適用対象:  Python SDK azure-ai-ml v2 (現行)
Python SDK azure-ai-ml v2 (現行)
このチュートリアルでは、次の操作を行います。
- クラウド ストレージにデータをアップロードする
- Azure Machine Learning データ資産を作成する
- 対話型開発のためにノートブック内のデータにアクセスする
- データ資産の新しいバージョンを作成する
機械学習プロジェクトは、通常、探索的データ分析 (EDA)、データの前処理 (クリーニング、特徴エンジニアリング)、および仮説を検証するための機械学習モデルプロトタイプの構築から始まります。 この プロトタイプ 作成プロジェクト フェーズは非常に対話型であり、 Python 対話型コンソールを使用した IDE または Jupyter ノートブックでの開発に役立ちます。 このチュートリアルでは、これらの概念について説明します。
前提条件
-
Azure Machine Learning を使用するには、ワークスペースが必要です。 まだない場合は、作業を開始するために必要なリソースの作成を完了し、ワークスペースを作成してその使用方法の詳細を確認してください。
重要
Azure Machine Learning ワークスペースがマネージド仮想ネットワークを使用して構成されている場合、パブリック Python パッケージ リポジトリへのアクセスを許可するアウトバウンド規則の追加が必要になることがあります。 詳細については、「シナリオ: パブリック機械学習パッケージにアクセスする」を参照してください。
-
スタジオにサインインして、ワークスペースを選択します (まだ開いていない場合)。
-
ワークスペースでノートブックを開くか作成します。
- コードをコピーしてセルに貼り付ける場合は、新しいノートブックを作成します。
- または、スタジオの [サンプル] セクションから tutorials/get-started-notebooks/explore-data.ipynb を開きます。 次に、[複製] を選択してノートブックを [ファイル] に追加します サンプル ノートブックを見つけるには、「サンプル ノートブックから学習する」を参照してください。
カーネルを設定して Visual Studio Code (VS Code) で開く
コンピューティング インスタンスがまだない場合は、開いているノートブックの最上部のバーで作成します。

コンピューティング インスタンスが停止している場合は、[コンピューティングの開始] を選択して、実行されるまで待ちます。

コンピューティング インスタンスが実行中になるまで待ちます。 次に、右上にあるカーネルが
Python 3.10 - SDK v2であることを確認します。 そうでない場合は、ドロップダウン リストを使用してこのカーネルを選択します。
このカーネルが表示されない場合は、コンピューティング インスタンスが実行中であることを確認します。 そうである場合は、ノートブックの右上にある [更新] ボタンを選択します。
認証が必要であることを示すバナーが表示された場合は、[認証] を選択します。
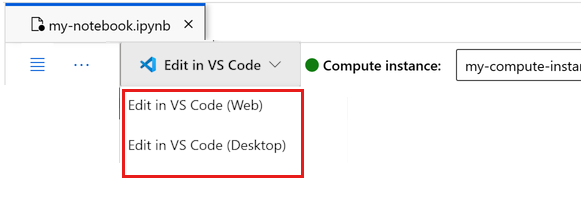
ここでノートブックを実行するか、それを VS Code で開いて、Azure Machine Learning リソースの機能を備えた完全な統合開発環境 (IDE) を使用することができます。 [VS Code で開く] を選択し、Web またはデスクトップのオプションを選択します。 この方法で起動すると、コンピューティング インスタンス、カーネル、ワークスペース ファイル システムに VS Code がアタッチされます。




