評価フローとメトリックをカスタマイズする
評価フローは特別な種類のフローであり、メトリックを計算することによって、実行の出力が特定の条件および目標とどの程度よく一致しているかを評価します。
プロンプト フローでは、タスクと目標に合わせて独自の評価フローとメトリックをカスタマイズまたは作成した後、それを使って他のフローを評価できます。 このドキュメントでは、次のことを説明します。
- プロンプト フローでの評価について理解する
- 入力
- 出力とメトリックのログ
- 評価フローを開発する方法
- カスタマイズされた評価フローをバッチ実行で使用する方法
プロンプト フローでの評価について理解する
プロンプト フローでは、フローは入力を処理して出力を生成するノードのシーケンスです。 同様に、評価フローは、必要な入力を受け取って、対応する出力 (多くの場合はスコアまたはメトリック) を生成できます。 評価フローの概念は標準フローと似ていますが、作成エクスペリエンスと使用方法に関していくつか違う点があります。
評価フローの特別な機能は次のとおりです。
- 通常、テスト対象の実行の後に、その出力を受け取って実行されます。 出力を使って、スコアとメトリックを計算します。 評価フローの出力は、テスト対象のフローのパフォーマンスの測定結果です。
- テスト対象のフローの、テスト データセットに対する全体的なパフォーマンスを計算する集計ノードが存在する場合があります。
log_metric()関数を使ってメトリックをログできます。
評価方法の開発で入力と出力を定義する方法について説明します。
入力
評価フローは、データセットに基づいてフロー バッチ実行のメトリックまたはスコアを計算します。 そのためには、テスト対象の実行の出力を受け取る必要があります。 評価フローの入力は、標準フローの入力を定義するのと同じ方法で定義できます。
評価フローは、別の実行の後に実行され、その実行の出力が特定の条件や目標とどの程度よく一致しているかを評価します。 したがって、評価はその実行から生成された出力を受け取ります。
たとえば、テスト対象のフローが質問に基づいて回答を生成する QnA フローである場合は、評価の入力にそれに応じた answer のような名前を付けることができます。 テスト対象のフローが、テキストをカテゴリに分類する分類フローである場合は、評価の入力に category のような名前を付けることができます。
