事業継続とディザスター リカバリーのためのフェールオーバー
アップタイムを最大化するために、Azure Machine Learning での事業継続の維持とディザスター リカバリーの準備について事前に計画を立てておきます。
Microsoft は、Azure サービスを常に使用できるようにする作業に取り組んでいます。 そうはいっても、計画されていないサービスの停止が発生する可能性はあります。 リージョン規模のサービス停止に対処するため、ディザスター リカバリー計画を用意しておくことをお勧めします。 この記事では、次の方法について学習します。
- Azure Machine Learning と関連リソースの複数リージョンへのデプロイを計画する。
- ログ、ノートブック、Docker イメージ、その他のメタデータを回復できる可能性を最大限に高めます。
- ソリューションの高可用性に対応した設計を行う。
- 別のリージョンへのフェールオーバーを開始する。
重要
Azure Machine Learning 自体では、自動フェールオーバーやディザスター リカバリーは提供されていません。 実行履歴などのワークスペース メタデータのバックアップと復元は使用できません。
ワークスペースまたは対応するコンポーネントを誤って削除した場合に備え、この記事では、現在サポートされている回復オプションについても説明します。
Azure Machine Learning のための Azure サービスについて
Azure Machine Learning は複数の Azure サービスに依存しています。 これらのサービスの一部は、ユーザー サブスクリプションでプロビジョニングされています。 これらのサービスの高可用性構成は、ユーザーが行う必要があります。 他のサービスは Microsoft サブスクリプションで作成され、Microsoft によって管理されます。
次のような Azure サービスがあります。
Azure Machine Learning インフラストラクチャ: Azure Machine Learning ワークスペース用の Microsoft によって管理される環境。
関連付けられているリソース: Azure Machine Learning ワークスペースの作成時にサブスクリプションでプロビジョニングされたリソース。 これらのリソースには、Azure Storage、Azure Key Vault、Azure Container Registry、Application Insights が含まれます。
- 既定のストレージには、モデル、トレーニング ログ データ、データセットなどのデータがあります。
- Key Vault には、Azure Storage、Container Registry、データ ストアのための資格情報が格納されています。
- Container Registry には、トレーニングおよび推論環境用の Docker イメージがあります。
- Application Insights は、Azure Machine Learning を監視するためのものです。
コンピューティング リソース: ワークスペースのデプロイ後に作成するリソース。 たとえば、機械学習モデルをトレーニングするために作成するコンピューティング インスタンスまたはコンピューティング クラスターです。
- コンピューティング インスタンスとコンピューティング クラスター: Microsoft によって管理されるモデル開発環境。
- その他のリソース:Azure Kubernetes Service (AKS)、Azure Databricks、Azure Container Instances、Azure HDInsight など、Azure Machine Learning に接続できる Microsoft のコンピューティング リソース。 これらのリソースの高可用性の設定の構成は、ユーザーが行う必要があります。
他のデータ ストア: Azure Machine Learning には、トレーニング データ用に Azure Storage、Azure Data Lake Storage、Azure SQL Database などの別のデータ ストアをマウントできます。 これらのデータ ストアは、サブスクリプション内でプロビジョニングされます。 高可用性の設定の構成は、ユーザーが行う必要があります。
次の表では、Microsoft によって管理される Azure サービスとユーザーによって管理される Azure サービスを示します。 また、既定で高可用性になっているサービスも示します。
| サービス | 管理者 | 既定で高可用性 |
|---|---|---|
| Azure Machine Learning インフラストラクチャ | Microsoft | |
| 関連付けられているリソース | ||
| Azure Storage | あなたが | |
