Azure Machine Learning で画像にラベルを付けるデータのラベル付けプロジェクトを作成して実行する方法について説明します。 このタスクを補助するために、支援付き機械学習 (ML) データ ラベル付け、または人間参加型のラベル付けを使用します。
分類、物体検出 (境界ボックス)、インスタンスのセグメント化 (多角形)、またはセマンティック セグメント化 (プレビュー) のラベルを設定します。
Azure Machine Learning でデータのラベル付けツールを使用して、テキスト ラベル付けプロジェクトを作成することもできます。
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 プレビュー バージョンはサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
画像のラベル付け機能
Azure Machine Learning のデータのラベル付けは、以下のように、データのラベル付けプロジェクトを作成、管理、監視するために使用できるツールです。 これは次の目的で使用されます。
- データ、ラベル、チーム メンバーを調整して、ラベル付けタスクを効率的に管理する。
- 進行状況を追跡し、未完了のラベル付けタスクのキューを維持する。
- プロジェクトを開始および停止し、ラベル付けの進行状況を制御する。
- ラベル付きのデータを確認し、Azure Machine Learning データセットとしてエクスポートする。
重要
Azure Machine Learning データ ラベル付けツールで操作する画像データは、Azure Blob Storage データストアで使用できる必要があります。 既存のデータストアがない場合は、プロジェクトの作成時にデータ ファイルを新しいデータストアにアップロードできます。
画像データには、次のいずれかのファイル拡張子を持つ任意のファイルを指定できます。
.jpg.jpeg.png.jpe.jfif.bmp.tif.tiff.dcm.dicom
各ファイルはラベル付けされる項目です。
テーブル内の画像が上記のいずれかの形式である場合、MLTable データ資産を画像ラベル付けプロジェクトへの入力として使用することもできます。 詳細については、MLTable データ資産を管理する方法に関する記事を参照してください。
前提条件
次の項目を使用して、Azure Machine Learning で画像のラベル付けを設定します。
- ローカル ファイルまたは Azure Blob Storage 内にあるラベル付け対象のデータ。
- 適用するラベルのセット。
- ラベル付けに関する指示。
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
- Azure Machine Learning ワークスペース。 Azure Machine Learning ワークスペースを作成する方法に関するページを参照してください。
イメージのラベル付けプロジェクトを作成する
ラベル付けプロジェクトは、Azure Machine Learning で管理します。 Machine Learning の [データのラベル付け] ページを使用して、プロジェクトを管理します。
データが既に Azure Blob Storage 内にある場合は、ラベル付けプロジェクトを作成する前に、それをデータストアとして使用できるようにします。
プロジェクトを作成するには、 [プロジェクトの追加] を選択します。
[プロジェクト名] に、プロジェクトの名前を入力します。
プロジェクトを削除しても、そのプロジェクト名を再利用することはできません。
画像ラベル付けプロジェクトを作成するには、[メディアの種類] で [画像] を選択します。
[ラベル付けタスクの種類] で、シナリオのオプションを選択します。