ground truth などの他の入力が必要になる場合もあります。 たとえば、分類フローの正確性を計算する場合は、実測値としてデータセットで category 列を提供する必要があります。 QnA フローの正確性を計算する場合は、実測値としてデータセットで answer 列を提供する必要があります。
既定では、評価にはテスト実行に提供されたテスト データセットと同じデータセットが使用されます。 ただし、対応するラベルまたはターゲットのグラウンド トゥルース値が別のデータセット内にある場合は、そのデータセットに簡単に切り替えることができます。
QnA または RAG のシナリオでの question や context のように、メトリックを計算するために他の入力が必要になる場合があります。 これらの入力は、標準フローの入力を定義するのと同じ方法で定義できます。
入力の説明
メトリックの計算に必要な入力がわかるよう、必要な入力ごとに説明を追加できます。 この説明は、バッチ実行の送信でソースをマッピングするときに表示されます。

各入力の説明を追加するには、評価方法を開発するときに、入力セクションで [説明の表示] を選びます。 また、[説明を非表示にします] を選ぶと説明が表示されないようにできます。

この場合、この説明はバッチ実行の送信でこの評価方法を使用すると表示されます。
出力とメトリック
評価の出力は、テスト対象のフローのパフォーマンスの測定結果です。 出力には、通常、スコアなどのメトリックが含まれており、推論や提案のテキストが含まれることもあります。
評価の出力 - インスタンス レベルのスコア
プロンプト フローのフローでは、一度に 1 つのデータ行が処理されて、出力レコードが生成されます。 同様に、ほとんどの評価ケースでは、出力ごとにスコアがあり、データごとにフローのパフォーマンスをチェックできます。
評価フローでは各データのスコアを計算でき、評価フローの出力セクションで設定すると、各データ サンプルのスコアをフロー出力として記録できます。 この作成エクスペリエンスは、標準的なフローの出力の定義と同じです。

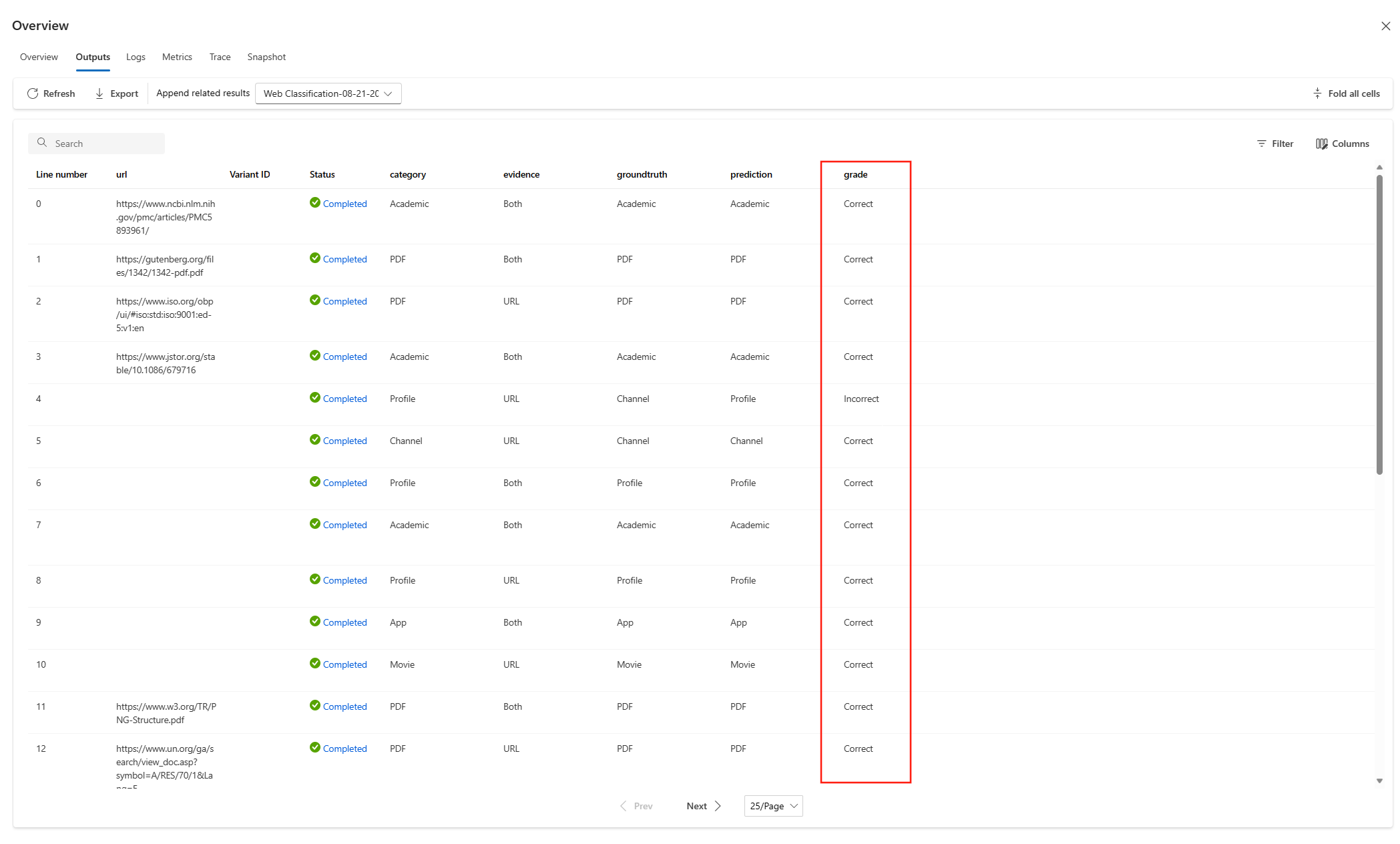
この評価方法を使って別のフローを評価したときは、[概要] > [出力] タブでスコアを見ることができます。 このプロセスは、標準フローのバッチ実行出力のチェックと同じです。 インスタンス レベルのスコアは、テスト対象フローの出力に追加されます。
