Azure Machine Learning データセットをバージョン管理および追跡する
適用対象:  Python SDK azureml v1
Python SDK azureml v1
この記事では、再現性のために Azure Machine Learning データセットをバージョン管理する方法について説明します。 データセットのバージョン管理ではデータの特定の状態がブックマークされるので、将来の実験にデータセットの特定のバージョンを適用できます。
次の典型的なシナリオでは、Azure Machine Learning リソースをバージョン管理することをお勧めします。
- 再トレーニングのために新しいデータを使用できるようになったとき
- 異なるデータ準備または特徴エンジニアリングのアプローチを適用するとき
前提条件
Azure Machine Learning SDK for Python。 この SDK には、azureml-datasets パッケージが含まれています
Azure Machine Learning ワークスペース。 新しいワークスペースを作成するか、次のコード サンプルを使って既存のワークスペースを取得します。
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
データセットのバージョンを登録および取得する
登録したデータセットをバージョン管理し、複数の実験にわたって再利用し、同僚と共有することができます。 複数のデータセットを同じ名前で登録し、名前とバージョン番号によって特定のバージョンを取得することができます。
データセットのバージョンを登録する
次のコード サンプルでは、titanic_ds データセットの create_new_version パラメーターを True に設定して、このデータセットの新しいバージョンを登録しています。 ワークスペースに既存の titanic_ds データセットが登録されていない場合、このコードを実行すると titanic_ds という名前の新しいデータセットが作成され、そのバージョンは 1 に設定されます。
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
名前でデータセットを取得する
既定では、Dataset クラスの get_by_name() メソッドは、ワークスペースに登録されているデータセットの最新バージョンを返します。
次のコードは、titanic_ds データセットのバージョン 1 を返します。
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
バージョン管理のベスト プラクティス
