この記事では、さまざまな Azure リージョンにわたる SAP HANA の可用性に関連するシナリオについて説明します。 Azure リージョン間の距離のため、複数の Azure リージョンで SAP HANA 可用性を設定するには、特別な考慮事項が必要です。
複数の Azure リージョンにデプロイする理由
Azure リージョンは、多くの場合、大きな距離で区切られます。 地政学的リージョンによっては、Azure リージョン間の距離は、米国のように数百マイル、または数千マイルになる場合があります。 距離があるため、2 つの異なる Azure リージョンにデプロイされている資産間のネットワーク トラフィックでは、ネットワークラウンドトリップ待機時間が大幅に発生します。 待機時間は、一般的な SAP ワークロードの下で 2 つの SAP HANA インスタンス間の同期データ交換を除外するのに十分な大きさです。
一方、組織には、多くの場合、プライマリ データセンターの場所とセカンダリ データセンターの間に距離の要件があります。 距離の要件は、地理的に広い場所で自然災害が発生した場合に可用性を提供するのに役立ちます。 例として、2017 年 9 月と 10 月にカリブ海とフロリダを襲ったハリケーンがあります。 組織には、少なくとも最小距離の要件がある場合があります。 ほとんどの Azure のお客様にとって、最小距離の定義では 、Azure リージョン全体の可用性を設計する必要があります。 2 つの Azure リージョン間の距離が大きすぎて HANA 同期レプリケーション モードを使用できないため、RTO と RPO の要件により、可用性構成を 1 つのリージョンにデプロイし、2 つ目のリージョンに追加のデプロイを追加する必要がある場合があります。
このシナリオで考慮すべきもう 1 つの側面は、フェールオーバーとクライアント リダイレクトです。 2 つの異なる Azure リージョンの SAP HANA インスタンス間のフェールオーバーは、常に手動フェールオーバーであると想定されています。 SAP HANA システム レプリケーションのレプリケーション モードは非同期に設定されているため、プライマリ HANA インスタンスでコミットされたデータがセカンダリ HANA インスタンスにまだ作成されていない可能性があります。 そのため、自動フェールオーバーは、レプリケーションが非同期である構成のオプションではありません。 手動で制御されたフェールオーバーの場合でも、フェールオーバーの演習と同様に、プライマリ側のすべてのコミット済みデータがセカンダリ インスタンスに作成されていることを確認してから、他の Azure リージョンに手動で移動する必要があります。
Azure Virtual Network では、異なる IP アドレス範囲が使用されます。 IP アドレスは、2 番目の Azure リージョンにデプロイされます。 そのため、SAP HANA クライアント構成を変更する必要があるか、できれば名前解決を変更する手順を作成する必要があります。 これにより、クライアントは新しいセカンダリ サイトのサーバー IP アドレスにリダイレクトされます。 詳細については、引 き継ぎ後のクライアント接続復旧に関する SAP 記事を参照してください。
