Azure Service Fabric のクラスター リソース マネージャー機能には、クラスターを記述するためのメカニズムが複数用意されています。
- 障害ドメイン
- アップグレード ドメイン
- ノードのプロパティ
- ノード容量
クラスター リソース マネージャーでは、実行時にこの情報を利用することで、クラスターで実行されているサービスの高可用性が確保されます。 クラスター リソース マネージャーでは、これらの重要なルールが適用されると同時に、クラスター内のリソース消費量の最適化も試みられます。
障害ドメイン
障害ドメインとは、障害について調整されている領域です。 1 台のコンピューターは 1 つの障害ドメインになります。 電源障害、ドライブ障害、問題のある NIC ファームウェアなど、さまざまな理由から、単独で停止する可能性があります。
同じイーサネット スイッチに接続されたコンピューターは、同じ障害ドメイン内にあります。 これらのコンピューターは、単一の電源または単一の場所を共有しています。
ハードウェア障害は当然重複するため、障害ドメインは本質的に階層的です。 それらは、Service Fabric では URI として表されます。
障害ドメインを正しく設定することが重要です。この情報はサービスを安全に配置するために Service Fabric によって使用されるためです。 Service Fabric では、(なんらかのコンポーネントのエラーによって生じた) 障害ドメインの損失によってサービスが停止するようなサービスの配置は望ましくありません。
Azure 環境では、環境によって提供される障害ドメイン情報を利用して、ユーザーの代わりに Service Fabric によってクラスター内のノードが正しく構成されます。 Service Fabric のスタンドアロン インスタンスの場合、障害ドメインはクラスターの設定時に定義されます。
警告
Service Fabric に提供される障害ドメインの情報が正確であることが重要です。 たとえば、Service Fabric クラスターのノードが 10 個の仮想マシン内で実行され、5 個の物理ホストで実行されているとします。 この場合、仮想マシンが 10 個ある場合でも、(最上位の) 障害ドメインは 5 個のみです。 物理ホストで障害が発生すると、VM では調整による障害が発生するため、同じ物理ホストを共有すると、VM では同じルート障害ドメインが共有されることになります。
Service Fabric では、ノードの障害ドメインが変わらないことが想定されています。 VM の高可用性を確保する他のメカニズム (HA-VM など) では、Service Fabric との競合が発生する場合があります。 これらのメカニズムでは、ホスト間での VM の透過的な移行が使われます。 それらでは、VM 内で実行されているコードの再構成または通知は行われません。 そのため、Service Fabric クラスターを実行する環境としては "サポートされません"。
採用する高可用性テクノロジは、Service Fabric のみにすることをお勧めします。 VM のライブ移行や SAN などのメカニズムは必要ありません。 これらのメカニズムと Service Fabric を組み合わせて使うと、アプリケーションの可用性と信頼性が "低下します"。 これは、新たな複雑さが増え、障害の集中する場所が増え、Service Fabric と競合する信頼性と可用性の戦略が利用されるためです。
次の図では、障害ドメインに属するすべてのエンティティに色が付けられ、その結果の異なる障害ドメインがすべて示されています。 この例には、データセンター ("DC")、ラック ("R")、ブレード ("B") があります。 各ブレードで複数の仮想マシンが保持されている場合は、障害ドメイン階層に別のレイヤーが存在することがあります。
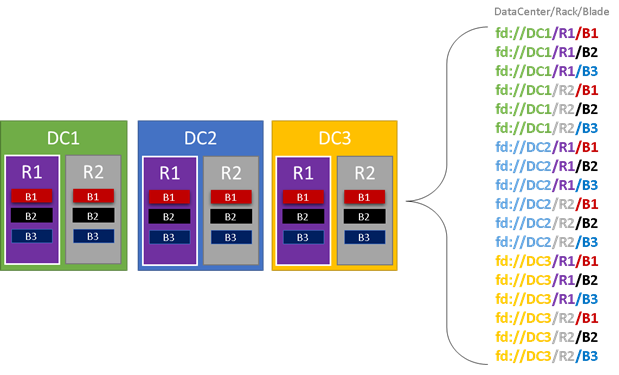
Service Fabric のクラスター リソース マネージャーでは、実行時に、クラスター内の障害ドメインが考慮されて、レイアウトが計画されます。 別個の障害ドメインに属するように、サービスのステートフル レプリカまたはステートレス インスタンスが分散されます。 サービスを障害ドメイン全体に分散することで、どの階層レベルで障害ドメインで障害が発生しても、サービスの可用性は損なわれなくなります。
クラスター リソース マネージャーにとって、障害ドメイン階層に存在するレイヤーの数は重要ではありません。 階層の一部の損失がその階層で実行されているサービスに影響しないように試みられます。
障害ドメイン階層の各レベルのノード数を同じにすることをお勧めします。 クラスター内の障害ドメインの "ツリー" が不均衡な場合、クラスター リソース マネージャーによるサービスの最適な割り当ての計算が困難になります。 障害ドメインのレイアウトが不均衡の場合、一部のドメインの損失がサービスの可用性に与える影響が、他のドメインの損失によるものよりも大きくなることを意味します。 その結果、クラスター リソース マネージャーは 2 つの目的の間で板挟みになります。
- サービスを配置することにより、その "重い" ドメインのコンピューターを使用する。
- ドメインの損失によって問題が生じないように、他のドメインにサービスを配置する。
