このクイック スタートでは、Azure Batch で Microsoft Planetary Computer Pro GeoCatalog リソースを使用して地理空間データを大規模に処理する方法について説明します。
Azure Batch は、大規模な並列コンピューティングとハイ パフォーマンス コンピューティング (HPC) ワークロードを実行できるクラウドベースのジョブ スケジューリング サービスです。 Azure Batch と Microsoft Planetary Computer Pro を組み合わせることで、次のことができます。
- 複数のコンピューティング ノード間で大量の地理空間データを並列に処理する
- マネージド ID を使用して GeoCatalog API に対して安全に認証する
- ワークロードの需要に基づいて処理能力をスケールアップまたはスケールダウンする
- インフラストラクチャを管理せずに地理空間データ パイプラインを自動化する
このクイック スタートでは、ユーザー割り当てマネージド ID を使用して Batch プールを設定し、GeoCatalog にアクセスするためのアクセス許可を構成し、STAC API にクエリを実行するジョブを実行する方法について説明します。
ヒント
Microsoft Planetary Computer Pro を使用したアプリケーション開発オプションの概要については、データを使用した アプリケーションの接続とビルドに関するページを参照してください。
[前提条件]
開始する前に、このクイックスタートを完了するために次の要件を満たしていることを確認してください。
- アクティブなサブスクリプションを持つ Azure アカウント。 [アカウントの作成] リンク を無料で使用します。
- マイクロソフト プラネタリー コンピューター Pro GeoCatalog リソース。
次のツールがインストールされている Linux マシン。
- Azure CLI
-
perlパッケージ。
Batch アカウントを作成する
リソース グループを作成します。
az group create \
--name spatiobatchdemo \
--location uksouth
ストレージ アカウントを作成します。
az storage account create \
--resource-group spatiobatchdemo \
--name spatiobatchstorage \
--location uksouth \
--sku Standard_LRS
Storage Blob Data Contributorを現在のユーザーにストレージ アカウントに割り当てます。
az role assignment create \
--role "Storage Blob Data Contributor" \
--assignee $(az account show --query user.name -o tsv) \
--scope $(az storage account show --name spatiobatchstorage --resource-group spatiobatchdemo --query id -o tsv)
Batch アカウントを作成します。
az batch account create \
--name spatiobatch \
--storage-account spatiobatchstorage \
--resource-group spatiobatchdemo \
--location uksouth
Von Bedeutung
コンピューター ノードのプールを作成するのに十分なクォータがあることを確認します。 十分なクォータがない場合は、 Azure Batch のクォータと制限 に関するドキュメントの手順に従って、引き上げを要求できます。