| Key Vault | あなたが | ✓ |
| Container Registry | あなたが | |
| Application Insights | あなたが | NA |
| コンピューティング リソース | ||
| コンピューティング インスタンス | Microsoft | |
| コンピューティング クラスター | マイクロソフト | |
| その他のコンピューティング リソース (AKS、 Azure Databricks、Container Instances、HDInsight など) |
自分 | |
| 他のデータ ストア (Azure Storage、SQL Database、 Azure Database for PostgreSQL、Azure Database for MySQL、 Azure Databricks ファイル システムなど) |
自分 |
この記事の残りの部分では、これらの各サービスを高可用性にするために必要な操作について説明します。
複数リージョンへのデプロイを計画する
複数リージョンへのデプロイは、2 つの Azure リージョンで Azure Machine Learning および他のリソース (インフラストラクチャ) を作成することに依存しています。 リージョン規模での停止が発生した場合、他のリージョンに切り替えることができます。 リソースをデプロイする場所を計画する際は、次の点を考慮してください。
リージョンの可用性: ユーザーに近いリージョンを使用します。 Azure Machine Learning のリージョンの可用性を確認するには、「リージョン別の Azure 製品」を参照してください。
Azure ペア リージョン: ペアになったリージョンでは、プラットフォームの更新が調整され、必要に応じて復旧作業が優先されます。 詳細については、「Azure のペアになっているリージョン」をご覧ください。
サービスの可用性: ソリューションで使用されるリソースを、ホット/ホット、ホット/ウォーム、またはホット/コールドのいずれにするかを決定します。
- ホット/ホット: 両方のリージョンが同時にアクティブになり、1 つのリージョンですぐに使用を開始できます。
- ホット/ウォーム: プライマリ リージョンがアクティブになり、セカンダリ リージョンでは重要なリソース (デプロイされたモデルなど) を開始する準備ができています。 重要でないリソースは、セカンダリ リージョンに手動でデプロイする必要があります。
- ホット/コールド: プライマリ リージョンがアクティブになり、セカンダリ リージョンには必要なデータとともに Azure Machine Learning および他のリソースがデプロイされています。 モデル、モデル デプロイ、パイプラインなどのリソースは、手動でデプロイする必要があります。
ヒント
ビジネス要件によっては、異なる Azure Machine Learning リソースを異なる方法で扱ってもかまいません。 たとえば、デプロイされたモデル (推論) にはホット/ホットを使用し、実験 (トレーニング) にはホット/コールドを使用することもできます。
Azure Machine Learning は、他のサービスに基づいて構築されます。 一部のサービスは、他のリージョンにレプリケートするように構成できます。 その他のものは、複数のリージョンで手動で作成する必要があります。 次の表に、サービスの一覧、レプリケーションの責任、および構成の概要を示します。
| Azure サービス | Geo レプリケートの責任 | 構成 |
|---|---|---|
| Machine Learning ワークスペース | 自分 | 選択したリージョンにワークスペースを作成します。 |
| Machine Learning コンピューティング | 自分 | 選択したリージョンにコンピューティング リソースを作成します。 動的にスケーリングできるコンピューティング リソースの場合は、両方のリージョンに、ニーズに見合った十分なコンピューティング クォータがあることを確認してください。 |
| Key Vault | Microsoft | 両方のリージョンで、Azure Machine Learning のワークスペースとリソースを備えた同じ Key Vault インスタンスを使用します。 Key Vault は、セカンダリ リージョンに自動的にフェールオーバーします。 詳細については、「Azure Key Vault の可用性と冗長性」を参照してください。 |
| Container Registry | Microsoft | Container Registry インスタンスを構成して、Azure Machine Learning 用にペアになっているリージョンにレジストリを geo レプリケートするようにします。 両方のワークスペース インスタンス用に同じインスタンスを使用します。 詳細については、「Azure Container Registry の geo レプリケーション」を参照してください。 |
