重要
この記事では、Azure Machine Learning SDK v1 の使用に関する情報を提供します。 SDK v1 は 2025 年 3 月 31 日の時点で非推奨となり、サポートは 2026 年 6 月 30 日に終了します。 SDK v1 は、その日付までインストールして使用できます。
2026 年 6 月 30 日より前に SDK v2 に移行することをお勧めします。 SDK v2 の詳細については、「 Azure Machine Learning Python SDK v2 と SDK v2 リファレンスとは」を参照してください。
この記事では、デザイナーを使用してバッチ予測パイプラインを作成する方法について説明します。 バッチ予測では、任意の HTTP ライブラリからトリガーできる Web サービスを使用して、大規模なデータセットをオンデマンドで継続的にスコア付けできます。
このハウツー ガイドでは、次のタスクを実行する方法について説明します。
- バッチ推論パイプラインを作成して発行します。
- パイプライン エンドポイントを使用します。
- エンドポイントのバージョンを管理します。
SDK を使用してバッチ スコアリング サービスを設定する方法については、「 チュートリアル: 画像分類用の Azure Machine Learning パイプラインを構築する」を参照してください。
前提条件
このガイドは、既にトレーニング パイプラインがあることを前提としています。 デザイナーのガイド付き概要については、デザイナーのチュートリアルのパート 1 を完了してください。
重要
このドキュメントで言及しているグラフィカル要素 (スタジオやデザイナーのボタンなど) が表示されない場合は、そのワークスペースに対する適切なレベルのアクセス許可がない可能性があります。 ご自分の Azure サブスクリプションの管理者に連絡して、適切なレベルのアクセス許可があることを確認してください。 詳細については、「ユーザーとロールを管理する」を参照してください。
バッチ推論パイプラインを作成する
推論パイプラインを作成できるようにするには、トレーニング パイプラインを少なくとも 1 回実行する必要があります。
Machine Learning Studio にサインインし、[デザイナー] を選択 します。
予測の作成に使用するモデルをトレーニングするトレーニング パイプラインを選択します。
パイプラインを送信します。


ジョブの詳細リンクを選択してジョブの詳細ページに移動し、トレーニング パイプライン ジョブが完了したら、バッチ推論パイプラインを作成できます。
サイドバー メニューで [ジョブ ] を選択し、ジョブを選択します。 キャンバスの上にあるドロップダウンの [ 推論パイプラインの作成] を選択します。 [Batch inference pipeline](バッチ推論パイプライン) を選択します。
注意
現在、推論パイプラインの自動生成は、デザイナーの組み込みコンポーネントによって純粋に構築されたトレーニング パイプラインでのみ機能します。
 が強調表示された [Create inference pipeline](推論パイプラインの作成) ドロップダウンのスクリーンショット。](media/how-to-run-batch-predictions-designer/create-batch-inference.png?view=azureml-api-1)
バッチ推論パイプラインのドラフトが自動的に作成されます。 バッチ推論パイプラインのドラフトでは、トレーニングされたモデルを MD- ノードとして、変換をトレーニング パイプライン ジョブの TD- ノードとして使用します。
この推論パイプラインのドラフトを変更して、バッチ推論の入力データをより適切に処理することもできます。

 が強調表示された [Create inference pipeline](推論パイプラインの作成) ドロップダウンのスクリーンショット。](media/how-to-run-batch-predictions-designer/create-batch-inference.png?view=azureml-api-1#lightbox)

パイプライン入力を追加する
