チュートリアル: デザイナーを使用して機械学習モデルをデプロイする
このチュートリアルのパート 1 では、自動車価格を予測する線形回帰モデルをトレーニングしました。 この 2 番目のパートでは、Azure Machine Learning デザイナーを使用してモデルをデプロイし、他のユーザーがモデルを使用できるようにします。
Note
デザイナーは、従来の事前構築済みコンポーネント (v1) とカスタム コンポーネント (v2) の 2 種類のコンポーネントをサポートします。 これら 2 種類のコンポーネントには互換性がありません。
従来の事前構築済みコンポーネントは、主にデータ処理や、回帰や分類などの従来の機械学習タスク向けの事前構築済みのコンポーネントを提供します。 この種類のコンポーネントは引き続きサポートされますが、新しいコンポーネントは追加されません。
カスタム コンポーネントを使用すると、独自のコードをコンポーネントとしてラップすることができます。 これは、ワークスペース間でのコンポーネントの共有と、Machine Learning スタジオ、CLI v2、SDK v2 インターフェイス間でのシームレスな作成をサポートします。
新しいプロジェクトでは、Azure Machine Learning v2 と互換性があり、新しい更新を継続的に受け取るカスタム コンポーネントを使用することをお勧めします。
この記事は、従来の事前構築済みコンポーネントに適用され、CLI v2 および SDK v2 との互換性はありません。
このチュートリアルでは、次の作業を行いました。
- リアルタイム推論パイプラインを作成する。
- 推論クラスターを作成する。
- リアルタイム エンドポイントをデプロイする。
- リアルタイム エンドポイントをテストする。
前提条件
チュートリアルのパート 1 を完了して、デザイナーで機械学習モデルをトレーニングしてスコア付けする方法を学習します。
重要