| ストレージ アカウント | 自分 | Azure Machine Learning では、geo 冗長ストレージ (GRS)、geo ゾーン冗長ストレージ (GZRS)、読み取りアクセス geo 冗長ストレージ (RA-GRS)、または読み取りアクセス geo ゾーン冗長ストレージ (RA-GZRS) を使用した "既定のストレージ アカウント" のフェールオーバーはサポートされていません。 各ワークスペースの既定のストレージに対して、独立したストレージ アカウントを作成します。 他のデータ ストレージに対しては、別々のストレージ アカウントまたはサービスを作成します。 詳細については、「Azure Storage の冗長性」を参照してください。 |
| Application Insights | あなたが | 両方のリージョンのワークスペースに対して Application Insights を作成します。 データ保持期間と詳細を調整するには、「Application Insights でのデータの収集、保持、保存」を参照してください。 |
セカンダリ リージョンでの高速な復旧と再起動を可能にするには、次のような開発方法をお勧めします。
- Azure Resource Manager テンプレートを使用します。 テンプレートは、"コードとしてのインフラストラクチャ" であり、サービスを両方のリージョンで迅速にデプロイできます。
- 2 つのリージョン間のずれを避けるために、継続的インテグレーションとデプロイのパイプラインを更新して両方のリージョンにデプロイします。
- デプロイを自動化する場合は、Azure Kubernetes Service などのワークスペースにアタッチしたコンピューティング リソースの構成を含めます。
- 両方のリージョンのユーザーに対するロールの割り当てを作成します。
- 両方のリージョンに対し、Azure Virtual Networks などのネットワーク リソースとプライベート エンドポイントを作成します。 ユーザーが両方のネットワーク環境にアクセスできるようにします。 たとえば、両方の仮想ネットワークに VPN と DNS の構成を行います。
コンピューティングとデータ サービス
ニーズに応じて、Azure Machine Learning によって使用されるコンピューティングまたはデータ サービスを増やすことができます。 たとえば、Azure Kubernetes Services または Azure SQL Database を使用することもできます。 高可用性を実現するためにこれらのサービスを構成する方法については、次の情報を参照してください。
コンピューティング リソース
- Azure Kubernetes Service:「Azure Kubernetes Service (AKS) での事業継続とディザスター リカバリーに関するベスト プラクティス」および「可用性ゾーンを使用する Azure Kubernetes Service (AKS) クラスターを作成する」を参照してください。 AKS クラスターが Azure Machine Learning Studio、SDK、または CLI を使用して作成された場合、複数のリージョンにわたる高可用性はサポートされません。
- Azure Databricks:詳細については、「Azure Databricks クラスターに対するリージョンのディザスター リカバリー」を参照してください。
- Container Instances:フェールオーバーは、オーケストレーターによって行われます。 詳細については、「Azure Container Instances とコンテナー オーケストレーター」を参照してください。
- HDInsight:詳細については、「Azure HDInsight でサポートされている高可用性サービス」を参照してください。
データ サービス
- Azure BLOB コンテナー/Azure Files/Data Lake Storage Gen2: 「Azure Storage の冗長性」を参照してください。
- [Data Lake Storage Gen1] :「Data Lake Storage Gen1 の高可用性とディザスター リカバリーのガイダンス」を参照してください。
- SQL Database:「Azure SQL Database と SQL Managed Instance の高可用性」を参照してください。
- Azure Database for PostgreSQL:詳細については、「Azure Database for PostgreSQL - Single Server での高可用性の概念」を参照してください。
