Premium ブロック BLOB ストレージ アカウントにより、高性能なハードウェア経由でデータを利用できます。 データは、低待機時間のために最適化されたソリッドステート ドライブ (SSD) に格納されています。 SSD は従来のハード ドライブと比べ、スループットが高くなります。 データがすぐにアクセス可能なメモリ チップに格納されるので、ファイル転送がはるかに高速になります。 ドライブのすべての部分に一度にアクセスできます。 これに対し、ハード ディスク ドライブ (HDD) のパフォーマンスは、読み取り/書き込みヘッドへのデータの近さによって異なります。
ハイ パフォーマンス ワークロード
Premium ブロック BLOB ストレージ アカウントは、高速の一貫した応答時間を必要とするワークロードや、1 秒あたりの入出力操作数 (IOP) が多いワークロードに最適です。 ワークロードの例を次に示します。
対話型ワークロード。 高度に対話型のリアルタイム アプリケーションでは、データをすばやく書き込む必要があります。 eコマースやマッピング アプリケーションでは、多くの場合に即時の更新とユーザーからのフィードバックが必要です。 たとえば、eコマース アプリケーションでは、表示頻度の低い項目はキャッシュされない可能性があります。 ただし、要求時には顧客に瞬時に表示される必要があります。 対話型編集またはマルチプレーヤー オンライン ゲーム アプリケーションでは、リアルタイムの更新を提供することで、質の高いエクスペリエンスが維持されます。
IoT/ストリーミング分析. IoT シナリオでは、毎秒、小さな書き込み操作がクラウドにプッシュされる可能性があります。 大量のデータが収集され、分析のために集計され、ほぼ瞬時に削除される場合があります。 Premium ブロック BLOB ストレージのインジェスト機能を利用すると、この種類のワークロードに効率的に対応できます。
人工知能/機械学習 (AI/ML) 。 AI/ML では、ビジュアル、音声、テキストなどのさまざまなデータの種類の使用と処理を扱います。 このハイ パフォーマンス コンピューティング型のワークロードでは大量のデータが処理されますが、データ分析のために迅速な応答と効率的なインジェスト時間が必要です。
コスト効率
Premium ブロック BLOB ストレージ アカウントでは、Standard 汎用 v2 アカウントと比較してストレージ コストは高くなりますが、トランザクション コストは低くなります。 アプリケーションとワークロードで多数のトランザクションが実行される場合、特にワークロードの書き込み負荷が高い場合に、Premium ブロック BLOB ストレージのコスト効率が高くなる可能性があります。
ほとんどの場合、テラバイトあたり毎秒 (TPS/TB) 35 から 40 を超えるトランザクションを実行するワークロードは、この種類のアカウントに適しています。 たとえば、ワークロードが 1 か月に 5 億回の読み取り操作と 1 億回の書き込み操作を実行する場合、次のように TPS/TB を計算できます。
1 秒あたりの書き込みトランザクション数 = 100,000,000 / (30 x 24 x 60 x 60) = 39 (最も近い整数に丸められます)
1 秒あたりの読み取りトランザクション数 = 500,000,000 / (30 x 24 x 60 x 60) = 193 (最も近い整数に丸められます)
1 秒あたりの合計トランザクション数 = 193 + 39 = 232
アカウントに、平均 5TB のデータがあったとすると、TPS/TB は 230/5 = 46 になります。
注
価格は、操作ごと、およびリージョンごとに異なります。 Azure 料金計算ツールを使用して、Standard パフォーマンス レベルと Premium パフォーマンス レベルの価格を比較します。
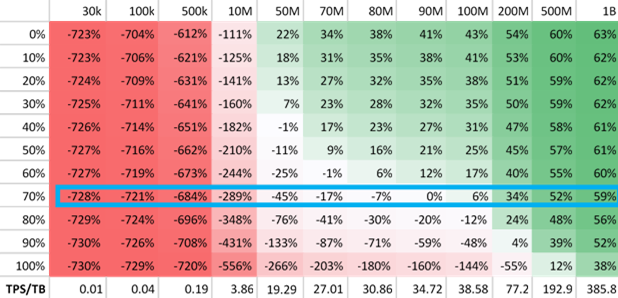
次の表に、Premium ブロック BLOB ストレージ アカウントのコスト効率を示しています。 この表の数値は、Azure Data Lake Storage 対応 Premium ブロック BLOB ストレージ アカウント (Azure Data Lake Storage の Premium レベルとも呼ばれます) に基づいています。 各列は、1 か月のトランザクション数を表します。 各行は、読み取りトランザクションであるトランザクションのパーセンテージを表します。 表内の各セルは、読み取りトランザクションのパーセンテージと実行されたトランザクション数に関連付けたコスト削減率を示しています。