不均衡なドメインとはどのようなものでしょうか。 次の図では、異なる 2 つのクラスター レイアウトが示されています。 最初の例では、ノードは障害ドメイン全体に均等に分散されています。 2 つ目の例では、1 つの障害ドメインに、他の障害ドメインより多くのノード数があります。
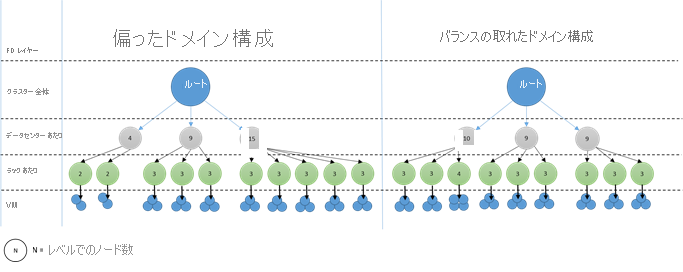
Azure では、ノードが含まれる障害ドメインの選択は自動的に行われます。 しかし、プロビジョニングするノードの数によっては、障害ドメインのノードの数に偏りが生じる可能性があります。
たとえば、クラスターに障害ドメインが 5 つあるときに、ノード タイプ (NodeType) のノードを 7 つプロビジョニングするとします。 この場合、最初の 2 つの障害ドメインではノード数が多くなります。 その後さらに、少数のインスタンスでより多くの NodeType インスタンスをデプロイすると、問題は悪化します。 この理由から、各ノードの種類のノード数は、障害ドメイン数の倍数にすることをお勧めします。
アップグレード ドメイン
アップグレード ドメインも、Service Fabric クラスター リソース マネージャーがクラスターのレイアウトを把握できる機能です。 アップグレード ドメインでは、同時にアップグレードされるノードのセットが定義されます。 アップグレード ドメインを使用すると、クラスター リソース マネージャーで、アップグレードなどの管理操作を把握し、調整することができます。
アップグレード ドメインは障害ドメインに似ていますが、重要な相違点がいくつかあります。 まず、障害ドメインは、調整されるハードウェア障害の領域で定義されます。 一方、アップグレード ドメインはポリシーで定義されます。 環境に数を指定させるのではなく、自分で希望の数を決定します。 ノードと同数のアップグレード ドメインを持つことができます。 障害ドメインとアップグレード ドメインのもう 1 つの違いは、アップグレード ドメインが階層ではない点です。 むしろ、それらは単純なタグに似ています。
次の図では、3 つの障害ドメインにストライピングされた 3 つのアップグレード ドメインが示されています。 また、ステートフル サービスの 3 つの異なるレプリカの配置例も示されています。これらのレプリカはそれぞれ、異なる障害ドメインとアップグレード ドメインに含まれています。 この配置であれば、サービスのアップグレードの最中に障害ドメインが 1 つ失われても問題はなく、コードとデータのコピーが 1 つ残ります。
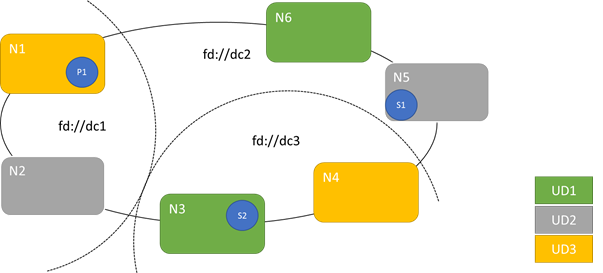
アップグレード ドメインの数を増やすことは良くもあり、悪くもあります。 アップグレード ドメインを増やすと、アップグレードの各手順が細かくなり、影響を受けるノードまたはサービスの数が少なくなります。 一度に移動する必要のあるサービスは減少し、システムに対する変更も少なくなります。 アップグレード中に発生した問題の影響が及ぶサービスが減少するため、これは信頼性の向上に寄与する傾向にあります。 アップグレード ドメインを増やすと、アップグレードの影響に対処するために必要とされる、他のノードにおける利用可能なバッファーも減少します。
たとえば、アップグレード ドメインが 5 つある場合、各アップグレード ドメイン内のノードではトラフィックの約 20 パーセントが処理されています。 アップグレードのためにそのアップグレード ドメインを停止する必要がある場合、通常、その負荷は他のドメインで処理される必要があります。 残りのアップグレード ドメインは 4 つなので、それぞれに合計トラフィックの約 25 パーセントの空き領域が必要です。 アップグレード ドメインの数を増やすと、クラスター内のノードの必要なバッファーが減ります。
10 個のアップグレード ドメインがある場合を考えます。 その場合、各アップグレード ドメインでは合計トラフィックの約 10 パーセントだけが処理されています。 アップグレードでクラスターをステップ実行する場合、各ドメインに必要な空き領域は、合計トラフィックの約 11 パーセントのみとなります。 一般に、アップグレード ドメインの数を多くすると、必要な予約容量が少なくなるため、高い使用率でノードを実行できます。 障害ドメインの場合にも同じことが言えます。
アップグレード ドメインを増やすことの欠点は、アップグレード時間が長くなる傾向があることです。 Service Fabric では、アップグレード ドメインが完了されてから短い待機時間があり、チェックが実行されてから、次のアップグレードが開始されます。 このような遅延があるので、アップグレードによって導入された問題を検出してから、アップグレードを進めることができます。 正しくない変更が一度に多くのサービスに影響を及ぼすのを防ぐことができるため、このトレードオフは許容されています。
アップグレード ドメインが少なすぎると、負の副作用が多数あります。 各アップグレード ドメインを停止してアップグレードしている間は、全体的な容量の大部分が使用できません。 たとえば、アップグレード ドメインが 3 つしかない場合は、サービスまたはクラスター容量全体の約 3 分の 1 が一度に停止します。 ワークロードを処理するために残りのクラスターの容量を十分確保する必要があるので、そのようにサービスの多くの部分を一度に停止することは望ましくありません。 そのバッファーを維持すると、通常の操作時に、他の場合よりも読み込まれるノード数が少なくなります。 その結果、サービスの実行コストが増えます。