重要
このチュートリアルの残りの部分には、チュートリアル ノートブックのセルが含まれています。 それらをコピーして新しいノートブックに貼り付けるか、複製した場合はここでそのノートブックに切り替えます。
このチュートリアルで使用するデータをダウンロードする
データ インジェストの場合、Azure Data Explorer はこれらの 形式で生データを処理します。 このチュートリアルでは、 CSV 形式のクレジット カード クライアント データ サンプルを使用します。 この手順は、Azure Machine Learning リソースで行われます。 そのリソースでは、このノートブックが配置されているフォルダーのすぐ下に、 推奨されるデータ名を持つローカル フォルダーを作成します。
Note
このチュートリアルは、Azure Machine Learning リソース フォルダーの場所に配置されたデータに依存します。 このチュートリアルでは、"local" とは、その Azure Machine Learning リソース内のフォルダーの場所を意味します。
こちらの図に示すように、3 つのドットの下にある [ターミナルを開く] を選択します。
![ノートブック ツール バーの [ターミナルを開く] ツールを示すスクリーンショット。](media/tutorial-cloud-workstation/open-terminal.png?view=azureml-api-2)
ターミナル ウィンドウが新しいタブで開きます。
ディレクトリ (
cd) を、このノートブックが配置されているのと同じフォルダーに変更してください。 たとえば、ノートブックが get-started-notebooks という名前のフォルダーにある場合は、次のようになります。cd get-started-notebooks # modify this to the path where your notebook is locatedターミナル ウィンドウにこちらのコマンドを入力して、データをコンピューティング インスタンスにコピーします。
mkdir data cd data # the subfolder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvこれで、ターミナル ウィンドウを終了できます。
UC Irvine Machine Learning Repository のデータの詳細については、このリソースを参照してください。
ワークスペースへのハンドルを作成する
コードを調べる前に、ワークスペースを参照する方法が必要です。 ワークスペースのハンドルとして ml_client を作成します。 その後、ml_client を使用してリソースとジョブを管理します。
次のセルに、サブスクリプション ID、リソース グループ名、ワークスペース名を入力します。 これらの値を見つけるには:
- 右上にある Azure Machine Learning スタジオ ツール バーで、ワークスペース名を選びます。
- ワークスペース、リソース グループ、サブスクリプション ID の値をコードにコピーします。
- 各値は、一度に 1 つずつ個別にコピーする必要があります。 領域を閉じ、値を貼り付けて、次の領域に進みます。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Note
MLClient を作成しても、ワークスペースに接続されません。 クライアントの初期化は遅延型なので、初めて呼び出す必要が生じるときまで待機します。 これは、次のコード セルで発生します。
クラウド ストレージにデータをアップロードする
