Azure Managed Instance for Apache Cassandra では、マネージド オープンソースの Apache Cassandra データセンターに対して、デプロイとスケーリングの自動化された操作を提供します。 この機能により、ハイブリッド シナリオが高速化され、継続的なメンテナンスの削減に役立ちます。
このクイックスタートでは、Azure portal を使用して、Azure Managed Instance for Apache Cassandra クラスターの Azure 仮想ネットワーク内にフル マネージド Apache Spark クラスターを作成する方法について説明します。 Spark クラスターは Azure Databricks で作成します。 その後、そのクラスターにノートブックを作成 (アタッチ) し、さまざまなデータ ソースのデータを読み取って分析情報を得ます。
Azure 仮想ネットワークへの Azure Databricks のデプロイ (仮想ネットワークインジェクション) の詳細な手順を参照することもできます。
前提条件
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
Azure Databricks クラスターを作成する
Azure Managed Instance for Apache Cassandra を持つ仮想ネットワークに Azure Databricks クラスターを作成するには、次の手順に従います。
Azure portal にサインインします。
左側のウィンドウで、 リソース グループを見つけます。 マネージド インスタンスがデプロイされている仮想ネットワークを含むリソース グループに移動します。
仮想ネットワーク リソースを開き、アドレス空間を書き留めます。
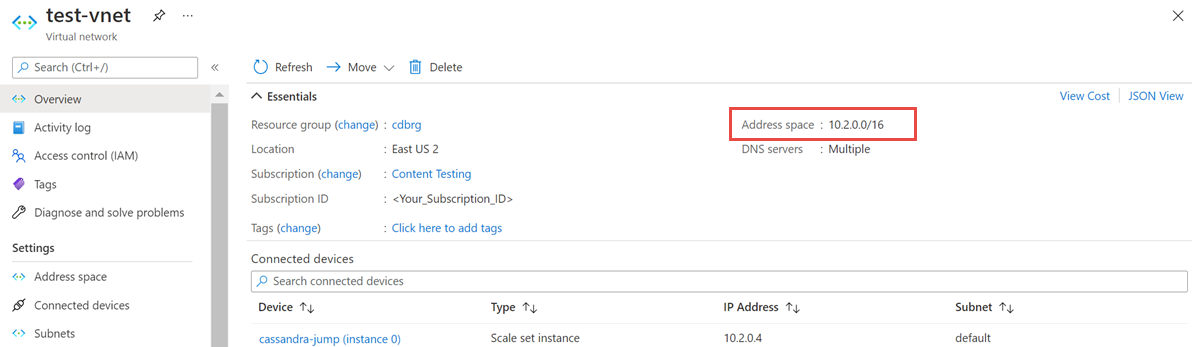
リソース グループから、[ 追加 ] を選択し、検索フィールドで Azure Databricks を検索します。
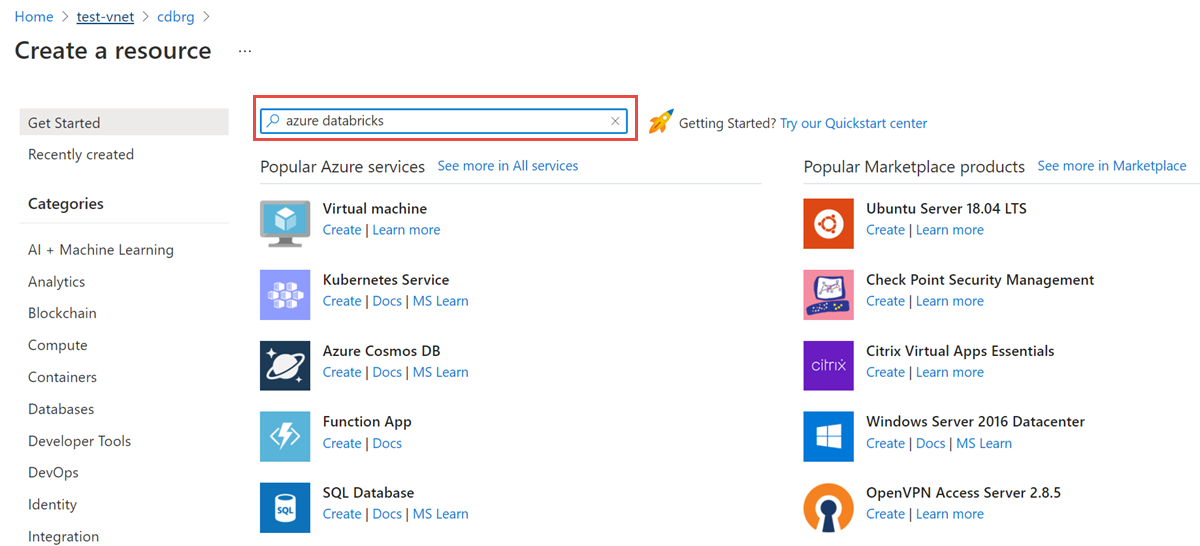
[ 作成] を選択して Azure Databricks アカウントを作成します。
![[作成] が選択された Azure Databricks オファリングを示すスクリーンショット。](media/deploy-cluster-databricks/databricks-create.png)
次の値を入力します。
- ワークスペース名: Azure Databricks ワークスペースの名前を指定します。
- リージョン: 仮想ネットワークと同じリージョンを選択してください。
- 価格レベル: Standard、 Premium、または 試用版を選択します。 これらのレベルの詳細については、 Azure Databricks の価格に関するページを参照してください。
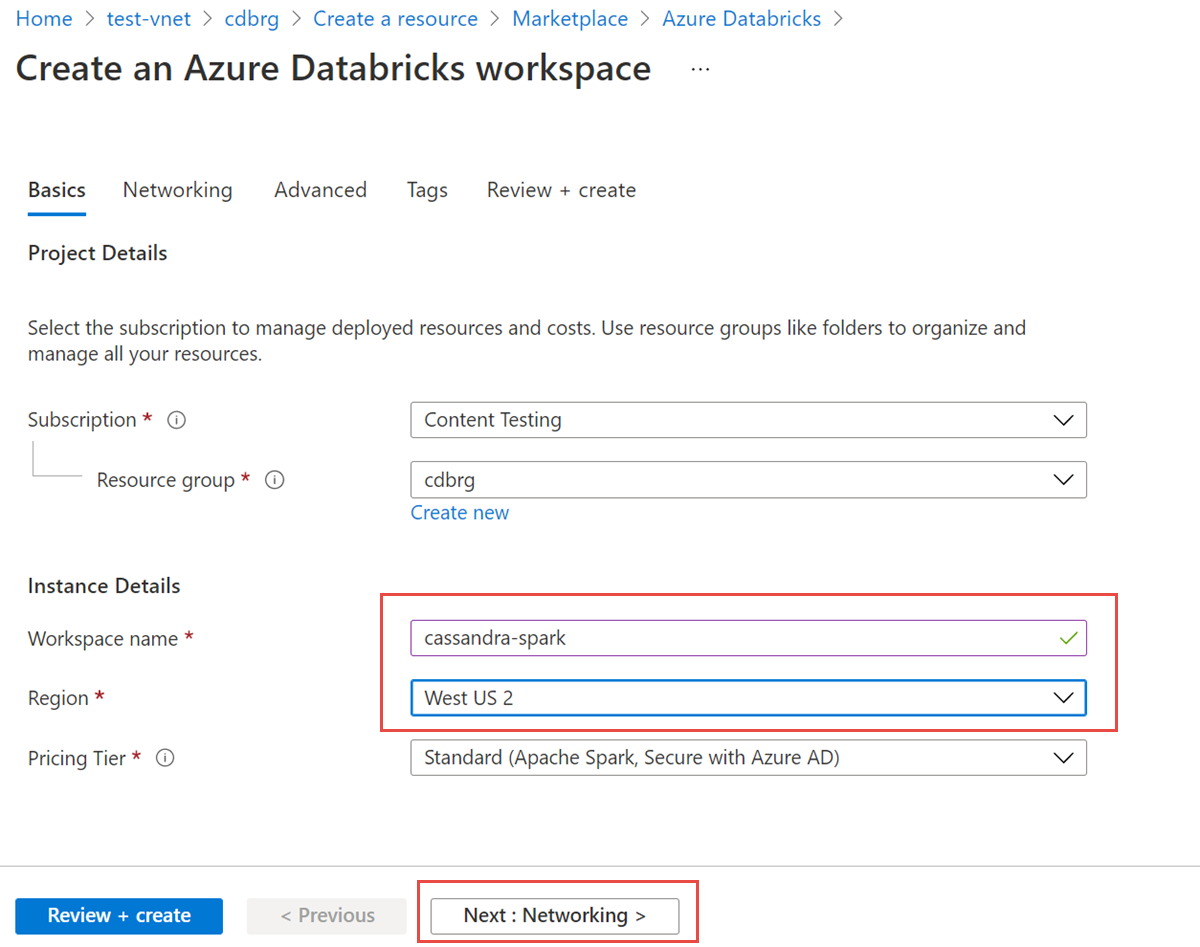
[ネットワーク] タブ を 選択し、次の詳細を入力します。
- 仮想ネットワーク (VNet) に Azure Databricks ワークスペースをデプロイする: [はい] を選択します。
- 仮想ネットワーク: ドロップダウン リストから、マネージド インスタンスが存在する仮想ネットワークを選択します。
- パブリック サブネット名: パブリック サブネットの名前を入力します。
