このクイック スタートでは、Azure portal の組み込みクエリ ツールである Search エクスプローラーを使用して、Azure AI Search インデックスに対してクエリを実行する方法について説明します。 このツールを使用して、クエリまたはフィルター式をテストしたり、コンテンツがインデックスに存在するかどうかを確認したりできます。
このクイックスタートでは、既存のインデックスを使用して Search エクスプローラーをデモンストレーションします。
前提条件
アクティブなサブスクリプションが含まれる Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search Service。 サービスを作成 するか 、現在の サブスクリプションで既存のサービスを検索します。 このクイック スタートでは、無料サービスを使用できます。
このクイック スタートでは、hotels-sample インデックスを使用します。 このクイック スタートの手順に従ってインデックスを作成します。
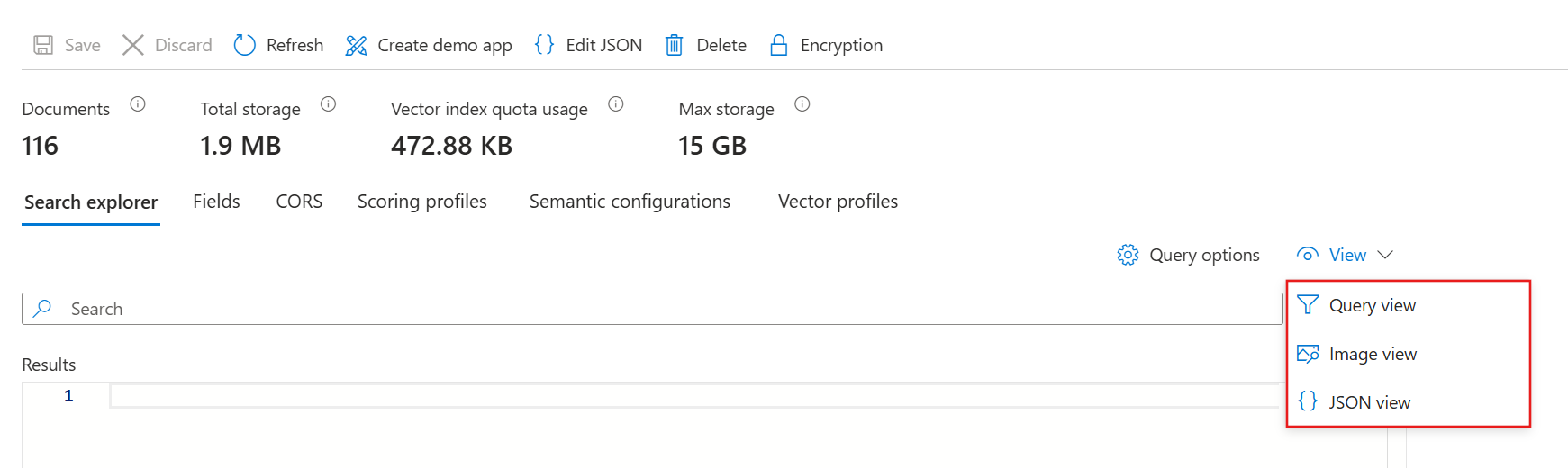
Search エクスプローラーの起動
Azure portal で、Search サービスに移動します。
左側のウィンドウで、[ 概要] を選択します。
コマンド バーで、 検索エクスプローラーを選択します。
![ポータルの [検索エクスプローラー] コマンドのスクリーンショット。](media/search-explorer/search-explorer-cmd.png)
または、インデックス ページの [検索エクスプローラー ] タブを選択します。
クエリの 3 つの方法
Search エクスプローラーでクエリを実行するには、次の 3 つの方法があります。
クエリ ビューには、既定の検索バーがあります。 空のクエリや、
ocean view + parkingなどのブール値を含む自由形式のクエリを受け入れます。画像ビューには、PNG、JPG、または JPEG ファイルを参照またはドラッグ アンド ドロップするためのウィンドウが用意されています。 インデックスに 画像ベクター化と同等のスキルがない限り、このビューは使用できません。
JSON ビューでは、パラメーター化されたクエリがサポートされます。 フィルター、orderby、select、count、searchFields、およびその他すべてのパラメータを JSON ビューに設定する必要があります。