このドキュメントで言及しているグラフィカル要素 (スタジオやデザイナーのボタンなど) が表示されない場合は、そのワークスペースに対する適切なレベルのアクセス許可がない可能性があります。 ご自分の Azure サブスクリプションの管理者に連絡して、適切なレベルのアクセス許可があることを確認してください。 詳細については、「ユーザーとロールを管理する」を参照してください。
リアルタイム推論パイプラインを作成する
パイプラインをデプロイするためには、まずトレーニング パイプラインをリアルタイム推論パイプラインに変換する必要があります。 このプロセスにより、トレーニング コンポーネントが削除され、要求を処理するための Web サービスの入力と出力が追加されます。
Note
推論パイプラインの作成機能では、デザイナーの組み込みコンポーネントのみを含み、トレーニング済みモデルを出力するモデルのトレーニングなどのコンポーネントを備えたトレーニング パイプラインがサポートされます。
リアルタイム推論パイプラインを作成する
サイド ナビゲーション パネルから [パイプライン] を選択し、作成したパイプライン ジョブを開きます。 パイプライン キャンバスの上にある詳細ページで、省略記号 [...] を選択し、[Create inference pipeline]\(推論パイプラインの作成\)>[Real-time inference pipeline]\(リアルタイム推論パイプライン\) を選択します。
新しいパイプラインは次のようになります。
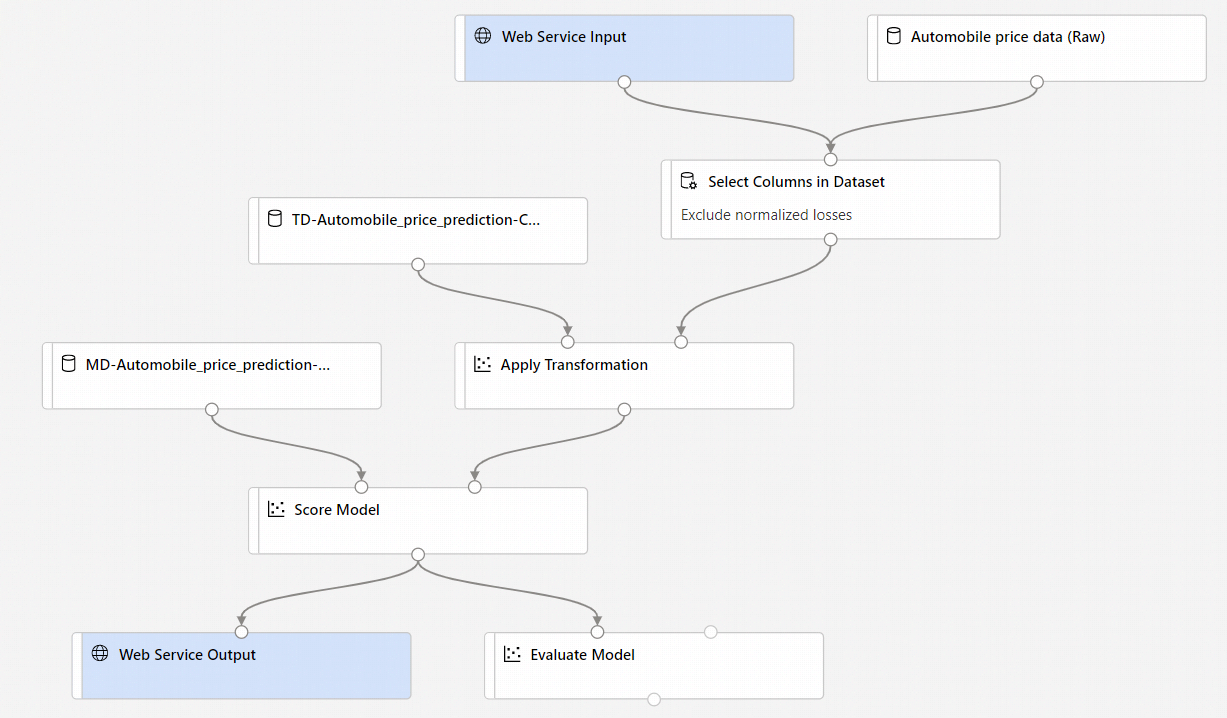
[Create inference pipeline](推論パイプラインの作成) を選択すると、以下のようないくつかの処理が行われます。
- トレーニング済みのモデルが、コンポーネント パレットに [Dataset](データセット) コンポーネントとして格納されます。 これは [マイ データセット] で見つかります。
- [Train Model](モデルのトレーニング) や [Split Data](データの分割) などのトレーニング コンポーネントが削除されます。
- 保存したトレーニング済みのモデルが再びパイプラインに追加されます。
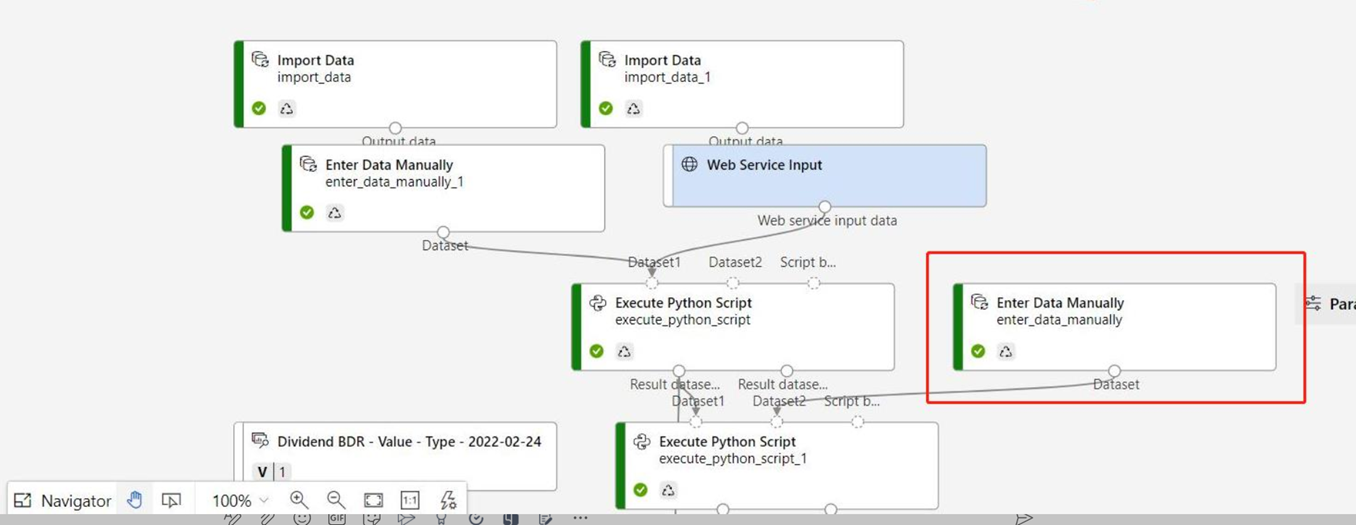
