Resource Health の概要
Azure Resource Health は、Azure のリソースに影響を及ぼしているサービスの問題を診断したり、サポートを受けたりするために役立ちます。 リソースの現在と過去の正常性について報告します。
Azure の状態レポートは、さまざまな Azure ユーザーに影響するサービスの問題について報告します。 Resource Health は、リソースの正常性に関するパーソナライズされたダッシュボードを提供します。 Resource Health は、Azure サービスの問題によってリソースが利用できなかったすべての時間を示します。 このデータにより、SLA 違反が発生したかどうかを簡単に確認できます。
リソース定義と正常性評価
リソースは、仮想マシン、Web アプリ、SQL Database など、Azure サービスの特定のインスタンスです。 Resource Health は、さまざまな Azure サービスからの信号を基に、リソースが正常であるかどうかを評価します。 リソースが正常でない場合、Resource Health は追加の情報を分析して問題の原因を特定します。 また、問題解決のために Microsoft が実施しているアクションについても報告し、問題に対処するためにユーザーができることを特定します。
正常性の評価方法の詳細については、Azure Resource Health に関する記事でリソースの種類と正常性チェックの一覧を参照してください。
正常性状態
リソースの正常性は、次のいずれかの状態として表示されます。
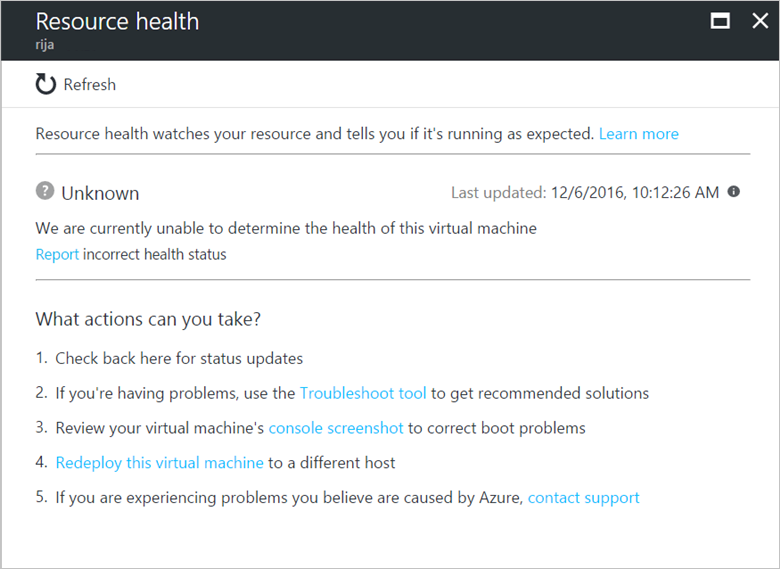
利用可能
使用可能は、リソースの正常性に影響を与えるイベントが検出されていないことを意味します。 リソースが過去 24 時間以内に予定外のダウンタイムから回復した場合は、"最近解決された" ことを示す通知が表示されます。
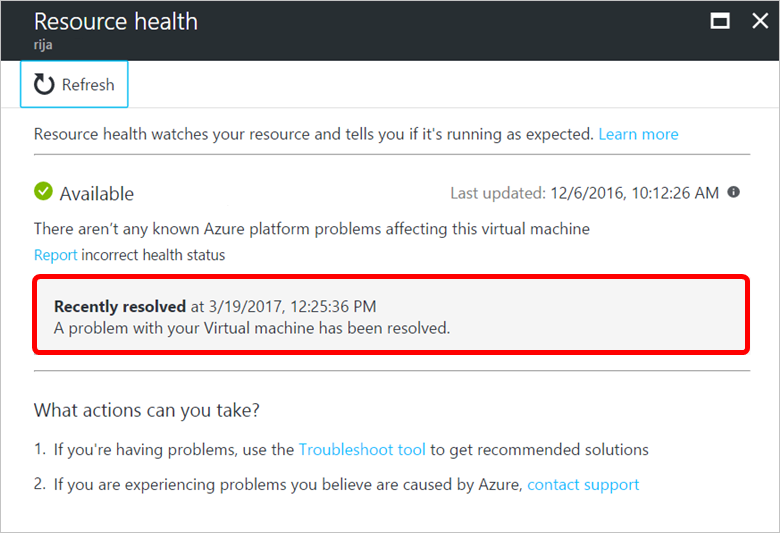
利用不可
使用不可は、サービスにおいて、リソースの正常性に影響を与える継続中のイベント (プラットフォームまたはプラットフォーム以外のイベント) が検出されたことを意味します。
