バッチ実行を使用すると、大規模なデータセットでプロンプト フローを実行し、データ行ごとに出力を生成できます。 大規模なデータセットでプロンプト フローのパフォーマンスを評価するには、バッチ実行を送信し、評価方法を使用してパフォーマンス スコアとメトリックを生成します。
バッチ フローが完了すると、評価方法が自動的に実行され、スコアとメトリックが計算されます。 評価メトリックを使用して、パフォーマンスの基準および目標と照らし合わせてフローの出力を評価できます。
この記事では、バッチ実行を送信し、評価方法を使用してフロー出力の品質を測定する方法について説明します。 評価結果とメトリックを表示する方法と、異なる方法またはバリアントのサブセットを使って新しい評価ラウンドを開始する方法についても説明します。
前提条件
バッチ フローを評価方法と一緒に実行するには、次のコンポーネントが必要です。
パフォーマンスをテストする作業用の Azure Machine Learning プロンプト フロー。
バッチ実行に使用するテスト データセット。
テスト データセットは CSV、TSV、または JSONL 形式である必要があり、フローの入力名に一致するヘッダーが付けられている必要があります。 ただし、評価実行のセットアップ プロセス中に、さまざまなデータセット列を入力列にマップできます。
評価のバッチ実行を作成して送信する
バッチ実行を送信するには、フローをテストするデータセットを選択します。 評価方法を選んで、フロー出力のメトリックを計算することもできます。 評価方法を使わない場合は、この評価ステップをスキップして、メトリックを計算せずにバッチ実行を実行できます。 後で評価ラウンドを実行することもできます。
評価の有無にかかわらずバッチ実行を開始するには、プロンプト フロー ページの上部にある [評価] を選択します。
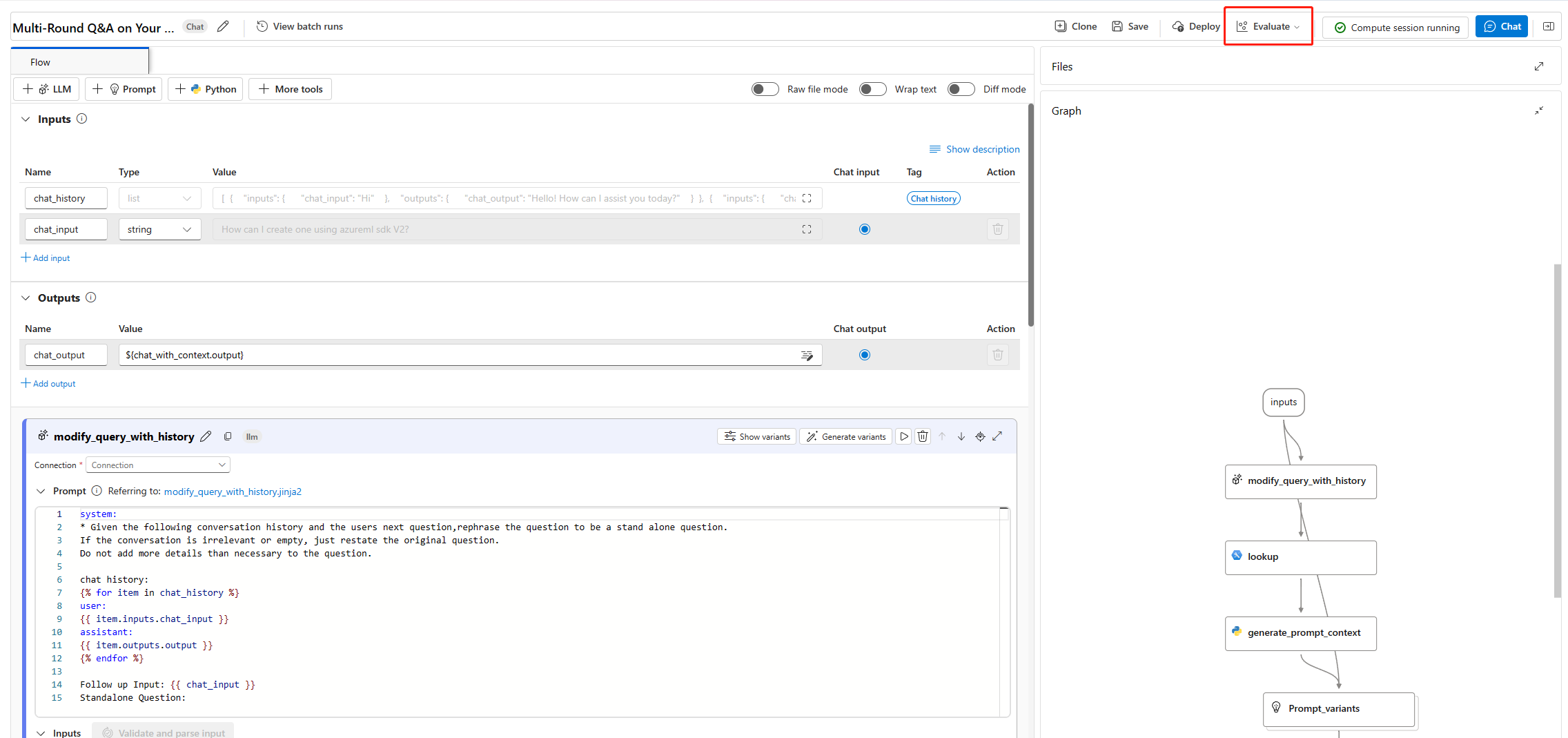
[Batch run & Evaluate]\(バッチ実行と評価\) ウィザードの [基本設定] ページで、必要に応じて [Run display name]\(実行の表示名\) をカスタマイズし、オプションで [Run description]\(実行の説明\) と [タグ] を指定します。 [次へ] を選択します。