- [Web Service Input](Web サービスの入力) および [Web Service Output](Web サービスの出力) コンポーネントが追加されます。 ユーザー データがパイプラインに入力される位置と、データが返される位置が、これらのコンポーネントによって示されます。
Note
既定で、[Web Service Input]\(Web サービスの入力\) では、同じダウンストリーム ポートに接続するコンポーネント出力データと同じデータ スキーマが予期されます。 このサンプルでは、[Web Service Input]\(Web サービスの入力\) と [Automobile price data (Raw)]\(自動車価格データ (未加工)\) は同じダウンストリーム コンポーネントに接続します。そのため、[Web Service Input]\(Web サービスの入力\) では、[Automobile price data (Raw)]\(自動車価格データ (未加工)\) と同じデータ スキーマが予期され、ターゲット変数列
priceがスキーマに含まれます。 しかし、データにスコアを付けるときは、ターゲット変数の値がわかりません。 このような場合は、データセット内の列の選択コンポーネントを使用して、推論パイプライン内のターゲット変数列を削除できます。 ターゲット変数列を削除する [データセット内の列の選択] の出力が、[Web サービスの入力] コンポーネントの出力と同じポートに接続されていることを確認してください。[Configure & Submit]\(構成と送信\) を選択し、パート 1 で使用したものと同じコンピューティング先と実験を使用します。
これが最初のジョブの場合は、パイプラインの実行が完了するまでに最大 20 分かかることがあります。 既定のコンピューティング設定の最小ノード サイズは 0 です。これは、アイドル状態になった後に、デザイナーによってリソースが割り当てられる必要があることを意味します。 コンピューティング リソースが既に割り当てられているため、パイプラインの反復ジョブにかかる時間は短くなります。 さらにデザイナーでは、各コンポーネント用にキャッシュされた結果を使用して、効率を向上させます。