- Azure Database for MySQL:詳細については、「Azure Database for MySQL でのビジネス継続性を理解する」を参照してください。
- Azure Databricks ファイル システム: 詳細については、「Azure Databricks クラスターに対するリージョンのディザスター リカバリー」を参照してください。
ヒント
独自のカスタマー マネージド キーを指定して Azure Machine Learning ワークスペースをデプロイした場合、Azure Cosmos DB もサブスクリプション内にプロビジョニングされます。 その場合、その高可用性の設定の構成は、ユーザーが行う必要があります。 詳細については、「Azure Cosmos DB での高可用性」を参照してください。
高可用性向けの設計
重要なコンポーネントを複数のリージョンにデプロイする
目指す事業継続のレベルを決定します。 レベルはソリューションのコンポーネントによって異なる場合があります。 たとえば、運用パイプラインまたはモデル デプロイの場合はホット/ホット構成とし、実験の場合はホット/コールドにすることができます。
分離ストレージ上のトレーニング データを管理する
ワークスペースでログ用に使用する既定のストレージからデータ ストレージを分離することで、次のことが可能になります。
- データストアと同じストレージ インスタンスを、プライマリとセカンダリのワークスペースにアタッチする。
- データ ストレージ アカウント用の geo レプリケーションを使用し、アップタイムを最大化する。
機械学習資産をコードとして管理する
Note
実行履歴、モデル、環境などのワークスペース メタデータのバックアップと復元は使用できません。 YAML 仕様を使用して資産と構成をコードとして指定すると、障害が発生した場合にワークスペース間で資産を再作成するのに役立ちます。
Azure Machine Learning でのジョブは、ジョブ仕様によって定義されます。 この仕様には、ワークスペース/インスタンス レベルで管理される入力アーティファクト (環境、データセット、コンピューティングを含む) に対する依存関係が含まれます。 複数リージョンのジョブの送信とデプロイについては、次の方法をお勧めします。
コード ベースをローカルで管理し、Git リポジトリによってサポートします。
Azure Machine Learning スタジオから重要なノートブックをエクスポートします。
スタジオで作成されたパイプラインをコードとしてエクスポートします。
Note
スタジオ デザイナーで作成されたパイプラインは、現在コードとしてエクスポートできません。
構成をコードとして管理します。
- ワークスペースへの参照をハードコーディングすることは避けてください。 代わりに、構成ファイルを使用してワークスペース インスタンスへの参照を構成し、Workspace.from_config() を使用してワークスペースを初期化します。 プロセスを自動化するには、Azure CLI 機械学習向け拡張機能のコマンドである az ml folder attach を使用します。
- ScriptRunConfig や Pipeline などのジョブの送信ヘルパーを使用します。
- Environments.save_to_directory() を使用して、環境の定義を保存します。
- カスタム Docker イメージを使用する場合は、Dockerfile を使用します。
- Dataset クラスを使用して、ソリューションで使用されるデータ パスのコレクションを定義します。
- Inferenceconfig クラスを使用して、モデルを推論エンドポイントとしてデプロイします。
フェールオーバーの開始
フェールオーバー ワークスペースで作業を続行する
プライマリ ワークスペースが使用できなくなった場合は、セカンダリ ワークスペースに切り替えて、実験と開発を続行することができます。 障害が発生した場合、Azure Machine Learning ではジョブが自動的にセカンダリ ワークスペースに送信されません。 コード構成を更新して、新しいワークスペース リソースを指定するようにします。 ワークスペース参照のハードコーディングを避けることをお勧めします。 代わりに、ワークスペース構成ファイルを使用して、ワークスペースを変更する際の手動のユーザー手順を最小限に抑えます。 また、新しいワークスペースに対する継続的インテグレーションやデプロイ パイプラインなどのすべての自動化も、更新するようにしてください。