2 つの Azure リージョン間の単純な可用性
可用性構成を 1 つのリージョン内に配置しないことを選択できますが、障害が発生した場合でもワークロードを処理する必要があります。 このようなシナリオの一般的なケースは、非運用システムです。 半日または 1 日でもシステムを停止することは持続可能ですが、48 時間以上システムを使用できないようにすることはできません。 セットアップのコストを削減するには、VM で重要度の低い別のシステムを実行します。 もう 1 つのシステムは宛先として機能します。 セカンダリ リージョン内の VM のサイズを小さくし、データを事前に読み込まないこともできます。 フェールオーバーは手動であり、完全なアプリケーション スタックをフェールオーバーするためのさらに多くの手順が必要であるため、VM をシャットダウンしてサイズを変更してから VM を再起動する追加の時間は許容されます。
1 つの VM 内の QA システムと DR ターゲットを共有するシナリオを使用している場合は、次の考慮事項を考慮する必要があります。
- delta_datashippingと logreplay には 2 つの 操作モード があり、このようなシナリオで使用できます。
- どちらの操作モードも、データを事前に読み込まずに異なるメモリ要件を持ちます
- Delta_datashippingは、logreplay が必要とするよりもプリロード オプションなしで必要なメモリが大幅に少なくなる可能性があります。 SAP HANA のシステム レプリケーションを実行する方法に関する SAP ドキュメントの第 4.3 章を参照してください
- プリロードなしの logreplay 操作モードのメモリ要件は決定論的ではなく、読み込まれる列ストア構造によって異なります。 極端なケースでは、プライマリ インスタンスのメモリの% が 50 個必要になる場合があります。 logreplay 操作モードのメモリは、データを事前に読み込むかどうかを選択したかどうかに依存しません。
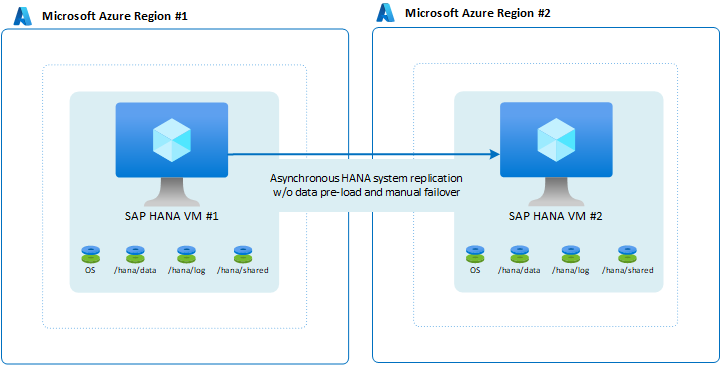
注
この構成では、HANA システム レプリケーション モードが非同期であるため、RPO=0 を指定できません。 RPO=0 を指定する必要がある場合、この構成は選択した構成ではありません。
構成で行うことができる小さな変更は、データを事前読み込みとして構成することです。 ただし、フェールオーバーの手動の性質と、アプリケーション レイヤーも 2 番目のリージョンに移動する必要がある場合は、データをプリロードしても意味がない可能性があります。
1 つのリージョン内およびリージョン間で可用性を組み合わせる
リージョン内とリージョン間の可用性の組み合わせは、次の要因によって推進される場合があります。
