この記事では、Azure Red Hat OpenShift で NVIDIA GPU ワークロードを使用する方法について説明します。
[前提条件]
- OpenShift CLI
- jq、moreutils、gettext パッケージ
- Azure Red Hat OpenShift 4.10
クラスターをインストールする必要がある場合は、「 チュートリアル: Azure Red Hat OpenShift 4 クラスターを作成する」を参照してください。 クラスターはバージョン 4.10.x 以降である必要があります。
注
4.10 の時点で、NVIDIA オペレーターを使用する権利を設定する必要はなくなりました。 これにより、GPU ワークロードに対するクラスターのセットアップが大幅に簡素化されました。
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
GPU クォータを要求する
Azure のすべての GPU クォータは、既定で 0 です。 Azure portal にサインインし、GPU クォータを要求する必要があります。 GPU ワーカーの競合により、実際に GPU を予約できるリージョンにクラスターをプロビジョニングしなければならない場合があります。
次の GPU ワーカーがサポートされています。
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
追加の MachineSet では、次のインスタンスもサポートされています。
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
注
クォータを要求する場合は、Azure がコア ベースであることに注意してください。 単一の NC4as T4 v3 ノードを要求するには、4 つずつのグループでクォータを要求する必要があります。 NC16as T4 v3 を要求する場合は、16 のクォータを要求する必要があります。
Azure ポータルにサインインします。
検索ボックスに「クォータ」と入力し、[コンピューティング] を選択します。
検索ボックスに「NCAsv3_T4」と入力し、クラスターが含まれているリージョンのボックスにチェック・マークを付けてから、[クォータの増加を要求する] を選択します。
クォータを構成します。
![Azure portal の [クォータ] ページのスクリーンショット。](media/howto-gpu-workloads/gpu-quota-azure.png)
クラスターにサインインする
クラスター管理特権があるユーザー アカウントで OpenShift にサインインします。 次の例では、kubadmin という名前のアカウントを使用します。
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
プル シークレット (条件付き)
プル シークレットを更新して、オペレーターをインストールして cloud.redhat.com に接続できることを確認します。
注
cloud.redhat.com が有効になっているプル シークレット全体を既に再作成している場合は、この手順をスキップしてください。
cloud.redhat.com にログインします。
https://cloud.redhat.com/openshift/install/azure/aro-provisioned にアクセスしてください。