次のコマンドを実行して、新しい Batch アカウントにサインインします。
az batch account login \
--name spatiobatch \
--resource-group spatiobatchdemo \
--shared-key-auth
Batch を使用してアカウントを認証すると、このセッションの後続の az batch コマンドで作成した Batch アカウントが使用されます。
ユーザー割り当てマネージド ID を作成します。
az identity create \
--name spatiobatchidentity \
--resource-group spatiobatchdemo
Azure portal を使用してコンピューティング ノードのプールを作成します。
- Azure portal で Batch アカウントに移動し、[ プール] を選択します。
![Azure portal のスクリーンショット。Batch アカウントの [プール] セクションと、プールを追加および管理するためのオプションが表示されています。](media/batch-pools-overview.png)
- [ + 追加] を選択して新しいプールを作成し、プールの ID として [ユーザー割り当て ] を選択します。
![Azure portal のスクリーンショット。[プールの追加] ページを示すスクリーンショット。ユーザーは、ID、オペレーティング システム、VM サイズなど、新しいプールの設定を構成できます。](media/add-batch-pool.png)
- 前に作成したユーザー割り当てマネージド ID を選択します。
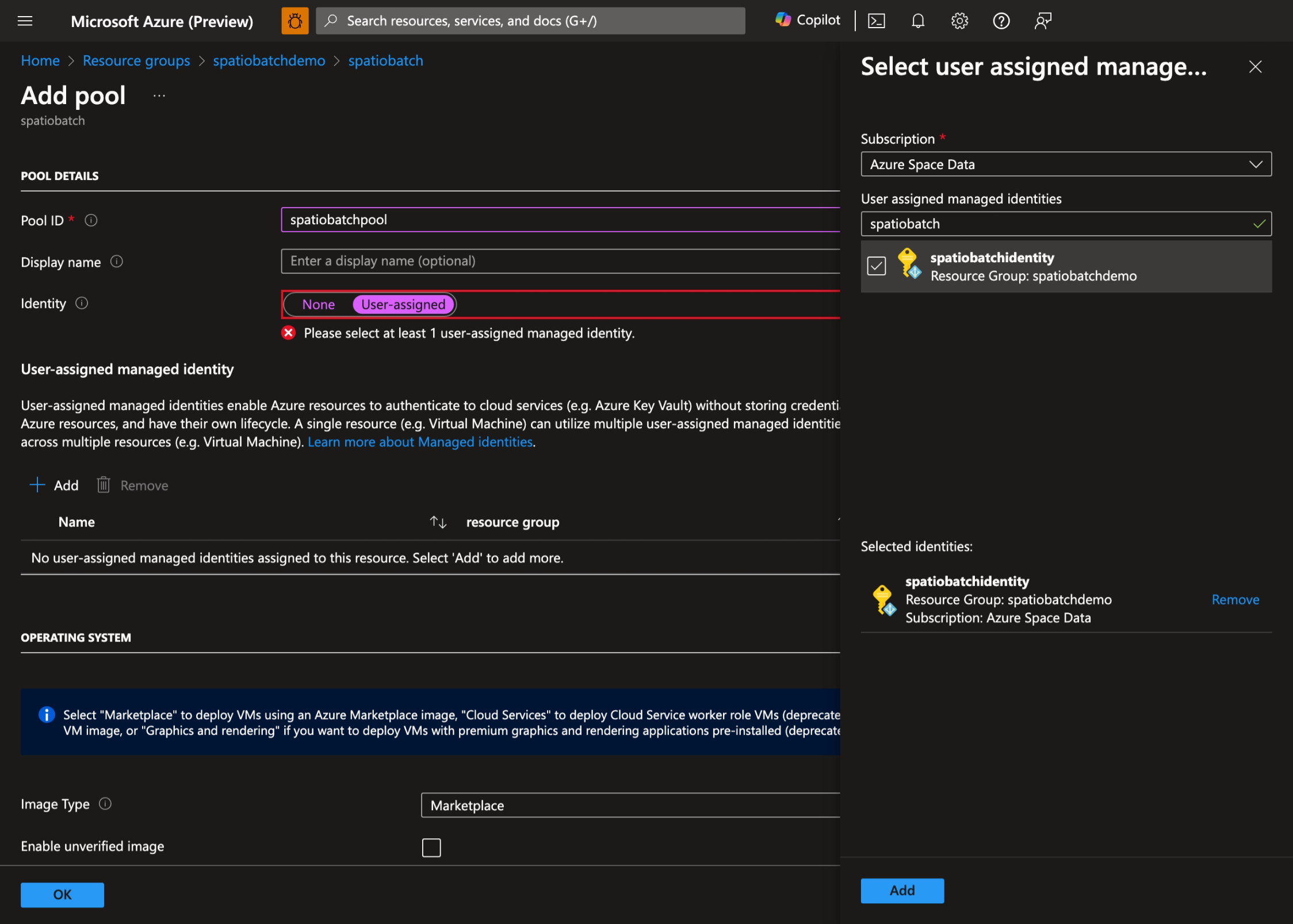
- お好みのオペレーティング システムと VM のサイズを選択します。 このデモでは、Ubuntu Server 20.04 LTS を使用します。
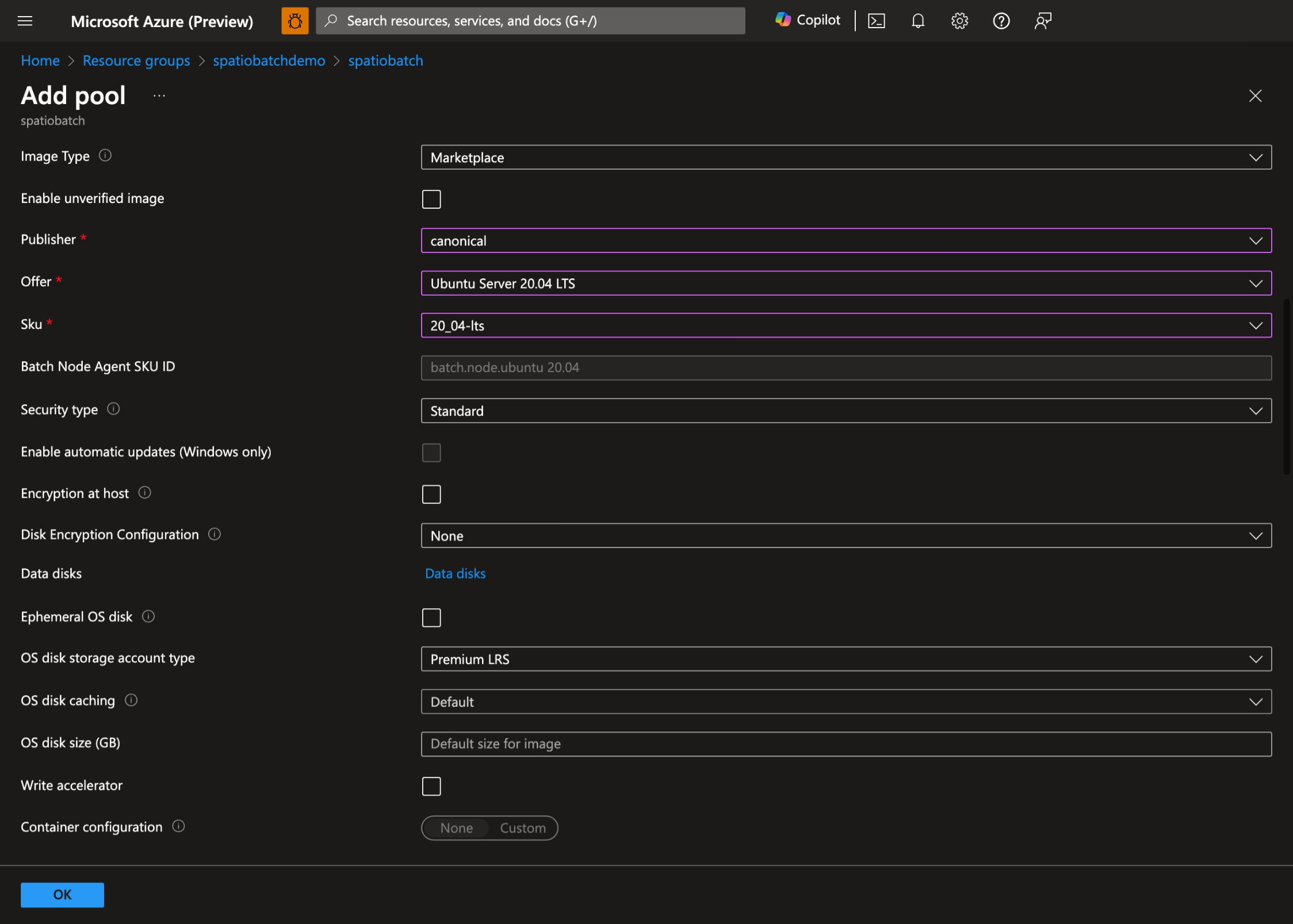
-
[タスクの開始] を有効にし、次のコマンド ラインを設定します。
bash -c "apt-get update && apt-get install jq python3-pip -y && curl -sL https://aka.ms/InstallAzureCLIDeb | bash"し、[昇格レベル] を [プールの自動ユーザー] に設定します。管理者:![Batch プールの [タスクの開始] 構成ページのスクリーンショット。このページには、コマンド ライン スクリプト、昇格レベル、およびコンピューティング ノードを初期化するためのその他の設定を指定するフィールドが含まれています。](media/start-task-configuration-page.png)
- [ OK] を 選択してプールを作成します。
![Azure portal のスクリーンショット。Batch アカウントの [プール] セクションと、プールを追加および管理するためのオプションが表示されています。](media/batch-pools-overview.png#lightbox)
![Azure portal のスクリーンショット。[プールの追加] ページを示すスクリーンショット。ユーザーは、ID、オペレーティング システム、VM サイズなど、新しいプールの設定を構成できます。](media/add-batch-pool.png#lightbox)


![Batch プールの [タスクの開始] 構成ページのスクリーンショット。このページには、コマンド ライン スクリプト、昇格レベル、およびコンピューティング ノードを初期化するためのその他の設定を指定するフィールドが含まれています。](media/start-task-configuration-page.png#lightbox)