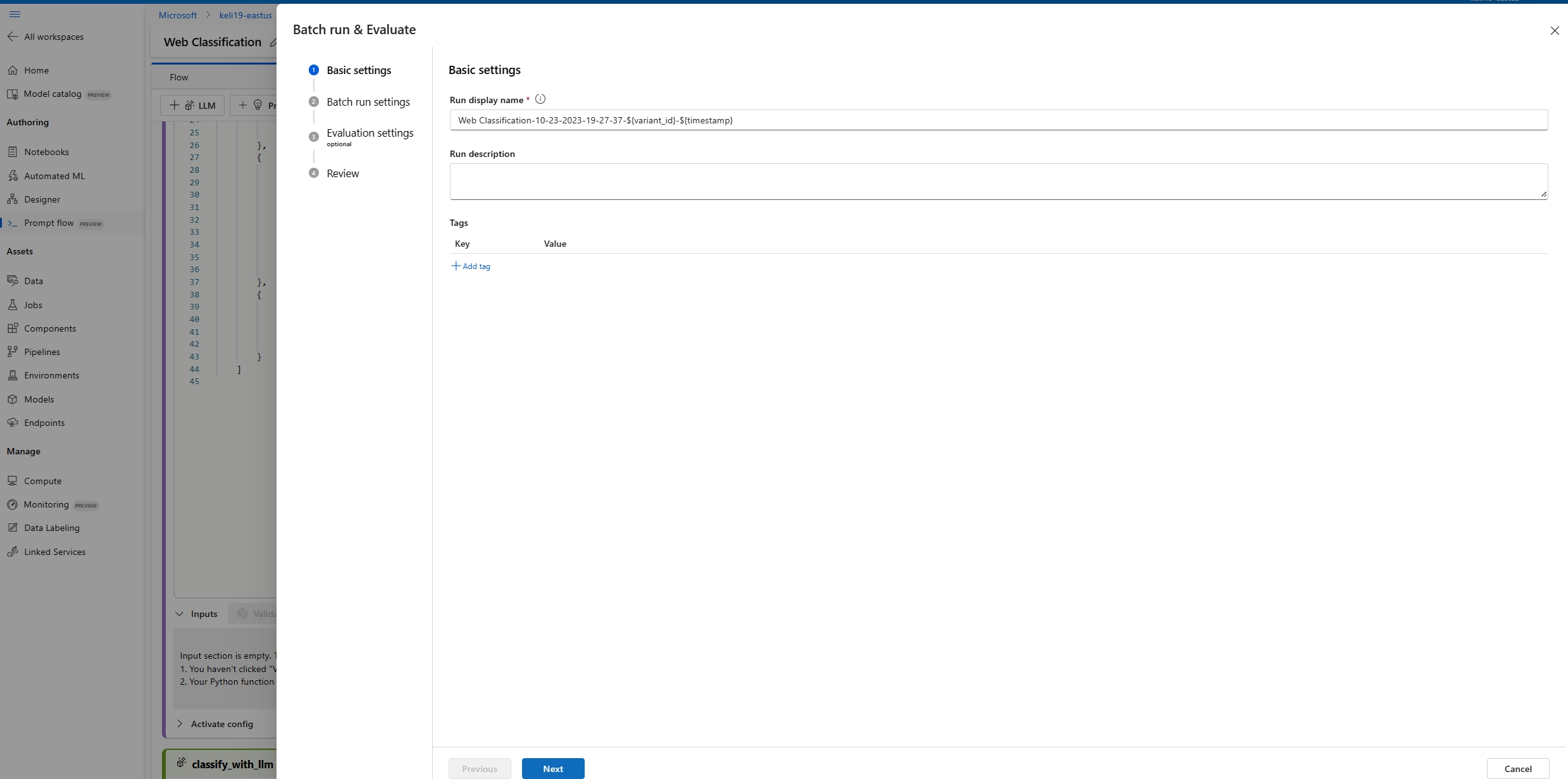
[Batch run settings]\(バッチ実行の設定\) ページで、使用するデータセットを選択し、入力マッピングを構成します。
プロンプト フローでは、フロー入力をデータセット内の特定のデータ列にマッピングすることがサポートされます。
${data.<column>}を使用して、データセット列を特定の入力に割り当てられます。 定数値を入力に割り当てる場合は、その値を直接入力できます。
この時点で [確認および送信] を選択すると、評価手順をスキップし、評価方法を使用せずにバッチ実行を実行できます。 バッチ実行では、データセット内の各項目に対して個別の出力が生成されます。 この出力は手動で確認するか、詳細に分析するためにエクスポートできます。
それ以外の場合、評価方法を使用してこの実行のパフォーマンスを検証するには、[次へ] を選択します。 また、完了したバッチ実行に新しい評価ラウンドを追加できます。
[Select evaluation]\(評価の選択\) ページで、実行する 1 つ以上のカスタマイズされた評価または組み込みの評価を選択します。 [詳細の表示] ボタンを選択すると、生成されるメトリックや、必要な接続と入力など、評価方法に関する詳細情報を表示できます。
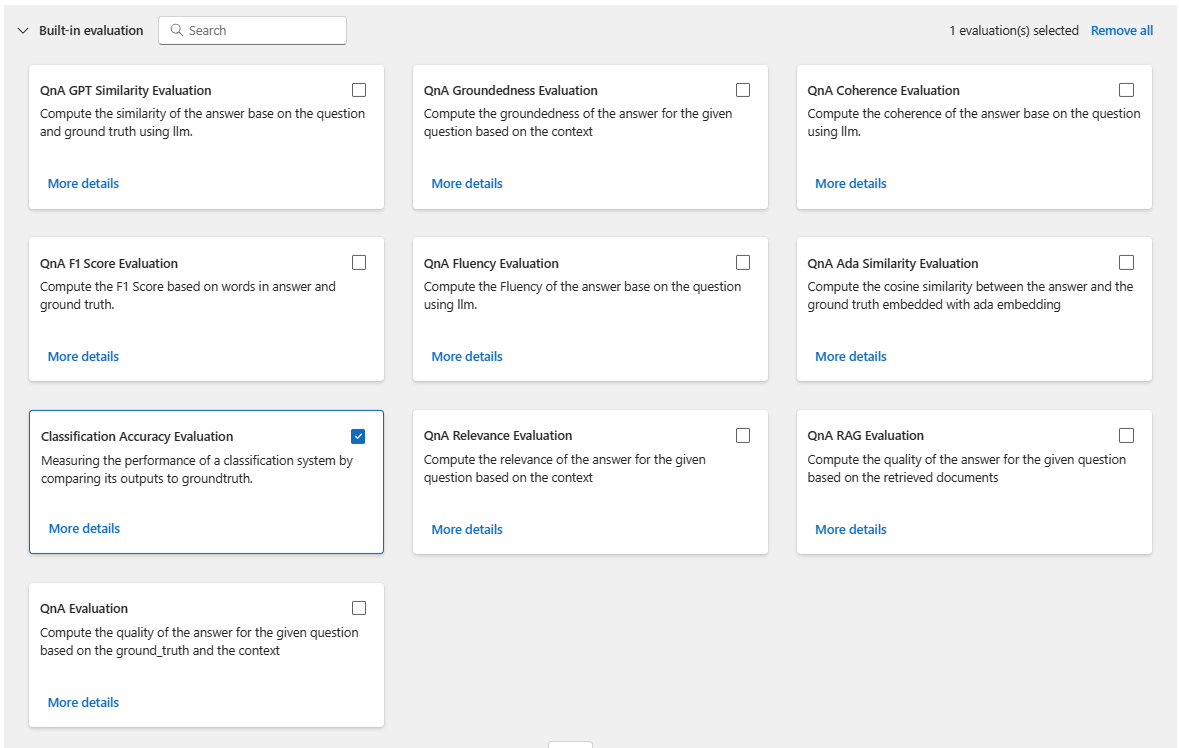
次に、[Configure evaluation]\(評価の構成\) 画面で、評価に必要な入力のソースを指定します。 たとえば、グラウンド トゥルース列はデータセットから取得できます。 既定では、評価ではバッチ実行全体と同じデータセットが使用されます。 ただし、対応するラベルまたはターゲットのグラウンド トゥルース値が別のデータセット内にある場合は、そのデータセットを使用できます。
Note
評価方法でデータセットからのデータが必要ない場合、データセットの選択は、評価結果に影響しない省略可能な構成です。 データセットを選択する、または入力マッピング セクションでデータセット列を参照する必要はありません。
