この記事では、Azure Machine Learning スタジオにおけるプロンプト フローの使用の主要なユーザー体験について説明します。 Azure Machine Learning ワークスペースでプロンプト フローを有効にし、プロンプト フローを作成して開発し、フローをテストして評価し、運用環境にデプロイする方法について説明します。
前提条件
- Azure Machine Learning ワークスペース。 ワークスペースの既定のストレージは BLOB の種類である必要があります。
- Azure OpenAI アカウント、またはデプロイメントが設定された既存の Azure OpenAI 接続。 詳細については、「 Azure OpenAI を使用してリソースを作成し、モデルをデプロイする」を参照してください。
注
仮想ネットワークを使用してプロンプト フローをセキュリティで保護する場合は、 ワークスペースで管理されている仮想ネットワークを使用してプロンプト フローをセキュリティで保護する手順にも従います。
接続を設定する
接続を使用すると、大きな言語モデル (LLM) やその他の外部ツール (Azure Content Safety など) との対話に必要な秘密鍵やその他の機密性の高い資格情報を安全に格納および管理できます。 接続リソースは、ワークスペース内のすべてのメンバーと共有されます。
Azure OpenAI 接続が既にあるかどうかを確認するには、Azure Machine Learning Studio の左側のメニューから [プロンプト フロー] を選択し、プロンプト フロー画面の [接続] タブを選択します。
![[作成] が強調表示された [接続] タブのスクリーンショット。](media/get-started-prompt-flow/connection-creation-entry-point.png?view=azureml-api-2)
プロバイダーが AzureOpenAI である接続が既に表示されている場合は、このセットアップ プロセスの残りの部分をスキップできます。 この接続には、例のフローで LLM ノードを実行できるようにするためのデプロイが必要です。 詳細については、「 モデルのデプロイ」を参照してください。
Azure OpenAI 接続がない場合は、[ 作成 ] を選択し、ドロップダウン メニューから AzureOpenAI を選択します。
[ Azure OpenAI 接続の追加 ] ウィンドウで、接続の名前を指定し、 サブスクリプション ID と Azure OpenAI アカウント名を選択し、 認証モード と API 情報を指定します。
プロンプト フローでは、Azure OpenAI リソースの API キー または Microsoft Entra ID 認証がサポートされます。 このチュートリアルでは、認証モードで API キーを選択します。
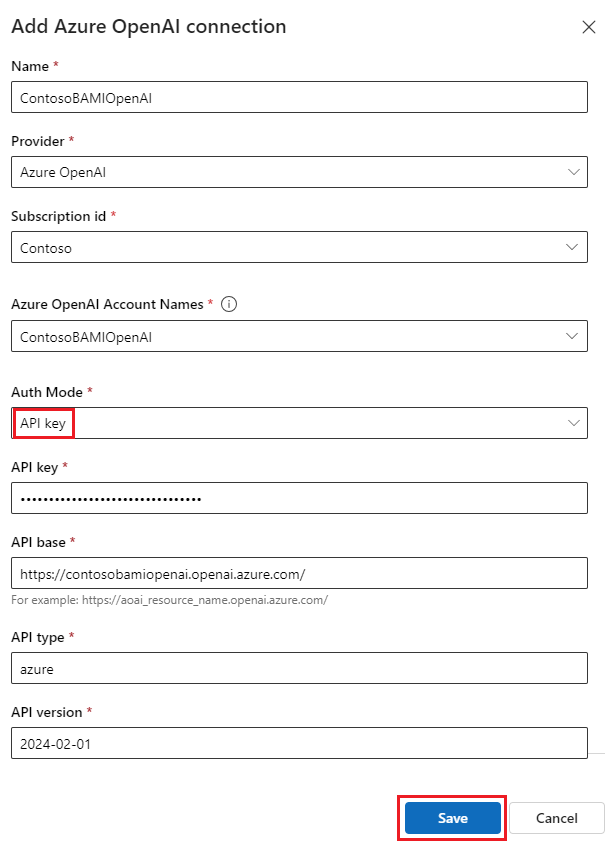
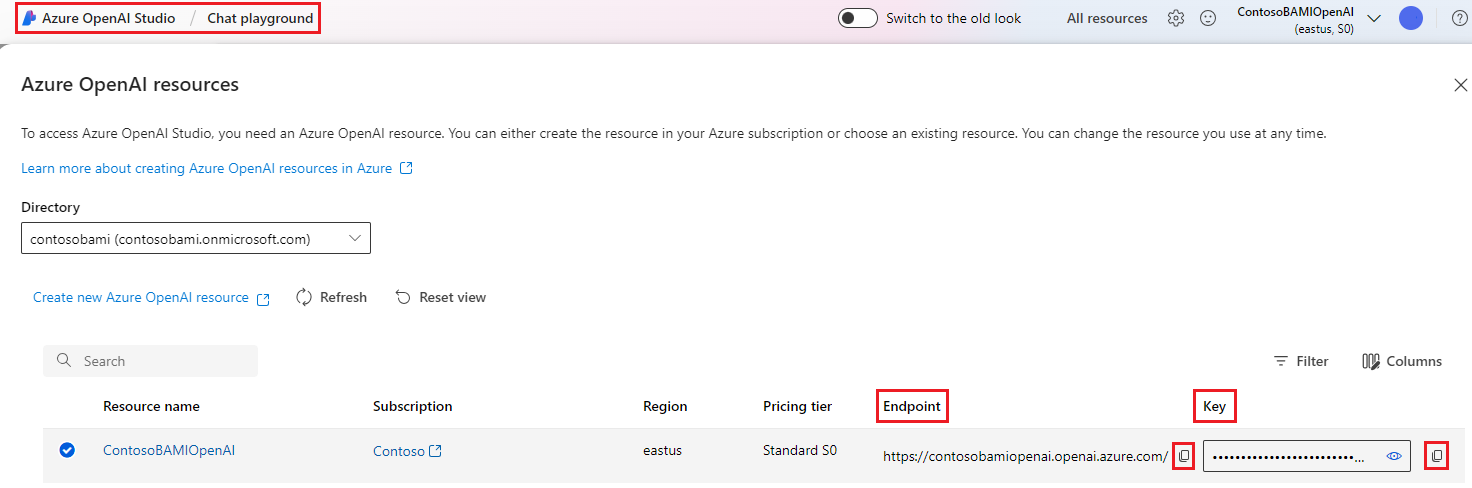
API 情報を取得するには、Azure OpenAI ポータルの チャット プレイグラウンド に移動し、Azure OpenAI リソース名を選択します。 キーをコピーし、[Azure OpenAI 接続の追加] フォームの API キー フィールドに貼り付け、エンドポイントをコピーして、フォームの API ベース フィールドに貼り付けます。
Microsoft Entra ID 認証の詳細については、「Microsoft Entra ID 認証を使用して Azure AI Foundry Models で Azure OpenAI を構成する方法」を参照してください。
