重要
この記事では、Azure Machine Learning SDK v1 の使用に関する情報を提供します。 SDK v1 は 2025 年 3 月 31 日の時点で非推奨となり、サポートは 2026 年 6 月 30 日に終了します。 SDK v1 は、その日付までインストールして使用できます。
2026 年 6 月 30 日より前に SDK v2 に移行することをお勧めします。 SDK v2 の詳細については、「 Azure Machine Learning Python SDK v2 と SDK v2 リファレンスとは」を参照してください。
この記事では、自動機械学習のトレーニング済みモデルから生成されたトレーニング コードを表示する方法について説明します。
自動 ML トレーニング済みのモデルに対するコード生成により、特定の実行向けにモデルをトレーニングして構築するために自動 ML が使用する次の詳細を表示できます。
- データの前処理
- アルゴリズムの選択
- 特徴付け
- ハイパーパラメーター
任意の自動 ML トレーニング済みのモデル、推奨または子の実行を選択することで、その特定のモデルを作成した Python トレーニング コードを生成して表示できます。
生成されたモデルのトレーニング コードを使用して、次の作業を実行できます。
- モデルのアルゴリズムが使用する特徴付けプロセスとハイパーパラメーターについて学習します。
- トレーニング済みのモデルの追跡/バージョン管理/監査を行います。 バージョン管理されたコードを保存して、実稼働環境にデプロイされるモデルで使用される特定のトレーニング コードを追跡します。
- ハイパーパラメーターを変更するか、自分の ML とアルゴリズムのスキル/エクスペリエンスを適用して、トレーニング コードをカスタマイズし、カスタマイズしたコードで新しいモデルの再トレーニングを行います。
次の図は、すべての種類のタスクで自動 ML 実験のコードを生成できることを示しています。 まず、モデルを選びます。 選んだモデルが強調表示されたら、Azure Machine Learning によって、モデルの作成に使われたコード ファイルがコピーされ、ノートブックの共有フォルダーに表示されます。 ここから、必要に応じてコードを表示およびカスタマイズできます。
前提条件
Azure Machine Learning ワークスペース。 ワークスペースを作成するには、「ワークスペース リソースの作成」を参照してください。
この記事では、自動化された機械学習実験の設定にある程度精通していることを前提としています。 チュートリアルまたは方法に従って、自動化された機械学習実験の主要な設計パターンについて確認してください。
自動 ML のコード生成を使用できるのは、リモートの Azure Machine Learning コンピューティング先での実験実行のみです。 コード生成は、ローカル実行ではサポートされていません。
Azure Machine Learning スタジオ、SDKv2、または CLIv2 からトリガーされるすべての自動 ML 実行では、コード生成が有効になります。
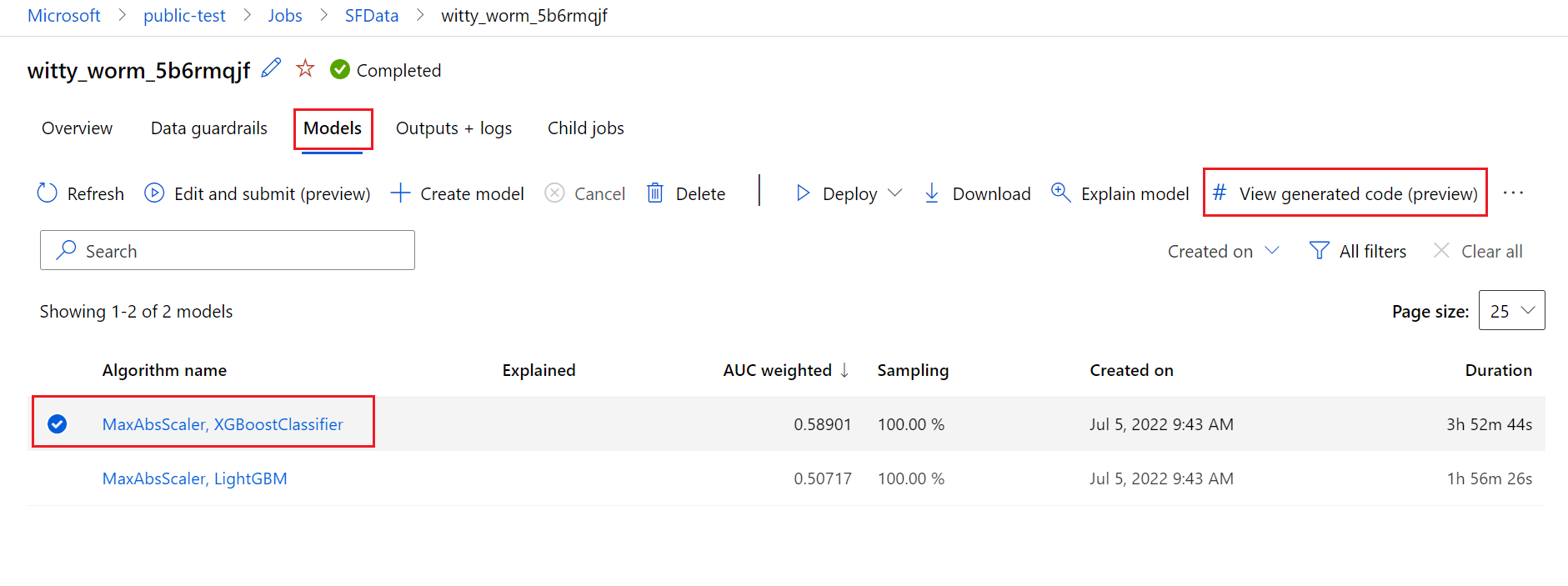
生成されたコードとモデルの成果物を取得する
既定では、自動 ML トレーニング済みのモデルごとに、トレーニングの完了後にトレーニング コードが生成されます。 自動 ML は、その特定のモデルの実験の outputs/generated_code にこのコードを保存します。 Azure Machine Learning スタジオの UI で、選択したモデルの [出力とログ] タブにそれらを表示できます。
script.py これは、特徴付けステップ、使用される特定のアルゴリズム、およびハイパーパラメーターを使用して分析するモデルのトレーニング コードです。
script_run_notebook.ipynb モデルのトレーニング コード (script.py) を、Azure Machine Learning SDK v2 を使って Azure Machine Learning コンピューティングで実行するためのボイラー プレート コードが含まれるノートブック。
自動 ML トレーニングの実行が完了したら、Azure Machine Learning スタジオの UI から script.py と script_run_notebook.ipynb ファイルにアクセスできます。