データセットのバージョンを作成しても、ワークスペースにデータの追加のコピーが作成されるわけでは "ありません"。 データセットはストレージ サービス内のデータへの参照なので、信頼できる唯一の情報源は 1 つであり、それはストレージ サービスによって管理されます。
重要
データセットが参照するデータが上書きまたは削除された場合、そのデータセットの特定バージョンを呼び出しても、変更が元に戻ることは "ありません"。
データセットからデータを読み込むときは常に、データセットによって参照された現在のデータ コンテンツが読み込まれます。 データセットの各バージョンの再現可能性を確保したい場合は、データセットのバージョンが参照しているデータの内容を変更しないようにすることをお勧めします。 新しいデータが追加されたら、新しいデータ ファイルを別個のデータ フォルダーに保存してから、新しいデータセット バージョンを作成し、その新しいフォルダーのデータを含めます。
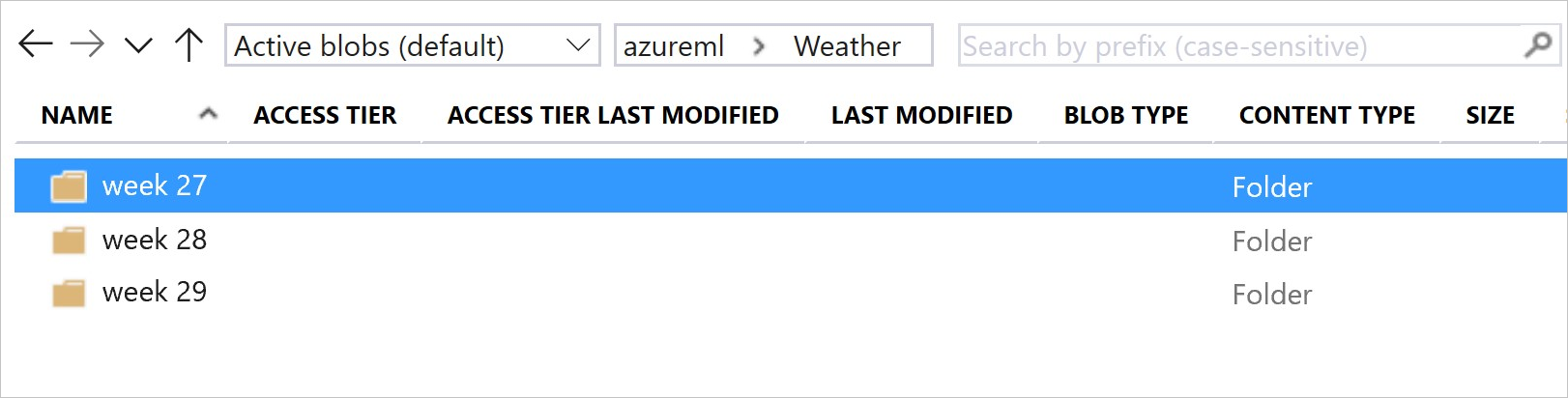
次の画像とサンプル コードは、データ フォルダーを構成し、それらのフォルダーを参照するデータセット バージョンを作成する、お勧めの方法を示しています。
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
ML パイプライン出力データセットをバージョン管理する
データセットは、ML の各パイプライン ステップの入力および出力として使用できます。 パイプラインを再実行すると、各パイプライン ステップの出力は新しいデータセット バージョンとして登録されます。
Machine Learning パイプラインを再実行するたびに、パイプラインによって各ステップの出力が新しいフォルダーに格納されます。 その後、バージョン管理される出力データセットは再現可能になります。 詳しくは、パイプラインのデータセットに関する記事を参照してください。
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
実験のデータを追跡する
Azure Machine Learning を使用すると、入力と出力のデータセットとして実験全体のデータが追跡されます。 次のシナリオでは、データが入力データセットとして追跡されます。
実験ジョブを送信するときに、
ScriptRunConfigオブジェクトのinputsまたはargumentsのいずれかのパラメーターを使用して、DatasetConsumptionConfigオブジェクトとしてスクリプトが特定のメソッド (たとえば
get_by_name()やget_by_id()) を呼び出すとき。 データセットをワークスペースに登録したときにそのデータセットに割り当てた名前が、表示名となります