プラットフォームのイベント
プラットフォームのイベントは、Azure インフラストラクチャの複数のコンポーネントによってトリガーされます。 これには、スケジュールされたアクション (計画的なメンテナンスなど) と、予期しないインシデント (計画されていないホストの再起動や、指定の期間後に障害が発生すると予測される機能が低下したホスト ハードウェアなど) の両方が含まれます。
Resource Health は、イベントと復旧プロセスについてさらに詳細な情報を提供します。 また、ユーザーは、有効なサポート契約がない場合でも、Microsoft サポートに問い合わせることができます。
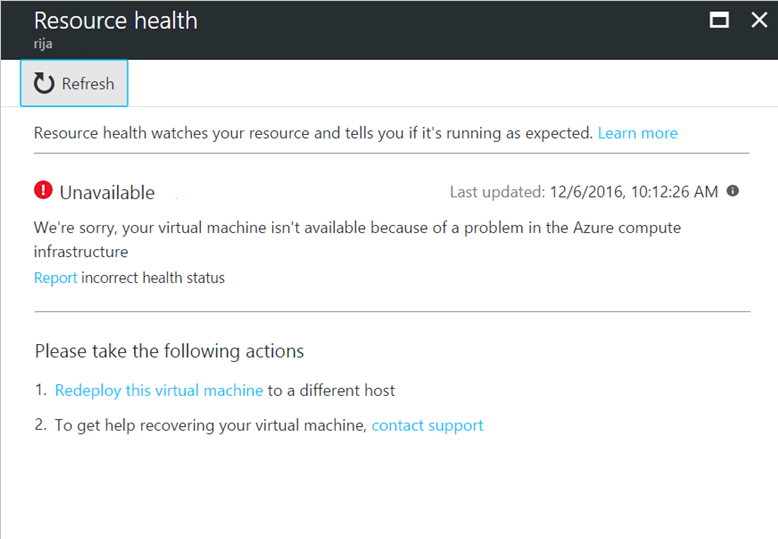
プラットフォーム以外のイベント
プラットフォーム以外のイベントは、ユーザー アクションによってトリガーされます。 たとえば、仮想マシンを停止した場合や、Azure Cache for Redis への接続数が最大数に到達した場合などです。
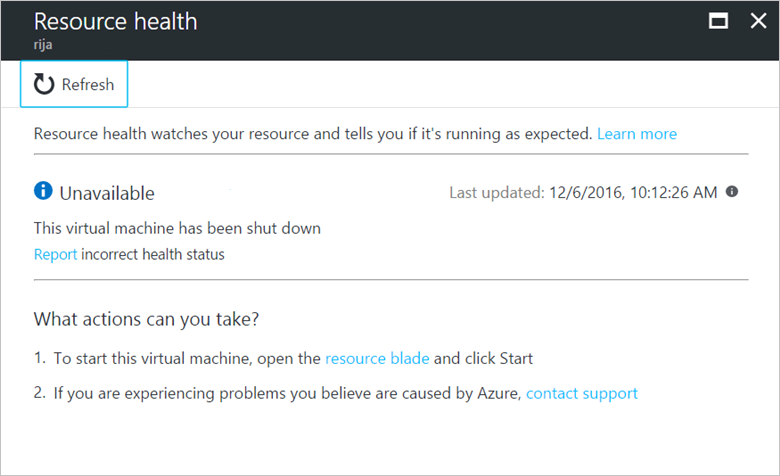
Unknown
不明は、Resource Health がリソースに関する情報を 10 分以上受け取っていないことを意味します。 これは一般的に、仮想マシンの割り当てが解除されている場合に発生します。 この状態はリソースの状態を明確に示すものではありませんが、トラブルシューティングにとって重要なデータ ポイントである可能性がありまあす。
リソースが予期した通りに実行されている場合、リソースの状態は数分後に使用可能に変更されます。
リソースで問題が発生している場合、不明の正常性状態は、プラットフォーム内のイベントによってリソースが影響を受けていることを意味している可能性があります。
低下しています
低下は、リソースでパフォーマンス低下が検出されたものの、まだ使用可能であることを意味します。
低下と報告されるタイミングについては、リソースごとに独自の基準があります。
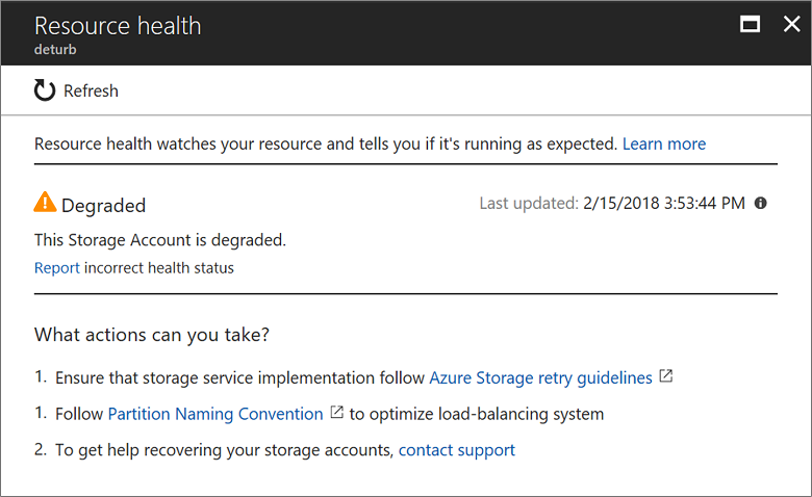