左側のウィンドウで [ジョブの詳細] を選択して、リアルタイム推論パイプライン ジョブの詳細に移動します。
[ジョブの詳細] ページで [デプロイ] を選択します。
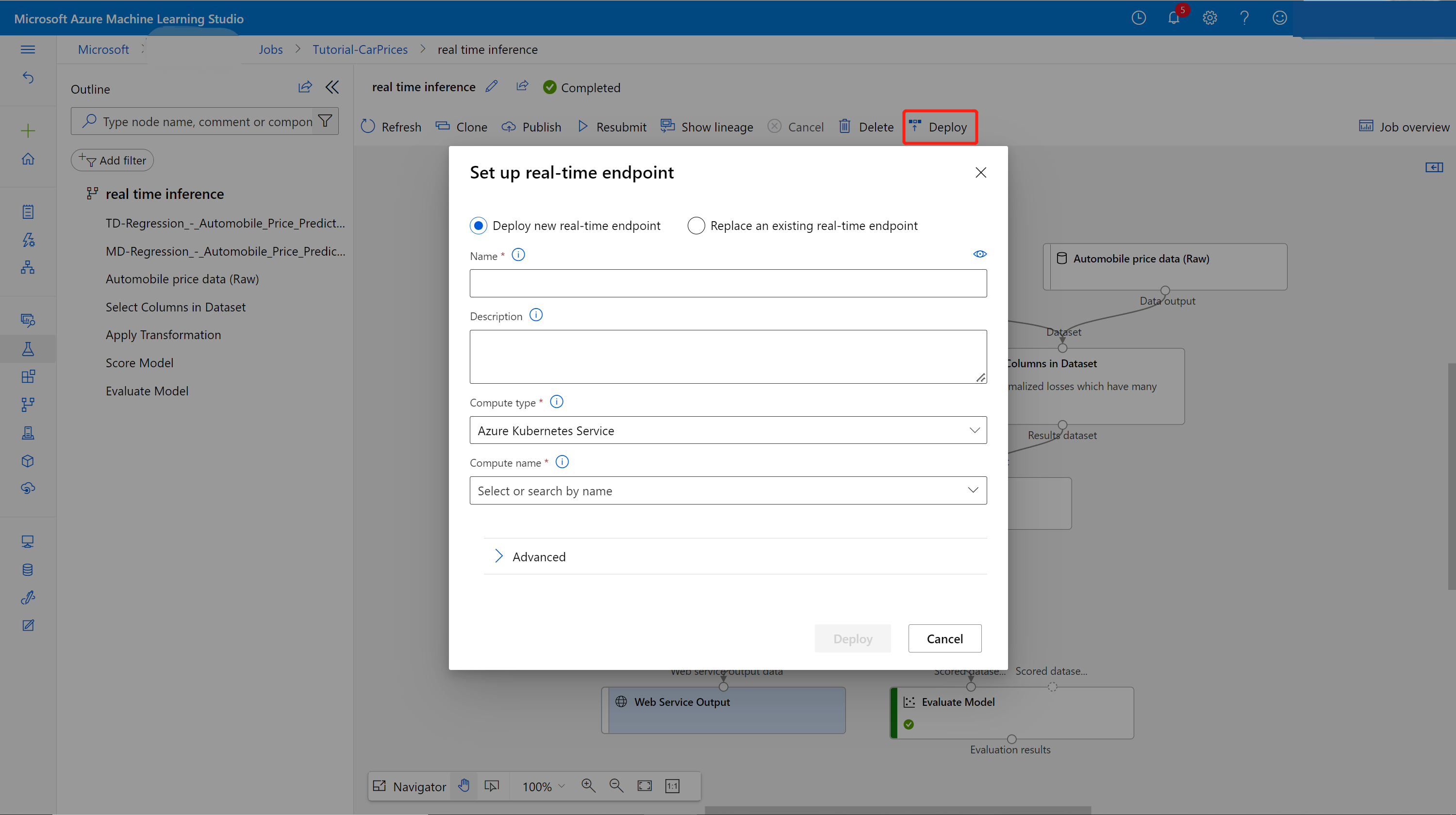


推論クラスターを作成する
表示されたダイアログ ボックスで、既存の Azure Kubernetes Service (AKS) クラスターを選択して自分のモデルをデプロイできます。 既存の AKS クラスターがない場合は、次の手順を使用して作成してください。
ダイアログ ボックスで [計算する] を選択して、[計算する] ページに移動します。
ナビゲーション リボンで、[Kubernetes Clusters]\(Kubernetes クラスター\)>[+ 新規] を選択します。
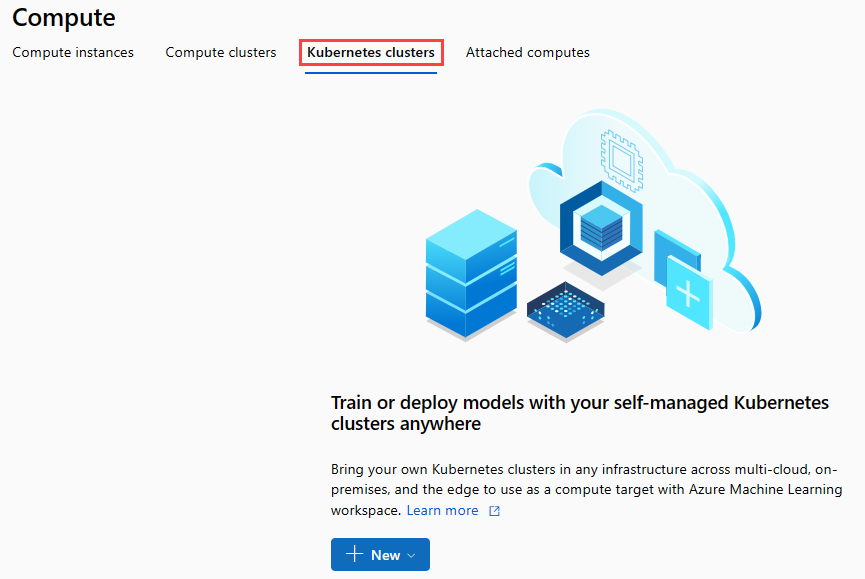
推論クラスター ウィンドウで、新しい Kubernetes サービスを構成します。
[Compute name](コンピューティング名) に「aks-compute」と入力します。
[Region](リージョン) には、使用できる近くのリージョンを選択します。
[作成] を選択します
Note
新しい AKS サービスの作成には約 15 分かかります。 プロビジョニングの状態は、 [Inference Clusters](推論クラスター) ページで確認できます。
リアルタイム エンドポイントをデプロイする
AKS サービスのプロビジョニングが完了したら、リアルタイム推論パイプラインに戻ってデプロイを完了します。
キャンバスの上にある [Deploy](デプロイ) を選択します。
[Deploy new real-time endpoint](新しいリアルタイム エンドポイントのデプロイ) を選択します。
作成した AKS クラスターを選択します。
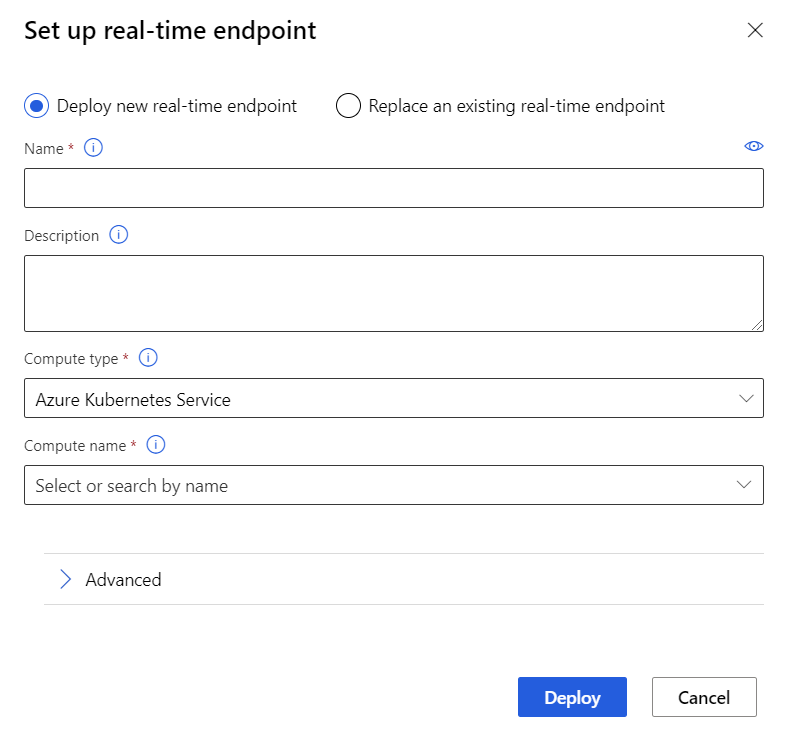