[Download pull secret] (プル シークレットのダウンロード) を選択し、プル シークレットを
pull-secret.txtとして保存します。重要
このセクションの残りの手順は、
pull-secret.txtと同じ作業ディレクトリで実行する必要があります。既存のプル シークレットをエクスポートします。
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonダウンロードしたプル シークレットをシステムのプル シークレットとマージして
cloud.redhat.comを追加します。jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.json新しいシークレット ファイルをアップロードします。
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonすべてが cloud.redhat.com と同期するまで、約 1 時間待つ必要がある場合があります。
シークレットを削除します。
rm pull-secret.txt export-pull.json new-pull-secret.json
GPU マシン セット
では、Kubernetes MachineSet を使用してマシン セットを作成します。 次の手順では、クラスター内の最初のマシン セットをエクスポートし、それをテンプレートとして使用して単一の GPU マシンを構築する方法について説明します。
既存のマシン セットを表示します。
セットアップを容易にするために、この例では、最初のマシン セットを、新しい GPU マシン セットを作成するために複製するマシン セットとして使用します。
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')サンプルのマシン セットのコピーを保存します。
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.json.metadata.nameフィールドを新しい一意の名前に変更します。jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonspec.replicasがマシン セットに必要なレプリカ数と一致していることを確認します。jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.json.spec.selector.matchLabels.machine.openshift.io/cluster-api-machinesetフィールドと一致するように.metadata.nameフィールドを変更します。jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.json.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetフィールドと一致するように.metadata.nameを変更します。jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonAzure からの目的の GPU インスタンスの種類に一致するように
spec.template.spec.providerSpec.value.vmSizeを変更します。この例で使用するマシンは Standard_NC4as_T4_v3 です。