メトリックのログと集計ノード
さらに、実行の全体的な評価を提供することも重要です。 各単一出力を評価した個々のスコアと区別するため、実行の全体的なパフォーマンスを評価するための値を "メトリック" と呼びます。
すべての個別スコアに基づいて全体的な評価値を計算するには、評価フローで Python ノードの [集計] をオンにして "リデュース" ノードに変換し、そのノードで入力をリストとして取り込んでバッチ処理できます。

このようにして、各フロー出力のすべてのスコアを計算して処理し、各スコア出力の全体的な結果を計算できます。 たとえば、分類フローの正確性を計算する場合は、各スコア出力の正確性を計算してから、すべてのスコア出力の平均の正確性を計算できます。 次に、promptflow_sdk.log_metrics() を使って、平均の正確性をメトリックとしてログできます。 メトリックは数値 (float/int) である必要があります。 文字列型メトリックのログはサポートされていません。
次のコード スニペットは、各データの正確性スコア (grade) を平均して全体的な正確性を計算する例です。 全体的な正確性は、promptflow_sdk.log_metrics() を使ってメトリックとしてログされます。
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
この関数は Python ノードで呼び出したので、他の場所に割り当てる必要はありません。後でメトリックを見ることができます。 この評価方法をバッチ実行で使うと、全体的なパフォーマンスを示すメトリックを [概要] > [メトリック] タブで見ることができます。

評価方法の開発を始める
独自の評価方法を開発するには、次の 2 つの方法があります。
- 新しい評価フローを最初から作成する: 新しい評価方法を一から開発します。 プロンプト フロー タブのホーム ページの [種類別に作成] セクションで、[評価フロー] を選んで評価フローのテンプレートを表示できます。

- 組み込みの評価フローをカスタマイズする: 組み込みの評価フローを変更します。 フロー作成ウィザード - フロー ギャラリーから組み込みの評価フローを見つけ、[複製] を選択してカスタマイズを行います。 その後、組み込みの評価のロジックとフローを調べて、フローを変更できます。 この方法では、最初から作成するのではなく、サンプルを使ってカスタマイズできます。

