Azure AI Search を使用して、Azure Blob Storage のカスタマー マネージド キーで暗号化されたドキュメントのインデックスを作成する方法について説明します。
通常、インデクサーは、Azure Blob Storage クライアント ライブラリで クライアント側の暗号化 を使用して暗号化された BLOB からコンテンツを抽出することはできません。 これは、インデクサーが Azure Key Vault のカスタマー マネージド暗号化キーにアクセスできないためです。 ただし、 DecryptBlobFile カスタム スキル と ドキュメント抽出スキルを使用すると、キーへの制御されたアクセスを提供してファイルを復号化し、そこからコンテンツを抽出できます。 これにより、格納されているドキュメントの暗号化状態を損なうことなく、これらのドキュメントにインデックスを作成するして強化する機能のロックが解除されます。
Azure Blob Storage に保存されている PDF、HTML、DOCX、PPTX などの以前に暗号化されたドキュメント全体(非構造化テキスト)を扱うことから始め、このチュートリアルでは、REST クライアントと検索 REST API を使用して次の操作を行います。
- ドキュメントを復号化し、そこからテキストを抽出するパイプラインを定義する
- 出力を格納するインデックスを定義する
- パイプラインを実行してインデックスを作成して読み込む
- フルテキスト検索と豊富なクエリ構文を使用して結果を探索する
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
任意の層またはリージョンでのAzure AI Search。
Azure Storage、Standard パフォーマンス (汎用 v2)。
カスタマー マネージド キーで暗号化された BLOB。 サンプル データを作成するには、「 チュートリアル: Azure Key Vault を使用して BLOB を暗号化および復号化する」を参照してください。
Azure AI Search と同じサブスクリプションにある Azure Key Vault。 キー コンテナーでは、論理的な削除と消去保護が有効になっている必要があります。
カスタムスキルデプロイでは、Azure Function アプリと Azure Storage アカウントが作成されます。 これらのリソースは自動的に作成されるため、前提条件として一覧表示されません。 このチュートリアルを完了したら、使用していないサービスに対して課金されないように、リソースをクリーンアップすることを忘れないでください。
注
スキルセットでは、多くの場合 、Azure AI サービスのマルチサービス リソースをアタッチする必要があります。 記述したように、このスキルセットは Azure AI サービスに依存しないため、キーは必要ありません。 組み込みのスキルを呼び出す基づく拡張を後で追加する場合は、それに応じてスキルセットを更新することを忘れないでください。
カスタム スキルをデプロイする
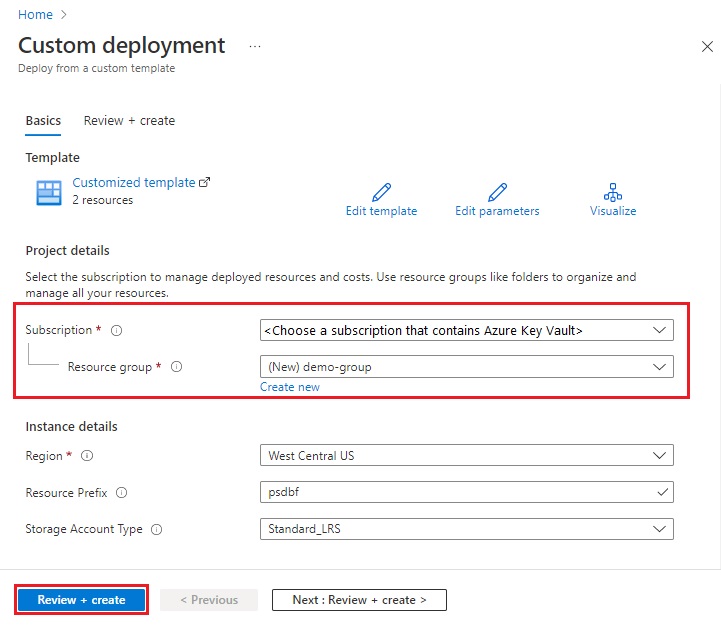
このチュートリアルでは、Azure Search Power Skills GitHub リポジトリのサンプル DecryptBlobFile プロジェクトを使用します。 このセクションでは、スキルセットで使用できるようにスキルを Azure 関数にデプロイします。 組み込みのデプロイ スクリプトにより、プレフィックス psdbf-function-app- で始まる Azure 関数リソースが作成されて、スキルが読み込まれます。 サブスクリプションとリソース グループを指定するように求められます。 必ず、Azure Key Vault インスタンスを含むサブスクリプションを選択してください。
運用上、DecryptBlobFile スキルは、各 BLOB の URL と SAS トークンを入力として受け取ります。 Azure AI Search で想定されるファイル参照コントラクトを使用して、ダウンロードされた復号化されたファイルを出力します。 解読を実行するには、DecryptBlobFile に暗号化キーが必要であることを思い出してください。 設定の一部として、Azure Key Vault 内の暗号化キーへのアクセスを DecryptBlobFile 関数に許可するアクセス ポリシーも作成します。
DecryptBlobFile ランディング ページで、[Azure へのデプロイ] を選択して、Azure portal で Resource Manager テンプレートを開きます。
