適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、Jupyter Notebook で R カーネルを実行するコンピューティング インスタンスにおいて、Azure Machine Learning スタジオで R を使用する方法について説明します。します。
一般的な RStudio IDE を使用することもできます。 RStudio または Posit Workbench は、コンピューティング インスタンスのカスタム コンテナーにインストールできます。 ただし、その場合、Azure Machine Learning ワークスペースに対する読み取りと書き込みに制限があります。
重要
この記事に示されているコードは、Azure Machine Learning コンピューティング インスタンスで動作します。 コンピューティング インスタンスには、コードを正常に実行するために必要な環境と構成ファイルがあります。
前提条件
- Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning を試してください
- Azure Machine Learning ワークスペースとコンピューティング インスタンス
- Azure Machine Learning スタジオでの Jupyter ノートブックの使用に関する基本的な知識。 詳細については、「クラウド ワークステーションでのモデル開発」のリソースを参照してください。
スタジオのノートブックで R を実行する
コンピューティング インスタンス上の Azure Machine Learning ワークスペースでノートブックを使用します。
Azure Machine Learning Studio にサインインします。
あなたのワークスペースがまだ開いていない場合は、開いてください。
左側のナビゲーションで [ノートブック] を選択します
RunR.ipynb という名前の新しいノートブックを作成します
ヒント
スタジオでノートブックを作成して操作する方法がわからない場合は、「ワークスペースで Jupyter ノートブックを実行する」を参照してください。
このノートブックを選択します。
ノートブックのツール バーで、コンピューティング インスタンスが実行されていることを確認します。 もし実行されていない場合は、ただちに開始してください。
ノートブックのツール バーで、カーネルを [R] に切り替えます。
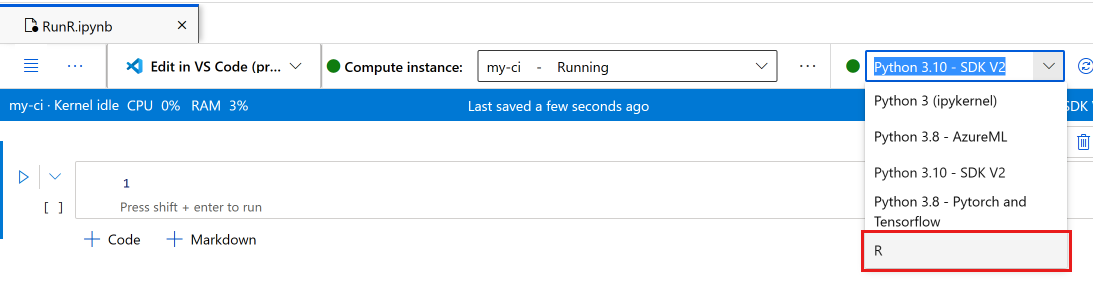

これで、ノートブックで R コマンドを実行する準備ができました。
データにアクセスする
ワークスペース ファイル ストレージ リソースにファイルをアップロードし、R でそれらのファイルにアクセスできます。ただし、Azure "データ アセット" または "データストア" からのデータに保存されたファイルの場合、いくつかのパッケージをインストールする必要があります。
このセクションでは、Python と reticulate パッケージを使用して、対話型セッションからデータ アセットとデータストアを R に読み込む方法について説明します。
azureml-fsspec Python パッケージと reticulate R パッケージを使用して、表形式データを Pandas DataFrames として読み取ります。 さらに、このセクションでは、データ資産とデータストアを R data.frameに読み込む例も取り上げます。
これらのパッケージをインストールするには:
コンピューティング インスタンスで、setup.sh という名前の新しいファイルを作成します。
そのファイルにこのコードをコピーします。
#!/bin/bash set -e # Installs azureml-fsspec in default conda environment # Does not need to run as sudo eval "$(conda shell.bash hook)" conda activate azureml_py310_sdkv2 pip install azureml-fsspec conda deactivate # Checks that version 1.26 of reticulate is installed (needs to be done as sudo) sudo -u azureuser -i <<'EOF' R -e "if (packageVersion('reticulate') >= 1.26) message('Version OK') else install.packages('reticulate')" EOF[ターミナルでスクリプトを保存して実行する] を選択してスクリプトを実行します
インストール スクリプトでは、こちらの手順が実行されます。
-
pipにより、コンピューティング インスタンスの既定の conda 環境にazureml-fsspecがインストールされます - 必要に応じて R の