- 一連のラベルから画像に 1 つのラベルのみを適用するには、[画像分類マルチクラス] を選択します。
- 一連のラベルから画像に 1 つ以上のラベルを適用するには、[画像分類マルチラベル] を選択します。 たとえば、犬の写真には "犬" と "日中" の両方のラベルが付けられる可能性があります。
- 画像内の各オブジェクトにラベルを割り当て、境界ボックスを追加するには、[オブジェクト識別 (境界ボックス)] を選択します。
- 画像内の各オブジェクトにラベルを割り当て、各オブジェクトの周りに多角形を描画するには、[多角形 (インスタンスのセグメント化)] を選択します。
- 画像にマスクを描画し、ピクセル レベルでラベル クラスを割り当てるには、[セマンティック セグメント化 (プレビュー)] を選択します。
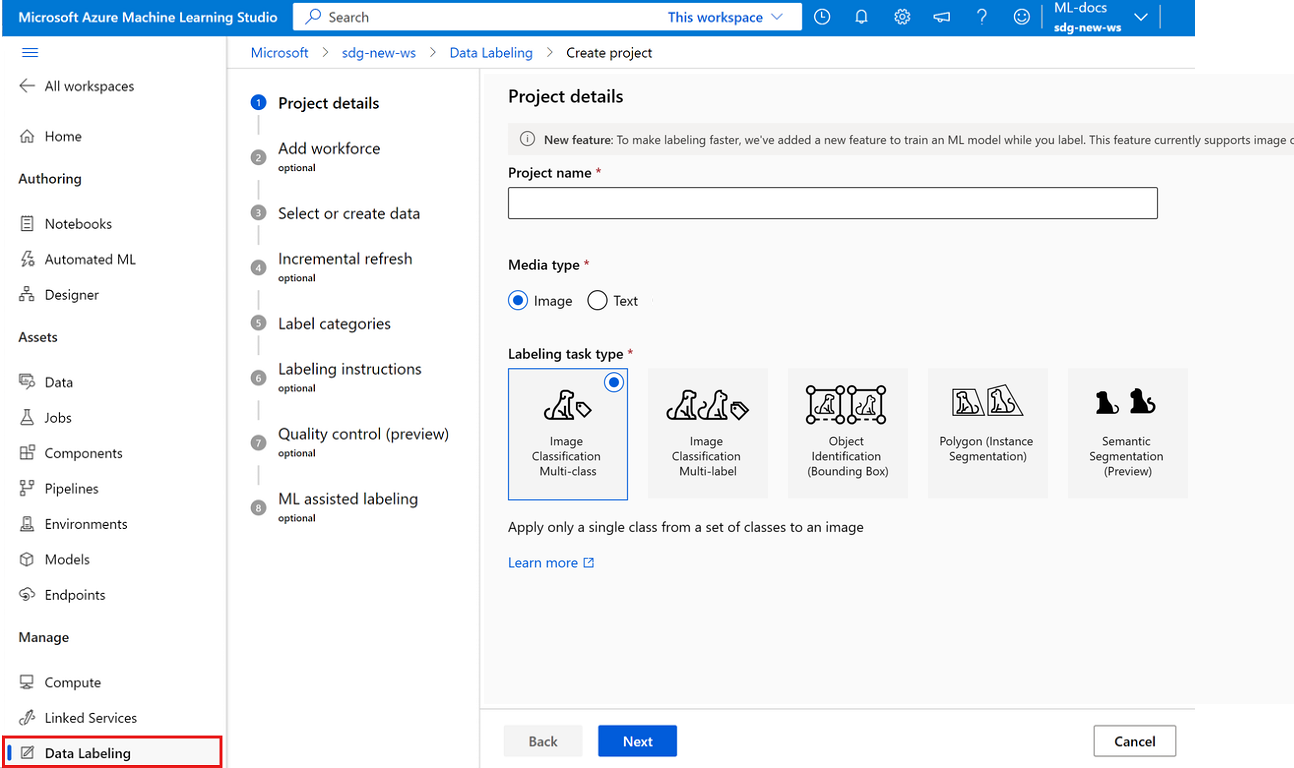
[次へ] を選択して続行します。
従業員を追加する (省略可能)
Azure Marketplace からデータのラベル付け会社と契約している場合のみ、 [Azure Marketplace でベンダーのラベル付け会社を利用する] を選択します。 次に、ベンダーを選択します。 ベンダーがリストに表示されない場合は、このオプションを解除します。
必ず最初にベンダーに連絡してから、契約に署名してください。 詳細については、データのラベル付けベンダー企業との連携 (プレビュー) に関するページを参照してください。
[次へ] を選択して続行します。
ラベル付けの対象データを指定する
対象のデータが含まれるデータセットを既に作成済みの場合は、[既存のデータセットを選択します] ドロップダウンからそのデータセットを選択します。
[データセットを作成する] を選んで、既存の Azure データストアを使うか、ローカル ファイルをアップロードすることもできます。
注意
1 つのプロジェクトに 50 万個を超えるファイルを含めることはできません。 データセットのファイル数がこれを超える場合は、最初の 50 万件のファイルだけが読み込まれます。
データ列マッピング (プレビュー)
MLTable データ資産を選択すると、さらに [データ列マッピング] ステップが表示され、画像の URL を含む列を指定できます。
[イメージ] フィールドにマップする列を指定する必要があります。 必要に応じて、データに存在する他の列をマップすることもできます。 たとえば、データに [ラベル] 列が含まれている場合は、それを [カテゴリ] フィールドにマップできます。 データに [信頼度] 列が含まれている場合は、それを [信頼度] フィールドにマップできます。
前のプロジェクトからラベルをインポートする場合、ラベルは、作成するラベルと同じ形式にする必要があります。 たとえば、境界ボックス ラベルを作成する場合は、インポートするラベルも境界ボックス ラベルである必要があります。
インポート オプション (プレビュー)
[データ列マッピング] ステップに [カテゴリ] 列を含める場合は、[インポート オプション] を使用して、ラベル付きデータの処理方法を指定します。
[イメージ] フィールドにマップする列を指定する必要があります。 必要に応じて、データに存在する他の列をマップすることもできます。 たとえば、データに [ラベル] 列が含まれている場合は、それを [カテゴリ] フィールドにマップできます。 データに [信頼度] 列が含まれている場合は、それを [信頼度] フィールドにマップできます。
前のプロジェクトからラベルをインポートする場合、ラベルは、作成するラベルと同じ形式にする必要があります。 たとえば、境界ボックス ラベルを作成する場合は、インポートするラベルも境界ボックス ラベルである必要があります。
Azure データストアからデータセットを作成する