マネージド ID にアクセス許可を割り当てる
GeoCatalog へのマネージド ID アクセスを提供する必要があります。 GeoCatalog に移動し、 アクセス制御 (IAM) を選択し、[ ロールの割り当ての追加] を選択します。
![[ロールの割り当ての追加] ページが表示されている Azure portal のスクリーンショット。このページには、ロールを選択し、ユーザー、グループ、またはマネージド ID へのアクセスを割り当て、確認する前に割り当てを確認するためのフィールドが含まれています。](media/add-role-assignment-page.png#lightbox)
ニーズ、 GeoCatalog Administrator 、または GeoCatalog Readerに基づいて適切なロールを選択し、[ 次へ] を選択します。
![[ロールの選択] ページが表示されている Azure portal のスクリーンショット。このページには、GeoCatalog 管理者や GeoCatalog 閲覧者などのロールを選択するためのドロップダウン メニューと、次の手順に進むボタンが含まれています。](media/select-role.png#lightbox)
作成したマネージド ID を選択し、[ 確認と割り当て] を選択します。
![[ID の選択] ページが表示されている Azure portal のスクリーンショット。このページには、使用可能なマネージド ID の一覧が含まれています。これにより、ユーザーは Batch プールに割り当てる ID を選択できます。](media/select-review-assign.png#lightbox)
Batch ジョブを準備する
ストレージ アカウントにコンテナーを作成します。
az storage container create \
--name scripts \
--account-name spatiobatchstorage
スクリプトをコンテナーにアップロードします。
az storage blob upload \
--container-name scripts \
--file src/task.py \
--name task.py \
--account-name spatiobatchstorage
Batch ジョブを実行する
このクイック スタートには、 Python スクリプトと Bash スクリプトの 2 つの例があります。 いずれかを使用してジョブを作成できます。
Python スクリプト タスク
Python スクリプト ジョブを実行するには、次のコマンドを実行します。
geocatalog_url="<geocatalog url>"
token_expiration=$(date -u -d "30 minutes" "+%Y-%m-%dT%H:%M:%SZ")
python_task_url=$(az storage blob generate-sas --account-name spatiobatchstorage --container-name scripts --name task.py --permissions r --expiry $token_expiration --auth-mode login --as-user --full-uri -o tsv)
cat src/pythonjob.json | perl -pe "s,##PYTHON_TASK_URL##,$python_task_url,g" | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
Python ジョブは、次の Python スクリプトを実行します。
import json
