を拡張するための実用的な手法であり、オーバーフィットを防ぎ、目に見えないデータに対するモデルの一般化機能を改善するのに役立ちます。 自動 ML では、入力画像をモデルにフィードする前に、Computer Vision タスクに基づいてさまざまなデータ拡張手法が適用されます。 現在、データ拡張を制御するために公開されたハイパーパラメーターはありません。
| タスク | 影響を受けるデータセット | 適用されるデータ拡張手法 |
|---|---|---|
| 画像分類 (複数クラスおよび複数ラベル) | トレーニング 検証とテスト |
ランダムなサイズ変更とトリミング、左右反転、色ジッター (輝度、コントラスト、彩度、色相)、チャネルごとの ImageNet の平均と標準偏差を使用した正規化 サイズ変更、中心のトリミング、正規化 |
| 物体検出、インスタンスのセグメント化 | トレーニング 検証とテスト |
境界ボックス周囲のランダムなトリミング、展開、左右反転、正規化、サイズ変更 正規化、サイズ変更 |
| yolov5 を使用した物体検出 | トレーニング 検証とテスト |
モザイク、ランダム アフィン (回転、平行移動、スケーリング、傾斜)、左右反転 レターボックスのサイズ変更 |
実験の設定を構成する
最適なモデルとハイパーパラメーターを検索するために大きなスイープを実行する前に、既定値を使用して最初のベースラインを取得することが推奨されます。 次に、複数のモデルとそのパラメーターをスイープする前に、同じモデルで複数のハイパーパラメーターを調べることができます。 このように、より反復的なアプローチを採用することができます。複数のモデルとそれぞれに複数のハイパーパラメーターがあることで、検索領域が指数関数的に拡大し、最適な構成を見つけるためにより多くの反復処理が必要になるためです。
特定のアルゴリズム (たとえば yolov5) に既定のハイパーパラメーター値を使用する場合、次のように、AutoML 画像実行の構成を指定できます。
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
ベースライン モデルを構築したら、モデル アルゴリズムとハイパーパラメーター空間をスイープするために、モデルのパフォーマンスを最適化することができます。 次のサンプル構成を使用して、各アルゴリズムのハイパーパラメーターをスイープし、learning_rate、オプティマイザー、lr_scheduler などの値の範囲から選択して、最適な主要メトリックでモデルを生成できます。 ハイパーパラメーター値を指定していない場合は、指定したアルゴリズムに既定値が使われます。
主要メトリック
モデルの最適化とハイパーパラメーターの調整に使用される主要メトリックは、タスクの種類によって異なります。 他の主要メトリック値の使用は現在サポートされていません。
- IMAGE_CLASSIFICATION の
accuracy - IMAGE_CLASSIFICATION_MULTILABEL の
iou - IMAGE_OBJECT_DETECTION の
mean_average_precision - IMAGE_INSTANCE_SEGMENTATION の
mean_average_precision
実験の予算
必要に応じて、experiment_timeout_hours を使用して AutoML Vision 実験の最大時間予算 (実験が終了するまでの時間単位での時間) を指定できます。 何も指定しない場合、既定の実験タイムアウトは 7 日 (最大 60 日) です。
モデルのハイパーパラメーターのスイープ
Computer Vision モデルをトレーニングする際のモデルのパフォーマンスは、選択したハイパーパラメーターの値に大きく依存します。 最適なパフォーマンスを得るために、ハイパーパラメーターを調整する必要がある場合がよくあります。 自動 ML の Computer Vision タスクのサポートにより、ハイパーパラメーターをスイープして、モデルに最適な設定を見つけることができます。 この機能は、Azure Machine Learning のハイパーパラメーター調整機能に該当します。 ハイパーパラメーターを調整する方法を確認してください。
パラメーター検索空間を定義する
パラメーター空間でスイープするモデル アルゴリズムとハイパーパラメーターを定義できます。
- 各タスクの種類でサポートされているモデル アルゴリズムの一覧については、「モデル アルゴリズムとハイパーパラメーターを構成する」を参照してください。
- 各コンピューター ビジョン タスクの種類のハイパーパラメーターについては、コンピューター ビジョン タスク用のハイパーパラメーターに関する記事を参照してください。
- 不連続および連続のハイパーパラメーターでサポートされているディストリビューションの詳細を参照してください。