新しいデータに対して予測を作成するには、このパイプライン ドラフト ビューで別のデータセットを手動で接続するか、データセットの入力パラメーターを作成します。 入力を使用すると、実行時のバッチ推論プロセスの動作を変更できます。
このセクションでは、予測を行う別のデータセットを指定するパイプライン入力を作成します。
データセット コンポーネントをダブルクリックします。
キャンバスの右側にペインが表示されます。 ウィンドウの下部にある [ パイプライン入力として設定] を選択します。
入力の名前を入力するか、既定値をそのまま使用します。
![パイプライン入力として設定がオンになっている[クリーンされたデータセット] タブのスクリーンショット。](media/how-to-run-batch-predictions-designer/create-pipeline-parameter.png?view=azureml-api-1)
バッチ推論パイプラインを送信します。
![パイプライン入力として設定がオンになっている[クリーンされたデータセット] タブのスクリーンショット。](media/how-to-run-batch-predictions-designer/create-pipeline-parameter.png?view=azureml-api-1#lightbox)
バッチ推論パイプラインを発行する
これで、推論パイプラインをデプロイする準備ができました。 これにより、パイプラインがデプロイされ、他のユーザーが使用できるようになります。
ジョブの詳細ページで、リボン メニューの [発行 ] ボタンを選択します。
表示されたダイアログで、[ 新規作成] を選択します。
エンドポイント名と説明 (省略可能) を指定します。
ダイアログの下部近くに、トレーニング中に使用されるデータセット ID の既定値で構成した入力が表示されます。
[発行] を選択します。
 のスクリーンショット。](media/how-to-run-batch-predictions-designer/publish-inference-pipeline.png?view=azureml-api-1)
 のスクリーンショット。](media/how-to-run-batch-predictions-designer/publish-inference-pipeline.png?view=azureml-api-1#lightbox)
エンドポイントを使用する
これで、データセット パラメーターを含む発行済みパイプラインが完成しました。 パイプラインでは、トレーニング パイプラインで作成されたトレーニング済みモデルを使用して、パラメーターとして指定したデータセットにスコアを付けます。
パイプライン ジョブを送信する
このセクションでは、手動パイプライン ジョブを設定し、パイプライン パラメーターを変更して新しいデータをスコア付けします。
デプロイが完了したら、サイドバー メニューの [ パイプライン ] を選択します。
[ パイプライン エンドポイント ] タブを選択します。
作成したエンドポイントの名前を選択します。
 タブのスクリーンショット。](media/how-to-run-batch-predictions-designer/manage-endpoints.png?view=azureml-api-1)
[Published pipelines](発行済みパイプライン) を選択します。
この画面には、このエンドポイントで発行されたすべての発行済みパイプラインが表示されます。
発行したパイプラインを選択します。
パイプライン詳細ページには、パイプラインの詳細なジョブ履歴と接続文字列情報が表示されます。
[送信] を選択し、パイプラインの手動実行を作成します。
 のスクリーンショット。](media/how-to-run-batch-predictions-designer/submit-manual-run.png?view=azureml-api-1)
別のデータセットを使用するようにパラメーターを変更します。
[送信] を選択し、パイプラインを実行します。
 のスクリーンショット。](media/how-to-run-batch-predictions-designer/submit-manual-run.png?view=azureml-api-1#lightbox)
REST エンドポイントを使用する
パイプライン エンドポイントと発行されたパイプラインを使用する方法についての情報は、[エンドポイント] セクションにあります。