多くの場合、ローカル ファイルをアップロードできます。 ただし、Azure Storage Explorer には、大量のデータをより高速かつ堅牢に転送する方法が用意されています。 既定のファイル移動方法としては、Storage Explorer をお勧めします。
Blob Storage に既に格納済みのデータからデータセットを作成するには:
- [作成] を選択します
- [名前] に、データセットの名前を入力します。 必要に応じて、説明を入力します。
- [データセットの種類] が [ファイル] に設定されていることを確認します。 画像の場合、データセットの種類としてファイルのみがサポートされています。
- [次へ] を選択します。
- [Azure ストレージから] を選んでから、[次へ] を選択します。
- データストアを選んでから、[次へ] を選択します。
- データがお使いの Blob Storage 内のサブフォルダーにある場合は、[参照] を選んでパスを選択します。
- 選んだパスのサブフォルダー内にあるすべてのファイルを含めるには、パスに
/**を追加します。 - 現在のコンテナーとそのサブフォルダー内にあるすべてのデータを含めるには、
**/*.*を追加します。
- 選んだパスのサブフォルダー内にあるすべてのファイルを含めるには、パスに
- [作成] を選択します
- 作成したデータ資産を選びます。
アップロードしたデータからデータセットを作成する
データを直接アップロードするには:
- [作成] を選択します
- [名前] に、データセットの名前を入力します。 必要に応じて、説明を入力します。
- [データセットの種類] が [ファイル] に設定されていることを確認します。 画像の場合、データセットの種類としてファイルのみがサポートされています。
- [次へ] を選択します。
- [ローカル ファイルから] を選んでから、[次へ] を選択します。
- (省略可能) データストアを選びます。 既定値のままで、Machine Learning ワークスペースの既定の BLOB ストア (workspaceblobstore) にアップロードすることもできます。
- [次へ] を選択します。
- [アップロード]>[ファイルのアップロード] または [アップロード]>[フォルダーのアップロード] を選んで、アップロードするローカル ファイルまたはフォルダーを選択します。
- ブラウザー ウィンドウでファイルまたはフォルダーを見つけて、[開く] を選びます。
- すべてのファイルとフォルダーを指定するまで、[アップロード] を選択し続けます。
- 必要に応じて、[既に存在する場合は上書きする] チェック ボックスをオンにすることもできます。 ファイルおよびフォルダーの一覧を確認します。
- [次へ] を選択します。
- 詳細を確認します。 [戻る] を選択して設定を変更するか、[作成] を選択してデータセットを作成します。
- 最後に、作成したデータ資産を選びます。
増分更新を構成する
データセットに新しいデータ ファイルを追加する予定がある場合は、増分更新を使用して、新しいファイルをプロジェクトに追加します。
[一定の間隔での増分更新を有効にする] が設定されている場合、ラベル付けの完了率に基づいて、プロジェクトに追加する新しいファイルがないかどうかデータセットが定期的にチェックされます。 プロジェクトに最大 50 万個のファイルが含まれている場合、新しいデータのチェックは停止されます。
プロジェクトでデータストア内の新しいデータを継続的に監視する場合は、[一定の間隔での増分更新を有効にする] を選択します。
データストアの新しいファイルをプロジェクトに自動追加しない場合は、選択を解除します。
重要
増分更新が有効な場合は、更新するデータセットの新しいバージョンを作成しないでください。 自動追加する場合、データのラベル付けプロジェクトが初期バージョンにピン留めされているため、更新は表示されません。 代わりに、Azure Storage Explorer を使用して、Blob Storage 内の適切なフォルダーにあるデータを変更します。
