データ ドリフト (プレビュー) は廃止され、モデル モニターに置き換えられる予定です
データ ドリフト (プレビュー) は 2025 年 9 月 1 日に廃止され、データ ドリフト タスクにモデル モニターを使用できるようになります。 置き換え、機能のギャップ、手動の変更手順を理解するには、以下の内容を確認してください。

データ ドリフトを監視し、ドリフトが大きい場合のアラートを設定する方法について説明します。
Note
Azure Machine Learning モデルモニタリング (v2) には、シグナルとメトリックを監視するための追加機能とともに、データ ドリフトに対して改善された機能が用意されています。 Azure Machine Learning (v2) のモデルモニタリング機能の詳細については、「Azure Machine Learning を使用したモデルモニタリング」を参照してください。
Azure Machine Learning データセット モニター (プレビュー) を使用すると、次のことを実行できます。
- データのドリフトを分析して、時間の経過と共にどのように変化するかを把握する。
- モデル データを監視して、トレーニング用データセットと供給データセットの違いを確認する。 デプロイされたモデルからモデル データを収集することから始めます。
- 新しいデータを監視して、ベースライン データセットとターゲット データセットの違いを確認する。
- データの特徴をプロファイリングして、時間の経過と共に統計的な特性がどのように変化するかを追跡する。
- データ ドリフトに関するアラートを設定して、潜在的な問題を早期に警告する。
- 非常に多くのドリフトがデータに発生したと判断した場合に、 新しいバージョンのデータセットを作成 する。
モニターの作成には、Azure Machine Learning のデータセットが使用されます。 データセットには timestamp 列が含まれている必要があります。
データ ドリフト メトリックは、Python SDK または Azure Machine Learning Studio を使用して確認できます。 その他のメトリックと分析情報は、Azure Machine Learning ワークスペースに関連付けられている Azure Application Insights リソースを通じて利用できます。
重要
データセットのデータ ドリフト検出は、現在パブリック プレビュー段階にあります。 プレビュー バージョンはサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
前提条件
データセット モニターを作成して使用するには、以下が必要です。
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning を今すぐお試しください。
- Azure Machine Learning ワークスペース。
- Azure Machine Learning SDK for Python がインストール済み (これには azureml-datasets パッケージが含まれています)。
- データのファイル パス、ファイル名、または列にタイムスタンプが指定された構造化 (表形式) データ。
前提条件 (モデル モニターに移行する)
モデル モニターに移行する場合は、Azure Machine Learning モデル監視の前提条件に関するこちらの記事を確認してください。
データの誤差とは