- Azure リージョン内の RPO=0 の要件。
- 組織は、大規模な地域に影響を与える大きな自然災害の影響を受けるグローバルな運用を行う気も持てません。 これは、過去数年間にカリブ海を襲った一部のハリケーンの場合です。
- Azure 可用性ゾーンが提供できる範囲を明確に超えるプライマリ サイトとセカンダリ サイト間の距離を要求する規制。
このような場合は、HANA システム レプリケーションを使用して SAP HANA 多層システム レプリケーション構成 と呼ばれるものを設定できます。 アーキテクチャは次のようになります。
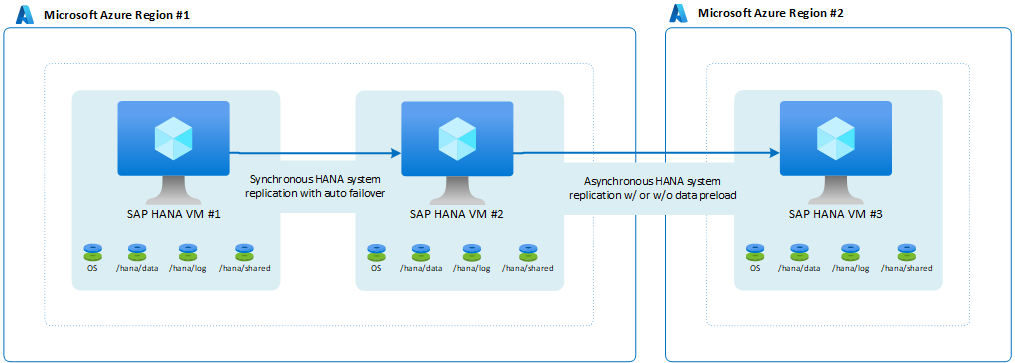
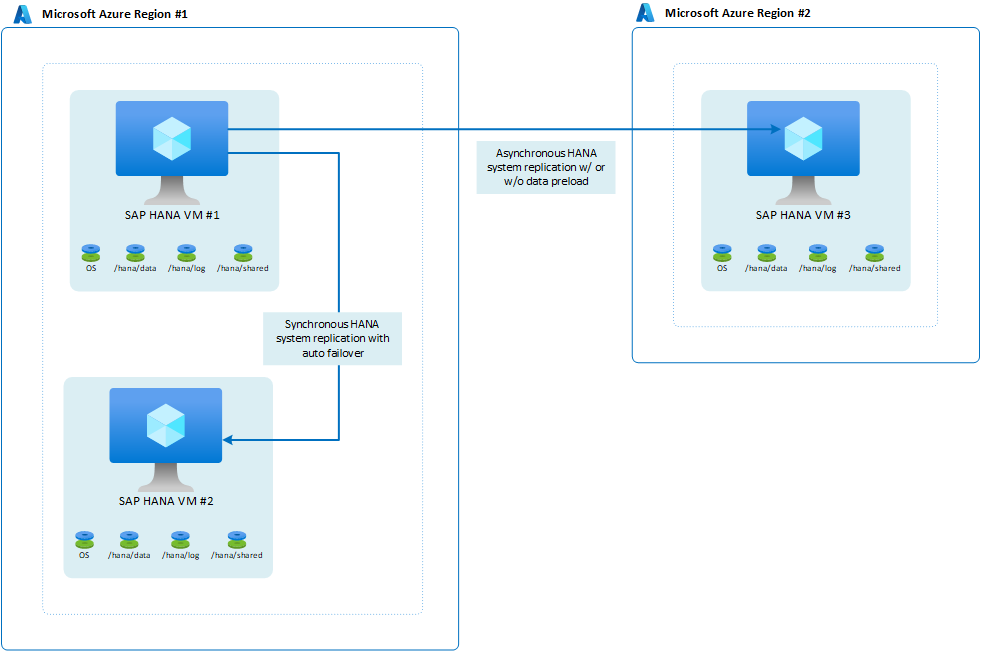
SAP では、HANA 2.0 SPS3 を使用した マルチターゲット システム レプリケーション が導入されました。 マルチターゲット システム レプリケーションは、更新シナリオでいくつかの利点をもたらします。 たとえば、セカンダリ HA サイトがメンテナンスまたは更新のために停止しても、DR サイト (リージョン 2) は影響を受けません。 HANA マルチターゲット システム レプリケーションの詳細については、 SAP ヘルプ ポータルを参照してください。 マルチターゲット レプリケーションで考えられるアーキテクチャは次のようになります。
組織に 2 番目の (DR) Azure リージョンでの高可用性の準備の要件がある場合、アーキテクチャは次のようになります。
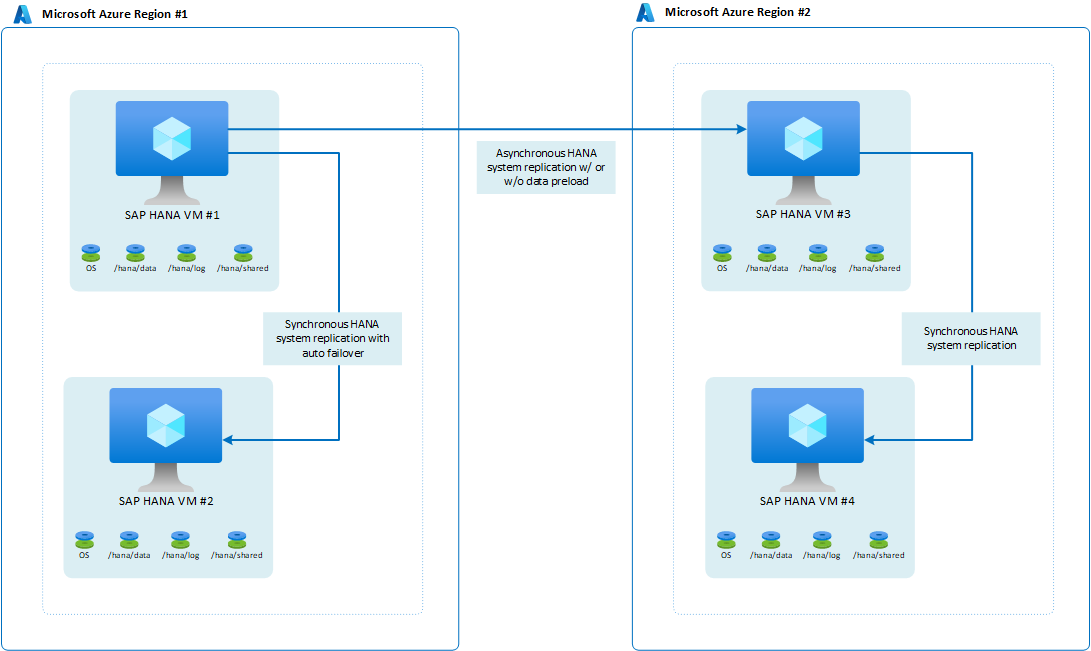
logreplay を運用モードとして使用すると、この構成は、プライマリリージョンにおいて RPO=0 を提供し、低い RTO を実現します。 この構成では、2 番目のリージョンへの移動が関係する場合にも適切な RPO が提供されます。 2 番目のリージョンの RTO 時間は、データがプリロードされているかどうかによって異なります。 多くのお客様は、セカンダリ リージョンの VM を使用してテスト システムを実行します。 そのユース ケースでは、データをプリロードできません。
重要
異なるレベル間の操作モードは同種である必要があります。 階層 1 と階層 2 の間での操作モードとして logreplay を使用することも、階層 3 を供給するために delta_datashipping を使用することもできません。 すべてのレベルで一貫性を保つ必要がある 1 つまたは他の操作モードのみを選択できます。 delta_datashippingは RPO=0 を提供するのに適していないため、このような多層構成の唯一の妥当な操作モードは logreplay のままです。 操作モードといくつかの制限の詳細については、SAP HANA システム レプリケーションの操作モードに関する記事を参照してください。
次のステップ
Azure でのこれらの構成の設定手順については、以下をご覧ください。