reticulateパッケージがインストールされます (バージョンは 1.26 以上である必要があります)
登録済みのデータ アセットまたはデータストアから表形式データを読み取る
Azure Machine Learning で作成されたデータ アセットにデータが保存されている場合、こちらの手順を使用して、その表形式ファイルを Pandas DataFrame または R の data.frame に読み込みます。
注
reticulate を使用したファイルの読み取りは、表形式のデータでのみ機能します。
reticulateの正しいバージョンがあることを確認します。 バージョンが 1.26 未満の場合、新しいコンピューティング インスタンスを使用してみてください。packageVersion("reticulate")reticulateを読み込み、azureml-fsspecがインストールされた conda 環境を設定しますlibrary(reticulate) use_condaenv("azureml_py310_sdkv2") print("Environment is set")データ ファイルへの URI パスを見つけます。
最初に、ワークスペースのハンドルを取得します
py_code <- "from azure.identity import DefaultAzureCredential from azure.ai.ml import MLClient credential = DefaultAzureCredential() ml_client = MLClient.from_config(credential=credential)" py_run_string(py_code) print("ml_client is configured")このコードを使用してアセットを取得します。
<MY_NAME>と<MY_VERSION>は、実際のデータ アセットの名前と番号に置き換えてください。ヒント
スタジオの左側のナビゲーションで [データ] を選択して、データ アセットの名前とバージョン番号を見つけます。
# Replace <MY_NAME> and <MY_VERSION> with your values py_code <- "my_name = '<MY_NAME>' my_version = '<MY_VERSION>' data_asset = ml_client.data.get(name=my_name, version=my_version) data_uri = data_asset.path"URI を取得するには、コードを実行します。
py_run_string(py_code) print(paste("URI path is", py$data_uri))
Pandas 読み取り関数を使用してファイルを R 環境に読み込みます。
pd <- import("pandas") cc <- pd$read_csv(py$data_uri) head(cc)
R パッケージのインストール
コンピューティング インスタンスには、R パッケージが数多くプレインストールされています。
他のパッケージをインストールするには、場所と依存関係を明示的に指定する必要があります。
ヒント
別のコンピューティング インスタンスを作成または使用する場合は、インストールしたパッケージをすべて再インストールする必要があります。
たとえば、tsibble パッケージをインストールするには、次のようにします。
install.packages("tsibble",
dependencies = TRUE,
lib = "/home/azureuser")
注
Jupyter ノートブックで実行される R セッション内でパッケージをインストールする場合、dependencies = TRUE は必須です。 これを使用しないと、依存パッケージが自動的にインストールされません。 正しいコンピューティング インスタンスの場所にインストールするために、lib の場所も必須です。
R ライブラリを読み込む
/home/azureuser を R ライブラリ パスに追加します。
.libPaths("/home/azureuser")
ヒント
ユーザーがインストールしたライブラリにアクセスするために、各対話型 R スクリプトで .libPaths を更新する必要があります。 このコードを各対話型 R スクリプトまたはノートブックの先頭に追加します。
libPath が更新されたら、通常どおりにライブラリを読み込みます。
library('tsibble')
ノートブックで R を使用する
前述の問題以外は、ローカル ワークステーションなど他の環境と同様に R を使用します。 ノートブックまたはスクリプトで、ノートブック/スクリプトが保存されているパスに対する読み取りと書き込みを行うことができます。
注
- 対話型 R セッションからは、ワークスペース ファイル システムへの書き込みのみ行うことができます。
- 対話型 R セッションから、MLflow (ログ モデルやクエリ レジストリなど) は操作できません。