モデルの精度は時間の経過と同時に低下します。これは、主にデータ ドリフトが原因です。 機械学習モデルの場合、データ ドリフトとは、モデルのパフォーマンスの低下につながるモデルの入力データの変更のことです。 データ ドリフトを監視すると、このようなモデルのパフォーマンスの問題を検出するために役立ちます。
データ ドリフトは、次のようなことが原因で発生します。
- 上流プロセスの変更 (センサーを交換したため測定単位がインチからセンチメートルに変更された場合など)。
- データ品質の問題 (センサーが破損しているため読み取り値が常に 0 になっている場合など)。
- データの自然なドリフト (平均気温が季節と共に変化する場合など)。
- 特徴間の関係の変化 (共変量シフト)。
Azure Machine Learning を使用すると、比較されるデータセットの複雑さを抽象化する単一のメトリックを計算することにより、ドリフト検出を簡略化することができます。 このようなデータセットには、数百単位の特徴と数万行が含まれている場合があります。 ドリフトが検出されたら、ドリフトを引き起こしている特徴までドリルダウンします。 次に、特徴レベルのメトリックを調べて、ドリフトの根本原因をデバッグし、特定します。
このトップ ダウン アプローチを使用すると、従来のルールベースの手法よりもデータの監視が簡単になります。 許可されたデータ範囲や許可された一意の値などのルールベースの手法では、時間がかかり、エラーが発生しやすくなります。
Azure Machine Learning では、データセット モニターを使用し、データ ドリフトを検出して警告します。
データセット モニター
データセット モニターを使用すると、次のことができます。
- データセット内の新しいデータに対してデータ ドリフトを検出して警告する。
- 履歴データのドラフトを分析する。
- 時系列で新しいデータをプロファイルする。
データ ドリフトに関するアルゴリズムは、データの変化を総合的に測定するだけでなく、どの特徴に詳細な調査が必要であるかがわかるようになっています。 データセット モニターでは、timeseries データセット内の新しいデータをプロファイリングすることによって、ほかにも多くのメトリックが生成されます。
Azure Application Insights を使用することで、モニターによって生成されるすべてのメトリックについてカスタム アラートを設定できます。 データセット モニターを使用すると、データの問題を迅速に検出し、考えられる原因を特定することによって問題のデバッグ時間を短縮できます。
概念的には、Azure Machine Learning でデータセット モニターを設定するシナリオは主に 3 つあります。
| シナリオ | 説明 |
|---|---|
| トレーニング データのドラフトに対してモデルのサービス データを監視する | 供給データがトレーニング データからドリフトすると、モデルの精度が低下するので、このシナリオの結果は、代用品を監視してモデルの精度を調べたものと解釈できます。 |
| 時系列データセットを監視して、以前の期間からのドリフトを調べる。 | このシナリオはより一般的なものであり、モデル構築の上流または下流に関係するデータセットを監視するために使用できます。 対象のデータセットには timestamp 列が必要です。 ベースライン データセットは、ターゲットのデータセットと共通の特徴を持つ表形式のデータセットです。 |
