Azure Monitor ログを使用した Site Recovery の監視
この記事では、Azure Site Recovery によってレプリケートされたマシンを Azure Monitor ログと Log Analytics を使って監視する方法を説明します。
Azure Monitor ログは、アクティビティ ログとリソース ログを他の監視データと共に収集するログ データ プラットフォームです。 Azure Monitor ログ内で、Log Analytics を使用してログ クエリを記述し、テストすることや、ログ データを対話形式で分析することができます。 ログの結果を可視化してクエリを実行したり、監視対象データに基づいてアクションを実行するようにアラートを構成したりすることが可能です。
Site Recovery では、Azure Monitor ログを次の目的に使用できます。
- Site Recovery の正常性と状態を監視する。 たとえば、レプリケーションの正常性、テスト フェールオーバーの状態、Site Recovery のイベント、保護対象マシンの RPO (目標復旧ポイント)、ディスク (またはデータ) の変更量を監視することができます。
- Site Recovery のアラートを設定する。 たとえば、マシンの正常性、テスト フェールオーバーの状態、Site Recovery ジョブの状態に対するアラートを構成することができます。
Site Recovery での Azure Monitor ログの使用は、Azure から Azure へのレプリケーションと VMware 仮想マシンまたは物理サーバーから Azure へのレプリケーションでサポートされます。
Note
チャーン データ ログを取得し、VMware と物理マシンのレート ログをアップロードするには、プロセス サーバーに Microsoft 監視エージェントをインストールする必要があります。 このエージェントからワークスペースに、複製を行うコンピューターのログが送信されます。 この機能は、モビリティ エージェントのバージョン 9.30 以降でのみ利用できます。
前提条件
次のものが必要です。
- 少なくとも 1 つのマシンが Recovery Services コンテナー内で保護されている。
- Site Recovery のログを格納するための Log Analytics ワークスペース。 ワークスペースの設定に関する説明を参照してください。
- Log Analytics におけるログ クエリの記述、実行、分析の方法に関する基本的な理解。 詳細情報。
最初に、監視についての一般的な質問を確認しておくことをお勧めします。
Azure Site Recovery で使用できるイベント ログ
Azure Site Recovery には、次のリソース固有のテーブルとレガシ テーブルが用意されています。 各イベントによって、サイトの回復関連成果物の特定のセットに関する詳細なデータが提供されます。
リソース固有のテーブル:
レガシ テーブル:
- Azure Site Recovery イベント
- Azure Site Recovery レプリケートされた項目
- Azure Site Recovery レプリケーション状態
- Azure Site Recovery ポイント
- Azure Site Recovery のレプリケーション データ アップロード速度
- Azure Site Recovery で保護されたディスクのデータ変更頻度
- Azure Site Recovery でレプリケートされた項目の詳細
ログを送信するように Site Recovery を構成する
コンテナーで、[診断設定]>[診断設定を追加する] の順に選択します。
![[診断設定を追加する] オプションを示すスクリーンショット。](media/monitoring-log-analytics/add-diagnostic.png)
[診断設定] で名前を指定し、 [Log Analytics への送信] ボックスをオンにします。
Azure Monitor ログのサブスクリプションと Log Analytics ワークスペースを選択します。
トグルで [Azure Diagnostics] を選択します。