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonAzure からの目的のゾーンに一致するように
spec.template.spec.providerSpec.value.zoneを変更します。jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonyaml ファイルの
.statusセクションを削除します。jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonyaml ファイル内の他のデータを確認します。
正しい SKU を確実に設定する
マシン セットに使用されるイメージに応じて、image.sku と image.version の両方の値を適宜設定する必要があります。 これは、Hyper-V の第 1 または第 2 世代の仮想マシンが確実に使用されるようにするためです。 詳細については、の を参照してください。
例:
Standard_NC4as_T4_v3 を使用している場合は、両方のバージョンがサポートされます。 「機能サポート」の中に記載されているとおりです。 この場合、変更は必要ありません。
Standard_NC24ads_A100_v4 を使用している場合は、第 2 世代 VM のみがサポートされます。
この場合、image.sku の値はクラスターの元の v2 に対応するイメージの同等の image.sku バージョンに従う必要があります。 この例では、その値は v410-v2 になります。
これは、次のコマンドを使用して確認できます。
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
クラスターがベース SKU イメージ aro_410 を使用して作成され、かつ同じ値がマシン セット内に保持されている場合、次のエラーで失敗します。
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
GPU マシン セットを作成する
新しい GPU マシンを作成するには、次の手順に従います。 新しい GPU マシンのプロビジョニングには、10 分から 15 分かかる場合があります。 この手順が失敗した場合は、Azure portal にサインインし、可用性に関する問題がないことを確認してください。 これを行うには、Virtual Machines に移動し、前に作成したワーカー名を検索して VM の状態を表示します。
GPU マシン セットを作成します。
oc create -f gpu_machineset.jsonこのコマンドが完了するまでに数分かかります。
GPU マシン セットを確認します。
マシンがデプロイ中である必要があります。 次のコマンドを使用して、マシン セットの状態を表示できます。
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiマシンがプロビジョニングされると (5 分から 15 分かかる場合があります)、マシンはノード一覧にノードとして表示されます。
oc get nodes前に作成した、
nvidia-worker-southcentralus1という名前のノードが表示されます。
NVIDIA GPU オペレーターをインストールする