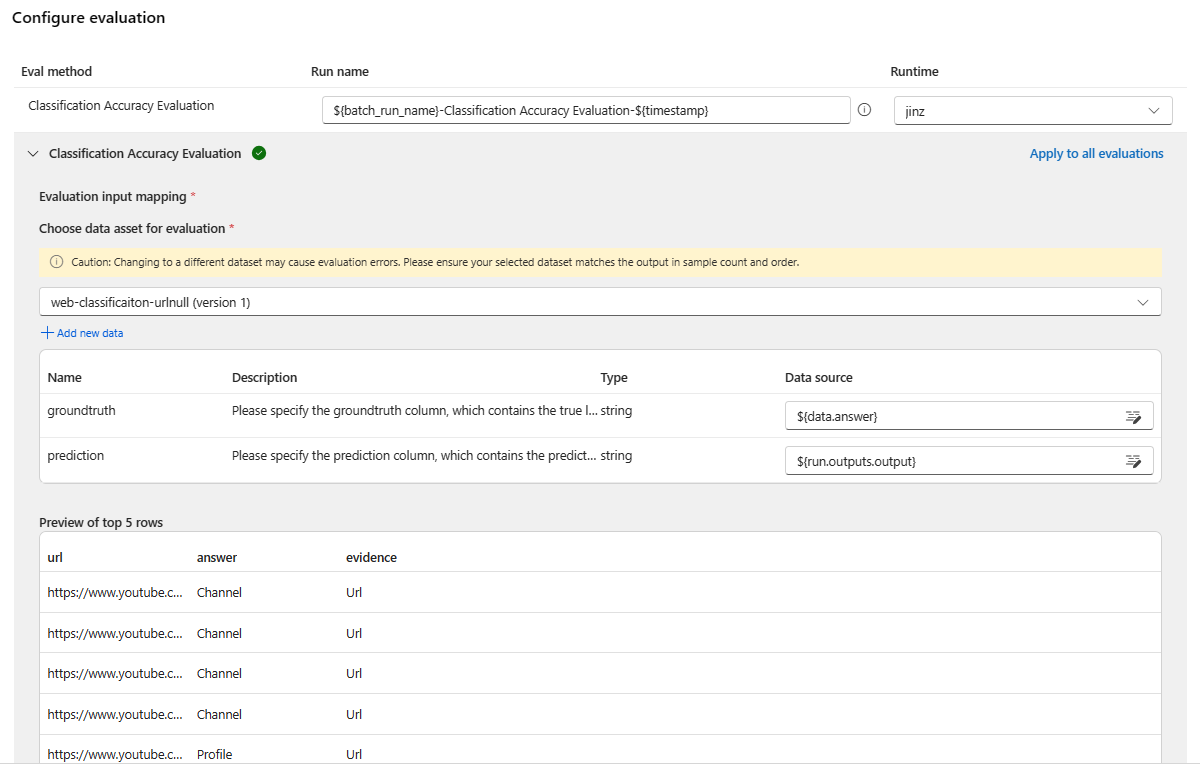
[Evaluation input mapping]\(評価入力のマッピング\) セクションで、評価に必要な入力のソースを指定します。
- データがテスト データセットからのデータの場合は、ソースを
${data.[ColumnName]}として設定します。 - データが実行の出力の場合は、ソースを
${run.outputs.[OutputName]}として設定します。
- データがテスト データセットからのデータの場合は、ソースを
評価方法によっては、GPT-4 や GPT-3 などの大規模言語モデル (LLM) が必要な場合や、資格情報やキーを使用するために他の接続が必要な場合があります。 これらの方法では、評価フローを使用するには、この画面の下部にある [接続] セクションに接続データを入力する必要があります。 詳細については、「接続を設定する」を参照してください。

[確認および送信] を選択して設定を見直し、[送信] を選択して評価を含むバッチ実行を開始します。






Note
- 評価プロセスによっては多くのトークンが使用されるため、>=16k トークンをサポートできるモデルを使用することをお勧めします。
- バッチ実行の最大期間は 10 時間です。 バッチ実行がこの制限を超えると実行は終了し、失敗として表示されます。 スロットリングを回避するために、LLM 容量を監視します。 必要であれば、データのサイズを小さくすることを検討してください。 それでも問題が発生する場合は、フィードバック フォームまたはサポート リクエストを提出してください。
評価結果とメトリックを表示する
送信されたバッチ実行の一覧は、Azure Machine Learning スタジオの [プロンプト フロー] ページの [実行数] タブにあります。
バッチ実行の結果を確認するには、実行を選択し、[Visualize outputs]\(出力の視覚化\) を選択します。
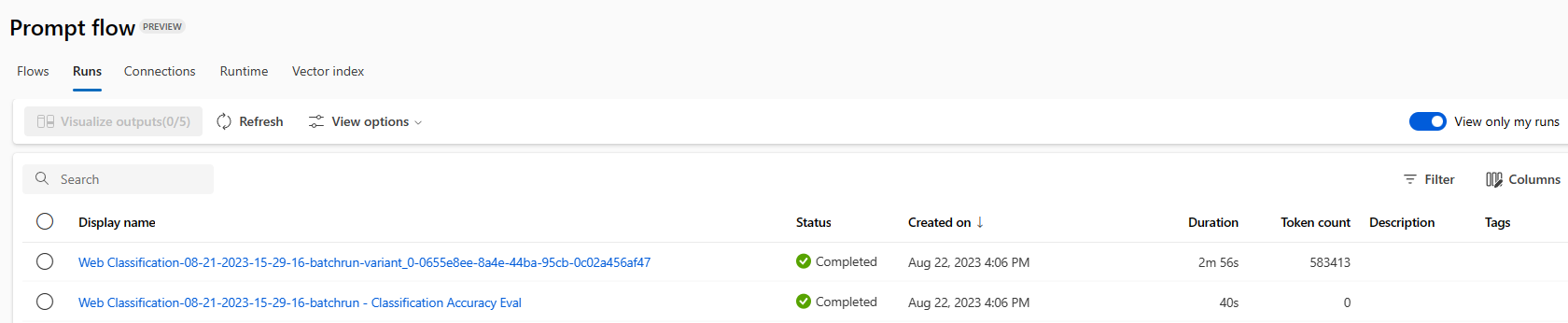