リアルタイム エンドポイントの [詳細] 設定を変更することもできます。
[詳細] 設定 Description Application Insights の診断とデータ収集を有効にする Azure Application Insights に、デプロイされたエンドポイントからのデータ収集を許可します。
既定値: false。スコアリング タイムアウト Web サービスのスコアリング呼び出しに適用するタイムアウト (ミリ秒)。
既定値: 60000。Auto scale enabled(自動スケーリングの有効化) Web サービスの自動スケールを許可します。
既定値: true。最小レプリカ数 この Web サービスを自動スケールするときに使用するコンテナーの最小数。
既定値: 1。最大レプリカ数 この Web サービスを自動スケールするときに使用するコンテナーの最大数。
既定値: 10。ターゲット使用率 オートスケーラーがこの Web サービスに対してメンテナンスを試行する目標使用率 (パーセンテージとして)。
既定値: 70。更新間隔 自動スケーラーがこの Web サービスのスケーリングを試みる頻度 (秒)。
既定値: 1。CPU 予約容量 この Web サービスに割り当てる CPU コアの数。
既定値: 0.1。メモリ予約容量 この Web サービスに割り当てるメモリの量 (GB 単位)。
既定値: 0.5。[デプロイ] を選択します。
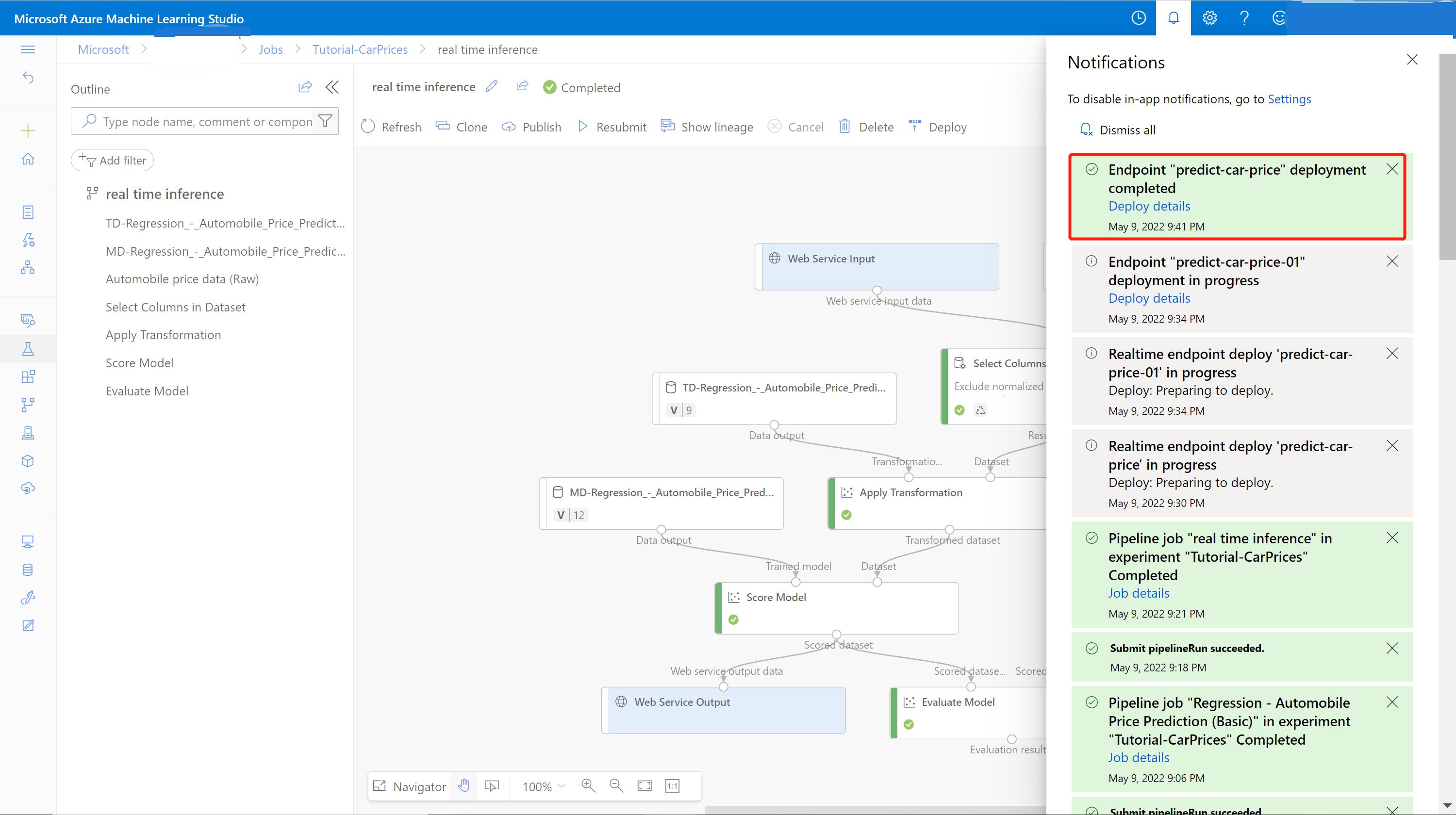
デプロイが完了すると、通知センターからの成功通知が表示されます。 これには数分かかる可能性があります。

ヒント
リアルタイム エンドポイント設定ボックスで、[コンピューティングの種類] に [Azure コンテナー インスタンス] を選択すると、Azure コンテナー インスタンスにデプロイすることもできます。 Azure コンテナー インスタンスは、テストまたは開発に使用されます。 必要な RAM が 48 GB より少ない低スケール CPU ベース ワークロードには Azure Container Instance を使用します。