ログの一覧から、AzureSiteRecovery で始まるログをすべて選択します。 [OK] をクリックします。
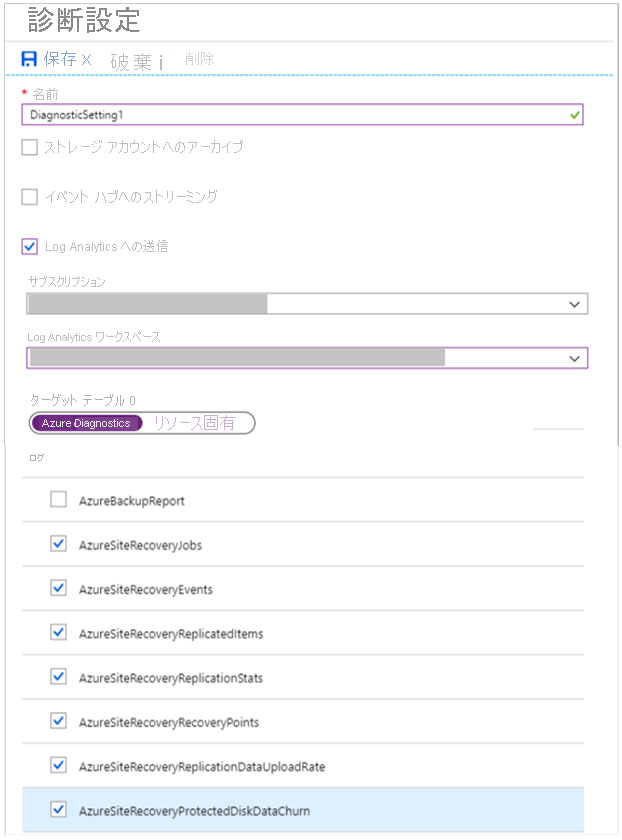
以後、選択したワークスペース内のテーブル (AzureDiagnostics) に Site Recovery のログが取り込まれます。
チャーンを送信し、レート ログをアップロードするように、プロセス サーバーで Microsoft 監視エージェントを構成する
オンプレミスで、VMware/物理マシンのデータ チャーン レート情報とソース データ アップロード レート情報を取得できます。 これを有効にするには、Microsoft 監視エージェントをプロセス サーバーにインストールする必要があります。
[Log Analytics] ワークスペースに移動し、[詳細設定] を選択します。
[接続されたソース] ページを選択し、[Windows サーバー] を選択します。
Windows エージェント (64 ビット) をプロセス サーバーにダウンロードします。
取得したワークスペース ID とキーを指定し、エージェントのインストールを完了します。
インストールが完了したら、Log Analytics ワークスペースに移動し、[レガシ エージェントの管理] を選択します。 [データ] ページに移動し、[Windows パフォーマンス カウンター] を選択します。
[+] を選択して、300 秒のサンプリング間隔を使用して次の 2 つのカウンターを追加します。
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
チャーンおよびアップロード レート データがワークスペースに送信されます。
現在、次の Azure Site Recovery カウンターは検索できません。
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
ただし、名前全体を貼り付けることで追加できます。

ASRAnalytics(*)\SourceVmChurnRateは、レプリケートされた仮想マシンのチャーン率に関する分析情報を提供します。ASRAnalytics(*)\SourceVmThrpRateは、レプリケーション中のソースとターゲットの間のデータ転送速度を示す、レプリケートされた仮想マシンのスループット速度を表します。
ログのクエリを実行する - 例
ログからデータを取得するには、Kusto 照会言語で記述されたログ クエリを使用します。 このセクションでは、Site Recovery の監視で一般的に使用されるクエリの例をいくつか紹介します。
Note
一部の例では、replicationProviderName_s を A2A に設定しています。 この場合、Site Recovery を使用してセカンダリ Azure リージョンにレプリケートされた Azure 仮想マシンが取得されます。 それらの例で、Site Recovery を使用して Azure にレプリケートされたオンプレミスの VMware 仮想マシンまたは物理サーバーを取得したい場合は、A2A を InMageRcm に置き換えてください。
レプリケーションの正常性を照会する
このクエリは、保護対象のすべての Azure 仮想マシンについて、最新のレプリケーションの正常性をノーマル、警告、クリティカルの 3 つの状態に分けて円グラフにプロットします。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Mobility Service のバージョンを照会する
このクエリは、Site Recovery を使ってレプリケートされた Azure 仮想マシンを、実行されている Mobility エージェントのバージョンごとに分けて円グラフにプロットします。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
RPO 時間を照会する
このクエリは、Site Recovery を使ってレプリケートされた Azure 仮想マシンを、目標復旧ポイント (RPO) (15 分未満、15 から 30 分、30 分超) ごとに分けて棒グラフにプロットします。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