環境内の障害ドメインまたはアップグレード ドメインの合計数に制限はありません。また、重複の制約もありません。 ただし、一般的なパターンがあります。
- 1 対 1 でマップされる障害ドメインとアップグレード ドメイン
- ノードごとに 1 つのアップグレード ドメイン (物理または仮想 OS インスタンス)
- "ストライプ" または "マトリックス" モデル (障害ドメインとアップグレード ドメインがマトリックスを形成。通常はコンピューターが表中で対角線を描くように配置される)
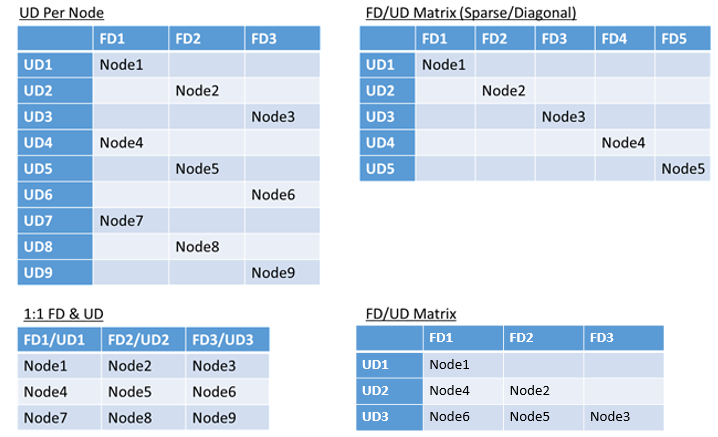
選択すべき最善のレイアウトに対する答えはありません。 それぞれに長所と短所があります。 たとえば、1FD 対 1UD モデルは設定が簡単です。 ノードごとに 1 つのアップグレード ドメインのモデルは、よく見られる構成に似ています。 アップグレード時は、各ノードが独立して更新されます。 これは、過去に少数のコンピューターを手動でアップグレードしていた方法と似ています。
最も一般的なモデルは、FD/UD マトリックスです。このモデルでは、障害ドメインとアップグレード ドメインがテーブルを形成し、ノードが対角線に沿って配置されます。 これは、Azure の Service Fabric クラスターの既定で使用されるモデルです。 ノード数が多いクラスターの場合、最終的に、密度の高いマトリックス パターンのようになります。
注
Azure でホストされている Service Fabric クラスターでは、既定の戦略の変更はサポートされていません。 そのカスタマイズが提供されるのは、スタンドアロン クラスターのみです。
障害ドメインとアップグレード ドメインの制約および結果の動作
既定の方法
既定では、クラスター リソース マネージャーにより障害ドメインとアップグレード ドメインの間でサービスのバランスが維持されます。 これは制約としてモデル化されています。 障害ドメインとアップグレード ドメインの制約では、次のことが表されます: "特定のサービス パーティションについて、階層の同じレベルにある 2 つのドメインでのサービス オブジェクト (ステートレス サービス インスタンスまたはステートフル サービス レプリカ) 数の差が 1 より大きくなってはならない"。
この制約は "最大限の差" を保証するものと考えることができます。 障害ドメインとアップグレード ドメインの制約により、規則に違反する特定の移動または配置はできなくなります。
たとえば、6 つのノードを持つクラスターを、5 つの障害ドメインと 5 つのアップグレード ドメインで構成したとします。
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
TargetReplicaSetSize (ステートレス サービスの場合は InstanceCount) の値が 5 のサービスを作成するとします。 レプリカを N1 ~ N5 に配置します。 実際は、このようなサービスをいくつ作成しても N6 が使用されることはありません。 しかし、なぜでしょうか。 現在のレイアウトと N6 を選択した場合のレイアウトの差異を見てみましょう。
現在のレイアウトと障害ドメインおよびアップグレード ドメインごとのレプリカの合計数は次のようになります。
| FD0 | FD1 | FD2 | FD3 | FD4 | 総 UD 数 | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
このレイアウトは、障害ドメインとアップグレード ドメインごとのノードという点でバランスが取れています。 障害ドメインとアップグレード ドメインごとのレプリカ数という点でもバランスが取れています。 各ドメインのノード数、レプリカ数は同じです。
次に、N2 ではなく N6 を使用した場合にどうなるかを見てみましょう。 レプリカはどのように分散されるでしょうか。
| FD0 | FD1 | FD2 | FD3 | FD4 | 総 UD 数 | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
このレイアウトは、障害ドメインの制約の "最大限の差" の保証という定義に違反しています。 FD0 には 2 つのレプリカがありますが、FD1 にはレプリカがありません。 FD0 と FD1 の差は合計 2 になります。これは、最大限の差である 1 を超えています。 制約に違反しているため、この配置はクラスター リソース マネージャーによって許可されません。
同様に (N1 と N2 ではなく) N2 と N6 を選択すると、次のようになります。
| FD0 | FD1 | FD2 | FD3 | FD4 | 総 UD 数 | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
障害ドメインの観点からは、このレイアウトはバランスがとれています。 しかし、現在は、レプリカの数が UD0 の 0 個に対して UD1 は 2 個なので、アップグレード ドメインの制約に違反しています。 このレイアウトも無効であり、クラスター リソース マネージャーで選択されません。
ステートフル レプリカまたはステートレス インスタンスの分散に対するこの方法は、可能な最高のフォールト トレランスを提供します。 1 つのドメインがダウンした場合、最小限の数のレプリカ/インスタンスが失われます。