リアルタイム エンドポイントをテストする
デプロイが完了したら、 [エンドポイント] ページに移動して、リアルタイム エンドポイントを表示できます。
[Endpoints](エンドポイント) ページで、デプロイ済みのエンドポイントを選択します。
[詳細] タブでは、REST URI、Swagger 定義、状態、タグなどの詳細情報を確認できます。
[Consume](使用) タブでは、サンプル使用コードやセキュリティ キーを検索し、認証方法を設定できます。
[デプロイ ログ] タブで、リアルタイム エンドポイントの詳細なデプロイ ログを確認できます。
エンドポイントをテストするには、 [テスト] タブに移動します。ここでは、テスト データを入力し、 [テスト] を選択して、エンドポイントの出力を確認します。
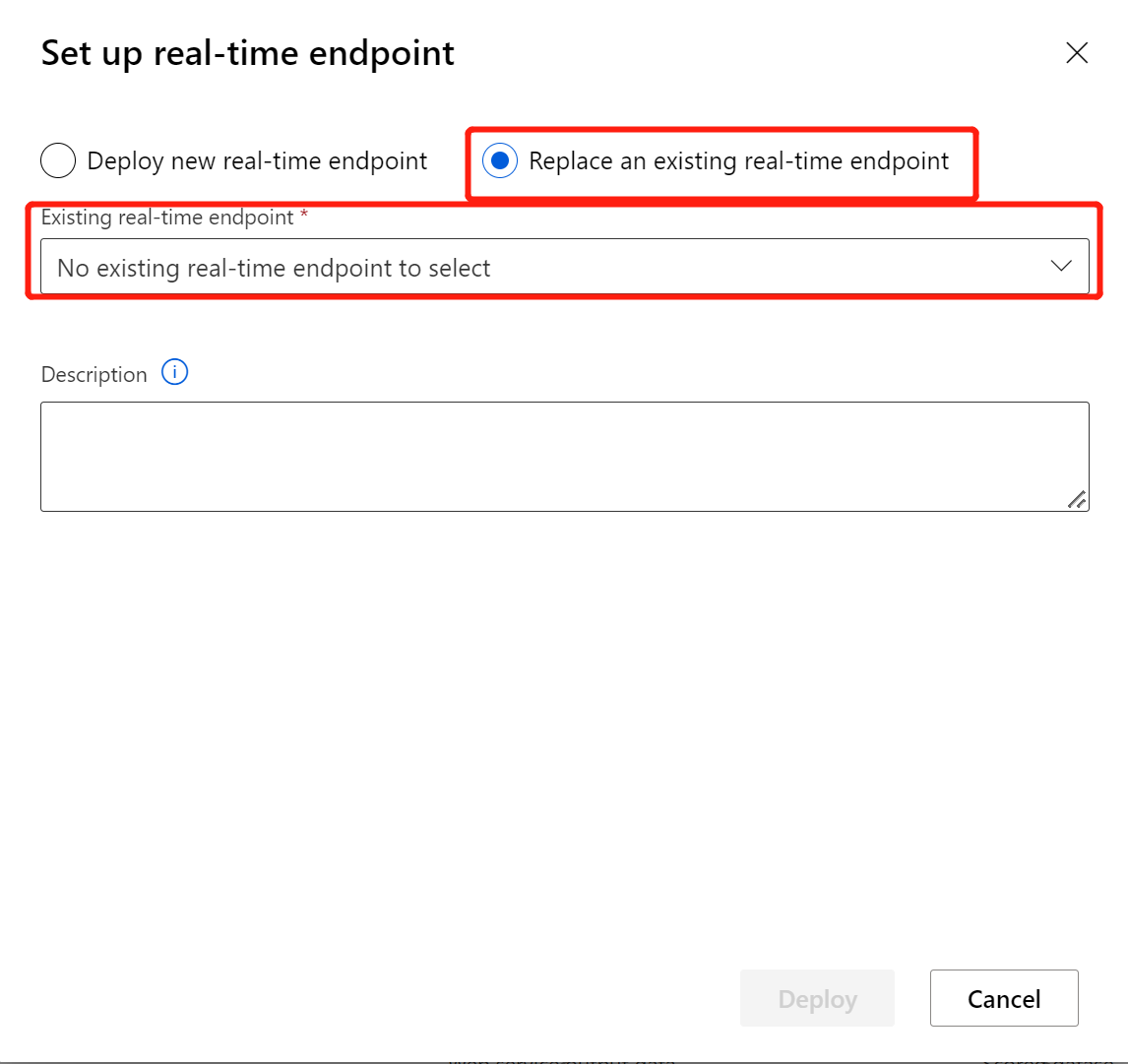
リアルタイム エンドポイントを更新する
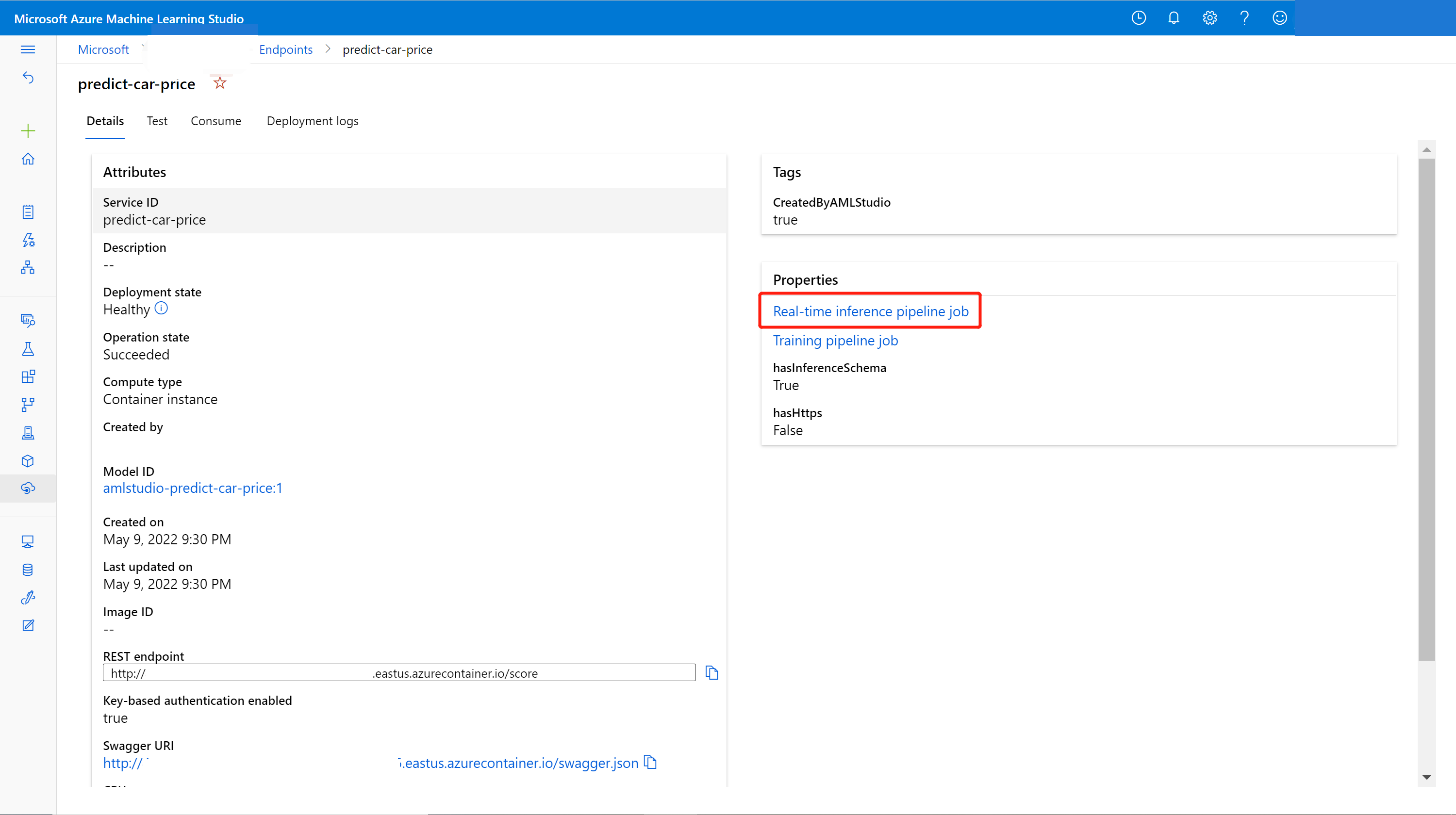
オンライン エンドポイントは、デザイナーでトレーニングされた新しいモデルで更新できます。 オンライン エンドポイントの詳細ページで、前のトレーニング パイプライン ジョブと推論パイプライン ジョブを見つけます。
トレーニング パイプラインのドラフトは、デザイナーのホームページで見つけて変更できます。
または、トレーニング パイプライン ジョブのリンクを開き、それを新しいパイプライン ドラフトに複製して編集を続行することもできます。
変更されたトレーニング パイプラインを送信したら、ジョブの詳細ページに移動します。
ジョブが完了したら、[モデルのトレーニング] を右クリックし、[データの登録] を選択します。
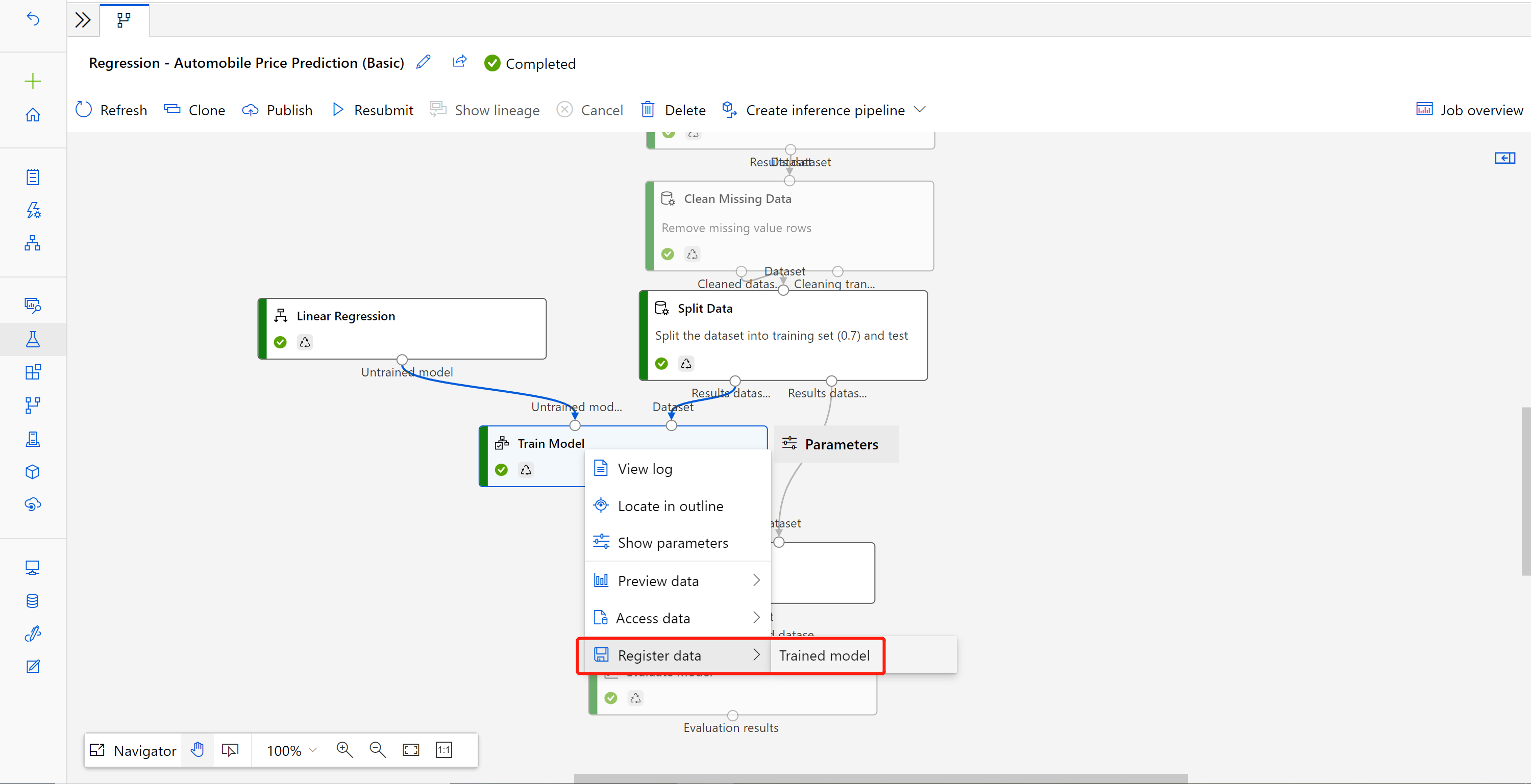
名前を入力し、[ファイル]の種類を選択します。
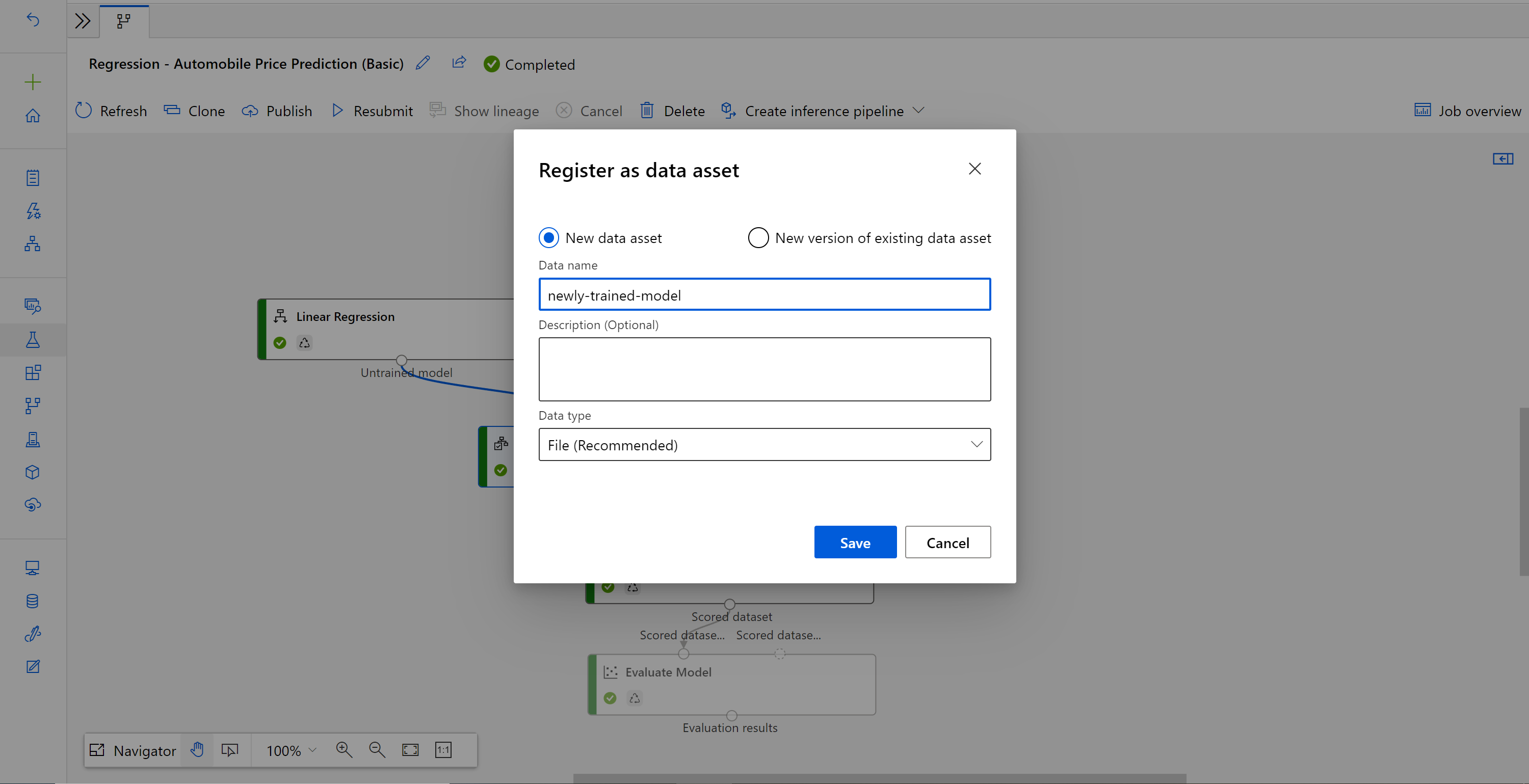