[Visualize outputs]\(出力の視覚化\) 画面の [Runs & metrics]\(実行とメトリック\) セクションに、バッチ実行と評価実行の全体的な結果が表示されます。 [出力] セクションに、行 ID、[実行]、[ステータス]、[システム メトリック] も含まれる結果テーブルの実行入力が 1 行ずつ表示されます。
![バッチ実行の出力を調べる、バッチ実行の結果ページの [出力] タブのスクリーンショット。](media/how-to-bulk-test-evaluate-flow/batch-run-output.png?view=azureml-api-2)
[Runs & metrics]\(実行とメトリック\) セクションの評価実行の横にある [表示] アイコンを有効にすると、[出力] テーブルに各行の評価スコアまたはグレードも表示されます。
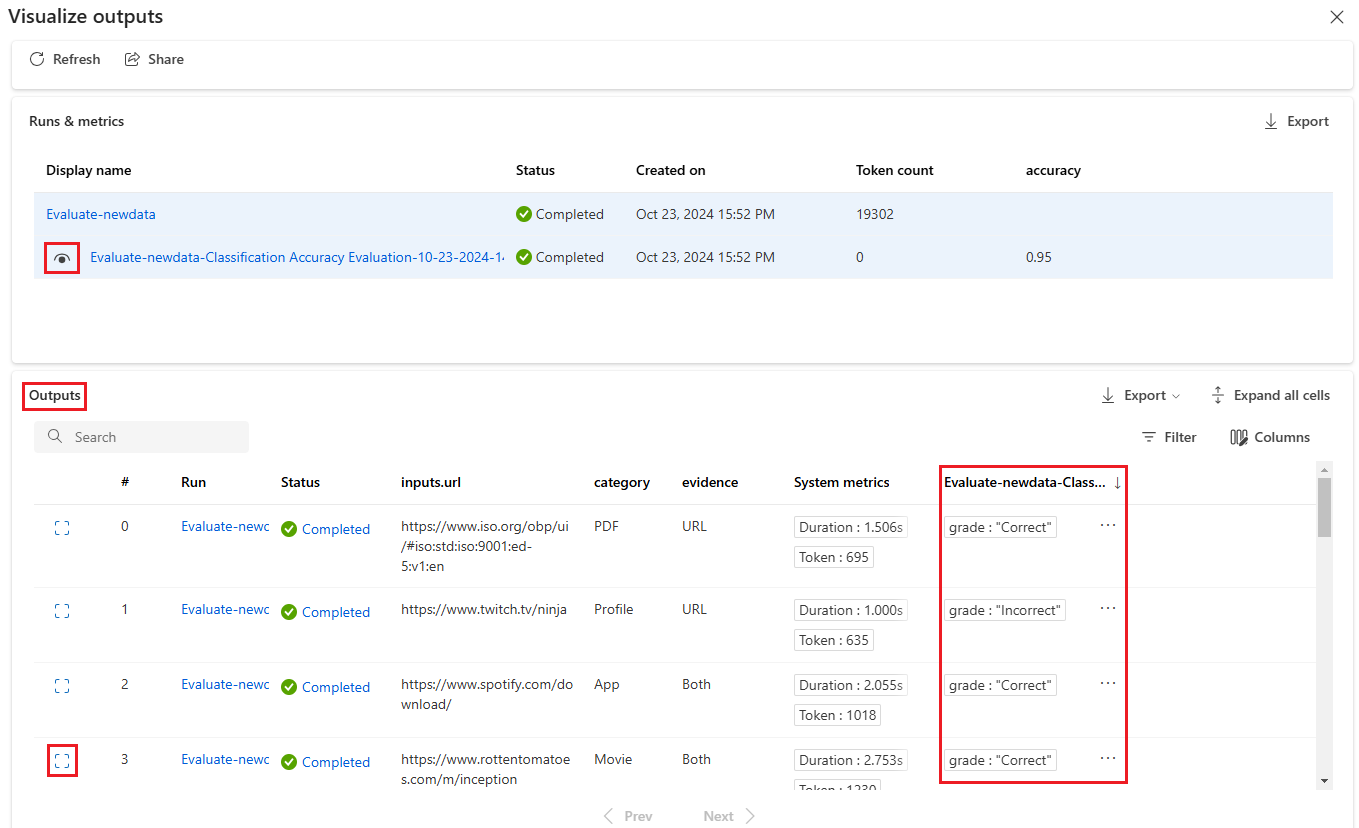
[出力] テーブルの各行の横にある [詳細の表示] アイコンを選択して、そのテスト ケースの [トレース] ビューと [詳細] を観察してデバッグします。 [トレース] ビューには、そのケースの [トークン] 数や [期間] などの情報が表示されます。 任意のステップを展開して選択すると、そのステップの [概要] と [入力] が表示されます。

![バッチ実行の出力を調べる、バッチ実行の結果ページの [出力] タブのスクリーンショット。](media/how-to-bulk-test-evaluate-flow/batch-run-output.png?view=azureml-api-2#lightbox)


テストしたプロンプト フローから評価実行の結果を表示することもできます。 [View batch runs]\(バッチ実行の表示\) で、[View batch runs]\(バッチ実行の表示\) を選択してフローのバッチ実行の一覧を表示するか、[View latest batch run outputs]\(最新のバッチ実行出力の表示\) を選択して最新の実行出力を表示します。
![[view bulk runs] (一括実行の表示) ボタンが選ばれている Web 分類のスクリーンショット。](media/how-to-bulk-test-evaluate-flow/batch-run-history.png?view=azureml-api-2#lightbox)