その一方で、この方法は厳しすぎて、クラスターがすべてのリソースを利用できない可能性があります。 特定のクラスター構成では、特定のノードを使用できません。 これにより、Service Fabric でサービスが配置されなくなり、警告メッセージが発生する可能性があります。 前の例では、一部のクラスター ノードを使用できません (例では N6)。 そのクラスター (N7-N10) にノードを追加した場合でも、障害ドメインとアップグレード ドメインの制約のため、レプリカ/インスタンスは N1–N5 のみに配置されます。
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
他の方法
クラスター リソース マネージャーでは、別のバージョンの障害ドメインとアップグレード ドメインの制約がサポートされています。 それでは、最低レベルの安全性を保証しながら配置することができます。 代わりの制約は次のように表すことができます: "特定のサービス パーティションについて、ドメイン間へのレプリカの分散は、パーティションでクォーラムの損失が発生しないことを保証しなければならない"。 この制約は "クォーラム セーフ" を保証するものと考えることができます。
注
ステートフル サービスの場合、"クォーラム損失" は、パーティション レプリカの過半数が同時にダウンしている状況と定義されます。 たとえば、TargetReplicaSetSize が 5 の場合、任意の 3 個のレプリカのセットがクォーラムを表します。 同様に、TargetReplicaSetSize が 6 の場合は、クォーラムには 4 個のレプリカが必要です。 どちらのケースも、パーティションが正常な機能を続けたい場合、3 個以上のレプリカが同時にダウンすることはできません。
ステートレス サービスの場合は、"クォーラム損失" のようなものはありません。 インスタンスの過半数が同時にダウンした場合でも、ステートレス サービスは正常に機能し続けます。 そのため、この記事の残りではステートフル サービスに焦点を当てます。
前に示した例に戻りましょう。 "クォーラム セーフ" バージョンの制約では、3 つのレイアウトすべてが有効です。 2 番目のレイアウトの FD0 または 3 番目のレイアウトの UD1 で障害が発生しても、パーティションにはまだクォーラムがあります。 (レプリカの過半数がまだアップしています。)制約のこのバージョンでは、ほぼ常に N6 が利用される可能性があります。
柔軟性については、"クォーラム セーフ" アプローチの方が "最大限の差" アプローチより優れています。 これは、ほぼすべてのクラスター トポロジで、有効なレプリカの分散を簡単に検索できるためです。 ただし、このアプローチは、一部の障害が他の障害より悪いため、最善のフォールト トレランス特性を保証できません。
最悪のシナリオでは、1 つのドメインとさらに 1 つのレプリカの障害により、レプリカの過半数が失われる可能性があります。 たとえば、5 個のレプリカまたはインスタンスでクォーラムを損失するために必要な障害は、3 つではなく、2 つだけです。
アダプティブ アプローチ
どちらのアプローチにも長所と短所があるため、これら 2 つの戦略を組み合わせたアダプティブ アプローチが導入されました。
注
Service Fabric バージョン 6.2 以降では、これが既定の動作になります。
アダプティブ アプローチでは、"最大限の差" ロジックが既定で使用され、必要な場合にのみ "クォーラム セーフ" ロジックに切り替わります。 クラスター リソース マネージャーでは、クラスターとサービスの構成方法を調べることで、必要な戦略が自動的に判別されます。
次の条件が両方とも当てはまるサービスに対して、クラスター リソース マネージャーでは "クォーラム ベース" のロジックが使用される必要があります。
- サービスの TargetReplicaSetSize が、障害ドメインおよびアップグレード ドメインの数で割り切れる。
- ノードの数が、障害ドメインの数とアップグレード ドメインの数を掛けた値と等しいかそれより少ない。
クォーラム損失はステートレス サービスには関係ありませんが、クラスター リソース マネージャーではステートレス サービスとステートフル サービスの両方にこのアプローチが使われることに注意してください。
前の例に戻り、クラスターに 8 個のノードがあるものとします。 クラスターはまだ、5 個の障害ドメインと 5 個のアップグレード ドメインで構成され、そのクラスターでホストされているサービスの TargetReplicaSetSize の値は 5 のままです。
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
すべての必要な条件が満たされているため、クラスター リソース マネージャーでは "クォーラム ベース" のロジックを使ってサービスが分散されます。 これにより、N6-N8 を使用できるようになります。 このケースで可能なサービスの分散の 1 つは、次のようなものです。
| FD0 | FD1 | FD2 | FD3 | FD4 | 総 UD 数 | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