各データのスコアを計算する
前に説明したように、評価を実行すると、データセットに対して実行されたフローに基づいて、スコアとメトリックが計算されます。 したがって、評価フローの最初のステップは、各個別出力のスコアを計算することです。
組み込みの評価フロー Classification Accuracy Evaluation を例にすると、対応する実測値に対してフローが生成する各出力の正確性を測定するスコア grade が、grade ノードで計算されます。 種類別に作成するときに、評価フローを作成して最初から編集する場合、このスコアはテンプレートの line_process ノードで計算されます。 line_process Python ノードを LLM ノードに置き換え、LLM を使ってスコアを計算することも、複数のノードを使って計算を実行することもできます。

次に、評価フローの出力としてノードの出力を指定する必要があります。これは、各データ サンプルに対して計算されたスコアが出力であることを示します。 また、追加情報として根拠を出力することもでき、これは標準フローで出力を定義する場合と同じエクスペリエンスです。
メトリックを計算してログする
評価の 2 番目のステップは、実行を評価するための全体的なメトリックを計算することです。 前に説明したように、メトリックは Aggregation として設定された Python ノードで計算されます。 このノードは、前のノードで計算されたスコアを受け取り、各データ サンプルのスコアをリストに整理してから、一度にまとめて計算します。
種類別に作成するときに最初から作成して編集する場合、このスコアは aggregate ノードで計算されます。 このコード スニペットは、集計ノードのテンプレートです。
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
スコアの平均値や標準偏差の計算など、独自の集計ロジックを使用できます。
次に、promptflow.logmetrics() 関数を使ってメトリックをログする必要があります。 1 つの評価フローで複数のメトリックをログできます。 メトリックは数値 (float/int) である必要があります。
カスタマイズされた評価フローを使用する