このセクションでは、nvidia-gpu-operator 名前空間を作成し、オペレーター グループを設定し、NVIDIA GPU オペレーターをインストールする方法について説明します。
NVIDIA 名前空間を作成します。
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFオペレーター グループを作成します。
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOF次のコマンドを使用して、最新の NVIDIA チャネルを取得します。
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
注
クラスターがプル シークレットを指定せずに作成された場合、クラスターには Red Hat や認定パートナーから得られるサンプルや演算子が含まれません。 この結果として、次のエラー メッセージが表示される場合があります。
サーバーからのエラー (NotFound): packagemanifests.packages.operators.coreos.com "gpu-operator-certified" が見つかりません。
Red Hat プル シークレットを Azure Red Hat OpenShift クラスターで追加するには、このガイドラインに従ってください。
次のコマンドを使用して、最新の NVIDIA パッケージを取得します。
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')サブスクリプションを作成します。
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFオペレーターのインストールが完了するまで待ちます。
オペレーターのインストールが完了したことを確認するまで続行しないでください。 また、GPU ワーカーがオンラインであることも確認します。
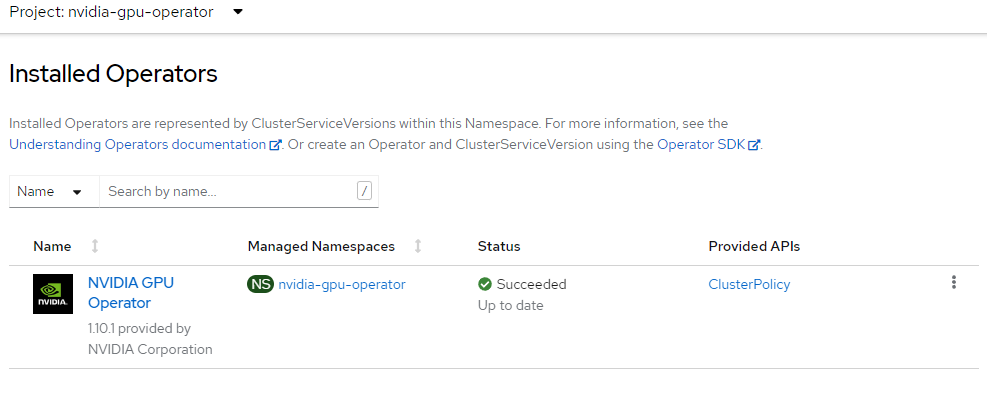
ノード機能検出オペレーターをインストールする
ノード機能検出オペレーターは、ノード上の GPU を検出し、ノードに適切なラベルを付けるので、ワークロードの対象にすることができます。
この例では、NFD オペレーターを openshift-ndf 名前空間にインストールし、NFD の構成である "サブスクリプション" を作成します。
ノード機能検出オペレーターのインストールに関する公式ドキュメント。
Namespaceを設定します。cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFOperatorGroupを作成します。cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFSubscriptionを作成します。cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFノード機能の検出がインストールを完了するまで待ちます。
OpenShift コンソールにログインしてオペレーターを表示するか、単に数分待つことができます。 オペレーターのインストールを待機しないと、次の手順でエラーが発生します。
NFD インスタンスを作成します。
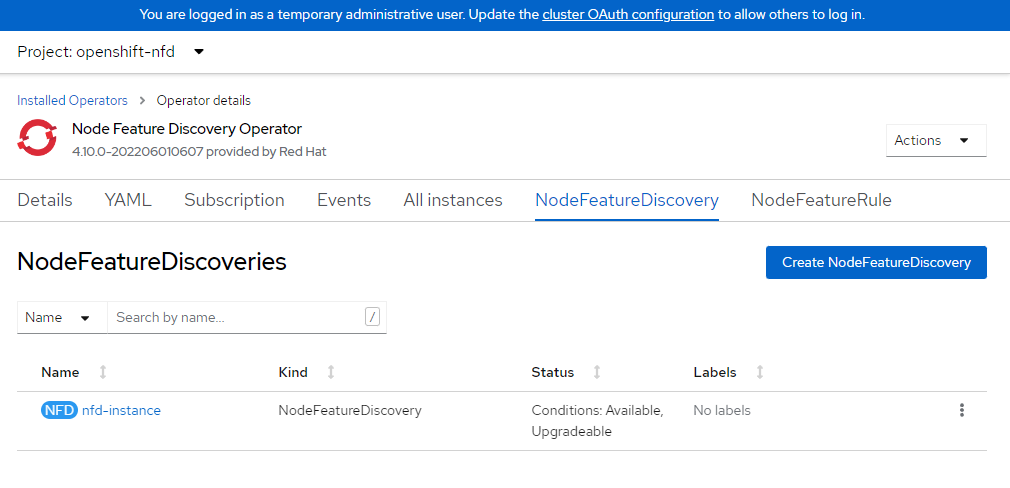
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFNFD の準備ができていることを確認します。