サービスの TargetReplicaSetSize の値が (たとえば) 4 に下がった場合、クラスター リソース マネージャーではその変更が認識されます。 TargetReplicaSetSize が障害ドメインおよびアップグレード ドメインの数で割り切れなくなったため、"最大限の差" ロジックの使用が再開されます。 その結果、ノード N1-N5 の残り 4 個のレプリカを分散させるため、特定のレプリカの移動が発生します。 そうすれば、障害ドメインとアップグレード ドメインの "最大限の差" バージョンのロジックに違反しません。
前のレイアウトでは、TargetReplicaSetSize の値が 5 で、N1 がクラスターから削除された場合、アップグレード ドメインの数は 4 になります。 サービスの TargetReplicaSetSize の値がアップグレード ドメインの数で割り切れなくなったため、やはり、クラスター リソース マネージャーでは "最大限の差" ロジックの使用が開始されます。 その結果、レプリカ R1 が再び作成された場合は、障害ドメインとアップグレード ドメインの制約に違反しないように、N4 に配置する必要があります。
| FD0 | FD1 | FD2 | FD3 | FD4 | 総 UD 数 | |
|---|---|---|---|---|---|---|
| UD0 | 該当なし | 該当なし | 該当なし | 該当なし | 該当なし | 該当なし |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
障害ドメインとアップグレード ドメインの構成
Azure でホストされる Service Fabric のデプロイでは、障害ドメインとアップグレード ドメインは自動的に定義されます。 Service Fabric によって Azure から環境情報が取得されて使用されます。
独自のクラスターを作成する (または開発で特定のトポロジを実行する) 場合は、障害ドメインとアップグレード ドメインの情報を自分で入力することになります。 この例では、(それぞれ 3 つのラックを備えた) 3 つのデータセンターにまたがる、ノードが 9 つのローカル開発クラスターを定義します。 このクラスターには、それらの 3 つのデータセンターにストライピングされる 3 つのアップグレード ドメインもあります。 ClusterManifest.xml での構成の例を次に示します。
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
この例では、スタンドアロン デプロイ用の ClusterConfig.json が使われています。
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
注
Azure Resource Manager でクラスターを定義すると、Azure によって障害ドメインとアップグレード ドメインが割り当てられます。 そのため、Azure Resource Manager テンプレートのノードの種類と仮想マシン スケール セットの定義には、障害ドメインまたはアップグレード ドメインに関する情報は含まれません。
ノードのプロパティと配置の制約
場合によっては (実際には、ほとんどの場合)、特定のワークロードが、クラスター内の特定のノードの種類だけで確実に実行されるようにしたいことがあります。 たとえば、ワークロードの中に GPU や SSD を必要とするものとしないものが混在している場合があります。
特定のワークロードをターゲットにするハードウェアの好例は、ほぼすべての n 層アーキテクチャです。 一部のコンピューターは、アプリケーションのフロント エンドまたは API 提供側として機能し、クライアントまたはインターネットに公開されます。 (多くの場合異なるハードウェア リソースを備えた) 複数のコンピューターが、コンピューティングまたはストレージ レイヤーの作業を処理します。 通常、これらはクライアントまたはインターネットに直接 公開されません。
Service Fabric では、特定のワークロードを特定のハードウェア構成で実行する必要が生じる状況があることが想定されます。 次に例を示します。
- 既存の n 層アプリケーションが Service Fabric 環境に "リフト アンド シフト (移行)" された。
- パフォーマンス、スケール、またはセキュリティの分離の理由により、ワークロードを特定のハードウェアで実行する必要がある。
- ポリシーまたはリソース消費の理由により、特定のワークロードを他のワークロードから切り離す必要がある。
こうした構成をサポートするため、Service Fabric にはノードに適用できるタグが含まれます。 これらのタグは、ノードのプロパティと呼ばれます。 "配置の制約" は、1 つまたは複数のノードのプロパティに選択される個々のサービスに接続されるステートメントです。 配置の制約で、サービスを実行する場所を定義します。 一連の制約は拡張可能です。 任意のキー/値のペアを使用できます。
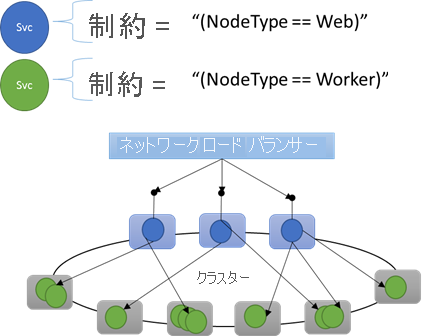
組み込みのノードのプロパティ
Service Fabric では、自動的に適用できる既定のノード プロパティがいくつか定義されています。これらのプロパティについては、ユーザーが定義する必要はありません。 NodeType と NodeName が、既定のプロパティとして各ノードで定義されています。