| 過去のデータに対して分析を実行する。 | このシナリオは、履歴データを解釈し、データセット モニターを設定する際の意思決定に反映させるために使用できます。 |
データセット モニターは、次の Azure サービスによって変わります。
| Azure サービス | 説明 |
|---|---|
| データセット | ドリフトでは、Machine Learning データセットを使用してトレーニング データが取得され、モデルのトレーニングのためにデータが比較されます。 データのプロファイル生成を使用して、最小値、最大値、個別値、個別値カウントなどのレポートされたメトリックの一部を生成します。 |
| Azure Machine Learning パイプラインとコンピューティング | ドリフト計算ジョブは、Azure Machine Learning パイプラインでホストされます。 このジョブは、オンデマンドまたはスケジュールによってトリガーされ、ドリフト モニターの作成時に構成されたコンピューティングで実行されます。 |
| Application Insights | ドリフトによって、機械学習ワークスペースに属する Application Insights にメトリックが送信されます。 |
| Azure Blob Storage | ドリフトによって、メトリックが JSON 形式で Azure BLOB Storage に送信されます。 |
ベースライン データセットとターゲット データセット
Azure Machine Learning データセットでデータ ドリフトを監視します。 データセット モニターを作成するときには、次の情報を参照します:
- ベースライン データセット - 通常はモデルのトレーニング データセット。
- ターゲット データセット - 通常はモデルの入力データ - 時間の経過に沿ってベースライン データセットと比較されます。 この比較は、ターゲット データセットにはタイムスタンプ列が指定されている必要があるということを意味します。
モニターは、ベースライン データセットとターゲット データセットを比較します。
モデル モニターに移行する
モデル モニターでは、対応する概念を次のように確認することができます。詳細については、「運用データを Azure Machine Learning に取り込んでモデル監視を設定する」というこちらの記事を参照してください。
- 参照データセット: データ ドリフト検出のベースライン データセットと同様に、最近の過去の運用推論データセットとして設定されます。
- 運用推論データ: データ ドリフト検出のターゲット データセットと同様に、運用推論データは、運用環境にデプロイされたモデルから自動的に収集できます。 これは、格納している推論データにすることもできます。
ターゲット データセットを作成する
ターゲット データセットには、データ内の列またはファイルのパス パターンから派生した仮想列のいずれかにタイムスタンプ列を指定することにより、timeseries 特性が設定されている必要があります。
Python SDK または Azure Machine Learning Studio を使用して、タイムスタンプを持つデータセットを作成します。
timeseries 特性をデータセットに追加するには、"タイムスタンプ" を表す列を指定する必要があります。 データが "{yyyy/MM/dd}" などの時刻情報を含むフォルダー構造にパーティション分割されている場合は、パス パターン設定を使用して仮想列を作成し、"パーティションのタイムスタンプ" として設定して、時系列 API 機能を有効にします。