また、データを削除しないでください。 プロジェクトで使用するデータセットからデータを削除すると、プロジェクトでエラーが発生します。
プロジェクトの作成後、[詳細] タブを使用して増分更新を変更し、最終更新のタイムスタンプを表示し、データの即時更新を要求します。
ラベル クラスを指定する
[ラベル カテゴリ] ページで、データを分類するためのクラスのセットを指定します。
適切なクラスを選択できるかどうかは、ラベラーの正確さと速さに影響します。 たとえば、植物や動物の属や種を略さずに使用するのではなく、フィールド コードを使用したり属を省略したりします。
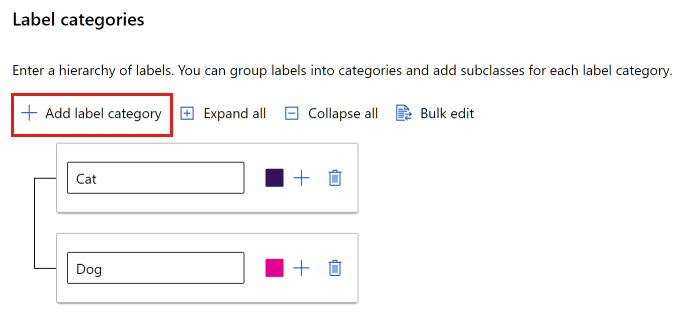
単純なリストを使用することも、ラベルのグループを作成することもできます。
単純なリストを作成するには、[ラベル カテゴリの追加] を選択して各ラベルを作成します。
異なるグループにラベルを作成するには、[ラベル カテゴリの追加] を選択して最上位レベルのラベルを作成します。 次に、各最上位レベルの下にあるプラス記号 (+) を選択して、そのカテゴリの次のレベルのラベルを作成します。 任意のグループに対して最大 6 つのレベルを作成できます。
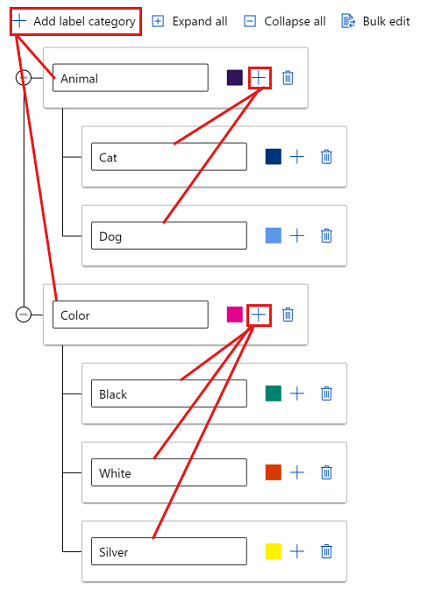
タグ付けプロセス中に、任意のレベルのラベルを選択できます。 たとえば、ラベル Animal、Animal/Cat、Animal/Dog、Color、Color/Black、Color/White、Color/Silver は、すべてラベルの選択肢として使用できます。 マルチラベル プロジェクトでは、各カテゴリのいずれかを選択する必要はありません。 これを意図している場合は、手順にこの情報を含めてください。
画像のラベル付けタスクを説明する
ラベル付けタスクをわかりやすく説明することが重要です。 [ラベル付けの手順] ページで、ラベル付けの手順に関する外部サイトへのリンクを追加できます。または、ページ上のエディット ボックスに手順を入力することもできます。 指示は、タスク指向で、対象ユーザーに適したものにします。 次の質問を考慮してください。
- どのようなラベルがラベラーに表示され、どのような方法で選択しますか。 参照する参照テキストはありますか。
- 適切なラベルが見あたらない場合はどうすればよいですか。
- 適切に見えるラベルが複数ある場合はどうすればよいですか。
- どのような信頼度しきい値をラベルに適用する必要がありますか。 確実にわからない場合は、ラベラーに最善の推測で選択させますか。
- 対象のオブジェクトが部分的にオクルージョンされている場合、または重なっている場合は、どうすればよいですか。
- 対象のオブジェクトが画像の端によってクリップされている場合は、どうすればよいですか。
- ラベルを送信した後に間違いに気付いた場合はどうすればよいですか。
- 光の状態が良くない、反射している、ぼやけている、望ましくない背景が映り込んでいる、カメラの角度がおかしいなど、画質問題が判明した場合はどうしますか。
- 複数のレビュー担当者がラベルの適用について異なる意見を持っている場合、どうしたらよいでしょうか。
境界ボックスについては、次のような重要な質問があります。
- このタスクでは境界ボックスはどのように定義されていますか。 完全にオブジェクトの内側に配置すべきですか、それとも外側に配置するべきですか。 できるだけ近くなるようにトリミングする必要がありますか、それともある程度の余白は許容されますか。
- 境界ボックスを定義する際にラベラーがどの程度の注意と一貫性を適用することを期待しますか。
- 各ラベル クラスのビジュアル定義はどのようなものですか。 各クラスに対して標準、エッジ、カウンターの各ケースの一覧を提供することはできますか。