パイプライン エンドポイントの REST エンドポイントは、ジョブの概要パネルで確認できます。 エンドポイントを呼び出すことにより、既定の発行済みパイプラインが使用されます。
発行済みパイプラインは、[Published pipelines](発行済みパイプライン) ページでも使用できます。 発行済みパイプラインを選択すると、グラフの右側にある [Published pipeline overview](発行済みパイプラインの概要) パネルにそのパイプラインの REST エンドポイントが表示されます。
REST 呼び出しを行うには、OAuth 2.0 ベアラー型認証ヘッダーが必要です。 ワークスペースの認証を設定し、パラメーター化された REST を呼び出す方法については、次のチュートリアル セクションをご覧ください。
エンドポイントのバージョン管理
デザイナーは、エンドポイントに発行する後続の各パイプラインにバージョンを割り当てます。 REST 呼び出しでパラメーターとして実行するパイプライン バージョンを指定できます。 バージョン番号を指定しない場合、デザイナーは既定のパイプラインを使用します。
パイプラインを発行するときに、そのエンドポイントの新しい既定のパイプラインにするように選択できます。
 にチェックマークが付いた [Set up published pipeline](発行済みパイプラインの設定) のスクリーンショット。](media/how-to-run-batch-predictions-designer/set-default-pipeline.png?view=azureml-api-1)
エンドポイントの [Published pipelines](発行済みパイプライン) タブで新しい既定のパイプラインを設定することもできます。
パイプライン エンドポイントを更新する
トレーニング パイプラインで何らかの変更を行った場合、新しくトレーニングされたモデルをパイプライン エンドポイントに対して更新できます。
変更したトレーニング パイプラインが正常に完了したら、ジョブの詳細ページに移動します。
[モデルのトレーニング] コンポーネントを右クリックし、[データの登録] を選択します。
![[データの登録] が強調表示された [モデルのトレーニング] コンポーネント オプションのスクリーンショット。](media/how-to-run-batch-predictions-designer/register-train-model-as-dataset.png?view=azureml-api-1)
名前を入力し、[ ファイル の種類] を選択します。
![[データ資産] が選択された [Register as data asset](データ資産として登録) のスクリーンショット。](media/how-to-run-batch-predictions-designer/register-train-model-as-dataset-2.png?view=azureml-api-1)
前のバッチ推論パイプラインドラフトを見つけるか、発行されたパイプラインを新しいドラフトに 複製 します。
推論パイプラインドラフトの MD- ノードを、前の手順で登録したデータに置き換えます。
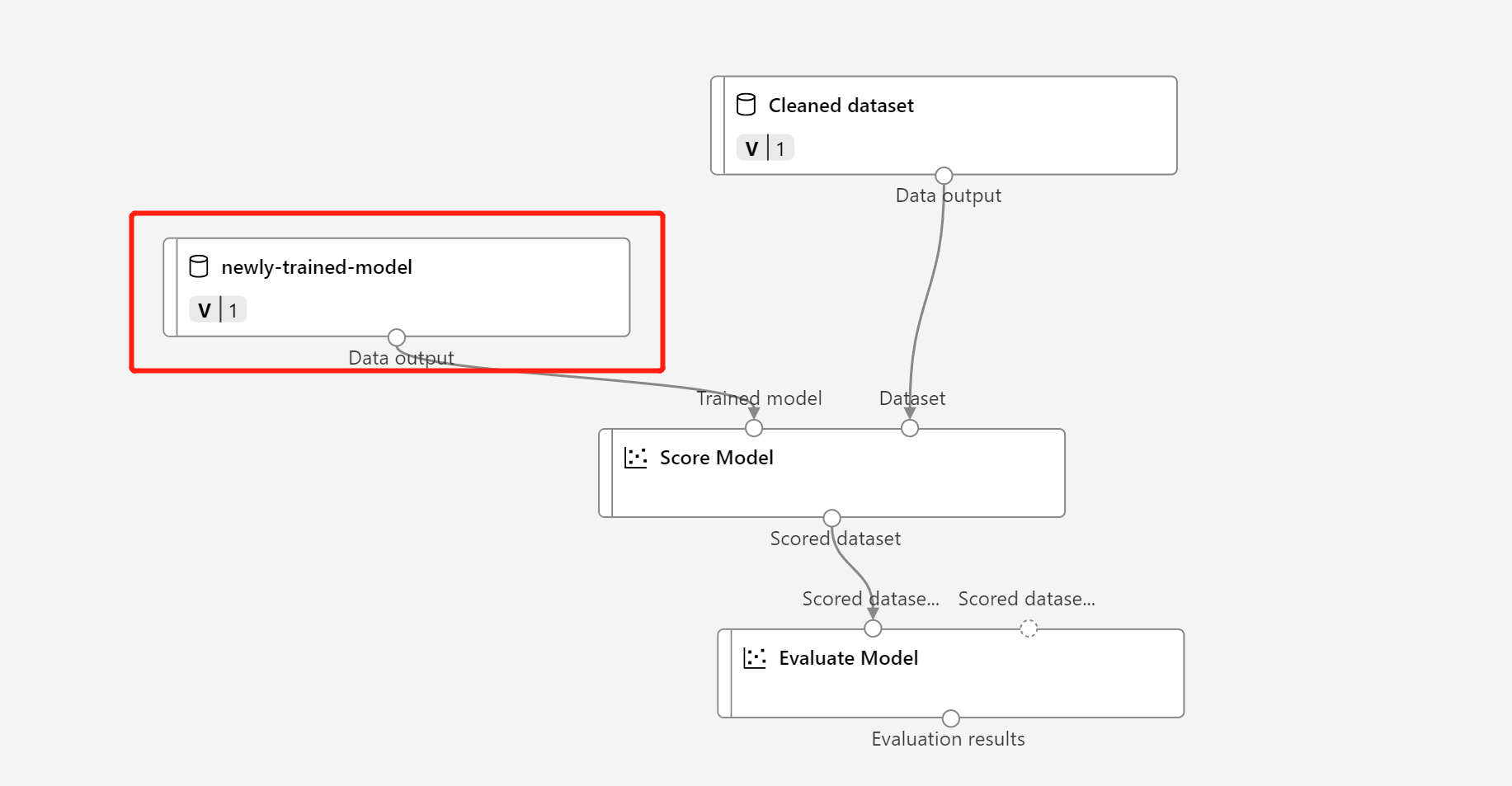
データ変換ノード TD- の更新は、トレーニング済みモデルと同じです。
更新されたモデルと変換を使用して推論パイプラインを送信し、もう一度発行します。
![[データの登録] が強調表示された [モデルのトレーニング] コンポーネント オプションのスクリーンショット。](media/how-to-run-batch-predictions-designer/register-train-model-as-dataset.png?view=azureml-api-1#lightbox)
![[データ資産] が選択された [Register as data asset](データ資産として登録) のスクリーンショット。](media/how-to-run-batch-predictions-designer/register-train-model-as-dataset-2.png?view=azureml-api-1#lightbox)