すべてのフィールドに入力したら、[ 保存] を選択して接続を作成します。
例のフローで LLM ノードを実行するには、接続をデプロイに関連付ける必要があります。 デプロイを作成するには、「 モデルのデプロイ」を参照してください。
![[作成] が強調表示された [接続] タブのスクリーンショット。](media/get-started-prompt-flow/connection-creation-entry-point.png?view=azureml-api-2#lightbox)


プロンプト フローを作成して開発する
プロンプト フロー ホーム ページの [フロー] タブで、[作成] を選択してプロンプト フローを作成します。 [ 新しいフローの作成] ページには、作成できるフローの種類、フローを作成するために複製できる組み込みのサンプル、フローをインポートする方法が表示されます。
サンプルから複製する
Explore ギャラリーでは、組み込みのサンプルを参照し、任意のタイルの詳細を表示を選択して、シナリオに適しているかどうかをプレビューできます。
このチュートリアルでは、 Web 分類 のサンプルを使用して、主要なユーザー体験について説明します。 Web 分類は、LLM を使用した多クラス分類を示すフローです。 URL を指定すると、フローによって URL が Web カテゴリに分類され、わずか数ショット、簡単な要約、分類のプロンプトが表示されます。 たとえば、URL https://www.imdb.comを指定すると、URL が Movieに分類されます。
サンプルを複製するには、[Web 分類] タイルで [複製] を選択します。
![Web 分類が強調表示されている [ギャラリーから作成] のスクリーンショット。](media/get-started-prompt-flow/sample-in-gallery.png?view=azureml-api-2#lightbox)
クローンフロー ペインには、ワークスペースのファイル共有ストレージ内にフローを保存する場所が表示されます。 必要に応じて、フォルダーをカスタマイズできます。 次に [クローン] を選択します。
複製されたフローが作成 UI で開きます。 [鉛筆の 編集] アイコンを選択すると、名前、説明、タグなどのフローの詳細を編集できます。
コンピューティング セッションを開始する
フローの実行にはコンピューティング セッションが必要です。 コンピューティング セッションは、必要なすべての依存関係パッケージを含む Docker イメージを含め、アプリケーションの実行に必要なコンピューティング リソースを管理します。
フロー作成ページで、[コンピューティング セッションの開始] を選択して コンピューティング セッションを開始します。

フロー作成ページを調べる
コンピューティング セッションの開始には数分かかる場合があります。 コンピューティング セッションの開始時に、フロー作成ページの各部分を表示します。
ページの左側にある [フロー ] ビューまたは [フラット化 ] ビューは、ノードの追加または削除、ノードのインラインでの編集と実行、またはプロンプトの編集によってフローを作成できるメイン作業領域です。 [ 入力 と 出力] セクションでは、入力と出力を表示、追加、削除、編集できます。
現在の Web 分類サンプルを複製したとき、入力と出力は既に設定されています。 フローの入力スキーマは、文字列型の URL