Azure Machine Learning では、クラウド内のストレージの場所を指す Uniform Resource Identifier (URI) を使用します。 URI を使用すると、ノートブックやジョブのデータに簡単にアクセスできます。 データ URI 形式は、Web ブラウザーで Web ページにアクセスするために使用する Web URL に似ています。 次に例を示します。
- パブリック https サーバーからデータにアクセスする:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Azure Data Lake Gen 2 からデータにアクセスする:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Azure Machine Learning データ資産は、Web ブラウザーのブックマーク (お気に入り) に似ています。 最も頻繁に使用されるデータを指す長いストレージ パス (URI) を記憶する代わりに、データ資産を作成し、フレンドリ名でその資産にアクセスできます。
データ資産を作成すると、データ ソースの場所への ''参照'' とそのメタデータのコピーも作成されます。 データは既存の場所に残るため、追加のストレージ コストは発生せず、データ ソースの整合性を危険にさらすことはありません。 Azure Machine Learning データストア、Azure Storage、パブリック URL、ローカル ファイルからデータ資産を作成できます。
ヒント
データのアップロードを小さくする場合、Azure Machine Learning データ資産の作成は、ローカル コンピューター リソースからクラウド ストレージにデータをアップロードする場合に適しています。 この方法により、追加のツールやユーティリティが不要になります。 ただし、データのアップロードが大きい場合は、専用のツールまたはユーティリティ ( azcopy など) が必要になる場合があります。 AzCopy コマンドライン ツールを使用して、Azure Storage との間でデータを移動します。 azcopy の詳細については、「 AzCopy の概要」を参照してください。
次のノートブック セルでは、データ資産を作成します。 このコード サンプルを使用すると、指定されたクラウド ストレージ リソースに生データ ファイルがアップロードされます。
データ資産の作成ごとに、一意のバージョンが必要です。 バージョンが既に存在する場合は、エラーが発生します。 このコードでは、データの最初の読み取りに "initial" を使用します。 そのバージョンが既に存在する場合、コードでは再作成されません。
また、version パラメーターは省略することもできます。 この場合、バージョン番号が自動的に生成され、1 から始まり、そこからインクリメントされます。
このチュートリアルでは、最初のバージョンとして "initial" という名前を使用します。 実稼働機械学習パイプラインの作成チュートリアルでは、このバージョンのデータも使用するため、そのチュートリアルでもう一度表示される値を使用します。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# Update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# Set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
アップロードしたデータを調べるには、左側のナビゲーション メニューの [資産] セクションで [データ] を選択します。 データがアップロードされ、データ資産が作成されます。