例: イメージ クエリ
検索エクスプローラーでは、 イメージ ビューを使用して画像をクエリ入力として受け入れます。そのためには、サポートされている vectorizer-skill ペアを使用する必要があります。 詳細については、「 検索インデックスでベクターライザーを構成する」を参照してください。
hotels-sample インデックスは、画像ベクター化用に構成されていません。 イメージ クエリを実行する場合は、「 クイック スタート: Azure portal でのベクター検索」の説明に従ってインデックスを作成します。 このクイック スタートではテキストベースのサンプル データに依存しているため、画像を含むドキュメントを使用する必要があります。
イメージ クエリを実行するには、画像を選択するか、検索領域にドラッグして、[ 検索] を選択します。 検索エクスプローラーは、画像をベクター化し、クエリを実行するためにベクターを検索エンジンに送信します。 検索エンジンは、指定した k 数の結果まで、入力イメージと十分に類似したドキュメントを返します。

例: JSON クエリ
検索エクスプローラーを使用して実行できる JSON クエリの例を次に示します。 これらの例に従うために、 JSON ビューに切り替えます。 各 JSON の例をテキスト領域に貼り付けることができます。
ヒント
JSON ビューでは、パラメーター名を補完する IntelliSense がサポートされています。 JSON ビュー内にカーソルを置き、スペース文字を入力して、すべてのクエリ パラメーターの一覧を表示します。
sなどの文字を入力して、その文字で始まるクエリ パラメーターのみを表示することもできます。
Intellisense では無効なパラメーターが除外されないため、最適な判断を使用してください。
指定されていないクエリの実行
Search エクスプローラーでは、POST 要求は Documents - Search Post (REST API) を使用して内部的に作成され、応答は詳細な JSON ドキュメントとして返されます。
コンテンツを初めて見る場合は、[用語が指定されていない検索] を選択して空の 検索 を実行します。 空の検索は最初のクエリとして役に立ちます。ドキュメント全体が返されるので、ドキュメントの構成を確認できるからです。 空の検索では、検索スコアはなく、ドキュメントは任意の順序 (すべてのドキュメントに対して"@search.score": 1 ) で返されます。 既定では、検索要求ごとに 50 個のドキュメントが返されます。
"count": true を追加して、インデックスで見つかった一致の数を取得します。 空の検索では、カウントはインデックス内のドキュメントの合計数です。 修飾された検索では、これはクエリ入力と一致するドキュメントの数です。 サービスは既定で上位 50 件の一致を返すので、結果で返される数よりも多くの一致がインデックスに含まれる可能性があることを思い出してください。
空の検索に相当する構文は * または "search": "*" です。
{
"search": "*",
"count": true
}
結果

フリー テキスト クエリを実行する
演算子の有無にかかわらず、自由形式の検索は、カスタム アプリから Azure AI Search に送信されるユーザー定義クエリをシミュレートするのに役立ちます。 インデックス内で検索可能として属性付けされたフィールドのみが、一致をスキャンします。
自由テキスト クエリの JSON ビューは必要ありませんが、この記事の他の例と一貫性を保つため、JSON で提供します。
検索語やクエリ式などの検索条件を指定すると、検索順位が機能するようになることに注意してください。 次にフリー テキスト検索の例を示します。
@search.scoreは、既定のスコアリング アルゴリズムを使用して一致に対して計算される関連性スコアです。
{
"search": "activities `outdoor pool` restaurant OR continental breakfast"
}
結果
CTRL + F キーを使用して、関心のある特定の語句を結果内で検索できます。

検索結果内のフィールドを制限する
"select"を追加して、明示的に名前が付けられたフィールドに結果を制限し、検索エクスプローラーで読みやすい出力を得られます。 インデックスで取得可能として属性付けされたフィールドのみが結果に表示されます。
{
"search": "activities `outdoor pool` restaurant OR continental breakfast",
"count": true,
"select": "HotelId, HotelName, Tags, Description"
}
結果