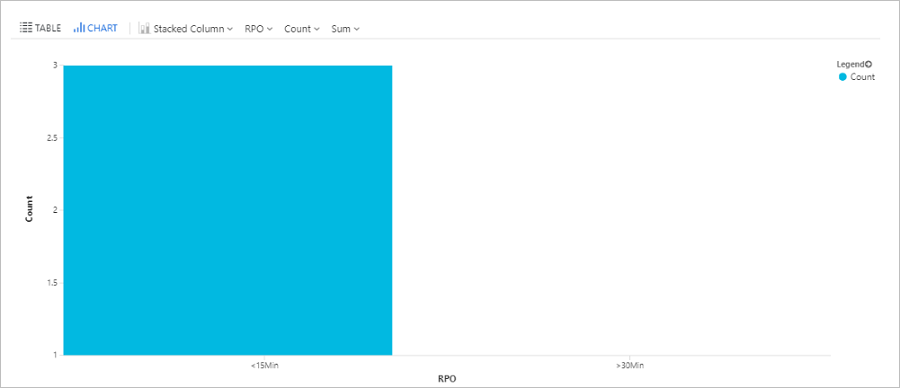
Site Recovery ジョブを照会する
このクエリは、(ディザスター リカバリーのあらゆるシナリオを対象に) 直近 72 時間以内にトリガーされたすべての Site Recovery ジョブとその完了状態を取得します。
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Site Recovery イベントを照会する
このクエリは、(ディザスター リカバリーのあらゆるシナリオを対象に) 直近 72 時間以内に発生したすべての Site Recovery イベントとその重大度を取得します。
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
テスト フェールオーバーの状態を照会する (円グラフ)
このクエリは、Site Recovery を使ってレプリケートされた Azure 仮想マシンのテスト フェールオーバーの状態を円グラフにプロットします。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
テスト フェールオーバーの状態を照会する (表)
このクエリは、Site Recovery を使ってレプリケートされた Azure 仮想マシンのテスト フェールオーバーの状態を表にプロットします。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
マシンの RPO を照会する
このクエリは、直近 72 時間における特定の Azure 仮想マシン (ContosoVM123) の RPO を追跡した傾向グラフをプロットします。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart
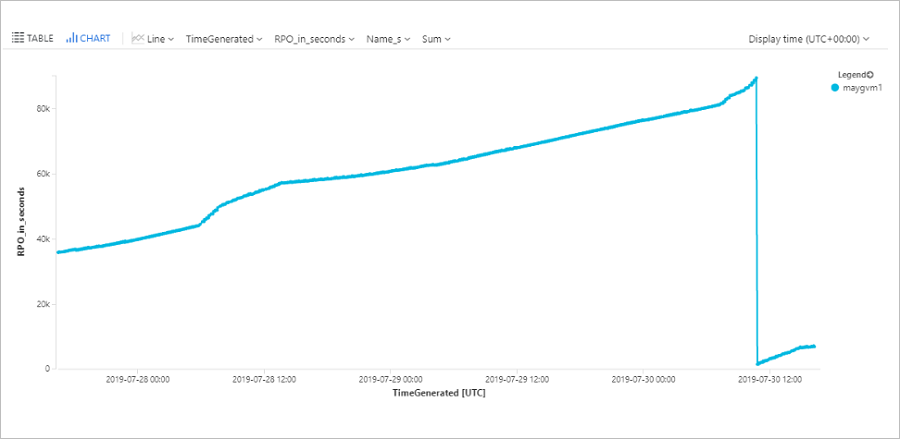
Azure 仮想マシンのデータ変更率 (チャーン) とアップロード率を照会する
このクエリによって、特定の Azure 仮想マシン (ContosoVM123) の傾向グラフが描画されます。そのグラフは、データ変更率 (秒あたりの書き込みバイト数) とデータ アップロード率を表わします。
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
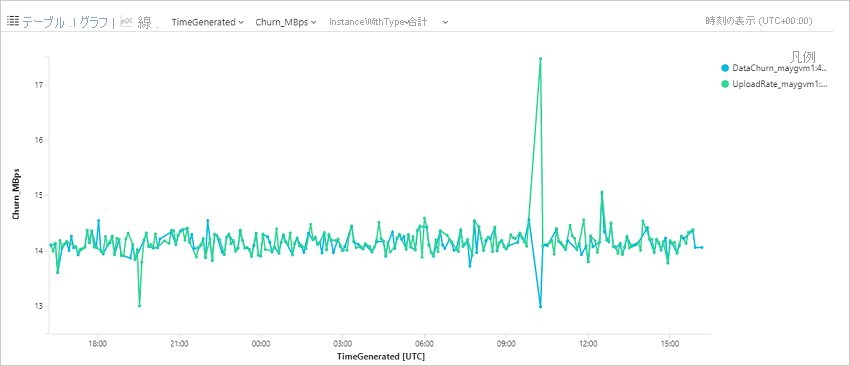
VMware または物理マシンのデータ変更率 (チャーン) とアップロード率を照会する
Note
これらのログをフェッチするようにプロセス サーバーで監視エージェントを設定します。 監視エージェントの構成手順はこちらを参照してください。
このクエリによって、複製アイテム win-9r7sfh9qlru の特定のディスク disk0 の傾向グラフが描画されます。そのグラフは、データ変更率 (1 秒あたりの書き込みバイト数) とデータ アップロード率を表わします。 Recovery Services コンテナーの複製アイテムの [ディスク] ブレードで、ディスクの名前を見つけることができます。 クエリで使用するインスタンス名は、この例のように、マシンの DNS 名の末尾に _ とディスク名を付けたものになります。
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
プロセス サーバーによってこのデータが 5 分おきに Log Analytics ワークスペースにプッシュされます。 これらのデータ ポイントは、5 分間に計算された平均を表わします。
ディザスター リカバリーのサマリーを照会する (Azure から Azure)
このクエリは、セカンダリ Azure リージョンにレプリケートされた Azure 仮想マシンのサマリー テーブルをプロットします。 仮想マシン名、レプリケーションと保護の状態、RPO、テスト フェールオーバーの状態、モビリティ エージェントのバージョン、アクティブなレプリケーション エラー、ソースの場所が示されます。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