Dataset クラスの with_timestamp_columns() メソッドによって、データセットのタイム スタンプ列が定義されます。
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
ヒント
データセットの timeseries 特性を使用する完全な例については、ノートブックの例または Datasets SDK のドキュメントを参照してください。

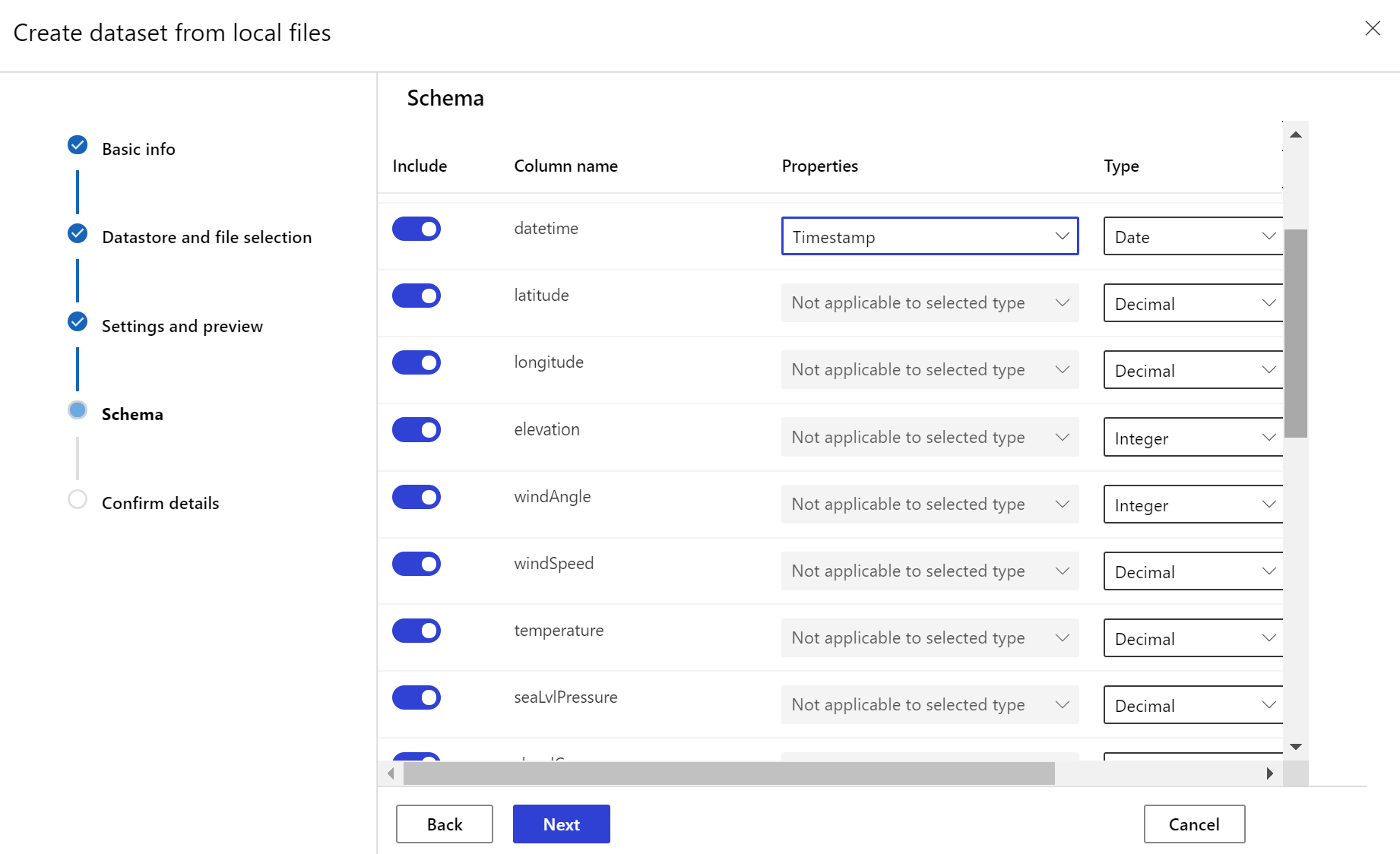
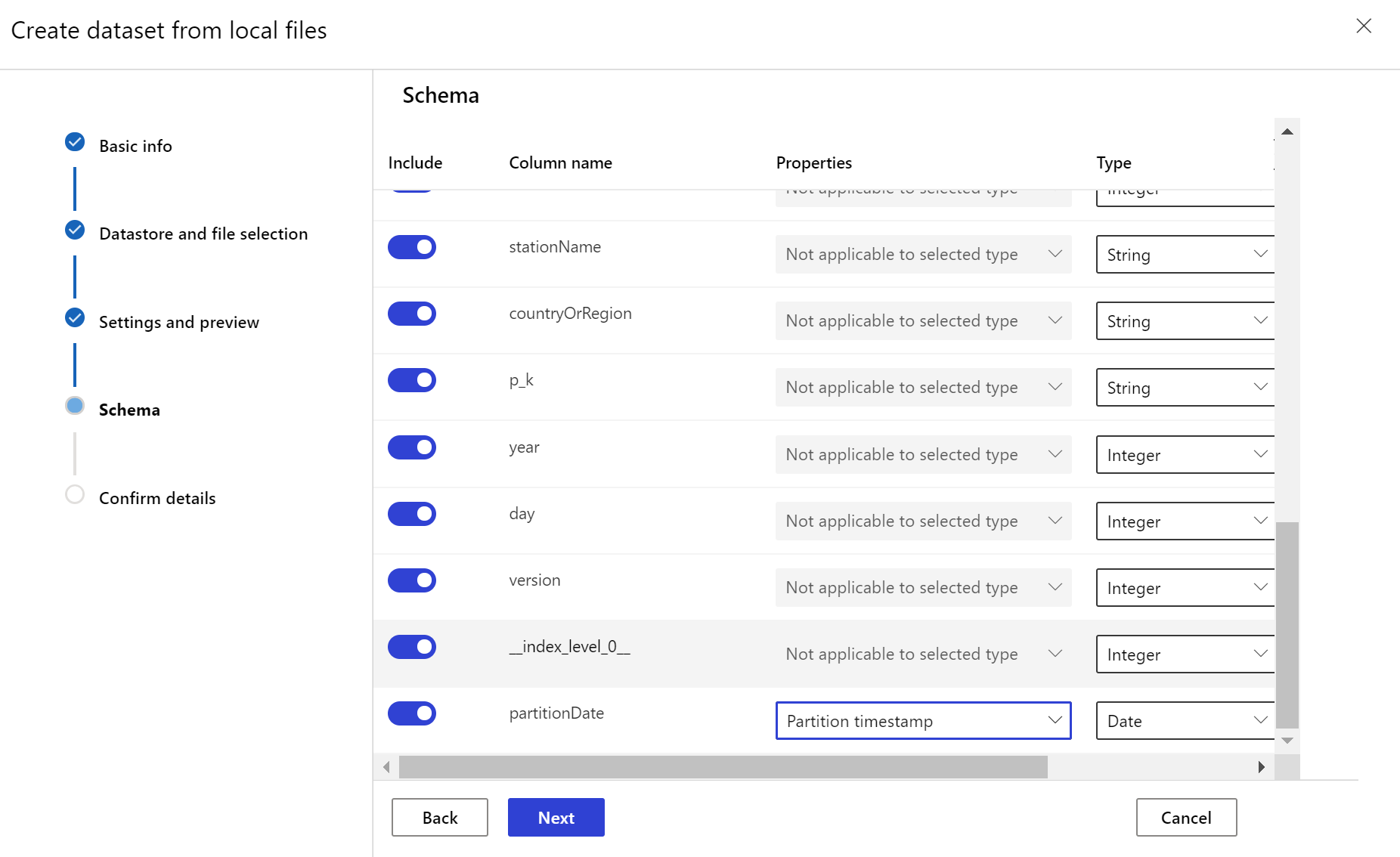
データセット モニターを作成する
新しいデータセットのデータ ドリフトを検出して警告するデータセット モニターを作成します。 Python SDK または Azure Machine Learning Studio のいずれかを使用します。
後で説明するように、データセット モニターは、設定された頻度 (毎日、毎週、毎月) 間隔で実行されます。 前回の実行以降にターゲット データセットで使用できる新しいデータが分析されます。 場合によっては、最新のデータのこのような分析では不十分な場合があります:
- アップストリーム ソースからの新しいデータは、データ パイプラインが壊れたために遅延し、データセット モニターの実行時にこの新しいデータを使用できませんでした。
- 時系列データセットには履歴データのみが含まれており、時間の経過とともにデータセット内のドリフト パターンを分析する必要があります。 たとえば、冬と夏の両方の季節に Web サイトに流れるトラフィックを比較して、季節のパターンを特定します。
- データセット モニターを初めて使用するとします。 将来の日を監視するように設定する前に、既存のデータに対する機能の動作を評価する必要があるとします。 このようなシナリオでは、特定のターゲット データセット セットの日付範囲を含むオンデマンド実行を送信して、ベースライン データセットと比較することができます。
backfill 関数は、指定した開始日と終了日の範囲に対してバックフィル ジョブを実行します。 バックフィル ジョブは、データの精度と完全性を確保する方法として、データ セット内の予期される欠落データ ポイントを埋めます。
Note
Azure Machine Learning モデルの監視は、手動の backfill 関数をサポートしていません。特定の時間の範囲に対してモデル モニターをやり直す場合は、その特定の時間の範囲に対して別のモデル モニターを作成できます。
詳細については、データ ドリフトに関する Python SDK リファレンス ドキュメントを参照してください。
次の例は、Python SDK を使用してデータセット モニターを作成する方法を示しています。
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
ヒント
timeseries データセットとデータ ドリフト検出機能を設定する完全な例については、サンプルのノートブックを参照してください。
![[モニターの作成] ウィザード](media/how-to-monitor-datasets/wizard.png?view=azureml-api-1)
モデル モニターを作成する (モデル モニターに移行する)