Azure Key Vault インスタンスが存在するサブスクリプションを選択します。 別のサブスクリプションを選択した場合、このチュートリアルは機能しません。
既存のリソース グループを選択するか、新しいリソース グループを作成します。 専用のリソース グループを使用すると、後でクリーンアップを簡単に行うことができます。
[ 確認と作成] を選択し、条件に同意して、[ 作成 ] を選択して Azure 関数をデプロイします。
デプロイが完了するまで待ちます。
暗号化解除ロジックと、アプリケーションデータを格納する Azure Storage リソースを含む Azure Function アプリが必要です。 次の手順では、キー コンテナーにアクセスし、REST 呼び出しに必要な情報を収集するためのアクセス許可をアプリに付与します。
Azure Key Vault にアクセス許可を付与する
Azure portal で Azure Key Vault サービスに移動します。 Azure Key Vault で、カスタム スキルへのアクセスをキーに許可するアクセス ポリシーを作成します。
左側のウィンドウで、[ アクセス ポリシー] を選択し、[ + 作成 ] を選択して アクセス ポリシーの作成ウィザードを 開始します。
![左側のウィンドウの [アクセス ポリシー] コマンドのスクリーンショット。](media/indexing-encrypted-blob-files/keyvault-access-policies.png)
[ アクセス許可 ] ページの [ テンプレートから構成] で、 Azure Data Lake Storage または Azure Storage を選択します。
[次へ] を選択します。
[ プリンシパル ] ページで、デプロイした Azure 関数インスタンスを選択します。 psdbf-function-app の既定値を持つリソース プレフィックスを使用して検索できます。
[次へ] を選択します。
[レビュー + 作成] で、[作成] を選択します。
アプリ情報の収集
Azure portal で psdbf-function-app 関数に移動します。 REST 呼び出しに必要な次のプロパティを書き留めておきます。
関数の URL を取得します。これは、関数のメイン ページの [基本] にあります。
![Azure 関数アプリの概要ページと [Essentials] セクションのスクリーンショット。](media/indexing-encrypted-blob-files/function-uri.png)
ホスト キー コードを取得します。これは、[ アプリ キー ] に移動し、 既定 のキーを表示し、値をコピーすることで確認できます。
![Azure 関数アプリの [アプリ キー] ページのスクリーンショット。](media/indexing-encrypted-blob-files/function-host-key.png)
Azure AI 検索のための管理者キーと URL を取得する
Azure portal にサインインします。
検索サービスの [概要 ] ページで、検索サービスの名前を取得します。 エンドポイント URL を見ることで、自分のサービス名を確かめることができます。 たとえば、エンドポイント URL が
https://mydemo.search.windows.netされている場合、サービス名はmydemo。[設定]>[キー] で、サービスに対する完全な権限の管理キーを取得します。 管理キーをロールオーバーする必要がある場合に備えて、2 つの交換可能な管理キーがビジネス継続性のために提供されています。 オブジェクトの追加、変更、および削除の要求には、主キーまたはセカンダリ キーのどちらかを使用できます。
サービスに送信されるすべての要求のヘッダーには、API キーが必要です。 有効なキーは、要求を送信するアプリケーションとそれを処理するサービスとの間に、要求ごとに信頼を確立します。
REST クライアントの設定
エンドポイントとキーの次の変数を作成します。
| 変数 | どこで手に入れるか |
|---|---|
admin-key |
Azure AI Search サービスの [キー] ページ上。 |
search-service-name |
Azure AI Search サービスの名前。 URL は https://{{search-service-name}}.search.windows.net です。 |
storage-connection-string |
ストレージ アカウントの [アクセス キー] タブで、 [key1]>[接続文字列] を選択します。 |