データセットが正常に登録されたら、推論パイプラインのドラフトを開くか、前の推論パイプライン ジョブを新しいドラフトに複製します。 推論パイプラインのドラフトで、[モデルのスコア付け] コンポーネントに接続されている MD-XXXX ノードとして示されている前のトレーニング済みモデルを、新しく登録されたデータセットに置き換えます。
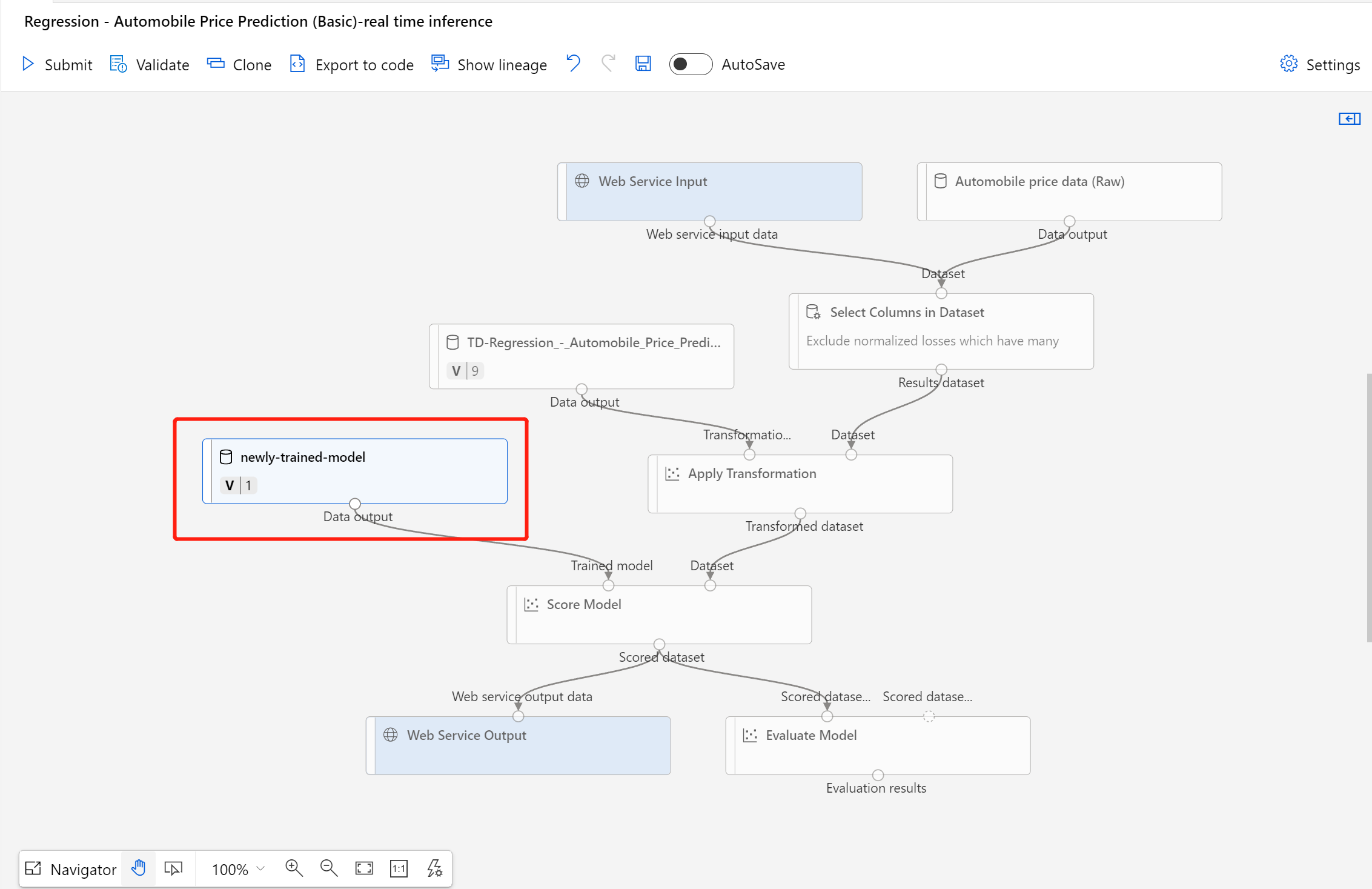
トレーニング パイプラインでデータ前処理部分を更新する必要があり、推論パイプラインに更新したい場合、処理は上記のステップとほぼ同じです。
変換コンポーネントの変換出力をデータ・セットとして登録するだけで済みます。
次に、推論パイプラインの TD- コンポーネントを、登録したデータセットに手動で置き換えます。
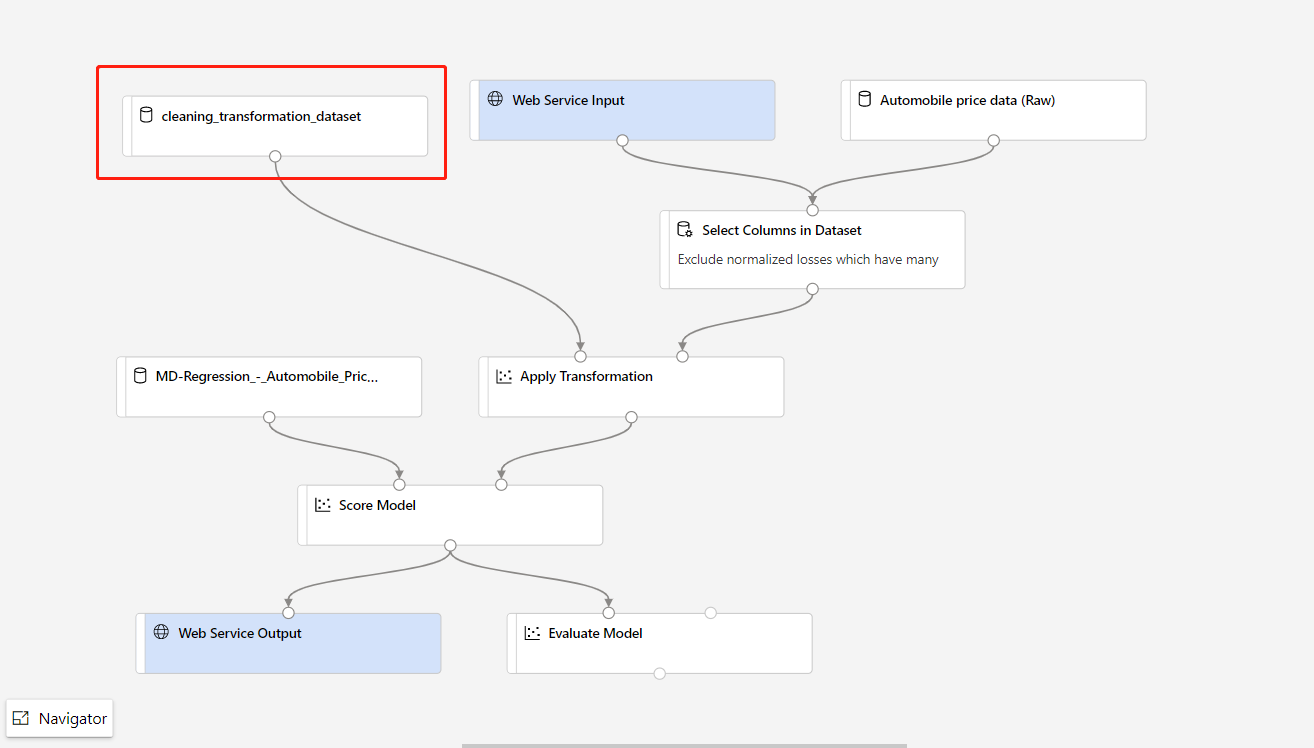
新しくトレーニングされたモデルまたは変換を使用して推論パイプラインを変更した後、それを送信します。 ジョブが完了したら、前にデプロイした既存のオンライン エンドポイントにデプロイします。




制限事項
データストアのアクセス制限により、推論パイプラインにデータのインポートまたはデータのエクスポート コンポーネントが含まれている場合、リアルタイム エンドポイントへのデプロイ時にこれらは自動的に削除されます。
リアルタイム推論パイプラインにデータセットがあり、それをリアルタイム エンドポイントにデプロイする場合、現在、このフローでは BLOB データストアから登録されたデータセットのみがサポートされています。 他の型のデータストアのデータセットを使用する場合は、[列の選択] を使用して、すべての列を選択する設定で初期データセットに接続し、[列をファイルとして選択] データセットの出力を登録した後、リアルタイム推論パイプラインの初期データセットを、この新しく登録されたデータセットに置き換えることができます。
推論グラフに、Web サービス入力コンポーネントと同じポートに接続されていないデータの手動入力コンポーネントが含まれている場合、HTTP 呼び出し処理中にデータの手動入力コンポーネントは実行されません。 回避策は、そのデータの手動入力コンポーネントの出力をデータセットとして登録し、推論パイプラインのドラフトで、データの手動入力コンポーネントを登録済みのデータセットに置き換えることです。