スイープのサンプリング方法
ハイパーパラメーターをスイープする場合は、定義されたパラメーター空間のスイープに使用するサンプリング方法を指定する必要があります。 現在のところ、hyperparameter_sampling パラメーターで次のサンプリング方法がサポートされています。
注意
現在、ランダム サンプリングとグリッド サンプリングのみが条件付きハイパーパラメーター空間をサポートしています。
早期終了ポリシー
早期終了ポリシーによって、パフォーマンスの低い実行を自動的に終了できます。 早期終了によって、コンピューティング効率が向上し、そうでなければ、あまり見込みのない構成で費やされてしまうコンピューティング リソースを節約できます。 画像の自動 ML では、early_termination_policy パラメーターを使用した次の早期終了ポリシーがサポートされています。 終了ポリシーが指定されていない場合は、すべての構成が完了するまで実行されます。
ハイパーパラメーター スイープの早期終了ポリシーを構成する方法の詳細を確認してください。
スイープのリソース
ハイパーパラメーター スイープに費やされるリソースを制御するには、スイープに iterations および max_concurrent_iterations を指定します。
| パラメーター | 詳細 |
|---|---|
iterations |
スイープする構成の最大数に必要なパラメーター。 1 ~ 1000 の整数にする必要があります。 特定のモデル アルゴリズムで既定のハイパーパラメーターだけを探索する場合は、このパラメーターを 1 に設定します。 |
max_concurrent_iterations |
同時に実行できる実行の最大数。 指定しない場合、すべての実行が並列で起動されます。 指定する場合は、1 ~ 100 の整数にする必要があります。 注: 同時実行の数は、指定したコンピューティング ターゲットで使用可能なリソースに基づいて制御されます。 目的の同時実行可能性のために、使用可能なリソースをコンピューティング先に確保する必要があります。 |
注意
スイープ構成の完全なサンプルについては、このチュートリアルを参照してください。
引数
パラメーター空間スイープ中に変更されない固定の設定またはパラメーターを引数として渡すことができます。 引数は名前と値のペアで渡され、名前の先頭に長鎖線を付ける必要があります。
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
増分トレーニング (省略可能)
トレーニングの実行が完了したら、トレーニング済みのモデルのチェックポイントを読み込むことによって、モデルをさらにトレーニングすることができます。 増分トレーニングには、同じデータセットまたは別のデータセットを使用することができます。
増分トレーニングに使用できるオプションは 2 つあります。 次のとおりです。
- チェックポイントの読み込み元となる実行 ID を渡す。
- FileDataset を使用してチェックポイントを渡す。
実行 ID を使用してチェックポイントを渡す
目的のモデルから実行 ID を見つけるには、次のコードを使用します。
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
実行 ID を使用してチェックポイントを渡すには、checkpoint_run_id パラメーターを使用する必要があります。
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
FileDataset を使用してチェックポイントを渡す
FileDataset を使用してチェックポイントを渡すには、checkpoint_dataset_id と checkpoint_filename パラメーターを使用する必要があります。
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
実行の送信
AutoMLImageConfig オブジェクトの準備が整ったら、実験を送信できます。
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
出力と評価のメトリック
AutoML トレーニングの実行によって、出力モデル ファイル、評価メトリック、ログ、およびスコアリング ファイルや環境ファイルなどのデプロイ成果物が生成され、それらは子実行の出力、ログおよびメトリック タブから表示できます。
ヒント
「実行結果の表示」セクションからジョブ結果に移動する方法を確認してください。
実行のたびに提供されるパフォーマンス グラフおよびメトリックの定義と例については、「自動化機械学習実験の結果を評価する」を参照してください