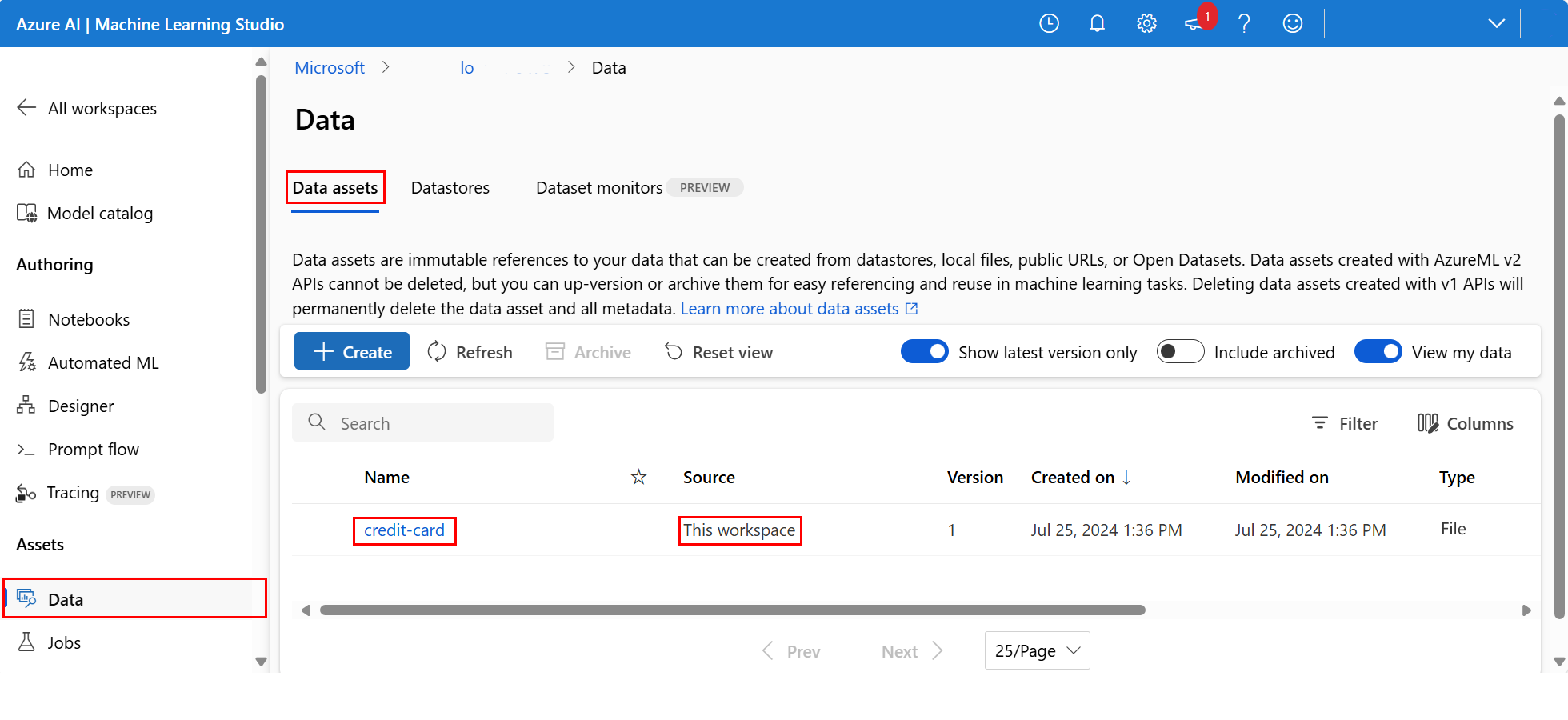
このデータは クレジット カードという名前です。 [ データ資産 ] タブの [名前 ] 列に表示されます。
Azure Machine Learning データストアは、Azure 上の "既存の" ストレージ アカウントへの "参照" です。 データストアには、これらのベネフィットがあります。
さまざまなストレージの種類と対話するための一般的で使いやすい API:
- Azure Data Lake Storage
- BLOB
- Files
と認証方法。
チームとして作業するときに便利なデータストアを見つけやすくする方法です。
スクリプト内で、資格情報ベースのデータ アクセス (サービス プリンシパル、SAS、キー) の接続情報を非表示にする方法。
ノートブック内のデータにアクセスする
頻繁にアクセスされるデータのデータ資産を作成する場合。 「データストア URI からデータにアクセスする」の説明に従って、 ファイル システムの場合と同様に、URI を使用してデータにアクセスできます。 ただし、前述のように、これらの URI を覚えにくくなる可能性があります。
別の方法として、azure Machine Learning データストアのファイル システム インターフェイスを提供する azureml-fsspec ライブラリを使用することもできます。 これは Pandas の CSV ファイルに簡単にアクセスする方法です。
重要
ノートブック セルで、このコードを実行して、Jupyter カーネルに azureml-fsspec Python ライブラリをインストールします。
%pip install -U azureml-fsspec
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# Read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
ノートブック内のデータ アクセスの詳細については、「 対話型開発時に Azure クラウド ストレージからデータにアクセスする」を参照してください。
データ資産の新しいバージョンを作成する
データには、機械学習モデルのトレーニングに適した簡易クリーニングが必要です。 次の特徴があります。
- 2 つのヘッダー
- 機械学習の機能として使用されないクライアント ID 列
- 応答変数名のスペース
また、CSV 形式と比較して、Parquet ファイル形式は、このデータを格納する優れた方法です。 Parquet は圧縮を提供し、スキーマを維持します。 データをクリーンアップし、Parquet 形式で格納するには:
# Read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# Rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# Remove ID column
df.drop("ID", axis=1, inplace=True)
# Write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
次の表は、前の手順でダウンロードした元の default_of_credit_card_clients.csv ファイル内のデータの構造を示しています。 アップロードされたデータには、次に示すように、23 個の説明変数と 1 つの応答変数が含まれています。
| 列名 | 変数の型 | 説明 |
|---|---|---|
| X1 | 説明 | 特定のクレジットの金額 (NT ドル): 個々の消費者のクレジットとその家族 (補足) クレジットの両方が含まれます。 |