結果の次のバッチを返す
Azure AI Search は、検索ランクに基づいて上位 50 件の一致を返します。 hotels-sample インデックスには 50 のホテルしかないため、ページングの仕組みを示すには、使用するホテル数をより少なくしています。 一致するドキュメントの次のセットを取得するには、 "top": 20 を追加し、 "skip": 10 して結果セットを 20 個のドキュメントに増やします (既定値は 50、最大値は 1000)、最初の 10 個のドキュメントをスキップします。 ドキュメント キー (HotelId) を確認して、ドキュメントを識別できます。
順位付けされた結果を取得するには、クエリ語句や式など、検索条件を指定する必要があることを思い出してください。 検索結果が深くなるほど、検索のスコアは低下します。
{
"search": "activities `outdoor pool` restaurant OR continental breakfast",
"count": true,
"select": "HotelId, HotelName, Tags, Description",
"top": 20,
"skip": 10
}
結果

フィルター式 (より大きい、より小さい、等しい)
filter パラメータを使用して、一致条件または除外条件を指定します。 フィールドは、インデックスでフィルター可能として属性付けする必要があります。 次の例では、4 つを超える評価を検索します。
{
"search": "activities `outdoor pool` restaurant OR continental breakfast",
"count": true,
"select": "HotelId, HotelName, Tags, Description, Rating",
"filter": "Rating gt 4"
}
結果

結果を並べ替える
検索スコアに加えて別のフィールドで結果を並べ替えるには、orderby を追加します。 フィールドは、インデックス内で並べ替え可能として属性付けする必要があります。 フィルタリングされた値が同じ (同じ価格など) 場合、順序は任意ですが、より詳細な並べ替え条件を追加できます。 これをテストするために使用できる式の例を次に示します。
{
"search": "activities `outdoor pool` restaurant OR continental breakfast",
"count": true,
"select": "HotelId, HotelName, Tags, Description, Rating, LastRenovationDate",
"filter": "Rating gt 4",
"orderby": "LastRenovationDate desc"
}
結果

重要なポイント
このクイックスタートでは、Search エクスプローラーを使用して、REST API でインデックスにクエリを実行しました。
結果は詳細な JSON ドキュメントとして返されるため、各ドキュメントの構造と内容全体を表示できます。 クエリ式の
selectパラメーターは、返されるフィールドを制限します。検索結果は、インデックスで取得可能として属性付けされたすべてのフィールドで構成されます。 [ フィールド ] タブを選択して属性を確認します。
キーワード検索は、商用 Web ブラウザーで入力する場合と同様に、エンド ユーザー エクスペリエンスをテストするのに役立ちます。 たとえば、hotels-sample インデックスを想定すると、
"activities 'outdoor pool' restaurant OR continental breakfast"を入力し、Ctrl-F を使用して検索結果内の用語を検索できます。クエリ式とフィルター式は、Azure AI Search に実装されている構文で表されます。 既定値は単純な構文です。しかし、必要に応じて完全な Lucene を使用し、より強力なクエリを実行できます。 フィルター式は、OData 構文で表現します。
リソースをクリーンアップする
自分のサブスクリプションで作業する場合は、不要になったリソースを削除してプロジェクトを完了することをお勧めします。 リソースを動作させたままだと、お金がかかることがあります。
Azure portal で、左側のウィンドウから [すべてのリソース ] または [リソース グループ ] を選択して、リソースを検索して管理します。 リソースを個別に削除することも、リソース グループを削除してすべてのリソースを一度に削除することもできます。
無料の検索サービスを使用している場合は、3 つのインデックス、インデクサー、データ ソースに制限されていることを覚えておいてください。 ポータルで 個々のアイテムを削除 して、制限を超えないようにすることができます。
次のステップ
クエリの構造と構文の詳細については、REST クライアントを使用して、REST API のより多くの部分を使用するクエリ式を作成します。 ドキュメント - Search Post (REST API) は、学習と探索に特に役立ちます。