storage-container-name |
インデックスを付ける暗号化されたファイルが含まれる BLOB コンテナーの名前。 |
function-uri |
Azure 関数のメイン ページにある 要点 の下にあります。 |
function-code |
Azure 関数で、[ アプリ キー] に移動し、 既定 のキーを表示し、値をコピーします。 |
api-version |
2020-06-30 のままにします。 |
datasource-name |
encrypted-blobs-ds のままにします。 |
index-name |
encrypted-blobs-idx のままにします。 |
skillset-name |
encrypted-blobs-ss のままにします。 |
indexer-name |
encrypted-blobs-ixr のままにします。 |
各要求を確認して実行する
エンリッチメント パイプラインのオブジェクトを作成するには、次の HTTP 要求を使用します。
インデックスを作成するための PUT 要求: この検索インデックスには、Azure AI Search で使用され、返されるデータが保持されます。
データソースを作成するための POST 要求: このデータソースは、暗号化された BLOB ファイルを格納しているストレージアカウントへの接続を指定します。
スキルセットを作成するための PUT 要求: スキルセットは、BLOB ファイル データを復号化する Azure 関数のカスタム スキル定義を指定します。 また、復号化後に各ドキュメントからテキストを抽出する DocumentExtractionSkill も指定します。
インデクサーを作成するための PUT 要求: インデクサーを実行すると、BLOB が取得され、スキルセットが適用され、結果が格納されます。 この要求は最後に実行する必要があります。 スキルセットのカスタム スキルは、復号化ロジックを呼び出します。
インデックス作成を監視する
インデックス作成とエンリッチメントは、インデクサー作成要求を送信するとすぐに開始されます。 ストレージ アカウントに含まれるドキュメントの数によっては、インデックス付けに時間がかかることがあります。 インデクサーがまだ実行されているかどうかを確認するには、 インデクサーの状態の取得 要求を送信し、応答を確認してインデクサーが実行されているかどうかを確認するか、エラーと警告の情報を表示します。
Free レベルを使用している場合は、次のメッセージが表示されます: "Could not extract content or metadata from your document. Truncated extracted text to '32768' characters"。 このメッセージは、Free レベルでの BLOB インデックス作成の 文字抽出に 32,000 個の制限があるために表示されます。 上位レベルでは、このデータ セットに対するこのメッセージは表示されません。
コンテンツを検索する
インデクサーの実行が完了したら、クエリを実行して、データの暗号化が正常に解除され、インデックスが作成されたことを確認できます。 Azure portal で Azure AI Search サービスに移動し、 Search Explorer を使用してインデックス付きデータに対してクエリを実行します。
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、料金が発生する可能性があります。 リソースを個別に削除するか、リソース グループを削除してリソースのセット全体を削除することができます。
Azure portal で、左側のナビゲーション ウィンドウにある [すべてのリソース] または [リソース グループ] リンクを使って、リソースを検索および管理できます。
次のステップ
暗号化されたファイルにインデックスを付けたので、より 多くのスキルを追加して データを強化し、より多くの洞察を得ることで、このパイプラインを反復処理できます。
二重に暗号化されたデータを使用している場合は、Azure AI 検索で利用可能なインデックス暗号化機能を調査するようにします。 インデクサーでインデックスを付けるには解読されたデータが必要ですが、インデックスを付けた後は、カスタマー マネージド キーを使用して、検索インデックスで暗号化することができます。 これにより、データは保存時に常に暗号化されることが保証されます。 詳細については、Azure AI Search のデータ暗号化のためのカスタマー マネージド キーの構成に関する記事を参照してください。