これを行うには、自動 ML 実験の親実行ページの [モデル] タブに移動します。 トレーニング済みモデルのいずれかを選んだ後、[生成されたコードの表示] ボタンを選ぶことができます。 このボタンにより、[Notebooks] ポータル拡張機能にリダイレクトされ、そこで特定の選択したモデルに対して生成されたコードを表示、編集、および実行できます。
![親実行の [モデル] タブの [生成されたコードの表示] ボタン](media/how-to-generate-automl-training-code/parent-run-view-generated-code.png?view=azureml-api-1)
特定のモデルの子実行のページに移動すると、子実行のページの上部からモデルに対して生成されたコードにアクセスすることもできます。
![子実行ページの [生成されたコードの表示] ボタン](media/how-to-generate-automl-training-code/child-run-view-generated-code.png?view=azureml-api-1)
Python SDKv2 を使用している場合は、MLFlow を介して最適な実行を取得し、結果として得られる成果物をダウンロードして、"script.py" と "script_run_notebook.ipynb" をダウンロードすることもできます。
制限事項
[生成されたコードの表示] を選択する場合、既知の問題があります。 ストレージが VNet の背後にある場合、このアクションは Notebooks ポータルへのリダイレクトに失敗します。 回避策として、ユーザーは、[出力とログ] タブの [出力][generated_code] フォルダーの順に移動し、> ファイルと [script_run_notebook.ipynb] ファイルを手動でダウンロードできます。 これらのファイルは、ノートブック フォルダーに手動でアップロードして、実行または編集できます。 Azure Machine Learning での VNet の詳細については、こちらのリンクを参照してください。
![上で説明したように、outputs と generated code フォルダーが選ばれている [出力とログ] タブを示すスクリーンショット。](media/how-to-generate-automl-training-code/view-generated-code.png?view=azureml-api-1)
script.py
script.py ファイルには、前に使用したハイパーパラメーターでモデルのトレーニングに必要であったコア ロジックが含まれています。 モデルのトレーニング コードは Azure Machine Learning スクリプトの実行のコンテキストで実行することが意図されていますが、いくつかの変更を加えると、独自のオンプレミス環境でスタンドアロンで実行することもできます。
スクリプトは、データの読み込み、データの準備、データの特徴付け、プリプロセッサ/アルゴリズムの指定、トレーニングなどの、いくつかの部分におおまかに分割できます。
データの読み込み
関数 get_training_dataset() が、前に使用したデータセットを読み込みます。 これトは、元の実験と同じワークスペースで実行される Azure Machine Learning スクリプト実行で実行することを前提にしています。
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
スクリプト実行の一部として実行すると、Run.get_context().experiment.workspace が正 しいワークスペースを取得します。 ただし、このスクリプトを別のワークスペース内またはローカル環境で実行する場合は、スクリプトを変更して該当するワークスペースを明示的に指定する必要があります。
ワークスペースが取得されると、元のデータセットが ID によって取得されます。 それぞれ get_by_id() または get_by_name() で、ID または名前を指定してまったく同じ構造の別のデータセットを指定することもできます。 この ID は、このスクリプトの後方にある次のコードのようなセクションで確認できます。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
この関数全体を独自のデータ読み込みメカニズムに置き換える選択もできます。唯一の制約は、戻り値が Pandas データフレームであり、データが元の実験と同じ形状である必要があるということです。
データの準備コード
関数 prepare_data() は、データをクリーンアップし、特徴量とサンプル重みの列を分割し、トレーニングで使用するデータを準備します。