ディザスター リカバリーのサマリーを照会する (VMware または物理サーバー)
このクエリは、Azure にレプリケートされた VMware 仮想マシンと物理サーバーのサマリー テーブルをプロットします。 マシン名、レプリケーションと保護の状態、RPO、テスト フェールオーバーの状態、モビリティ エージェントのバージョン、アクティブなレプリケーション エラー、関連するプロセス サーバーが示されます。
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
アラートを設定する - 例
Azure Monitor のデータに基づいて Site Recovery のアラートを設定できます。 ログ アラートの設定に関する詳細情報を参照してください。
Note
一部の例では、replicationProviderName_s を A2A に設定しています。 この場合、セカンダリ Azure リージョンにレプリケートされた Azure 仮想マシンのアラートが設定されます。 それらの例で、Azure にレプリケートされたオンプレミスの VMware 仮想マシンまたは物理サーバーのアラートを設定したい場合は、A2A を InMageRcm に置き換えてください。
複数のマシンがクリティカル状態
レプリケートされた Azure 仮想マシンのうち、クリティカル状態になった仮想マシンが 20 を超えた場合のアラートを設定します。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
このアラートでは、しきい値を 20 に設定します。
1 つのマシンがクリティカル状態
レプリケートされた特定の Azure 仮想マシンがクリティカル状態になった場合のアラートを設定します。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
このアラートでは、しきい値を 1 に設定します。
複数のマシンが RPO を超過
20 個を超える Azure 仮想マシンで RPO が 30 分を超過した場合のアラートを設定します。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
このアラートでは、しきい値を 20 に設定します。
1 つのマシンが RPO を超過
1 つの Azure 仮想マシンで RPO が 30 分を超過した場合のアラートを設定します。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
このアラートでは、しきい値を 1 に設定します。
複数のマシンのテスト フェールオーバーが 90 日を超過
テスト フェールオーバーが最後に成功してからの経過日数が 90 日を超える仮想マシンが 20 個を超えた場合のアラートを設定します。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
このアラートでは、しきい値を 20 に設定します。
1 つのマシンのテスト フェールオーバーが 90 日を超過
特定の仮想マシンでテスト フェールオーバーが最後に成功してからの経過日数が 90 日を超えた場合のアラートを設定します。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
このアラートでは、しきい値を 1 に設定します。
Site Recovery ジョブの失敗
Site Recovery のすべてのシナリオを対象に、直近 24 時間に Site Recovery ジョブ (このケースでは再保護ジョブ) が失敗した場合のアラートを設定します。
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
このアラートでは、しきい値を 1 に、期間を 1,440 分に設定して、直近 24 時間の失敗をチェックします。
次のステップ
Site Recovery のビルトインの監視機能に関する説明を参照してください。