仮想マシン スケール セットの詳細については、「Azure 仮想マシン スケール セットのリソース正常性状態が "低下" している」を参照してください。
正常性はサポート対象外
メッセージ "正常性がサポートされていません" または "RP にこのリソースに関する情報がないか、そのリソースに対する読み取りおよび書き込みアクセス権がありません" は、正常性メトリックでリソースがサポートされていないことを意味します。
正常性メトリックをサポートするリソースについては、サポートされているリソースの種類に関するページを参照してください。
アクティビティ ログに送信されるリソース正常性のイベント
リソース正常性のイベントは、次の場合にアクティビティ ログに記録されます。
- たとえば、"ResourceDegraded" や "AccountClientThrottling" などの注釈がリソースに対して送信されます。
- リソースが異常へと、または異常から遷移しました。
- リソースが 15 分以上異常でした。
次のリソース正常性の遷移はアクティビティ ログに記録されません:
- 不明な状態への遷移。
- 不明な状態からの遷移 (次の場合):
- これが最初の遷移である場合。
- 不明の前の状態が、その後の新しい状態と同じ場合。 (たとえば、リソースが正常から不明に遷移し、正常に戻った場合)。
- コンピューティング リソースの場合: 正常から異常に遷移して正常に戻った VM で、異常な時間が 35 秒未満の場合。
履歴情報
Note
Events - List By Subscription Id REST API の QueryStartTime パラメーターを使用すると、サブスクリプション内の現在のサービス正常性イベントを一覧表示して最大 1 年間のデータを照会できます。ただし、Events - List By Single Resource REST API には現在 QueryStartTime パラメーターがないため、特定のリソースを対象に現在のサービス正常性イベントを一覧表示する場合は、最大 1 年間のデータを照会することができません。