- オブジェクトがとても小さい場合、ラベルはどうすればよいですか。 オブジェクトとしてラベル付けすべきですか、それともそのオブジェクトを背景として無視すべきですか。
- 画像に一部しか写っていないオブジェクトの場合、ラベラーはどのように処理すべきですか。
- オブジェクトの一部が他のオブジェクトの背後に隠れている場合、ラベラーはどのように処理すべきですか。
- 明確な境界のないオブジェクトの場合、ラベラーはどのように処理すべきですか。
- 対象のオブジェクト クラスではなく、関連するオブジェクトの種類と視覚的に似ているオブジェクトの場合、ラベラーはどのように処理すべきですか。
注意
ラベラーは、番号キー 1 から 9 を使用して最初の 9 つのラベルを選択できます。 この情報を手順に含めることをお勧めします。
品質管理 (プレビュー)
より正確なラベルを取得するには、[品質管理] ページを使用して、各項目を複数のラベラーに送信します。
重要
合意ラベル付けは、現在、パブリック プレビュー段階にあります。
プレビュー バージョンはサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。
詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
各項目が複数のラベラーに送信されるようにするには、[合意によるラベル付けを有効にする (プレビュー)] を選択します。 次に、[最小ラベラー] と [最大ラベラー] の値を設定して、使用するラベラーの数を指定します。 最大数と同じ数のラベラーを使用できることを確認します。 プロジェクトの開始後にこれらの設定を変更することは "できません"。
ラベラーの最小数から合意に達すると、項目にラベルが付けられます。 合意に達しない場合、項目はさらに多くのラベラーに送信されます。 項目がラベラーの最大数に送られても合意に達しない場合、その状態は [レビューが必要] になり、プロジェクト所有者が項目のラベル付けの責任を持つことになります。
注意
インスタンスのセグメント化プロジェクトでは、合意によるラベル付けを使用できません。
支援付き機械学習データ ラベル付けを使用する
ラベル付けタスクを高速化するために、[支援付き機械学習ラベル付け] ページで自動機械学習モデルをトリガーできます。 医療画像 (拡張子が .dcm のファイル) は、支援付きラベル付けの対象には含まれません。 プロジェクトの種類がセマンティック セグメント化 (プレビュー)の場合、支援付き機械学習ラベル付けは使用できません。
ラベル付けプロジェクトの開始時に、潜在的な偏りを減らすために、項目がランダムな順序にシャッフルされます。 ただし、トレーニング済みモデルには、データセットに存在する偏りが反映されます。 たとえば、項目の 80% が単一のクラスに属している場合、モデルのトレーニングに使用されるデータの約 80% は、そのクラスに属します。
支援付きラベル付けを有効にするには、[支援付き機械学習ラベル付けを有効にする] を選んで、GPU を指定します。 お使いのワークスペースに GPU がない場合は、GPU クラスター (リソース名: DefLabelNC6v3, vmsize: Standard_NC6s_v3) が自動的に作成され、ワークスペースに追加されます。 このクラスターは最小ノード数 0 で作成されます。つまり、使用していないときはコストがかかりません。
支援付き機械学習ラベル付けは、2 つのフェーズで構成されます。
- クラスタリング
- 事前ラベル付け