バッチ実行の一覧で、バッチ実行名を選択して、その実行のフロー ページを開きます。
評価実行のフロー ページで、[出力の表示] または [詳細] を選択して、フローの詳細を表示します。 フローの [クローン] を選択して新しいフローを作成するか、[デプロイ] を選択してオンライン エンドポイントとしてデプロイできます。

[詳細] 画面で、次の手順を実行します。
[概要] タブに、実行プロパティ、入力データセット、出力データセット、タグ、説明など、実行に関する包括的な情報が表示されます。
[出力] タブに、ページの上部に結果の概要が表示され、その後にバッチ実行結果テーブルが表示されます。 [Append related results]\(関連する結果の追加\) の横にある評価実行を選択すると、評価実行結果もテーブルに表示されます。
![評価フローの詳細画面の [出力] タブのスクリーンショット。](media/how-to-bulk-test-evaluate-flow/batch-run-output-overview.png?view=azureml-api-2)
[ログ] タブに実行ログが表示されます。これは、実行エラーの詳細なデバッグに役立ちます。 ログ ファイルをダウンロードできます。
[メトリック] タブに、実行のメトリックへのリンクが表示されます。
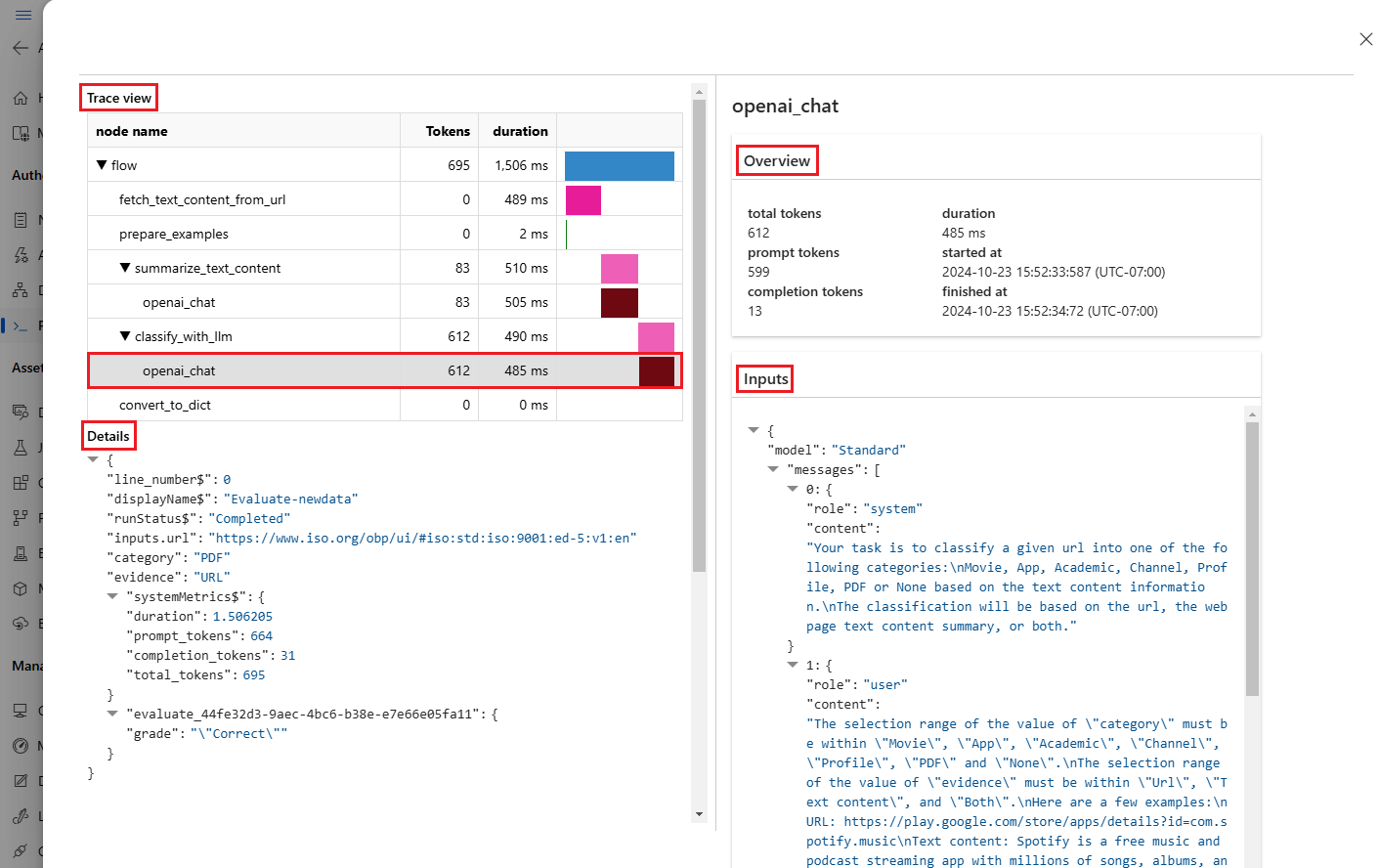
[トレース] タブに、各テスト ケースの [トークン] 数や [期間] などの詳細情報が表示されます。 任意のステップを展開して選択すると、そのステップの [概要] と [入力] が表示されます。
[スナップショット] タブに、実行のファイルとコードが表示されます。 flow.dag.yaml フロー定義を確認し、それらの任意のファイルをダウンロードできます。
![評価フローの詳細画面の [出力] タブのスクリーンショット。](media/how-to-bulk-test-evaluate-flow/batch-run-output-overview.png?view=azureml-api-2#lightbox)