from os import environ
import requests
from azure.identity import DefaultAzureCredential
MPCPRO_APP_ID = "https://geocatalog.spatio.azure.com"
credential = DefaultAzureCredential()
access_token = credential.get_token(f"{MPCPRO_APP_ID}/.default")
geocatalog_url = environ["GEOCATALOG_URL"]
response = requests.get(
f"{geocatalog_url}/stac/collections",
headers={"Authorization": "Bearer " + access_token.token},
params={"api-version": "2025-04-30-preview"},
)
print(json.dumps(response.json(), indent=2))
DefaultAzureCredentialを使用してマネージド ID で認証し、GeoCatalog からコレクションを取得します。 ジョブの結果を取得するには、次のコマンドを実行します。
az batch task file download \
--job-id pythonjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Bash ジョブ
Bash スクリプト ジョブを実行するには、次のコマンドを実行します。
geocatalog_url="<geocatalog url>"
cat src/bashjob.json | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
Bash ジョブは、次の Bash スクリプトを実行します。
az login --identity --allow-no-subscriptions > /dev/null
token=$(az account get-access-token --resource https://geocatalog.spatio.azure.com --query accessToken --output tsv)
curl --header \"Authorization: Bearer $token\" $GEOCATALOG_URL/stac/collections | jq
az login --identityを使用してマネージド ID で認証し、GeoCatalog からコレクションを取得します。 ジョブの結果を取得するには、次のコマンドを実行します。
az batch task file download \
--job-id bashjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
関連コンテンツ
- データを使用してアプリケーションを接続して構築する
- Microsoft Planetary Computer Pro のアプリケーション認証を構成する
- Microsoft Planetary Computer Pro を使用して Web アプリケーションを構築する
- Microsoft プラネタリー コンピューター Pro Explorer を使用する
- Microsoft プラネタリー コンピューター Pro へのアクセスを管理する
- Batch プールでマネージド ID を構成する
- アプリケーションとデータをプール ノードにコピーする
- Batch アプリケーション パッケージを使用してコンピューティング ノードにアプリケーションをデプロイする
- リソース ファイルの作成と使用