モデル モニターに移行するときに、モデルを Azure Machine Learning オンライン エンドポイントの運用環境にデプロイし、デプロイ時にデータ収集を有効にした場合、Azure Machine Learning は運用環境の推論データを収集し、Microsoft Azure Blob Storage に自動的に保存します。 その後、Azure Machine Learning モデルの監視を使用して、この運用推論データを継続的に監視できます。また、モデルを直接選択してターゲット データセット (モデル モニター内の運用推論データ) を作成できます。
モデル モニターに移行するときに、Azure Machine Learning オンライン エンドポイントの運用環境にモデルをデプロイしなかった場合、またはデータ収集を使用したくない場合は、カスタム シグナルとメトリックを使用してモデル監視を設定することもできます。
以下のセクションでは、モデル モニターに移行する方法について詳しく説明します。
自動的に収集された運用データを使用してモデル モニターを作成する (モデル モニターに移行する)
Azure Machine Learning オンライン エンドポイントでモデルを運用環境にデプロイし、デプロイ時にデータ収集を有効にした場合。
次のコードを使って、すぐに使用できるモデルモニタリングを設定できます。
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()

![モデル監視のための [基本設定] ページのスクリーンショット。](media/how-to-monitor-models/model-monitoring-basic-setup.png?view=azureml-api-1#lightbox)
カスタム データ前処理コンポーネントを介してモデル モニターを作成する (モデル モニターに移行する)
モデル モニターに移行するときに、Azure Machine Learning オンライン エンドポイントの運用環境にモデルをデプロイしなかった場合、またはデータ収集を使用したくない場合は、カスタム シグナルとメトリックを使用してモデル監視を設定することもできます。
運用データはあるがデプロイがない場合は、データを使用して継続的なモデルモニタリングを実行できます。 これらのモデルを監視するには、次のことが可能である必要があります。
- 運用環境にデプロイされたモデルから運用環境の推論データを収集します。
- 運用環境の推論データを Azure Machine Learning データ資産として登録し、データの継続的な更新を保証します。
- カスタム データ前処理コンポーネントを提供し、Azure Machine Learning コンポーネントとして登録します。
データ コレクターでデータが収集されない場合は、カスタム データ前処理コンポーネントを指定する必要があります。 このカスタム データ前処理コンポーネントがないと、Azure Machine Learning モデルモニタリング システムは、時間枠をサポートする表形式にデータを処理する方法を認識しません。
カスタム前処理コンポーネントには、次の入力シグネチャと出力シグネチャが必要です。
| [入力または出力] | シグネチャ名 | 型 | 説明 | 例値 |
|---|---|---|---|---|
| input | data_window_start |
リテラル、文字列 | ISO8601 形式のデータ ウィンドウ開始日時。 | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