同じ実行に対して新しい評価ラウンドを開始する
フローを再実行せずに、新しい評価ラウンドを実行して、完了したバッチ実行のメトリックを計算できます。 このプロセスにより、フローを再実行するコストが節約され、次のシナリオで役立ちます。
- バッチ実行を送信したときに評価方法を選択しなかったので、次は実行のパフォーマンスを評価します。
- 評価方法を使用して特定のメトリックを計算しました。次は別のメトリックを計算します。
- 前回の評価実行は失敗し、バッチ実行では正常に出力が生成されました。次は評価をもう一度試します。
別の評価ラウンドを開始するには、バッチ実行フロー ページの上部にある [評価] を選択します。 [New evaluation]\(新しい評価\) ウィザードが開き、[Select evaluation]\(評価の選択\) 画面が表示されます。 セットアップを完了し、新しい評価実行を送信します。
新しい実行がプロンプト フローの [実行] 一覧に表示され、一覧で複数の行を選択し、[Visualize outputs]\(出力の視覚化\) を選択して、出力とメトリックを比較できます。
評価実行の履歴とメトリックを比較する
フローのパフォーマンスを向上させるためにフローを変更する場合は、複数のバッチ実行を送信して、さまざまなフロー バージョンのパフォーマンスを比較できます。 また、異なる評価方法で計算されたメトリックを比較して、どの方法が自分のフローに適しているかを確認することもできます。
フローのバッチ実行履歴を確認するには、フロー ページの上部にある [View batch runs]\(バッチ実行の表示\) を選択します。 各実行を選択して、詳細を確認できます。 複数の実行を選択し、[Visualize outputs]\(出力の視覚化\) を選択して、それらの実行のメトリックと出力を比較することもできます。

組み込みの評価メトリックを理解する
Azure Machine Learning プロンプト フローには、フロー出力のパフォーマンスを測定するのに役立ついくつかの組み込みの評価方法が用意されています。 各評価方法では、異なるメトリックが計算されます。 次の表では、使用可能な組み込みの評価方法について説明します。