name: url; type: stringです。 プリセットの入力値を手動でhttps://www.imdb.comなどの別の値に変更できます。右上のファイルには、フローのフォルダーとファイル構造が表示されます。 各フロー フォルダーには、 flow.dag.yaml ファイル、ソース コード ファイル、およびシステム フォルダーが含まれています。 テスト、デプロイ、またはコラボレーション用のファイルを作成、アップロード、またはダウンロードできます。
右下の グラフ ビューは、フローがどのように見えるかを視覚化するためのものです。 拡大または縮小したり、自動レイアウトを使用したりできます。
[フロー] ビューまたはフラット化ビューでファイルをインラインで編集することも、[Raw ファイル モード] トグルをオンにしてファイルからファイルを選択して、ファイルをタブで開いて編集することもできます。
![生ファイル モードの [ファイルの編集] タブのスクリーンショット。](media/get-started-prompt-flow/file-edit-tab.png?view=azureml-api-2#lightbox)
このサンプルでは、入力は分類する URL です。 このフローでは、Python スクリプトを使用して URL からテキスト コンテンツをフェッチし、LLM を使用してテキスト コンテンツを 100 単語で要約し、URL と要約されたテキスト コンテンツに基づいて分類します。 次に、Python スクリプトによって LLM 出力がディクショナリに変換されます。 prepare_examples ノードは、分類ノードのプロンプトにいくつかのショット例をフィードします。
LLM ノードを設定する
LLM ノードごとに、 接続 を選択して LLM API キーを設定する必要があります。 Azure OpenAI 接続を選択します。
接続の種類に応じて、ドロップダウン リストから deployment_name またはモデルを選択する必要があります。 Azure OpenAI 接続の場合は、デプロイを選択します。 デプロイがない場合は、「モデルのデプロイ」の手順に従って、Azure OpenAI ポータルで デプロイを作成します。
注
Azure OpenAI 接続ではなく OpenAI 接続を使用する場合は、[ 接続 ] フィールドでデプロイではなくモデルを選択する必要があります。
この例では、指定されたプロンプトの例が チャット API 用であるため、API の種類がチャットであることを確認します。 チャット API と完了 API の違いの詳細については、「フローの開発」 を参照してください。

フロー内のsummarize_text_contentとclassify_with_llmという両方のLLMノードの接続を設定します。
1 つのノードを実行する
1 つのノードをテストしてデバッグするには、[フロー] ビューのノードの上部にある [実行] アイコンを選択します。 [入力] を展開し、フロー入力 URL を変更して、さまざまな URL のノードの動作をテストできます。
実行状態がノードの上部に表示されます。 実行が完了すると、ノード出力セクションに実行 出力 が表示されます。

グラフ ビューには、単一実行ノードの状態も表示されます。
fetch_text_content_from_url実行し、summarize_text_contentを実行して、フローが Web からコンテンツを正常にフェッチできるかどうかを確認し、Web コンテンツを要約します。
フロー全体を実行する