リテラル、文字列 | ISO8601 形式のデータ ウィンドウ終了日時。 | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | 収集された運用推論データ。Azure Machine Learning データ資産として登録されます。 | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | 表形式データセット。参照データ スキーマのサブセットと一致します。 |
カスタム データ前処理コンポーネントの例については、「azuremml-examples GitHub リポジトリのcustom_preprocessing」を参照してください。
データ ドリフトの結果の概要
このセクションでは、Azure Studio の [データセット] / [データセット モニター] ページに表示されるデータセットの監視結果について説明します。 このページでは、設定を更新し、特定の期間の既存のデータを分析することができます。
データ ドリフトの規模に関する最上位レベルの分析情報と、さらに調査すべき特徴の見所から始めます。
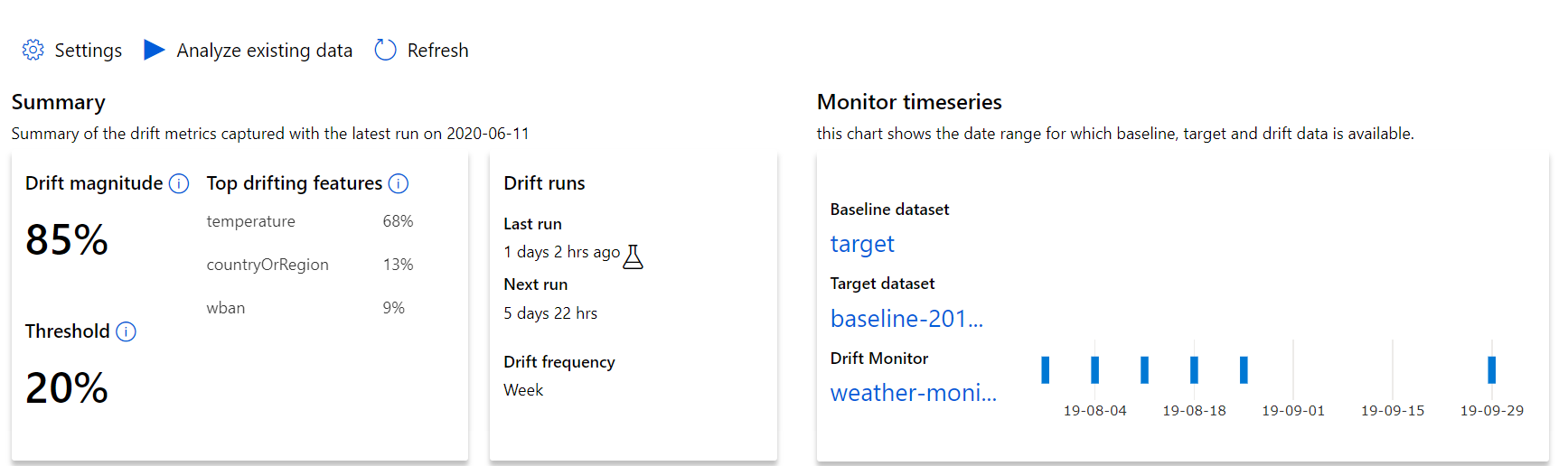
| メトリック | 説明 |
|---|---|
| データ ドリフトの大きさ | 時間の経過と共に生じるベースラインとターゲットのデータセット間のドリフトのパーセンテージ。 このパーセンテージは 0 から 100 までの範囲で示され、0 はデータセットが同一であることを表し、100 は Azure Machine Learning データ ドリフト モデルによって 2 つのデータセットが完全に識別可能であることを表します。 この大きさを生成するために使用されている機械学習の手法が原因で、測定されたパーセンテージの数値にはノイズの混入が想定されます。 |
| ドリフトが発生している主な特徴 | データセット内の機能のうち最も多くドリフトが発生し、ドリフトの規模指標に最も関与しているものを示します。 共変量シフトがあるため、基盤となる特徴の分布が特徴として比較的高い重要度になるように変更する必要は必ずしもありません。 |
| Threshold | データ ドリフトの規模が設定されたしきい値を超えると、アラートがトリガーされます。 モニター設定でしきい値を構成します。 |
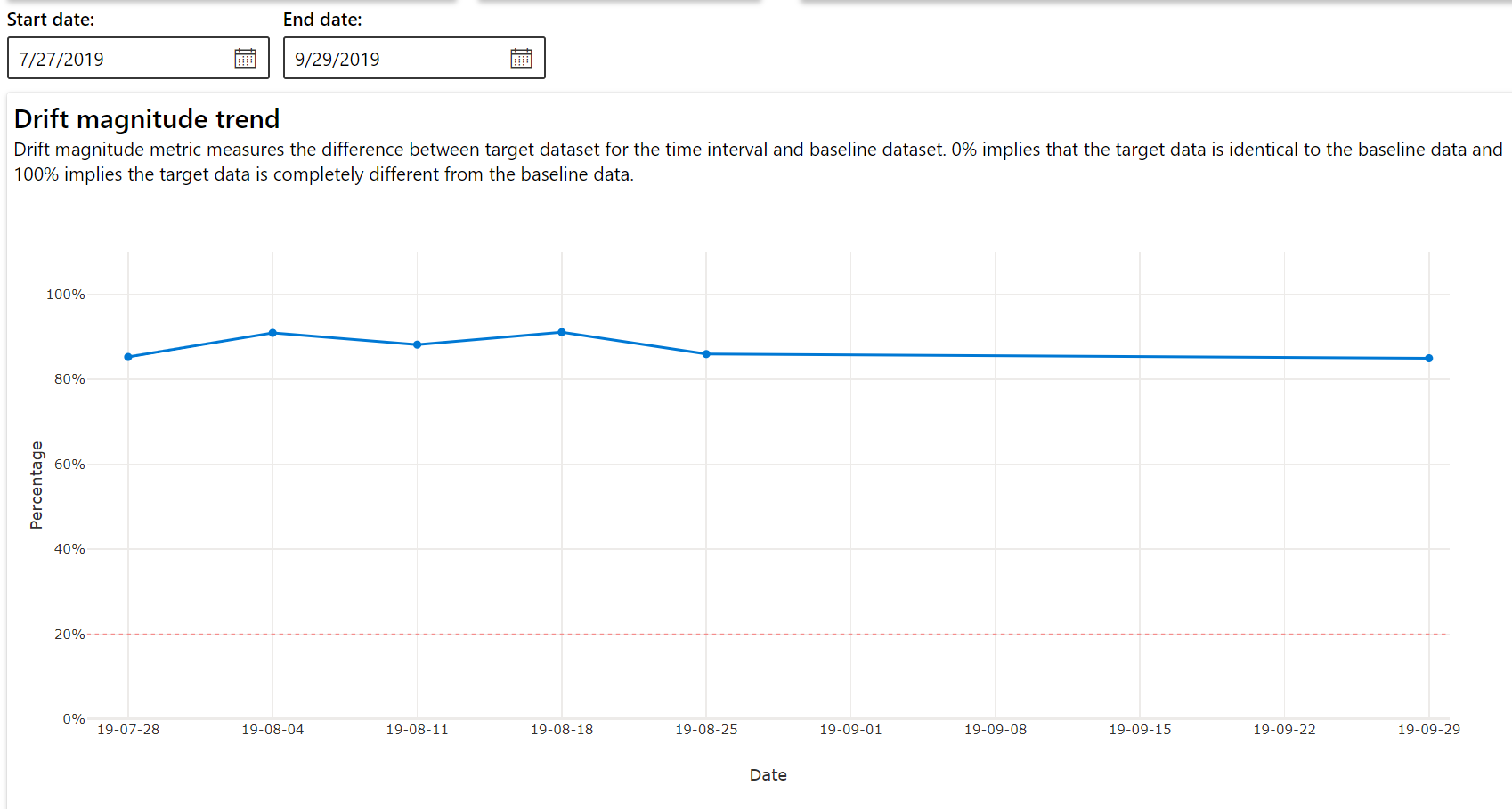
ドリフトの規模の傾向
指定した期間内のデータセットとターゲット データセットの違いを確認します。 100% に近いほど、2 つのデータセットの違いは大きくなります。
特徴ごとのドリフトの規模
このセクションには、選択した特徴の分布の経時的変化に対する特徴レベルの分析情報と、その他の統計情報が含まれています。
ターゲット データセットも時間の経過に沿ってプロファイリングされます。 各特徴のベースライン分布間の統計的な距離は、ターゲット データセットの時間の経過と比較されます。 概念的には、これはデータ ドリフトの規模と似ています。 ただし、この統計的な距離は、すべての特徴ではなく、個々の特徴に対するものです。 最小値、最大値、平均値も取得できます。
Azure Machine Learning Studio でグラフ内のバーを選択すると、その日付の特徴レベルの詳細が表示されます。 既定では、同じ特徴について、ベースライン データセットの分布と最近のジョブの分布が表示されます。