モデルを登録して展開する
実行が完了したら、最適な実行 (最適な主要メトリックになった構成) から作成されたモデルを登録できます
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
使用するモデルを登録したら、それを Azure Container Instances (ACI) または Azure Kubernetes Service (AKS) に Web サービスとしてデプロイできます。 ACI はデプロイをテストするための最適なオプションであるのに対し、AKS は高スケールの運用環境での使用により適しています。
この例では、AKS に Web サービスとしてモデルをデプロイします。 AKS にデプロイするには、まず AKS コンピューティング クラスターを作成するか、既存の AKS クラスターを使用します。 デプロイ クラスターには、GPU または CPU VM SKU のいずれかを使用できます。
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
次に、モデルを含む Web サービスを設定する方法を説明する推論構成を定義できます。 推論構成では、スコアリング スクリプトとトレーニング実行の環境を使用できます。
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
その後、AKS Web サービスとしてモデルをデプロイできます。
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
または、Azure Machine Learning スタジオ UI からモデルをデプロイすることもできます。 自動 ML 実行の [モデル] タブで、デプロイするモデルに移動し、[デプロイ] を選択します。
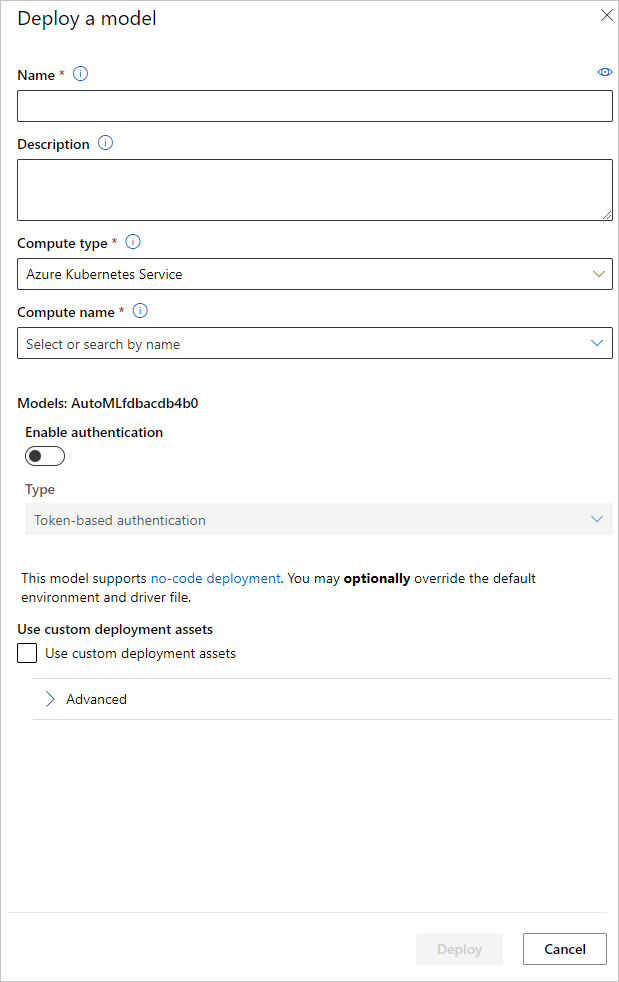
[モデルのデプロイ] ウィンドウでモデルのデプロイに使用するモデル デプロイ エンドポイント名と推論クラスターを構成できます。
推論構成を更新する
前の手順では、スコアリング ファイル outputs/scoring_file_v_1_0_0.py を最適なモデルからローカル score.py ファイルにダウンロードし、それを使用して InferenceConfig オブジェクトを作成しました。 このスクリプトは、ダウンロードして InferenceConfig を作成する前に、必要に応じてモデル固有の推論設定を変更するために変更できます。 たとえば、次は、スコアリング ファイルのモデルを初期化するコード セクションです。
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
各タスク (および一部のモデル) では、model_settings ディクショナリ内に一連のパラメーターがあります。 既定で、トレーニングおよび検証時に使用されたパラメーターに同じ値を使用します。 推論にモデルを使用するときに必要な動作に応じて、これらのパラメーターを変更できます。 各タスクの種類とモデルのパラメーターの一覧を次に示します。
| タスク | パラメーター名 | Default |
|---|---|---|
| 画像分類 (複数クラスおよび複数ラベル) | valid_resize_sizevalid_crop_size |
256 224 |
| オブジェクトの検出 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
yolov5 を使用した物体検出 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 中 0.1 0.5 |
| インスタンスのセグメント化 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
タスク固有のハイパーパラメーターの詳細については、「自動機械学習におけるコンピューター ビジョン タスクのハイパーパラメーター」を参照してください。
タイルを使用し、タイルの動作を制御する場合は、パラメーター tile_grid_size、tile_overlap_ratio、tile_predictions_nms_thresh を使用できます。 これらのパラメーターの詳細については、AutoML を使用した小さな物体検出モデルのトレーニングに関するページを確認してください。
サンプルの Notebook
GitHub の自動機械学習サンプルのノートブック リポジトリで詳しいコード サンプルやユース ケースを確認してください。 Computer Vision モデルの構築に固有のサンプルについては、"image-" プレフィックスが付いたフォルダーを確認してください。