このオペレーターの状態は [使用可能] と表示されます。
NVIDIA クラスター構成を適用する
このセクションでは、NVIDIA クラスター構成を適用する方法について説明します。独自のプライベート リポジトリまたは特定の設定がある場合は、これをカスタマイズする方法に関する NVIDIA ドキュメントを参照してください。 このプロセスの完了には数分かかる場合があります。
クラスター構成を適用します。
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFクラスター ポリシーを確認します。
OpenShift コンソールにログインし、オペレーターを参照します。
nvidia-gpu-operator名前空間が表示されていることを確認します。State: Ready once everything is completeと示されるはずです。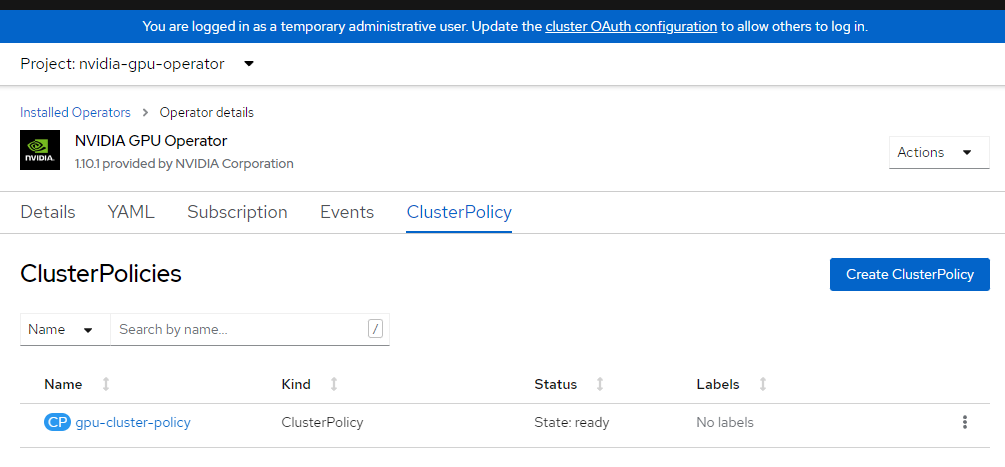
GPU を検証する
NVIDIA オペレーターと NFD が完全にインストールされ、マシンを自己識別するのに時間がかかる場合があります。 次のコマンドを実行して、すべてが想定どおりに実行されていることを確認してください。
NFD が GPU を表示できることを確認します。
oc describe node | egrep 'Roles|pci-10de' | grep -v master出力は次のようになります。
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueノード ラベルを確認します。
ノード ラベルを表示するには、OpenShift コンソールにログイン -> [コンピューティング] -> [ノード] -> [nvidia-worker-southcentralus1-] に進みます。 上から複数の NVIDIA GPU ラベルと pci-10de デバイスが表示されます。
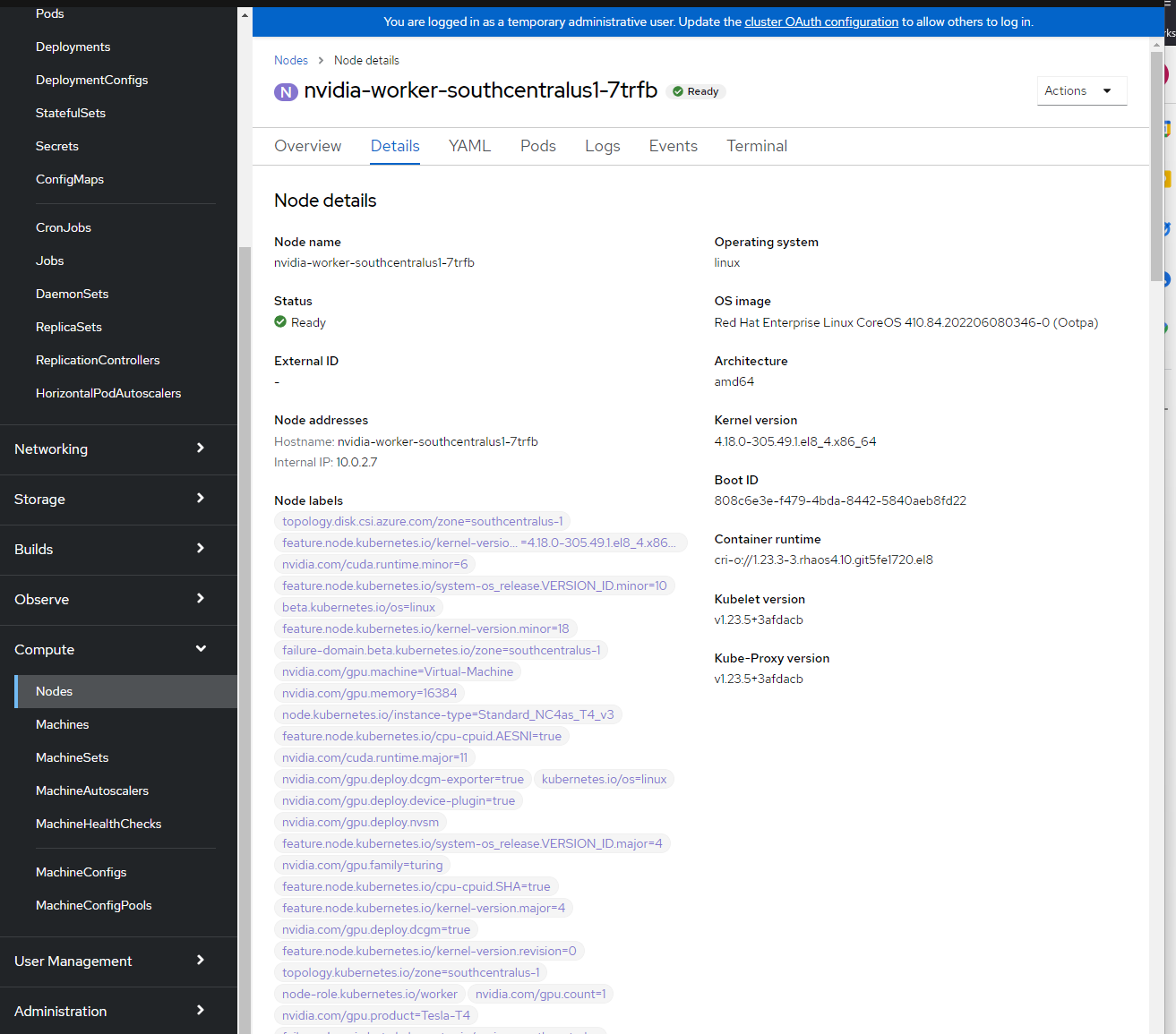
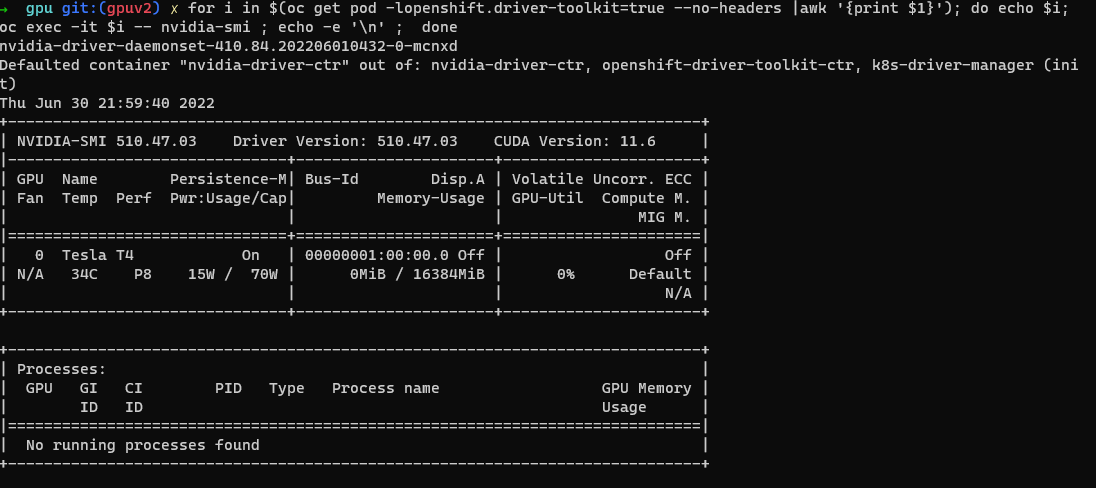
NVIDIA SMI ツールの検証。
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; done次のスクリーンショット例など、ホストで使用可能な GPU を示す出力が表示されます。 (GPU ワーカーの種類によって異なります)
GPU ワークロードを実行するポッドを作成します
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFログを表示します。
oc logs cuda-vector-add --tail=-1
注
エラー Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating が表示された場合は、oc delete pod cuda-vector-add の実行を試みてから、上記の create ステートメントを再実行してください。
出力は次のようになります (GPU によって異なります)。
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
成功した場合は、ポッドを削除できます。
oc delete pod cuda-vector-add