たとえば、配置の制約は "(NodeType == NodeType03)" と記述できます。 NodeType は一般的に使用されるプロパティです。 コンピューターの種類と 1 対 1 で対応するため、便利です。 コンピューターの各種類は、従来の n 層アプリケーションのワークロードの種類と対応しています。
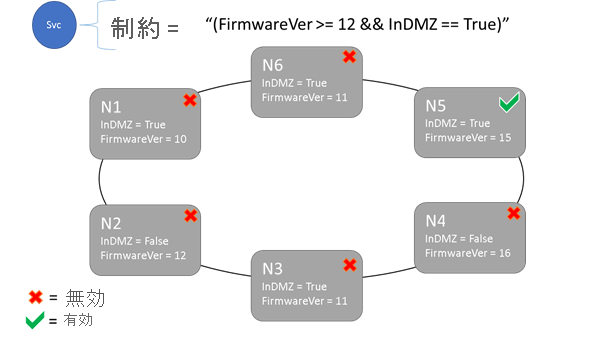
配置の制約とノードのプロパティの構文
ノード プロパティで指定する値には、string、ブール値、signed long を使用できます。 サービスを実行できるクラスターの場所が制約されるため、サービスのステートメントは配置の "制約" と呼ばれます。 制約として使用できるのは、クラスター内のノード プロパティに対して実行される任意のブール ステートメントです。 これらのブール値ステートメントでの有効なセレクターは次のとおりです。
特定のステートメントを作成するための条件確認:
ステートメント 構文 "等しい" "==" "等しくない" "!=" "より大きい" > "以上" ">=" "より小さい" < "以下" "<=" グループ化と論理演算のブール ステートメント:
ステートメント 構文 "および" "&&" "または" "||" "ではない" "!" "1 つのステートメントとしてグループ化" "()"
基本的な制約ステートメントの例をいくつか紹介します。
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
配置の制約ステートメント全体の評価が "True" のノードにのみ、サービスを配置することができます。 プロパティが定義されていないノードと、そのプロパティを含む配置の制約とは一致しません。
たとえば、ClusterManifest.xml でノード タイプに対して次のノード プロパティが定義されているとします。
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
次の例では、スタンドアロン デプロイの ClusterConfig.json または Azure でホストされたクラスターの Template.json で定義されているノード プロパティを示します。
注
通常、Azure Resource Manager テンプレートでは、ノードの種類はパラメーター化されています。 NodeType01 ではなく "[parameters('vmNodeType1Name')]" のようになります。
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
サービスに対して、次のようにサービスの配置の "制約" を作成できます。
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
NodeType01 のすべてのノードが有効な場合、制約が "(NodeType == NodeType01)" のノードの種類を選択することもできます。
サービスの配置の制約は、実行時に動的に更新できます。 必要に応じて、クラスター内でのサービスの移動や、要件の追加/削除などを行うことができます。 このような変更が行われる場合でも、Service Fabric によって、サービスは確実に稼働し続け、利用することができます。
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
配置の制約は、名前付きサービス インスタンスごとに指定されます。 更新すると、以前に指定された内容は常に置き換えられます (上書きされます)。
クラスター定義で、ノードのプロパティを定義します。 ノードのプロパティを変更するには、クラスター構成のアップグレードが必要です。 ノードのプロパティをアップグレードするには、影響を受ける各ノードを再起動して新しいプロパティを報告する必要があります。 Service Fabric ではこのようなローリング アップグレードが管理されます。
クラスター リソースの説明と管理
クラスター内のリソース消費量の管理は、オーケストレーターの重要なジョブの 1 つです。 クラスター リソースの管理は、2 つの異なることを意味する可能性があります。
1 つ目は、コンピューターがオーバーロードにならないようにすることです。 つまり、コンピューターが処理できる限度を超えてサービスを実行しないようにすることです。
2 つ目は、サービスを効率的に実行するために重要な分散と最適化です。 コスト効率またはパフォーマンス重視のサービス プランでは、一部のノードをホット ノードにして他のノードはコールド ノードにするということができません。 ホット ノードは、リソースの競合とパフォーマンスの低下を招きます。 コールド ノードは、リソースの浪費とコストの増加につながります。
Service Fabric ではリソースが "メトリック" として表されます。 メトリックとは、Service Fabric に対して記述する論理または物理リソースです。 たとえば、"WorkQueueDepth"、"MemoryInMb" などがメトリックです。 Service Fabric でノードを制御できる物理リソースの詳細については、「リソース ガバナンス」を参照してください。 Cluster Resource Manager によって使用される既定のメトリックについて、またカスタム メトリックを構成する方法については、こちらの記事を参照してください。