リソースをクリーンアップする
重要
作成したリソースは、Azure Machine Learning のその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
すべてを削除する
作成したすべてのものを使用する予定がない場合は、料金が発生しないように、リソース グループ全体を削除します。
Azure portal で、ウィンドウの左側にある [リソース グループ] を選択します。
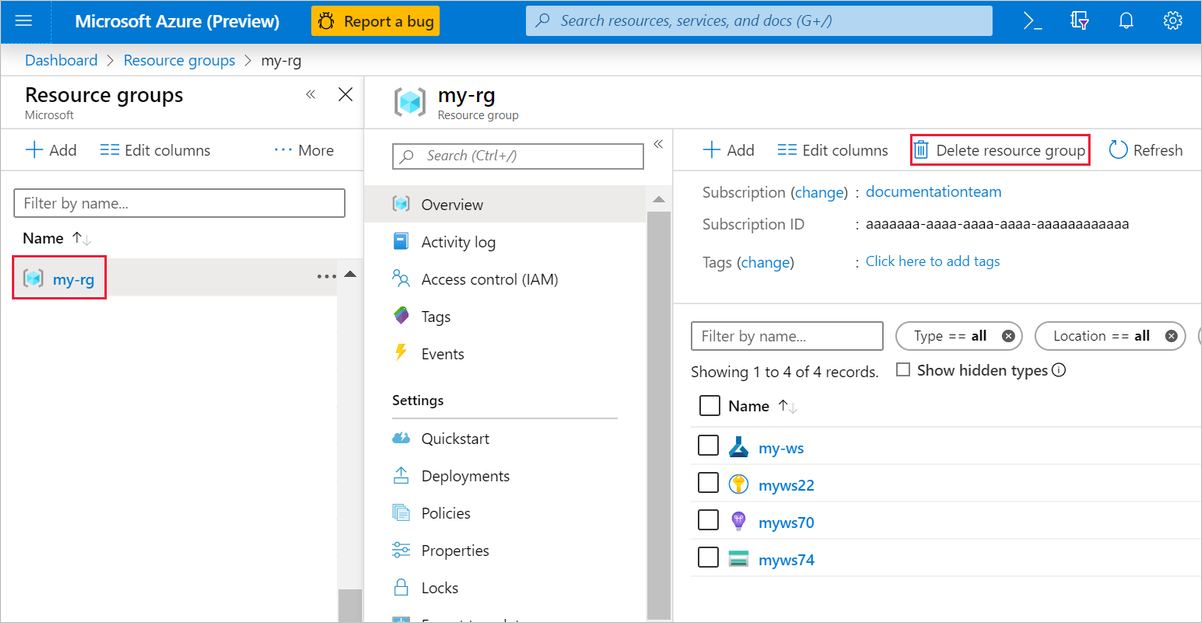
一覧から、作成したリソース グループを選択します。
[リソース グループの削除] を選択します。
リソース グループを削除すると、デザイナーで作成したすべてのリソースも削除されます。
個々の資産を削除する
実験を作成したデザイナーで、個々の資産を選択し、[削除] ボタンを選択してそれらを削除します。
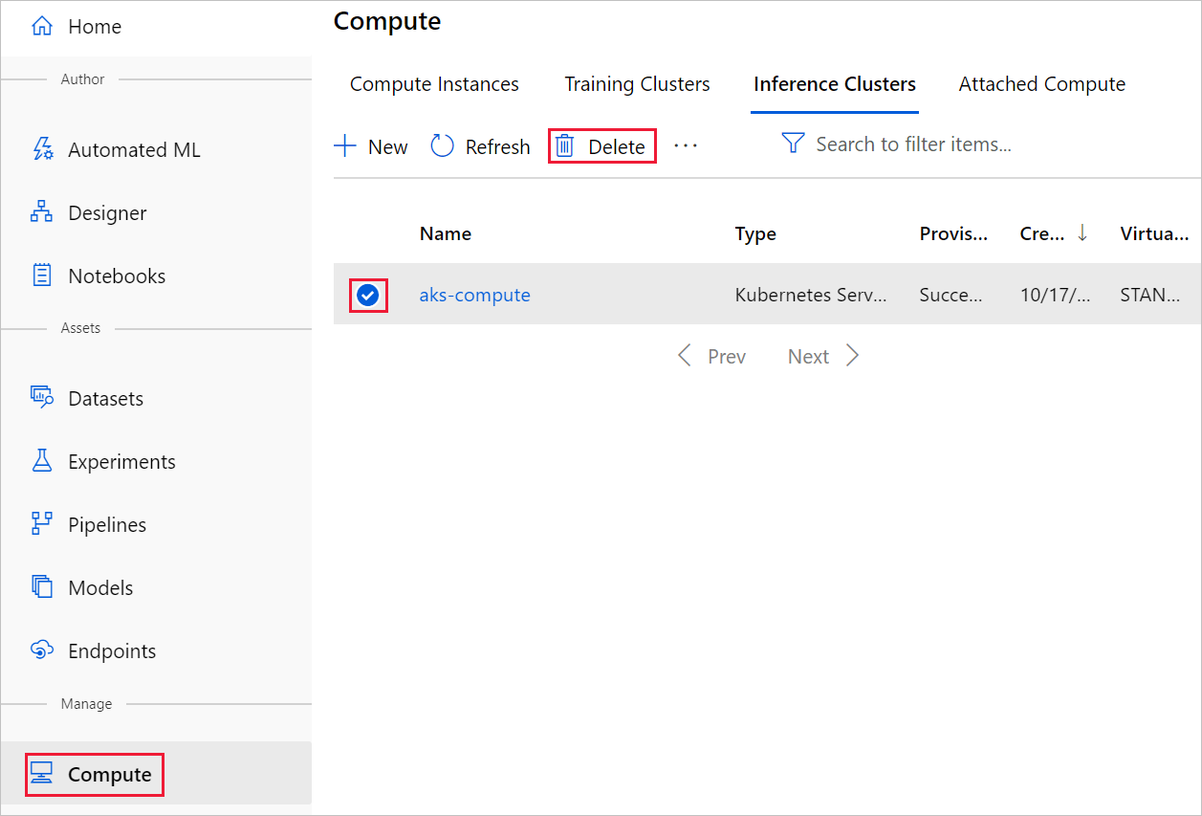
ここで作成したコンピューティング ターゲットは、使用されていない場合、自動的にゼロ ノードに自動スケーリングされます。 このアクションは、料金を最小限に抑えるために実行されます。 コンピューティング ターゲットを削除する場合は、次の手順を実行してください。
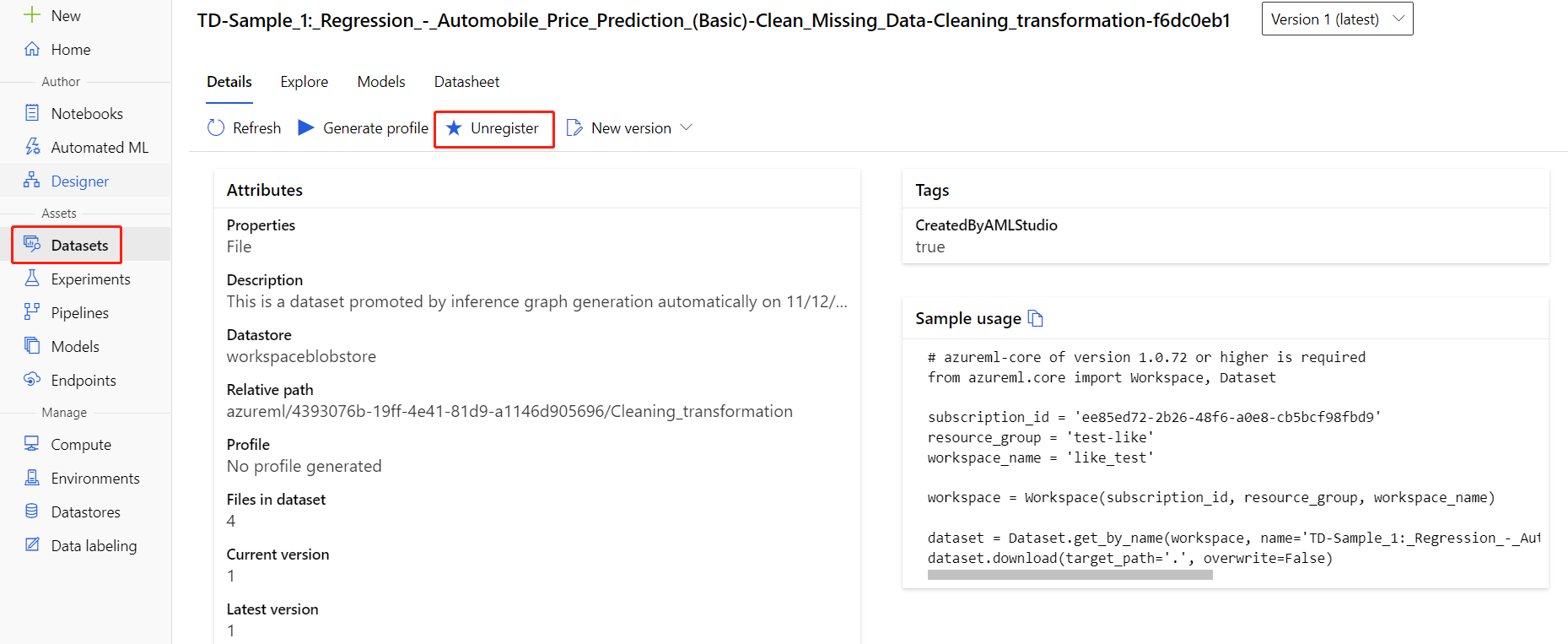
各データセットを選択し、[登録解除] を選択することによって、ワークスペースからデータセットを登録解除できます。
データセットを削除するには、Azure portal または Azure Storage Explorer を使用してストレージ アカウントに移動し、これらのアセットを手動で削除します。
関連するコンテンツ
このチュートリアルでは、デザイナーで機械学習モデルを作成、デプロイ、および使用する方法を学習しました。 デザイナーの使用方法について詳しくは、次の記事をご覧ください。