この関数は、データセットの種類と実験タスクの種類 (分類、回帰、時系列予測、イメージ、または NLP タスク) によって異なる場合があります。
次の例は、一般に、データ読み込みステップのデータフレームが渡されることを示しています。 ラベル列とサンプルの重み付け (最初に指定した場合) が抽出され、NaN を含む行が入力データから削除されます。
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
さらにデータ準備を行う場合は、このステップでカスタム データ準備コードを追加すると、実行できます。
データの特徴付けコード
関数 generate_data_transformation_config() は、最後の scikit-learn パイプラインに特徴付けステップを指定します。 元の実験の特徴抽出器が、パラメーターとともにここで再現されます。
たとえば、この関数で発生する可能性があるデータ変換が、SimpleImputer() や CatImputer() などのインピューター、または StringCastTransformer() や LabelEncoderTransformer() などのトランスフォーマーに基づいているとします。
列のセットを変換するために使用できる StringCastTransformer() 型のトランスフォーマーを次に示します。 この場合、セットは column_names で示されています。
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
同じ特徴量化または変換を適用する必要がある列が多数ある場合 (たとえば、複数の列グループ内の 50 列)、これらの列は型に基づいてグループ化して処理されます。
次の例では、各グループに一意のマッパーが適用されています。 このマッパーは、そのグループの各列に適用されます。
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
この方法では、データセットに数十または数百の列があるときに特に面倒になる可能性がある、各列にトランスフォーマーのコード ブロックを含める作業をせずに、より効率的にコードを作成できます。
分類と回帰のタスクでは、[FeatureUnion] が特徴抽出器として使用されます。
時系列予測モデルの場合、複数の時系列対応の特徴抽出器が scikit-learn パイプラインに収集されて、TimeSeriesTransformer にラップされます。
時系列予測モデルに対してユーザーが提供した特徴付けは、自動 ML によって提供されたものより前に実行されます。
プリプロセッサの指定コード
関数 generate_preprocessor_config() (存在する場合) は、最後の scikit-learn パイプラインの特徴付け後に実行される前処理ステップを指定します。
通常、この前処理ステップは、sklearn.preprocessing で実行されるデータの標準化/正規化のみで構成されます。
自動 ML は、非アンサンブル分類モデルと回帰モデルの前処理手順のみを指定します。
生成されたプリプロセッサ コードの例を次に示します。
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
アルゴリズムとハイパーパラメーターの指定コード
アルゴリズムとハイパーパラメーターの指定コードは、多くの ML の専門家が最も関心を持っている可能性があるものです。
関数 generate_algorithm_config() は、最後の scikit-learn パイプラインの最後のステージとして、モデルをトレーニングするための実際のアルゴリズムとハイパーパラメーターを指定します。
次の例では、特定のハイパーパラメーターを指定して XGBoostClassifier アルゴリズムを使用します。
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
ほとんどの場合、生成されるコードはオープン ソース ソフトウェア (OSS) のパッケージとクラスを使用します。 より複雑なコードを簡素化するために中間ラッパー クラスが使用されているインスタンスもあります。 たとえば、XGBoost 分類子や、LightGBM、Scikit-Learn の各アルゴリズムなどの一般的に使用されるライブラリを適用できます。
ML 専門家は、そのアルゴリズムおよび特定の ML 問題に関するスキルと経験に基づいて、必要に応じてハイパーパラメーターを調整して、そのアルゴリズムの構成コードをカスタマイズできます。