次のシナリオでは、データが出力データセットとして追跡されます。
実験ジョブを送信するときに、
outputsまたはargumentsのいずれかのパラメーターを使用してOutputFileDatasetConfigオブジェクトを渡す場合。OutputFileDatasetConfigオブジェクトによってパイプライン ステップ間でデータを保持することもできます。 詳しくは、ML パイプライン ステップ間でのデータの移動に関する記事を参照してくださいスクリプトにデータセットを登録する。 データセットをワークスペースに登録したときに割り当てた名前が、表示名となります。 次のコード サンプルでは、
training_dsが表示名となります。training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )スクリプトで、登録されていないデータセットを使用して、子ジョブを送信する場合。 送信すると、匿名で保存されたデータセットが生成されます
実験ジョブでのデータセットのトレース
Machine Learning の実験ごとに、実験の Job オブジェクトの入力データセットを追跡できます。 次のコード サンプルでは、get_details() メソッドを使って、実験の実行で使用された入力データセットを追跡しています。
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
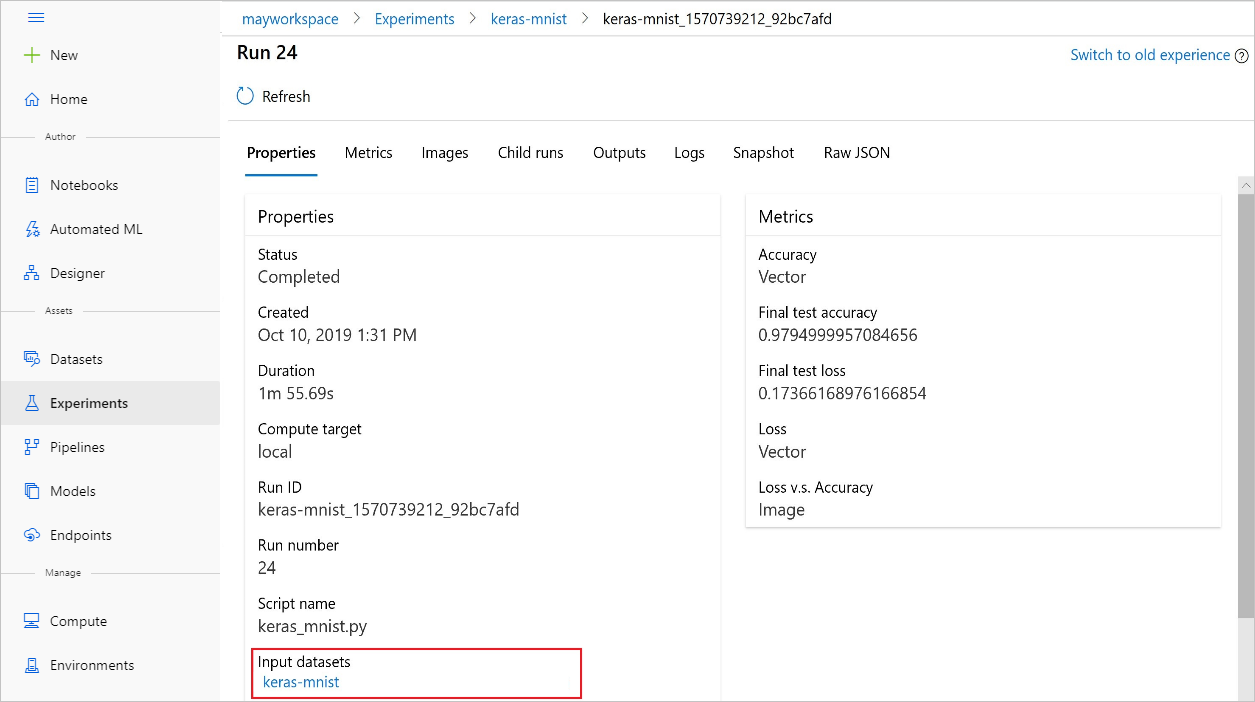
また、Azure Machine Learning スタジオを使用して、実験から input_datasets を見つけることもできます。
次のスクリーンショットは、Azure Machine Learning スタジオで実験の入力データセットを確認できる場所を示しています。 この例では、[実験] ペインから始めて、実験の特定の実行 (keras-mnist) について [プロパティ] タブを開きます。
次のコードにより、モデルがデータセットに登録されます。
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
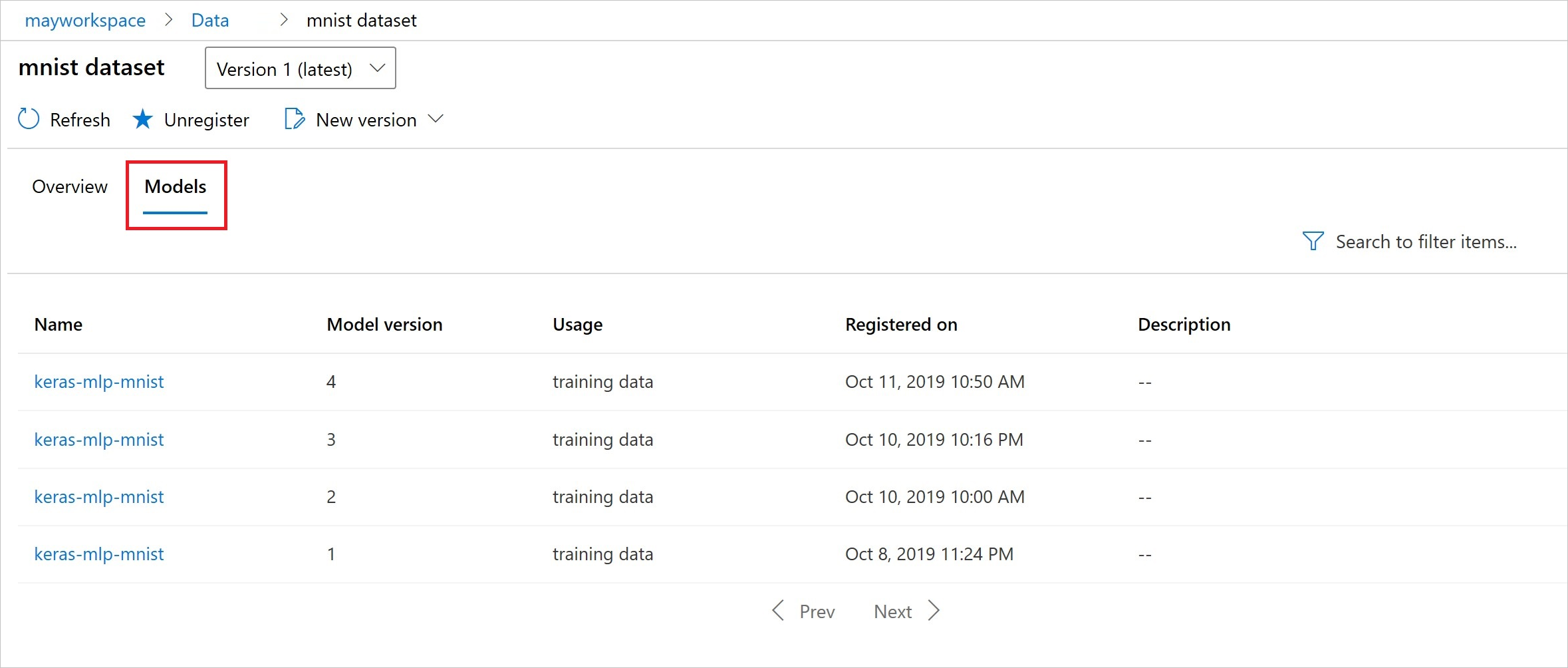
登録後は、Python またはスタジオを使用して、データセットに登録されたモデルのリストを表示できます。
次のスクリーンショットは、[資産] の下の [データセット] ペインからのものです。 データセットを選択して、[モデル] タブを選択し、そのデータセットに登録されたモデルのリストを表示します。