Azure Machine Learning では、ワークスペース インスタンス間でアーティファクトやメタデータを同期したり回復したりすることはできません。 アプリケーションのデプロイ戦略によっては、ジョブの送信を続行するために、アーティファクトを移動したり、データセット オブジェクトなどの実験入力をフェールオーバー ワークスペース内に再作成したりすることが必要な場合もあります。 geo レプリケーションを有効にして関連リソースを共有するようにプライマリ ワークスペースとセカンダリ ワークスペース リソースを構成した場合、一部のオブジェクトがフェールオーバー ワークスペースで直接使用できることがあります。 たとえば、両方のワークスペースが同じ Docker イメージ、構成されたデータストア、および Azure Key Vault リソースを共有する場合などです。 次の図は、2 つのワークスペースで同じイメージ (1)、データストア (2)、およびKey Vault (3) が共有されている構成を示しています。
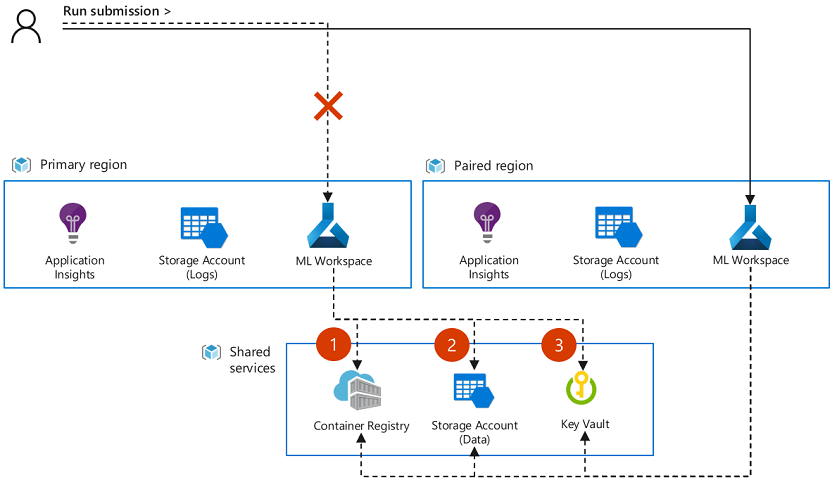
Note
サービス停止が発生したときに実行中のジョブは、セカンダリ ワークスペースに自動的に移行されません。 また、停止が解決したときに、ジョブがプライマリ ワークスペースで再開されて正常に完了する見込みもありません。 代わりに、セカンダリ ワークスペースまたは (停止が解決した後の) プライマリ ワークスペースのいずれかで、これらのジョブを再送信する必要があります。
ワークスペース間でのアーティファクトの移動
復旧方法によっては、作業を続行するにはデータセットやモデル オブジェクトなどのアーティファクトをワークスペース間でコピーすることが必要な場合もあります。 現時点では、ワークスペース間でのアーティファクトの移植性は限定的です。 フェールオーバー インスタンスで再作成できるよう、アーティファクトを可能な限りコードとして管理することをお勧めします。
次のアーティファクトは、Azure CLI 機械学習向け拡張機能を使用して、ワークスペース間でエクスポートおよびインポートできます。
| アーティファクト | エクスポート | [インポート] |
|---|---|---|
| モデル | az ml model download --model-id {ID} --target-dir {PATH} | az ml model register –name {NAME} --path {PATH} |
| 環境 | az ml environment download -n {NAME} -d {PATH} | az ml environment register -d {PATH} |
| Azure Machine Learning パイプライン (コード生成) | az ml pipeline get --path {PATH} | az ml pipeline create --name {NAME} -y {PATH} |
ヒント
- "登録済みのデータセット" は、ダウンロードしたり移動したりすることができません。 これには中間パイプライン データセットなど、Azure Machine Learning によって生成されたデータセットが含まれます。 ただし、両方のワークスペースからアクセスできたり、基になるデータ ストレージがレプリケートされたりする共有ファイルの場所を参照するデータセットは、両方のワークスペースに登録できます。 データセットを登録するには、az ml dataset register を使用します。
- ジョブの出力は、ワークスペースに関連付けられた既定のストレージ アカウントに格納されます。 サービス停止時にスタジオ UI からジョブの出力にアクセスできなくなる可能性がありますが、このときストレージ アカウントを使用して、データに直接アクセスできます。 BLOB に格納されているデータの操作の詳細については、「Azure CLI を使用して BLOB を作成、ダウンロード、一覧表示する」を参照してください。
Recovery options
ワークスペースの削除
ワークスペースを誤って削除した場合は、復旧できる可能性があります。 復旧手順については、「誤った削除の後に論理的な削除を使用してワークスペース データを復旧する」を参照してください。
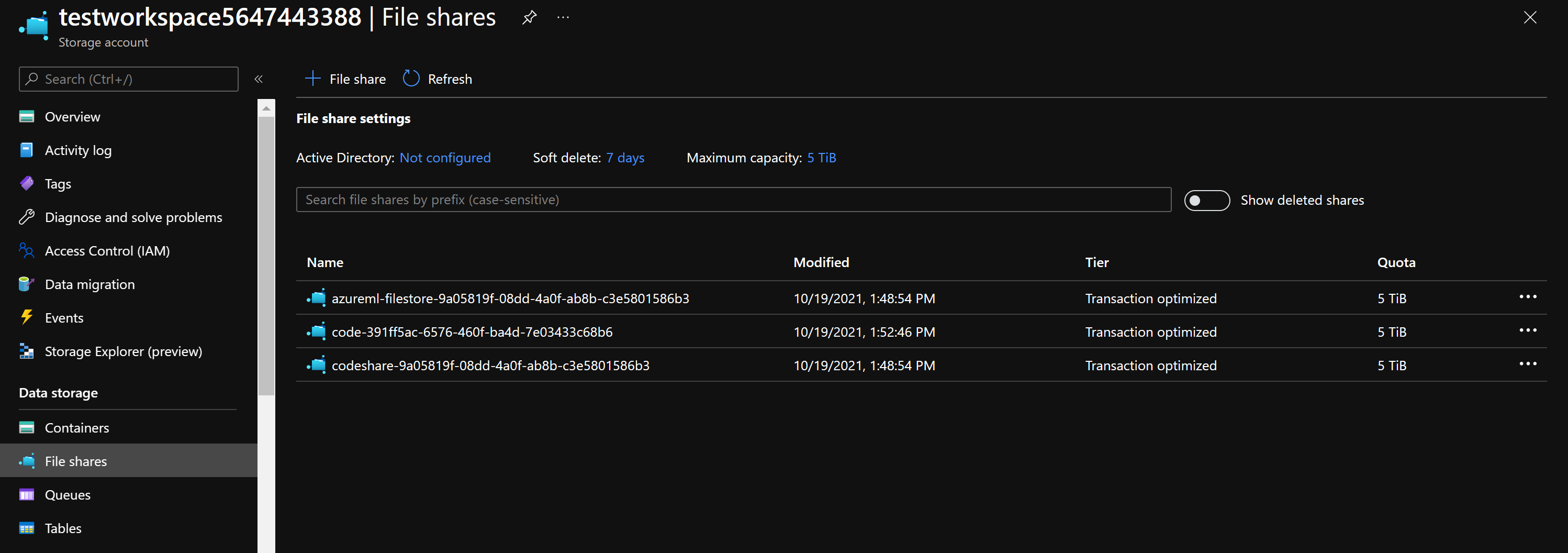
ワークスペースを復旧できない場合でも、次の手順に従って、ワークスペースに関連付けられている Azure ストレージ リソースからノートブックを取得できる場合があります。
- Azure portal で、Azure Machine Learning ワークスペースにリンクされていたストレージ アカウントに移動します。
- 左側の [データ ストレージ] セクションで、 [ファイル共有] をクリックします。
- ノートブックは、ワークスペース ID を含む名前が付けられたファイル共有にあります。
次のステップ
Azure Machine Learning を使用した反復可能なインフラストラクチャのデプロイについて学習するには、Azure Resource Manager テンプレートを使用します。