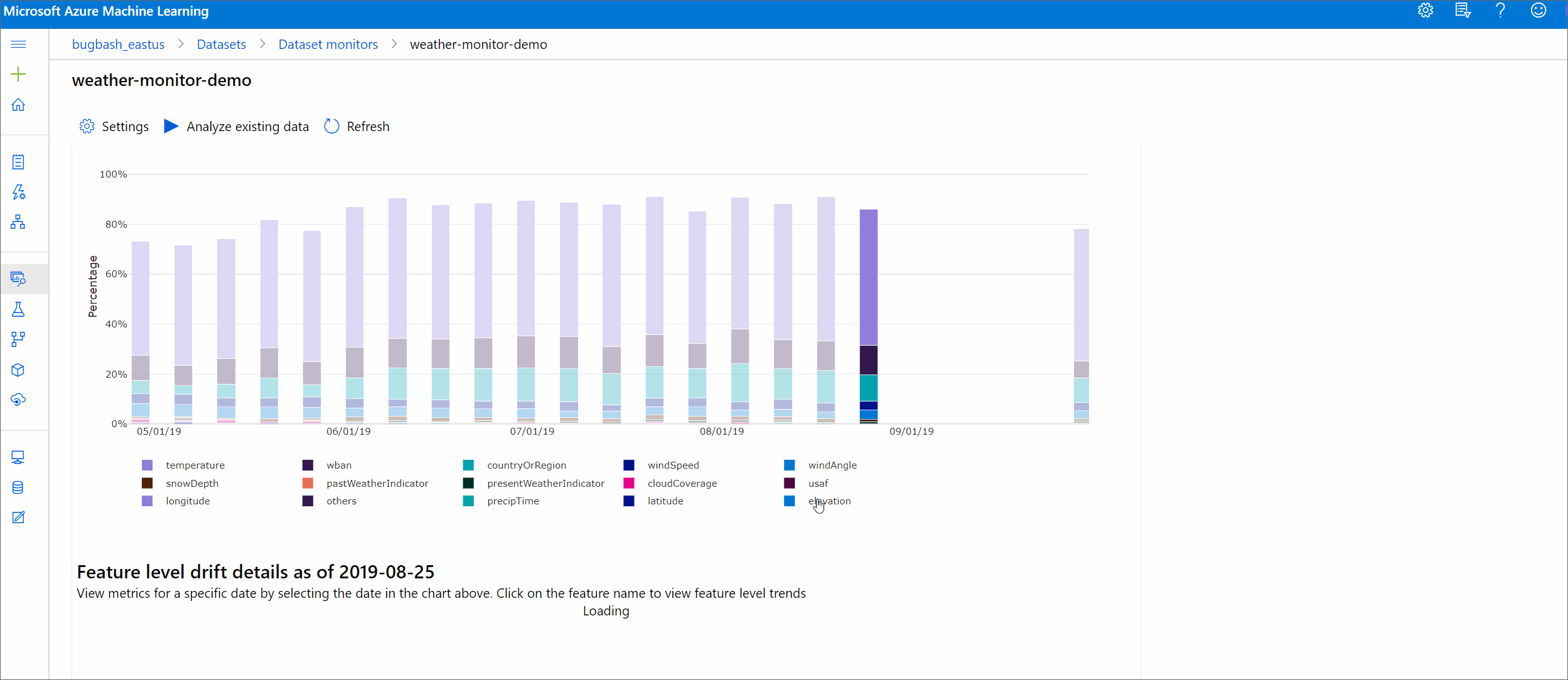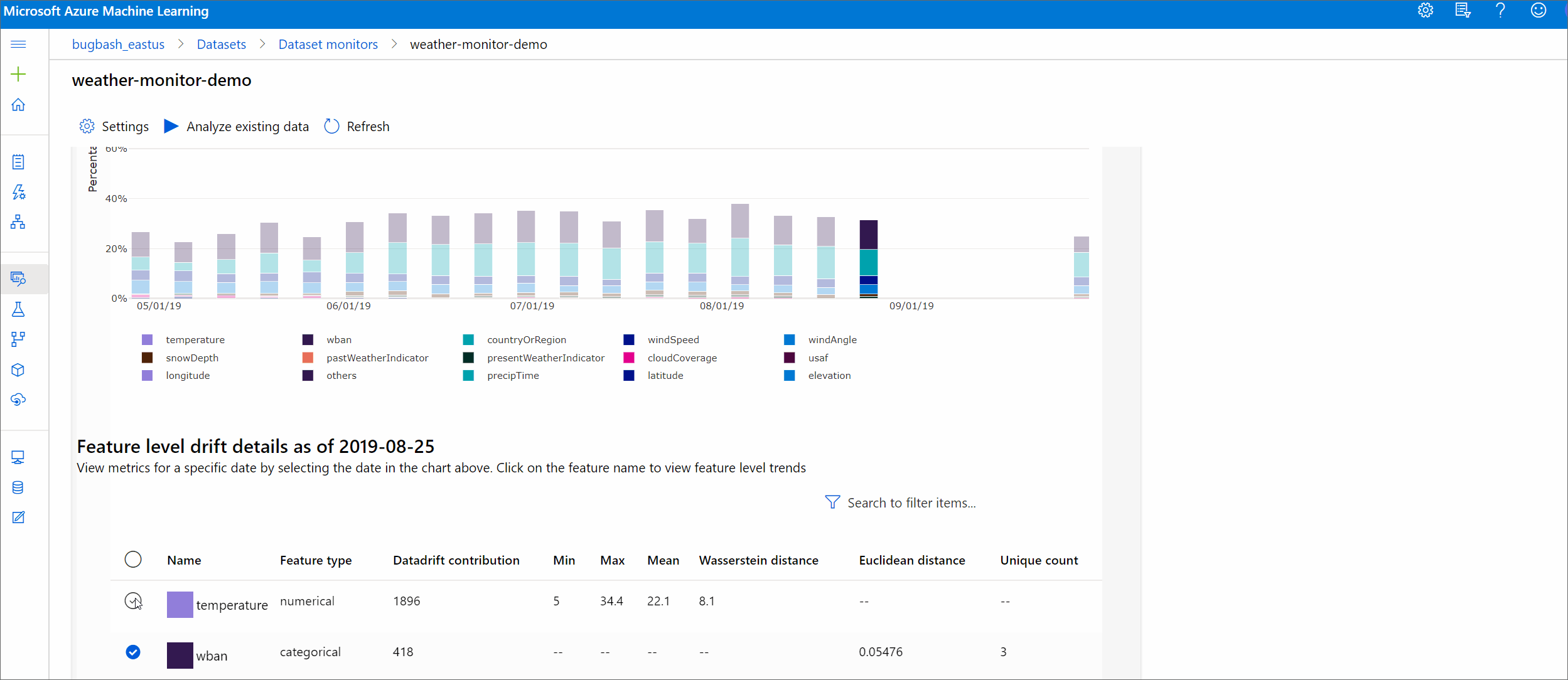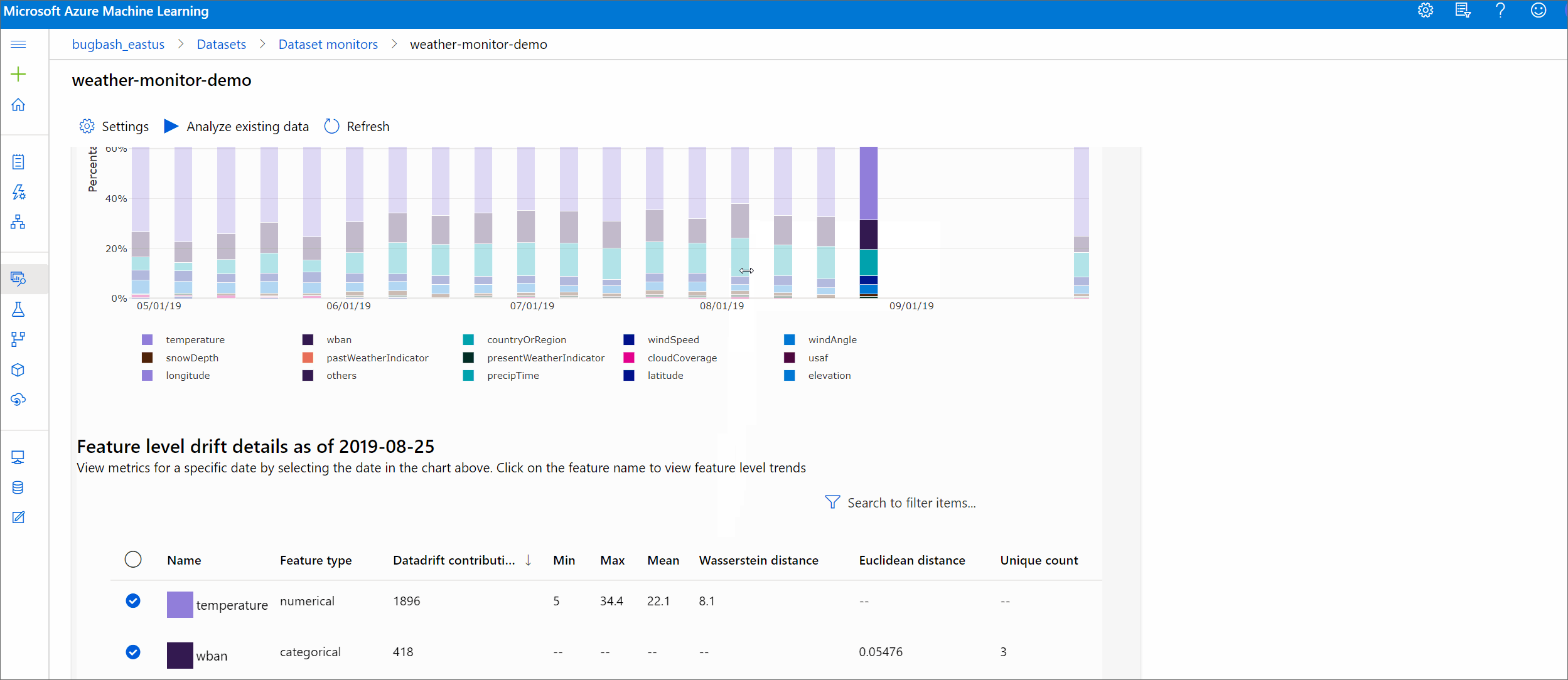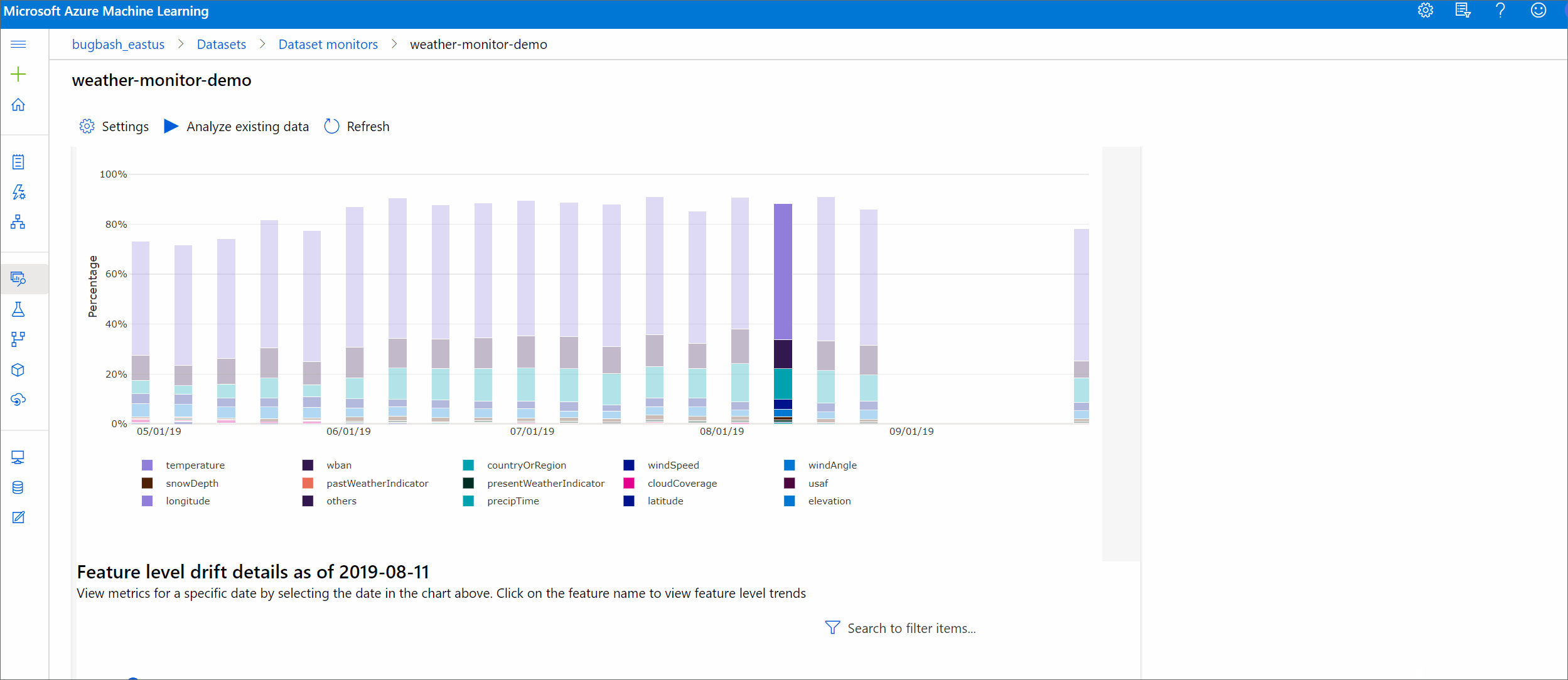
これらのメトリックは、Python SDK で、DataDriftDetector オブジェクトに get_metrics() メソッドを実行して取得することもできます。
特徴の詳細
最後に、下にスクロールして、個々の特徴の詳細を確認します。 グラフの上にあるプルダウンを使用して特徴を選択し、詳細を確認するメトリックを選択します。
グラフのメトリックは、特徴の種類によって異なります。
数値の特徴
メトリック 説明 ワッサースタイン距離 ベースライン分布をターゲット分布に変換するための最小限の作業量。 平均値 特徴量の平均値。 最小値 特徴量の最小値。 最大値 特徴量の最大値。 カテゴリ別の特徴
メトリック 説明 ユークリッド距離 カテゴリ列に対して計算されます。 ユークリッド距離は 2 つのベクトルに対して計算され、2 つのデータセットからの同じカテゴリ列の経験的分布から生成されます。 0 は、経験的分布に差がないことを示します。 0 から外れるほど、この列のドリフトは大きくなります。 傾向は、このメトリックの時系列プロットから観察でき、ドリフトが生じている特徴を明らかにするために役立ちます。 一意の値の数 特徴の一意の値 (カーディナリティ) の数。
このグラフで、1 つの日付を選択して、表示された特徴のターゲットとこの日付の間の特徴の分布を比較します。 数値の特徴の場合、これは 2 つの確率分布を示します。 特徴が数値の場合、横棒グラフが表示されます。
メトリック、アラート、イベント
メトリックは、Machine Learning ワークスペースに関連付けられている Azure Application Insights リソースで照会できます。 カスタム アラート ルールの設定や、アクション (メール、SMS、プッシュ、音声、Azure 関数など) をトリガーするためのアクション グループの設定など、Application Insights のすべての機能にアクセスすることができます。 詳細については、Application Insights の包括的ドキュメントを参照してください。
最初に、Azure portal に移動し、ワークスペースの [概要] ページを選択します。 関連付けられている Application Insights リソースが右端に表示されます。

左側のペインの [監査] から [ログ (Analytics)] を選択します。
データセット モニターのメトリックは、customMetrics として格納されます。 データセット モニターの設定後、クエリを記述して実行すれば、それらを表示できます。

アラート ルールを設定するためのメトリックを確認したら、新しいアラート ルールを作成できます。
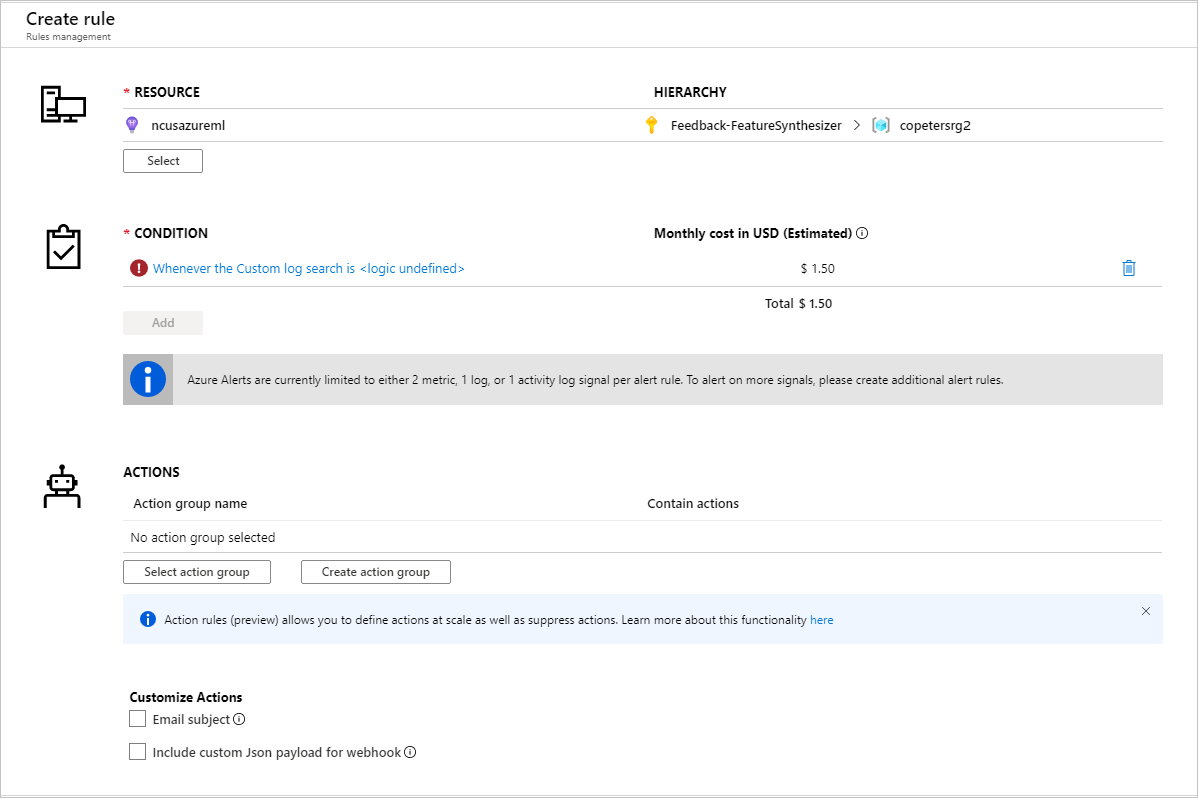
既存のアクション グループを使用するか、または、新しいアクション グループを作成して、設定した条件が満たされたときに実行されるアクションを定義することができます。
トラブルシューティング
データ ドリフト モニターに関する制限事項と既知の問題
履歴データ分析時の時間範囲は、モニターの頻度設定の 31 間隔までに制限されます。