フロー全体をテストしてデバッグするには、画面の上部にある [ 実行 ] を選択します。 フロー入力 URL を変更して、さまざまな URL に対するフローの動作をテストできます。
![全体実行が表示され [実行] ボタン強調表示されている Web 分類のスクリーンショット。](media/get-started-prompt-flow/run-flow.png?view=azureml-api-2#lightbox)
各ノードの実行状態と出力を確認します。
フロー出力の表示
フロー出力を設定して、複数のノードの出力を 1 か所で確認することもできます。 フロー出力は、次の場合に役立ちます。
- 1 つのテーブルで一括テスト結果を確認します。
- 評価インターフェイス マッピングを定義します。
- デプロイ応答スキーマを設定します。
複製されたサンプルでは、 カテゴリ と 証拠 フローの出力が既に設定されています。
上部バナーまたは上部メニュー バーの [出力の表示 ] を選択して、詳細な入力、出力、フロー実行、オーケストレーション情報を表示します。
![2 つの場所にある [出力の表示] ボタンのスクリーンショット。](media/get-started-prompt-flow/authoring-view-trace.png?view=azureml-api-2)
[出力] 画面の [出力] タブで、フローによってカテゴリと証拠を含む入力 URL が予測されることに注意してください。
![[出力] ページでの出力の表示のスクリーンショット。](media/get-started-prompt-flow/outputs-overview.png?view=azureml-api-2)
[出力] 画面で [トレース] タブを選択し、ノード名の下のフローを選択して、右側のウィンドウに詳細なフローの概要情報を表示します。 フローを展開し、任意のステップを選択すると、そのステップの詳細情報が表示されます。
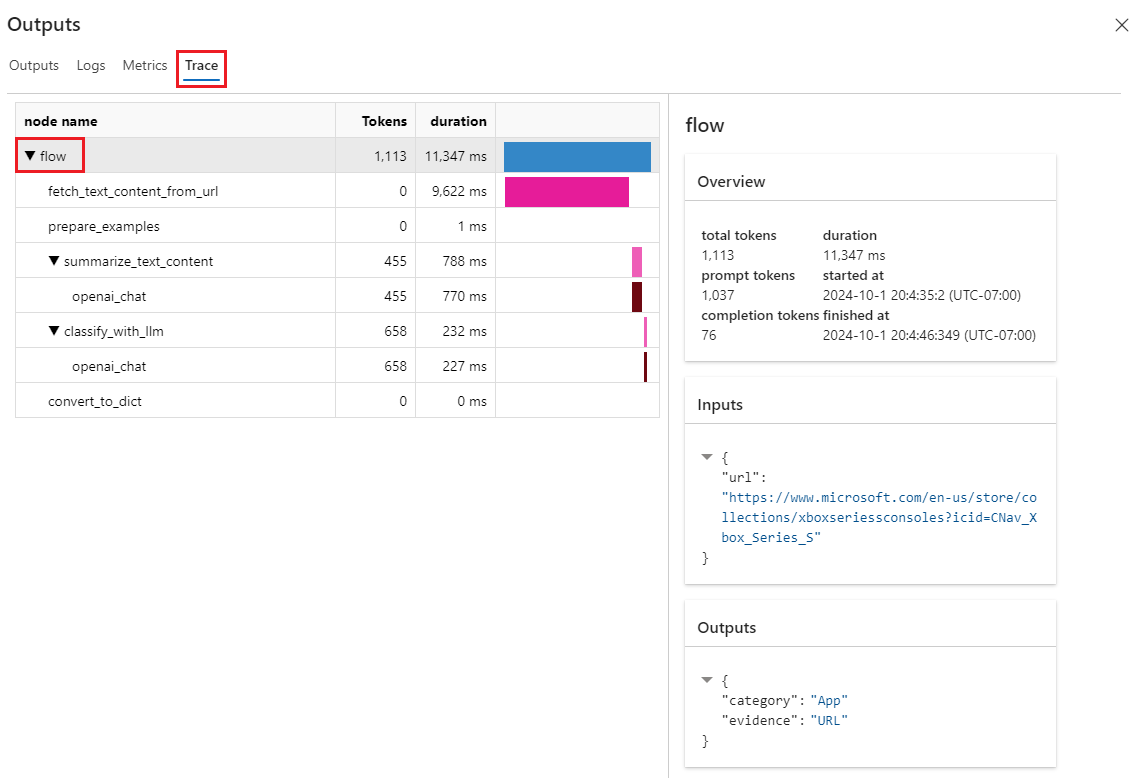
![2 つの場所にある [出力の表示] ボタンのスクリーンショット。](media/get-started-prompt-flow/authoring-view-trace.png?view=azureml-api-2#lightbox)
![[出力] ページでの出力の表示のスクリーンショット。](media/get-started-prompt-flow/outputs-overview.png?view=azureml-api-2#lightbox)

テストと評価
1 行のデータでフローが正常に実行されたら、大量のデータ セットで正常に実行されるかどうかをテストします。 一括テストを実行し、必要に応じて評価フローを追加し、結果を確認できます。
まずはテスト データを準備する必要があります。 Azure Machine Learning では、データの CSV、TSV、JSONL ファイル形式がサポートされています。
- GitHub に移動し、Web 分類サンプルのゴールデン データセット であるdata.csvをダウンロードします。
バッチ実行および評価ウィザードを使用して、バッチ実行と必要に応じて評価メソッドを構成して送信します。 評価方法もフローであり、Python または LLM を使用して精度や関連性スコアなどのメトリックを計算します。
フロー作成ページの上部メニューから [ 評価 ] を選択します。
[ 基本設定 ] 画面で、必要に応じて [実行] 表示名 を変更し、オプションの [実行の説明 ] と [タグ] を追加して、[ 次へ] を選択します。