メトリックは、配置の制約ともノード プロパティとも異なります。 ノードのプロパティは、ノード自体の静的な記述子です。 メトリックは、ノードが持っているリソースと、ノード上で実行されているときにサービスが消費するリソースを表します。 ノード プロパティは HasSSD にすることができるほか、true または false に設定できます。 その SSD の使用可能な容量とサービスによって消費される容量は、"DriveSpaceInMb" などのメトリックになります。
配置の制約とノード プロパティの場合と同様に、メトリックの名前が意味する内容は Service Fabric クラスター リソース マネージャーによって認識されません。 メトリックの名前は単なる文字列です。 あいまいな場合は作成したメトリック名の一部として単位を宣言することをお勧めします。
容量
すべてのリソースの "分散" をオフにしたとしても、Service Fabric クラスター リソース マネージャーは容量超過のノードが出ないように調整します。 クラスターの容量がいっぱいの場合や、ワークロードがノードよりも大きい場合でなければ、容量超過の管理は可能です。 容量とは、ノードにどのくらいのリソースがあるかを理解するためにクラスター リソース マネージャーが使用するもう 1 つの "制約" です。 容量の残りもクラスター全体で追跡されます。
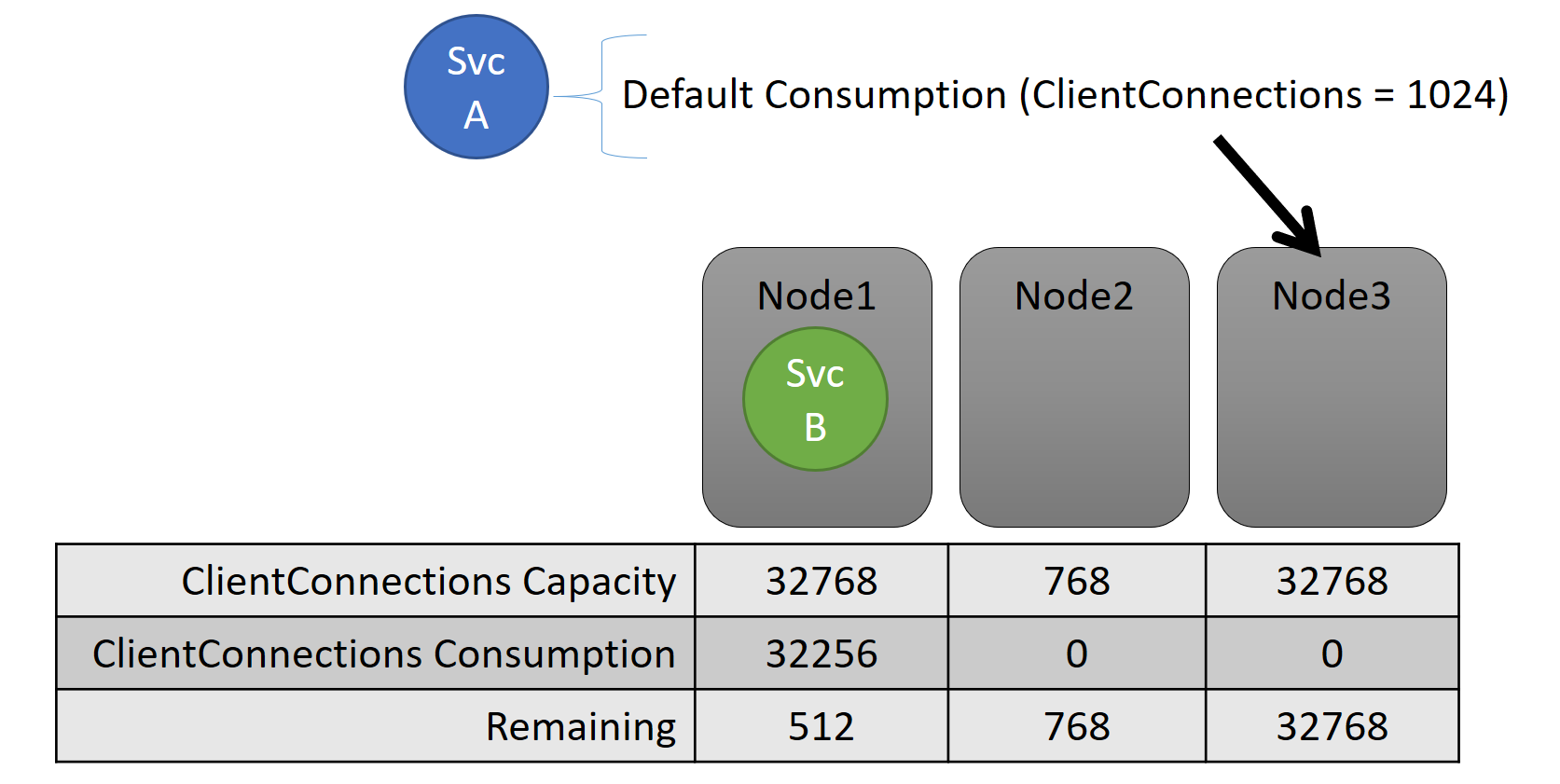
このサービス レベルの容量と消費量の両方が、メトリックで表現されます。 たとえば、メトリックが "ClientConnections" であり、あるノードで "ClientConnections" の容量が 32,768 だとします。 他のノードには他の制限がある可能性があります。 そのノードで実行されている一部のサービスは 32,256 のメトリック "ClientConnections" を消費している、と言うことができます。
実行中に、クラスター リソース マネージャーはクラスターとノードの残容量を追跡します。 クラスター リソース マネージャーは容量を追跡するために、サービスが実行されているノードの容量から、各サービスの使用量を差し引きます。 クラスター リソース マネージャーでは、ノードが容量超過にならないように、この情報を使用してレプリカを配置または移動する場所が検討されます。
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
クラスター マニフェストで定義した容量を確認できます。 ClusterManifest.xml の例を次に示します。
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
次に示すのは、スタンドアロン デプロイの ClusterConfig.json または Azure でホストされたクラスターの Template.json で定義されている容量の例です。
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
多くの場合、サービスの負荷は動的に変化します。 たとえば、レプリカの "ClientConnections" の負荷が 1,024 から 2,048 に変化したとします。 そのときに実行されていたノードでは、そのメトリックの残容量がわずか 512 だとします。 このとき、このノードには十分な空き領域がないため、レプリカまたはインスタンスの配置は無効になります。 クラスター リソース マネージャーでは、ノードを容量未満に戻す必要があります。 その結果、そのノードの 1 つまたは複数のレプリカまたはインスタンスが他のノードに移動され、容量を超過していたノードの負荷が軽減されます。
クラスター リソース マネージャーでは、レプリカ移動のコストが最小限になるように試みられます。 移動コストおよび再調整戦略とルールに関する詳細を確認してください。
クラスターの容量
Service Fabric のクラスター リソース マネージャーでは、クラスター全体がいっぱいの状態にならないように、どのような処理が行われているでしょうか。 動的負荷では、あまりできることがありません。 サービスにかかる負荷は、クラスター リソース マネージャーの動作に関係なく急増する場合があります。 そのため、今日クラスターに余裕があっても、明日急増があれば力不足になる可能性があります。
クラスター リソース マネージャーでの制御は、問題を防ぐのに役立ちます。 まず、クラスターがいっぱいになる原因となるワークロードが新しく作成されないようにします。
たとえば、ステートレス サービスを作成し、それに関連する負荷がある程度あるとします。 そのサービスでは "DiskSpaceInMb" メトリックが使用されています。 サービスでは、インスタンスごとに 5 ユニットの "DiskSpaceInMb" が消費されます。 作成するサービス インスタンスは 3 つです。 つまり、これらのサービス インスタンスを作成するには、クラスターに 15 ユニットの "DiskSpaceInMb" が必要です。
クラスター リソース マネージャーでは各メトリックの容量と消費量が継続的に計算されるので、クラスターの残りの容量を判断できます。 十分な領域がない場合、クラスター リソース マネージャーではサービス作成の呼び出しが拒否されます。