アンサンブル モデルについては、generate_preprocessor_config_N() (必要な場合) と generate_algorithm_config_N() が、アンサンブル モデルの各学習器に対して定義されます。ここで、N はアンサンブル モデルのリスト内の各学習器の配置位置を表します。 スタック アンサンブル モデルについては、メタ学習器 generate_algorithm_config_meta() が定義されます。
エンドツーエンド トレーニング コード
コード生成では、scikit-learn パイプラインを定義し、それに対して build_model_pipeline() を呼び出すために、train_model() と fit() がそれぞれ出力されます。
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
scikit-learn パイプラインには、特性付けステップ、プリプロセッサ (使用される場合)、およびアルゴリズムまたはモデルが含まれています。
時系列予測モデルの場合、scikit-learn パイプラインは ForecastingPipelineWrapper にラップされます。これには、適用されたアルゴリズムに応じて時系列データを適切に処理するために必要な追加のロジックがあります。
すべてのタスクの種類について、ラベル列をエンコードする必要がある場合に PipelineWithYTransformer を使用します。
scikit-Learn パイプラインを作成したら、この後呼び出す必要があるのは、モデルをトレーニングする fit() メソッドのみです。
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
train_model() からの戻り値は、入力データに適合し、トレーニングされたモデルです。
上記のすべての関数を実行するメイン コードは次のとおりです。
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
トレーニング済みのモデルを作成したら、それを使用して predict () メソッドで予測を行うことができます。 実験が時系列モデルの場合は、予測に forecast() メソッドを使用します。
y_pred = model.predict(X)
最後に、モデルはシリアル化され、"model.pkl" という名前の .pkl ファイルとして保存されます。
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
script_run_notebook.ipynb ノートブックは、Azure Machine Learning コンピューティングで簡単に script.py を実行する方法として機能します。
このノートブックは、既存の自動 ML のサンプル ノートブックに似ていますが、以降のセクションで説明するように、重要な違いがいくつかあります。
環境
通常、自動 ML 実行のトレーニング環境は、SDK によって自動的に設定されます。 ただし、生成されたコードなどのカスタム スクリプト実行を実行するときは、自動 ML によってプロセスが駆動されなくなるため、コマンド ジョブを成功させるために環境を指定する必要があります。
コード生成では、可能であれば、元の自動 ML 実験で使用された環境を再利用します。 そうすることで、依存関係がないためにトレーニング スクリプト実行が失敗することがなくなり、Docker イメージを再構築する必要がないという副次的効果があります。これにより、時間とコンピューティングリソースが節約されます。
追加の依存関係が必要な変更を script.py に対して行う場合、または独自の環境を使う場合は、それに応じて script_run_notebook.ipynb の環境を更新する必要があります。
実験を送信する
生成されたコードは自動 ML によって駆動されないため、AutoML ジョブを作成して送信する代わりに、Command Job を作成し、生成されたコード (script.py) を作成したジョブに提供する必要があります。
次の例には、計算や環境などのコマンド ジョブの実行に必要なパラメーターと通常の依存関係が含まれています。
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning studio
次のステップ
- モデルをデプロイする方法と場所についてさらに詳しく学習する。
- 自動 ML の実験で特に解釈可能性の機能を有効にする方法を参照してください。