| 評価方法 | メトリック | 説明 | 接続が必要かどうか | 必要な入力 | スコアの値 |
|---|---|---|---|---|---|
| 分類の精度の評価 | 精度 | 出力をグラウンド トゥルースと比較することで、分類システムのパフォーマンスを測定します | いいえ | 予測、実測値 | 0 から 1 の範囲内 |
| QnA 現実性評価 | 現実性 | モデルで予測された回答が入力ソースにおいてどの程度現実的なものかを測定します。 LLM の応答が正確な場合でも、ソースと照らし合わせて検証されていない場合は、その応答はグラウンディングされていません。 | はい | 質問、回答、コンテキスト (実測値なし) | 1 から 5 (1 が最悪、5 が最高) |
| QnA GPT 類似性評価 | GPT 類似性 | GPT モデルを使用して、ユーザーが提供したグラウンド トゥルースの回答とモデルで予測された回答の類似性を測定します | はい | 質問、回答、実測値 (コンテキストは不要) | 1 から 5 (1 が最悪、5 が最高) |
| QnA 関連性評価 | 関連性 | モデルで予測された回答が、質問とどの程度関連しているかを測定します | はい | 質問、回答、コンテキスト (実測値なし) | 1 から 5 (1 が最悪、5 が最高) |
| QnA 一貫性評価 | 一貫性 | モデルで予測された回答内のすべての文の品質と、それらの自然な適合具合を測定します | はい | 質問、回答 (実測値またはコンテキストなし) | 1 から 5 (1 が最悪、5 が最高) |
| QnA 流暢性評価 | 流暢性 | モデルで予測された回答の文法と言語の正確性を測定します | はい | 質問、回答 (実測値またはコンテキストなし) | 1 から 5 (1 が最悪、5 が最高) |
| QnA F1 スコア評価 | F1 スコア | モデルの予測とグラウンド トゥルースの間で共有されている単語数の割合を測定します | いいえ | 質問、回答、実測値 (コンテキストは不要) | 0 から 1 の範囲内 |