支援付きラベル付けを開始するために必要なラベル付けされたデータ項目の数は固定数ではありません。 この数は、ラベル付けプロジェクトごとに大きく異なる場合があります。 プロジェクトによっては、300 個の項目に手動でラベル付けした後に、事前ラベル付けまたはクラスターのタスクが可能になる場合があります。 支援付き機械学習ラベル付けでは、"転移学習" と呼ばれる手法が使用されます。 転移学習では、事前トレーニング済みモデルを使用して、トレーニング プロセスの速度を上げて開始します。 データセットのクラスが事前トレーニング済みモデルのクラスと似ている場合、数百個の項目に手動でラベルを付けるだけで、事前ラベルを使用できるようになることがあります。 データセットが、モデルの事前トレーニングに使われたデータと大きく異なる場合は、このプロセスにさらに時間がかかることがあります。
合意ラベル付けを使っている場合は、トレーニングに合意ラベルが使われます。
最終的なラベルは依然としてラベラーからの入力に依存するため、この技術は "人間参加型" のラベル付けと呼ばれることがあります。
注意
支援付き機械学習データ ラベル付けでは、仮想ネットワークの内側でセキュリティ保護された既定のストレージ アカウントはサポートされません。 支援付き機械学習データ ラベル付けには、既定以外のストレージ アカウントを使用する必要があります。 既定以外のストレージ アカウントは、仮想ネットワークの背後でセキュリティ保護できます。
クラスタリング
いくつかのラベルを送信すると、似た項目のグループ化が分類モデルによって開始されます。 これらの類似した画像は、ラベラーが効率よく手動タグ付けを行えるように、同じページ上に表示されます。 クラスタリングは、ラベラーに 4 枚、6 枚、9 枚の画像のグリッドを表示する場合に特に役立ちます。
手動でラベル付けされたデータで機械学習モデルのトレーニングが完了すると、モデルは切り詰められて、その最後の全結合層に到達します。 ラベル付けされていない画像は、その後、切り詰められたモデルを介し、"埋め込み" や "特徴量化" として知られるプロセスに渡されます。 このプロセスでは、モデル レイヤーが定義する高次元空間に各画像が埋め込まれます。 画像に最も近い空間内の他の画像は、クラスタリング タスクに使用されます。
クラスタリング フェーズは、オブジェクト検出モデルまたはテキスト分類には表示されません。
事前ラベル付け
トレーニングに十分なラベルを送信すると、分類モデルによってタグが予測されるか、物体検出モデルによって境界ボックスが予測されます。 ラベラーには、各項目に既に存在する予測済みのラベルを含むページが表示されるようになります。 オブジェクト検出では、予測されたボックスも表示されます。 タスクには、ページの送信前にこれらの予測を確認し、間違ってラベル付けされた画像を修正する作業が含まれます。
手動でラベル付けされたデータで機械学習モデルのトレーニングが完了すると、モデルは手動でラベル付けされた項目のテスト セットで評価されます。 この評価は、異なるいくつかの信頼度しきい値でモデルの精度を判断するのに役立ちます。 事前ラベルを表示するだけの精度がモデルにあるかどうかの基準となる信頼度のしきい値は、この評価プロセスによって設定されます。 その後、このモデルは、ラベル付けされていないデータに対して評価されます。 予測の信頼度がこのしきい値を超える項目が、事前ラベル付けに使用されます。
画像のラベル付けプロジェクトを初期化する
ラベル付けプロジェクトが初期化された後、プロジェクトのいくつかの部分は変更できなくなります。 タスクの種類やデータセットを変更することはできません。 ラベルや、タスクの説明の URL は変更 "できます"。 プロジェクトを作成する前に、設定を慎重に確認してください。 プロジェクトを送信すると、[データのラベル付け] 概要ページに戻り、プロジェクトが [初期化中] と表示されます。
注意
概要ページは自動的に更新されない場合があります。 しばらくしてからページを手動で更新すると、プロジェクトの状態が [作成済み] と表示されます。
トラブルシューティング
プロジェクトの作成またはデータへのアクセスに関する問題については、データラベル付けのトラブルシューティングに関するページを参照してください。