独自の評価フローとメトリックを作成した後は、このフローを使って、標準フローのパフォーマンスを評価できます。
まず、評価対象のフロー作成ページから始めます。 たとえば、大きなデータセットでのパフォーマンスがまだわからなくてテストする必要がある QnA フローなどです。 [
Evaluate] ボタンをクリックし、[Custom evaluation] を選びます。
次に、バッチ実行の送信とプロンプト フローでのフローの評価に関する記事で説明されているバッチ実行の送信手順と同様に、最初のいくつかのステップに従って、フローを実行するようにデータセットを準備します。
Evaluation settings - Select evaluationステップでは、組み込みの評価と共に、カスタマイズした評価も選択できます。 これにより、作成、複製、またはカスタマイズしたフロー リスト内のすべての評価フローの一覧が表示されます。 同じプロジェクトで他のユーザーが作成した評価フローは、このセクションには表示されません。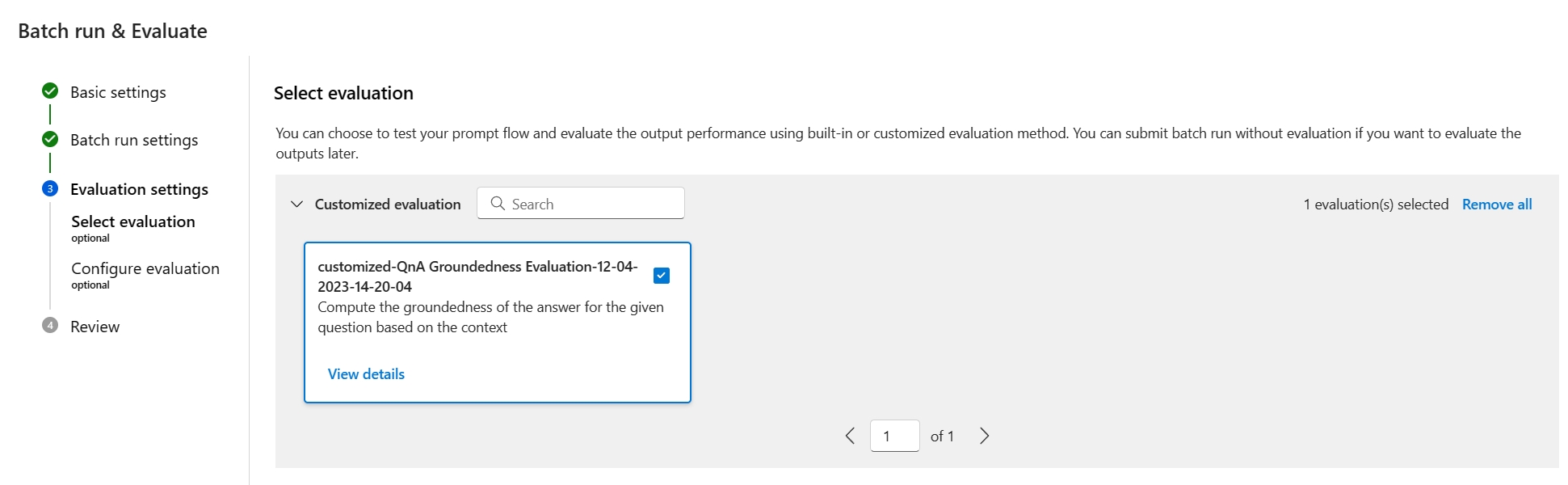
次に、
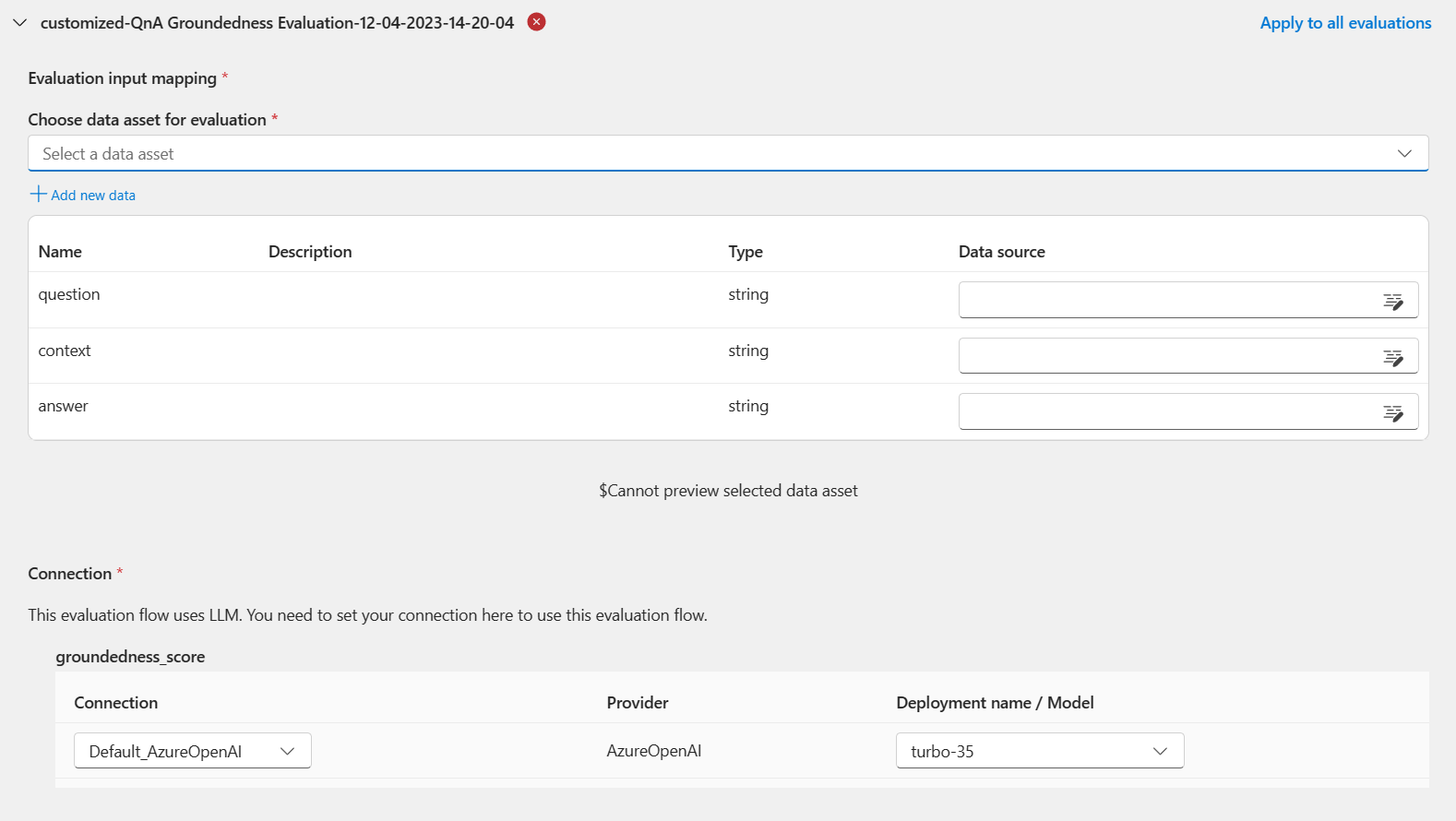
Evaluation settings - Configure evaluationステップで、評価方法に必要な入力データのソースを指定する必要があります。 たとえば、グラウンド トゥルース列はデータセットから取得できます。評価を実行するには、評価を送信するときに、"入力マッピング" セクションで、これらの必要な入力のソースを指定できます。 このプロセスは、バッチ実行の送信とプロンプト フローでのフローの評価に関する記事で説明されている構成と同じです。
- 実行の出力がデータ ソースの場合、ソースは
${run.output.[OutputName]}と示されます - テスト データセットがデータ ソースの場合、ソースは
${data.[ColumnName]}と示されます
Note
評価でデータセットのデータが必要ない場合は、入力マッピング セクションのデータセット列を参照する必要はありません。これは、データセットの選択がオプションの構成であることを示します。 データセットの選択は評価結果には影響しません。
- 実行の出力がデータ ソースの場合、ソースは
この評価方法を別のフローの評価に使うと、インスタンス レベルのスコアを [概要] ->[出力] タブで見ることができます。