要件は 15 ユニットが使用できることのみであるため、この領域はさまざまな方法で割り当てることができます。 たとえば、異なる 15 個のノードそれぞれに 1 つずつユニットが残っていても、5 つの異なるノードに 3 つずつユニットが残っていてもかまいません。 3 つのノードに 5 つの利用可能なユニットがある状態になるように配置し直せる場合、クラスター リソース マネージャーではサービスが配置されます。 クラスターの空きがほぼない場合や、既存のサービスを何らかの理由で統合できない場合を除き、通常、クラスターの再配置は可能です。
ノード バッファーおよび予約超過容量
メトリックのノード容量が指定されているときに、合計負荷が指定されたノード容量を超える場合、Cluster Resource Manager によってノードにレプリカが配置されたり移動されたりすることはありません。 これにより、クラスターの容量がほぼいっぱいになり、負荷の大きいレプリカを配置、置換、または移動する必要がある場合に、新しいレプリカの配置や障害が発生したレプリカの置換が妨げられることがあります。
柔軟性を高めるために、ノード バッファーまたは予約超過容量を指定することができます。 ノード バッファーまたは予約超過容量がメトリックに対して指定されている場合、バッファーまたは予約超過容量が未使用のままになるように Cluster Resource Manager によってレプリカの配置または移動が試みられますが、次のようなサービスの可用性を向上させるアクションに必要な場合はバッファーまたは予約超過容量を使用することができます。
- 新しいレプリカの配置または障害が発生したレプリカの置換
- アップグレード時の配置
- ソフトおよびハードの制約違反の修正
- 最適化
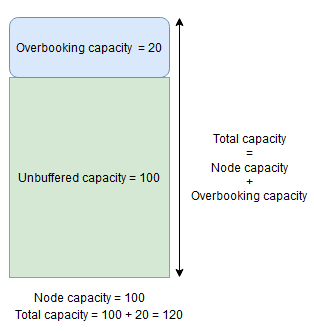
ノード バッファー容量は指定されたノード容量を下回る容量の予約部分を表し、予約超過容量は指定されたノード容量を上回る余分な容量の一部を表します。 どちらの場合も、Cluster Resource Manager によって、この容量を空けておくことが試みられます。
たとえば、ノードにメトリック CpuUtilization が 100 の容量が指定されていて、そのメトリックのノード バッファーの割合が 20% に設定されている場合、合計およびバッファーなしの容量はそれぞれ 100 および 80 となり、通常の状況で Cluster Resource Manager によって、ノードに対して 80 単位を超える負荷がかけられることはありません。

ノード バッファーは、上記のサービスの可用性を向上させるアクションにのみ使用されるノード容量の一部を予約する場合に使用する必要があります。
一方、ノードの予約超過の割合が使用されており、20% に設定されている場合、合計およびバッファーなしの容量はそれぞれ 120 と 100 になります。
Cluster Resource Manager でノードにレプリカを配置できるようにする場合は、予約超過容量を使用する必要があります。これは、リソースの合計使用量が容量を超える場合でも同様です。 これを使用すると、サービスの可用性を高めることはできますが、パフォーマンスが低下します。 予約超過が使用されている場合は、ユーザー アプリケーション ロジックが、必要となる可能性のあるものよりも少ない物理リソースで機能できる必要があります。
ノード バッファーまたは予約超過容量が指定されている場合、ターゲット ノードの合計負荷 (ノード バッファーの場合はノード容量、予約超過の場合はノード容量 + 予約超過容量) が合計容量を超えた場合、Cluster Resource Manager によってレプリカが移動されたり配置されたりすることはありません。
予約超過容量は、無制限として指定することもできます。 この場合、Cluster Resource Manager によって、ノードに対する合計負荷が指定されたノード容量を下回るようにすることが試みられますが、ノードにかかる負荷が大幅に増加する可能性があるため、深刻なパフォーマンスの低下につながることがあります。
メトリックには、ノード バッファーおよび予約超過容量の両方を同時に指定することはできません。
以下は、ClusterManifest.xml でノード バッファーまたは予約超過容量を指定する方法の例です。
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
以下は、スタンドアロン デプロイの ClusterConfig.json、または Azure でホストされたクラスターの Template.json を使用してノード バッファーまたは予約超過容量を指定する方法の例です。
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
次のステップ
- クラスター リソース マネージャー内のアーキテクチャと情報フローについては、「クラスター リソース マネージャーのアーキテクチャの概要」をご覧ください。
- 最適化メトリックの定義は、負荷を分散するのではなく、ノードで統合する方法の 1 つです。最適化を構成する方法については、「Service Fabric のメトリックと負荷の最適化」をご覧ください。
- 最初から開始して、Service Fabric クラスター リソース マネージャーの概要を確認するにはこちらを参照してください。
- クラスター リソース マネージャーでクラスターの負荷が管理され、分散されるしくみについては、「Service Fabric クラスターの均衡をとる」を参照してください。