バッチ実行設定画面で、[新しいデータの追加] を選択します。 [ データの追加 ] 画面で、データセットの 名前 を指定し、[ 参照 ] を選択してダウンロードした data.csv ファイルをアップロードし、[ 追加] を選択します。
データをアップロードした後、またはワークスペースに使用する別のデータセットがある場合は、ドロップダウン リストからデータセットを検索して選択し、最初の 5 行をプレビューします。
入力マッピング機能では、列名が一致しない場合でも、フロー入力をデータセット内の任意のデータ列にマッピングできます。
![[新しいデータのアップロード] が強調表示されている [バッチ実行と評価] のスクリーンショット。](media/get-started-prompt-flow/upload-new-data-batch-run.png?view=azureml-api-2)
必要に応じて、1 つまたは複数の評価方法を選択するには、[ 次へ] を選択します。 [評価の選択] ページには、組み込みのカスタマイズされた評価フローが表示されます。 組み込みの評価方法に対してメトリックがどのように定義されているかを確認するには、メソッドのタイルの 詳細 を選択します。
Web 分類は分類シナリオであるため、評価に使用する 分類精度評価 を選択し、[ 次へ] を選択します。
![評価メソッドに [バッチ実行と評価] が表示されている Web 分類のスクリーンショット。](media/get-started-prompt-flow/accuracy.png?view=azureml-api-2)
[評価の構成] 画面で、[評価入力のマッピング] を設定して、groundtruth をフロー入力 ${data.category} にマップし、prediction をフロー出力 ${run.outputs.category} にマップします。
![評価設定に [バッチ実行と評価] が表示されている Web 分類のスクリーンショット。](media/get-started-prompt-flow/accuracy-configure.png?view=azureml-api-2)
[ 確認と送信] を選択し、[ 送信] を選択してバッチ実行と選択した評価方法を送信します。
![[新しいデータのアップロード] が強調表示されている [バッチ実行と評価] のスクリーンショット。](media/get-started-prompt-flow/upload-new-data-batch-run.png?view=azureml-api-2#lightbox)
![評価メソッドに [バッチ実行と評価] が表示されている Web 分類のスクリーンショット。](media/get-started-prompt-flow/accuracy.png?view=azureml-api-2#lightbox)
![評価設定に [バッチ実行と評価] が表示されている Web 分類のスクリーンショット。](media/get-started-prompt-flow/accuracy-configure.png?view=azureml-api-2#lightbox)
結果をチェックする
実行が正常に送信されたら、[ 実行リストの表示 ] を選択して、プロンプト フローの [実行 ] ページで実行状態を表示します。 バッチ実行が完了するまでに時間がかかる場合があります。 [最新の情報に更新] を選択して、最新の状態を読み込むことができます。
バッチ実行が完了したら、実行の横にあるチェック を選択し、[出力の 視覚化 ] を選択してバッチ実行の結果を表示します。