| QnA Ada 類似性評価 | Ada 類似性 | グラウンド トゥルースと予測との両方に Ada 埋め込み API を使用して文 (ドキュメント) レベルの埋め込みを計算し、それらの間のコサイン類似性を計算します (1 つの浮動小数点数) | はい | 質問、回答、実測値 (コンテキストは不要) | 0 から 1 の範囲内 |
フロー パフォーマンスを向上する
実行に失敗した場合は、出力データとログ データを確認し、フローのエラーをデバッグします。 フローを修正するか、パフォーマンスを向上させるには、フロー プロンプト、システム メッセージ、フロー パラメーター、またはフロー ロジックを変更してみてください。
プロンプト エンジニアリング
プロンプトの構築は難しい場合があります。 プロンプト構築の概念については、プロンプトの概要に関する記事を参照してください。 目標の達成に役立つプロンプトを作成する方法については、「プロンプト エンジニアリングの手法」を参照してください。
システム メッセージ
システム メッセージ (メタプロンプトまたはシステム プロンプトと呼ばれることもあります) は、AI システムの動作のガイドとして、またシステム パフォーマンスを向上させるために使用できます。 システム メッセージを使用してフローのパフォーマンスを向上させる方法については、システム メッセージのステップ バイ ステップでの作成に関する記事を参照してください。
ゴールデン データセット
通常、LLM を使用するコパイロットを作成するには、ソース データセットを使用してモデルを現実にグラウンディングする必要があります。 "ゴールデン データセット" は、LLM が顧客の問い合わせに対して最も正確で有用な応答を提供するのに役立ちます。
ゴールデン データセットは、現実的な顧客の質問と専門的に作成された回答のコレクションであり、コパイロットが使用する LLM の品質保証ツールとして機能します。 ゴールデン データセットは、LLM のトレーニングやコンテキストの LLM プロンプトへの挿入に使用されるのではなく、LLM が生成する回答の品質を評価するために使用されます。
シナリオにコパイロットが含まれる場合、または独自のコパイロットを構築している場合は、詳細なガイダンスとベスト プラクティスをゴールデン データセットの作成に関する記事で参照してください。