- パブリック サブネット CIDR 範囲: パブリック サブネットの IP 範囲を入力します。
- プライベート サブネット名: プライベート サブネットの名前を入力します。
- プライベート サブネット CIDR 範囲: プライベート サブネットの IP 範囲を入力します。
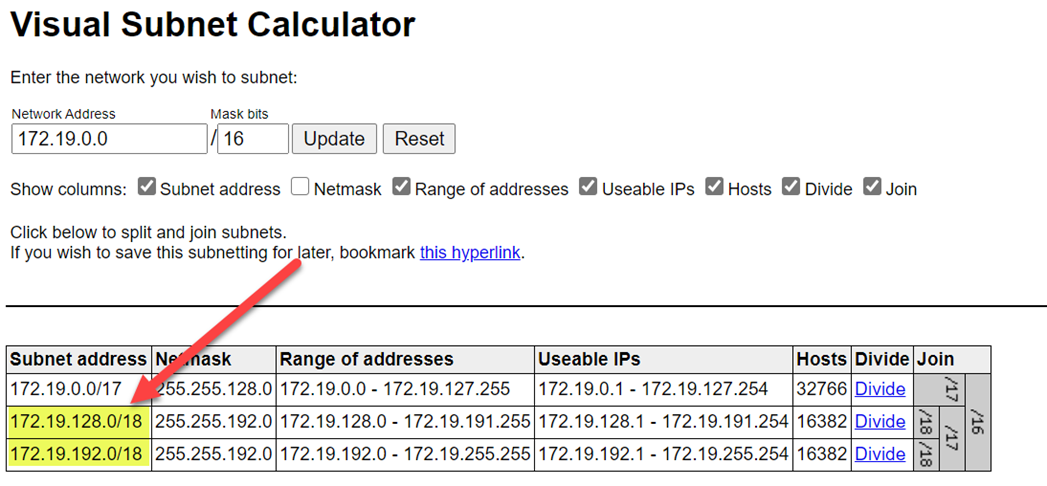
範囲の競合を防ぐために、選択する範囲は大きくするようにしてください。 必要に応じて、 ビジュアル サブネット計算ツール を使用して範囲を分割します。
次のスクリーンショットは、ネットワーク ウィンドウの詳細の例を示しています。
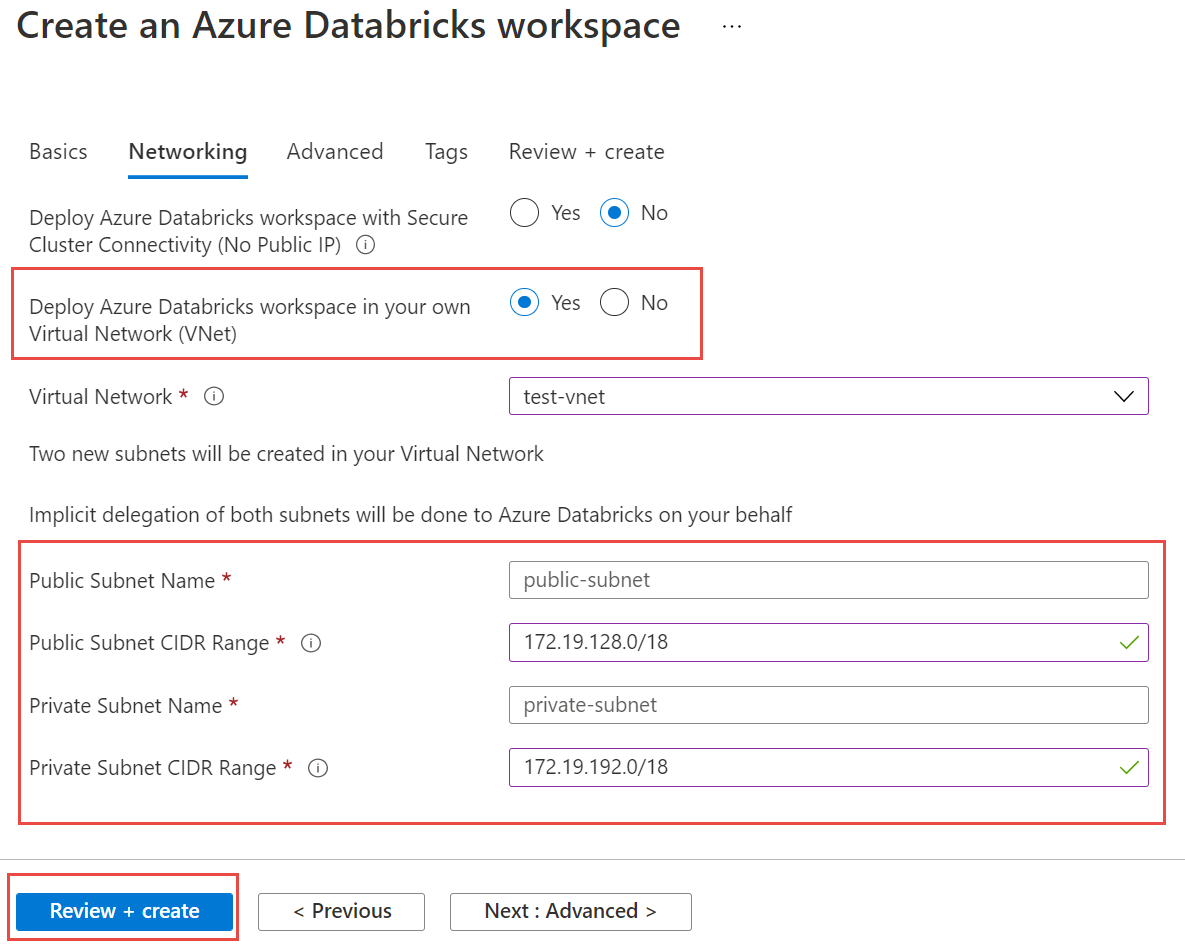
[ 確認と作成] を選択し、[ 作成 ] を選択してワークスペースをデプロイします。
ワークスペースが作成されたら、ワークスペースを開きます。
Azure Databricks ポータルにリダイレクトされます。 ポータルで [New Cluster](新しいクラスター) を選択します。
[ 新しいクラスター ] ウィンドウで、次のフィールド以外のすべてのフィールドの既定値をそのまま使用します。
- クラスター名: クラスターの名前を入力します。
- Databricks ランタイム バージョン: Spark 3.x のサポートには、Azure Databricks ランタイム バージョン 7.5 以降を選択することをお勧めします。
![Azure Databricks ランタイム バージョンが選択された [新しいクラスター] ダイアログ ボックスを示すスクリーンショット。](../reusable-content/ce-skilling/azure/media/cosmos-db/databricks-runtime.png)
[ 詳細オプション] を展開し、次の構成を追加します。 ノード IP と資格情報は必ず置き換えてください。
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueApache Spark Cassandra コネクタ ライブラリをクラスターに追加して、ネイティブと Azure Cosmos DB Cassandra 両方のエンドポイントに接続します。 クラスターで[ライブラリ]>[新規インストール>Maven]を選択し、[Maven
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0(Maven 座標\) フィールドにを追加します。
[インストール] を選択します。
リソースをクリーンアップする
このマネージド インスタンス クラスターを引き続き使用しない場合は、次の手順に従って削除します。
- Azure portal の左側のメニューにある [リソース グループ] を選択します。
- 一覧から、このクイック スタート用に作成したリソース グループを選択します。
- リソース グループの [概要] ペインで、 [リソース グループの削除] を選択します。
- 次のウィンドウで、削除するリソース グループの名前を入力し、[削除] を選択 します。
次のステップ
このクイック スタートでは、Azure Managed Instance for Apache Cassandra クラスターの仮想ネットワーク内にフル マネージド Apache Spark クラスターを作成する方法について説明しました。 次に、クラスターとデータセンターのリソースを管理する方法について説明します。