| X2 | 説明 | 性別 (1 = 男性、2 = 女性)。 |
| X3 | 説明 | 学歴 (1 = 大学院、2 = 大学、3 = 高校、4 = その他)。 |
| X4 | 説明 | 配偶者の有無 (1 = 既婚、2 = 独身、3 = その他)。 |
| X5 | 説明 | 年齢 (歳)。 |
| X6-X11 | 説明 | 過去の支払い履歴。 2005 年 4 月から 9 月までの過去の月次支払記録。 -1 = 正常な支払い、1 = 1 か月の支払遅延、2 = 2 か月の支払遅延、. . .、8 = 8 か月の支払遅延、9 = 9 か月以上の支払遅延。 |
| X12-17 | 説明 | 2005 年 4 月から 9 月までの請求明細書の金額 (NT ドル)。 |
| X18-23 | 説明 | 2005 年 4 月から 9 月までの以前の支払額 (NT ドル)。 |
| Y | Response | 既定の支払い (はい = 1、いいえ = 0) |
次に、データ資産の新しい バージョン を作成します。 データは自動的にクラウド ストレージにアップロードされます。 このバージョンでは、このコードを実行するたびに異なるバージョン番号が作成されるように、時間値を追加します。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new version of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
クリーンアップされた Parquet ファイルは、最新バージョンのデータ ソースです。 こちらのコードは、CSV バージョンの結果セットを最初に示し、次に Parquet バージョンを示します。
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# Print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# Print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
リソースをクリーンアップする
引き続き他のチュートリアルに取り組む場合は、「次のステップ」に進んでください。
コンピューティング インスタンスを停止する
ここで使用する予定がない場合は、コンピューティング インスタンスを停止します。
- スタジオの左側のウィンドウで、[ コンピューティング] を選択します。
- 上部のタブで、[コンピューティング インスタンス] を選択 します。
- 一覧からコンピューティング インスタンスを選択します。
- 上部のツールバーで、[停止] を選択します。
すべてのリソースの削除
重要
作成したリソースは、Azure Machine Learning に関連したその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
作成したどのリソースも今後使用する予定がない場合は、課金が発生しないように削除します。
Azure portal の検索ボックスに「リソース グループ」と入力し、それを結果から選択します。
一覧から、作成したリソース グループを選択します。
[概要] ページで、[リソース グループの削除] を選択します。
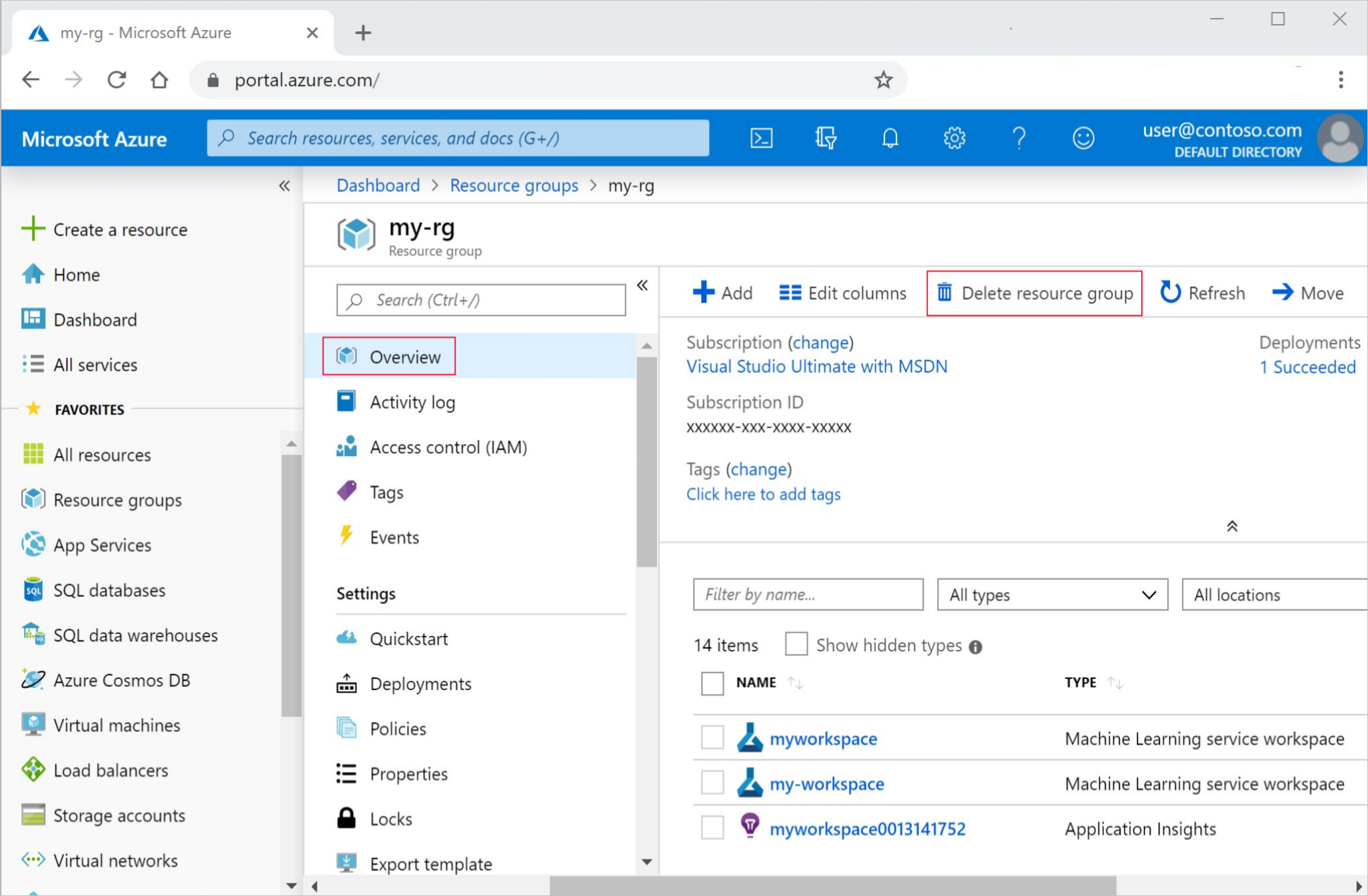
リソース グループ名を入力します。 次に、[削除] を選択します。
次のステップ
データ資産の詳細については、「データ資産の 作成」を参照してください。
データストアの詳細については、「データストアの 作成」を参照してください。
次のチュートリアルに進み、トレーニング スクリプトを開発する方法を学習してください。