特徴一覧が指定されていない (すべての特徴を使用する) 場合、200 の特徴に制限されます。
コンピューティング サイズは、データを処理できる十分な大きさにする必要があります。
特定のモニターのジョブについて、開始日と終了日の範囲に該当するデータがデータセットに存在することを確認します。
データセット モニターは、50 行以上を含むデータセットでのみ機能します。
データセット内の列、つまり特徴は、次の表の条件に基づいてカテゴリまたは数値として分類されます。 特徴がこれらの条件を満たしていない場合 (たとえば、string 型の列に一意の値が >100 個含まれる場合)、その特徴はデータ ドリフト アルゴリズムから削除されますが、プロファイリングは引き続き行われます。
特徴の種類 データ型 条件 制限事項 Categorical string 特徴内の一意の値の数は、100 個未満であり、かつ行数の 5% 未満であること。 null 値は独自のカテゴリとして扱われます。 数値 int、float 特徴内の値は数値データ型で、カテゴリの特徴の条件を満たしていません。 値の数の >15% を超える null が含まれる場合、その特徴は削除されます。 データ ドリフト モニターを作成したが、Azure Machine Learning Studio の "データセット モニター" ページにデータが表示されない場合は、次を試してください。
- ページの一番上で正しい日付範囲が選択されているかどうかを確認します。
- [データセット モニター] タブで、実験リンクを選択し、ジョブ状態を確認します。 このリンクはテーブルの右端にあります。
- ジョブが正常に完了したら、生成されているメトリックの数や警告メッセージがあるかどうかをドライバー ログで確認します。 実験を選択したら、[出力 + ログ] タブでドライバー ログを見つけます。
SDK の
backfill()関数で予期された出力が生成されない場合は、認証の問題が原因である可能性があります。 この関数に渡す計算を作成するときに、Run.get_context().experiment.workspace.compute_targetsを使用しないでください。 代わりに、次のような ServicePrincipalAuthentication を使用して、そのbackfill()関数に渡す計算を作成します。
Note
コードでサービス プリンシパルのパスワードをハード コーディングしないでください。 代わりに、Python 環境、キーストア、またはシークレットにアクセスするその他の安全な方法から取得します。
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
モデル データ コレクターからは、BLOB ストレージ アカウントにデータが到着するまでに最大で 10 分かかることがあります。 ただし、通常はそこまで時間はかかりません。 スクリプトまたは Notebook で、次のセルが実行されるように、10 分間待機します。
import time time.sleep(600)
次のステップ
- Azure Machine Learning Studio または Python ノートブックに移動して、データセット モニターを設定する。
- Azure Kubernetes Service にデプロイされたモデルでデータ ドリフトを設定する方法を確認する。
- Azure Event Grid を使用してデータセット ドリフト モニターを設定する。