![[実行] ページで [出力の視覚化] を選択したスクリーンショット。](media/get-started-prompt-flow/views.png?view=azureml-api-2#lightbox)
[ 出力の視覚化 ] 画面で、子実行の横にある目のアイコンを有効にして、バッチ実行結果のテーブルに評価結果を追加します。 トークンの合計数と全体的な精度を確認できます。 出力テーブルには、入力、フロー出力、システム メトリック、および Correct または Incorrect の評価結果など、データの各行の結果が表示されます。

出力テーブルでは、次のことができます。
- 列の幅の調整、列の非表示または再表示、列の順序の変更を行います。
- [ エクスポート] を選択して 現在のページ を CSV ファイルとしてダウンロードするか、Jupyter Notebook ファイルとして データ エクスポート スクリプト をダウンロードして出力をローカルにダウンロードできます。
- 任意の行の横にある [詳細の表示 ] アイコンを選択して、その行の完全な詳細を示す トレース ビュー を開きます。
分類タスクを評価できるメトリックは、精度だけではありません。 たとえば、リコールを使用して評価することもできます。 他の評価を実行するには、[実行] ページの [出力の視覚化] の横にある [評価] を選択し、他の評価方法を選択します。
エンドポイントとしてデプロイする
フローをビルドしてテストした後、それをエンドポイントとしてデプロイして、リアルタイム推論のためにエンドポイントを呼び出すことができます。
エンドポイントを構成する
[バッチ 実行 ] ページで、実行名のリンクを選択し、実行の詳細ページで、上部のメニュー バーの [ 配置 ] を選択して展開ウィザードを開きます。
[ 基本設定 ] ページで、 エンドポイント名 と デプロイ名 を指定し、 仮想マシン の種類と インスタンス数を選択します。
[次へ] を選択して、エンドポイント、デプロイ、および出力と接続の詳細設定を構成できます。 この例では、既定の設定を使用します。
[ 確認と作成 ] を選択し、[ 作成 ] を選択してデプロイを開始します。
エンドポイントをテストする
通知からエンドポイントの詳細ページに移動するか、スタジオの左側のナビゲーションで [エンドポイント ] を選択し、[ リアルタイム エンドポイント ] タブからエンドポイントを選択します。エンドポイントのデプロイには数分かかります。 エンドポイントが正常にデプロイされたら、[テスト] タブでテストできます。
テストする URL を入力ボックスに入力し、[ テスト] を選択します。 エンドポイントによって予測された結果が表示されます。
リソースをクリーンアップする
コンピューティング リソースとコストを節約するために、コンピューティング セッションを今のところ使用し終わったら停止できます。 実行中のセッションを選択し、[ コンピューティング セッションの停止] を選択します。
スタジオの左側のナビゲーションから [コンピューティング ] を選択し、コンピューティング インスタンスの一覧でコンピューティング インスタンスを選択し、[停止] を選択して、 コンピューティング インスタンス を 停止することもできます。
このチュートリアルで作成したリソースを使用する予定がない場合は、課金されないように削除できます。 Azure portal で、「リソース グループ」を検索して選択します。 一覧から、作成したリソースを含むリソース グループを選択し、 リソース グループ ページの上部メニューから [リソース グループの削除] を選択します。