Azure portal の Resource Health の [正常性の履歴] セクションで、最大 30 日間の履歴にアクセスできます。
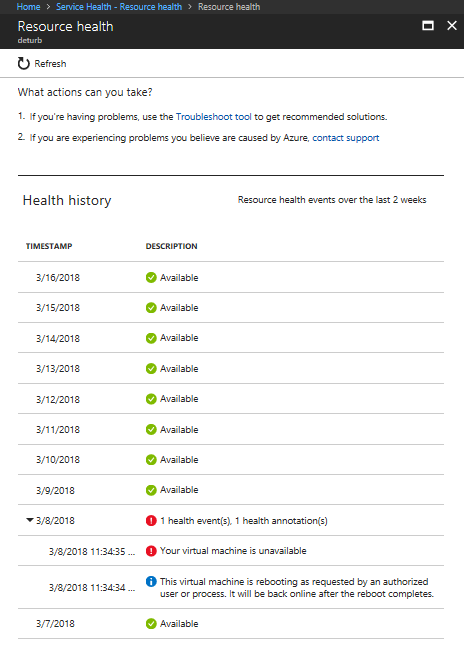
根本原因に関する情報
プラットフォームによって開始された使用不可の根本原因に関する詳細情報が Azure にある場合、その情報は、最初に使用不可になってから最大 72 時間は Resource Health に表示されている可能性があります。 この情報は、現在、仮想マシンについてのみ利用できます。
はじめに
1 つのリソースについて Resource Health を開くには
- Azure portal にサインインします。
- リソースを参照します。
- 左側のウィンドウのリソース メニューで、[リソース正常性] を選択します。
- 正常性履歴グリッドから PDF をダウンロードするか、[共有または管理] RCA ボタンをクリックします。
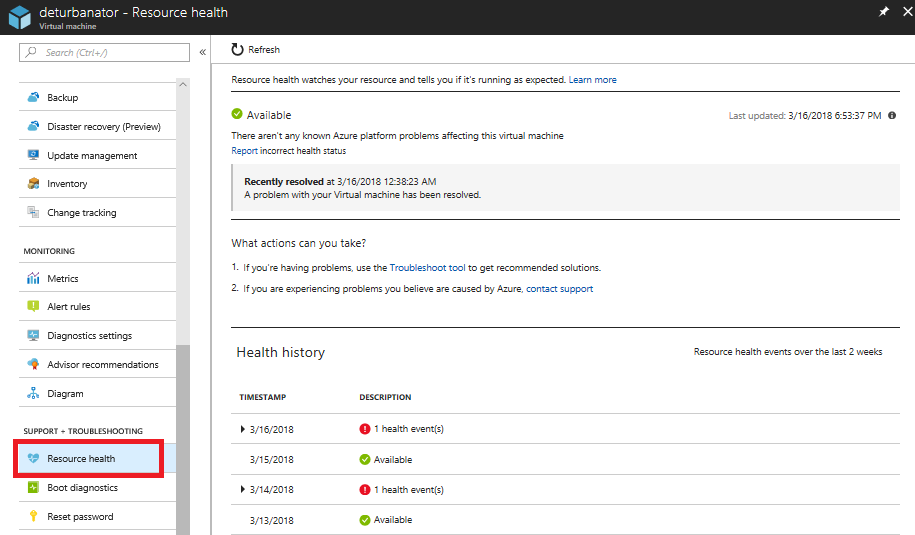
![Azure portal の [Resource Health] ペインのスクリーンショット。[利用不可] メッセージと [PDF としてダウンロード] ボタンと [RCA の共有または管理] ボタンが強調表示されています。](media/resource-health-overview/resource-health-history-grid.png#lightbox)
Resource Health には、[すべてのサービス] を選択し、フィルター テキスト ボックスに「resource health」と入力してアクセスすることもできます。 [ヘルプとサポート] ウィンドウで、[リソース正常性] を選択します。
![[すべてのサービス] から Resource Health を開く様子](media/resource-health-overview/fromotherservices.png)
次のステップ
Resource Health について詳しくは、次のリファレンスをご覧ください。