たとえば、お使いのアカウントが米国東部 2 リージョンにあり、そのアカウントでのトランザクションの数が 90M を超えていて、それらのトランザクションの 70% が読み取りトランザクションである場合、Premium ブロック BLOB ストレージ アカウントの方がコスト効率が高くなります。
注
データ 1 TB ごとの 1 秒あたりのトランザクション数に基づいてコスト効率を評価する場合は、表の下部に示されている列見出しを使用できます。
Premium シナリオ
このセクションでは、いくつかの Azure Storage パートナーが Premium ブロック BLOB ストレージを使用する方法の実際の例を記載しています。 また、それらの一部では、Azure Data Lake Storage も有効にしています。これにより、特定のシナリオでトランザクションのパフォーマンスをさらに高めることができる階層ファイル構造が導入されます。
ヒント
分析のユース ケースがある場合は、Azure Data Lake Storage と Premium ブロック BLOB ストレージ アカウントを使用することを強くお勧めします。
このセクションには、次の例が含まれています。
高速データ ハイドレーション
Premium ブロック BLOB ストレージは、環境を迅速にハイドレートつまり立ち上げるのに役立ちます。 バンキングなどの業界では、特定の規制要件により、企業は環境を定期的に解体し、最初から回復させる必要がある場合があります。 環境をハイドレートするために使用されるデータは、迅速に読み込まれる必要があります。
一部のパートナーは、毎週 MongoDB インスタンスのコピーを Premium ブロック BLOB ストレージ アカウントに格納しています。 その後、システムは解体されます。 システムをもう一度速やかにオンラインに戻すために、MongoDB インスタンスの最新のコピーが読み取られ、読み込まれます。 監査のために、以前のコピーは一定期間クラウド ストレージに保持されます。
対話型編集アプリケーション
複数のユーザーが同じコンテンツを編集するアプリケーションでは、スムーズなユーザー エクスペリエンスのために更新の速度が重要になります。
一部のパートナーは、ビデオ編集ソフトウェアを開発しています。 ユーザーがビデオに行ったすべての更新は、他のユーザーにすぐに表示されます。 ユーザーは、コンテンツの更新が表示されるまで待つことなく、自分のタスクに集中できます。 Premium ブロック BLOB ストレージに関連する低待機時間は、このシームレスなコラボレーション エクスペリエンスの作成に役立ちます。
データ視覚化ソフトウェア
レンダリング時間が短い場合、データ視覚化ソフトウェアで、ユーザーの生産性がはるかに向上する可能性があります。
地図作製業界の企業では、地図作製エディターを使用して地図の問題を検出しています。 これらのエディターでは、顧客の Global Positioning System (GPS) データから生成されたデータが使われます。 地図の重複を作成するために、編集ソフトウェアではキー検索をすばやく実行することで、地図の小さなセクションがレンダリングされます。
あるケースでは、Premium ブロック BLOB ストレージを使用する前に、パートナーは Standard 汎用 v2 ストレージによってサポートされる HBase クラスターを使用していました。 ただし、常時大規模なクラスターを実行し続けるためのコストが上昇してきました。 このパートナーは、このアーキテクチャから移行し、代わりに高速のキー検索のために Premium ブロック BLOB ストレージを使用することを決定しました。 重複を作成するために、REST API を使用して GPS 座標に対応するタイルをレンダリングしました。 Premium ブロック BLOB ストレージ アカウントにより、コスト効率の高いソリューションが提供され、待機時間がはるかに予測可能になりました。
eコマース企業
eコマース企業は、顧客向けストアのサポートに加えて、データ ウェアハウスと分析ソリューションを内部チームに提供する場合もあります。 Premium ブロック BLOB ストレージ アカウントを使用して、これらのデータ ウェアハウスおよび分析ソリューションによって待機時間の短縮要件をサポートしているパートナーを見てきました。 あるケースでは、カタログ チームが、オファー、価格、出荷方法、サプライヤー、在庫、物流に関連するデータのデータ ウェアハウス アプリケーションを管理しています。 情報は、多数のユース ケース用にクエリ、スキャン、抽出、およびマイニングされます。 チームは、このデータに対する分析を実行して、さまざまなマーチャンダイジング チームに関連分析情報や情報を提供します。
対話型分析
ほぼすべての業界で、企業はデータのクエリと分析を対話形式で行う必要があります。
データ サイエンティスト、アナリスト、開発者は、Premium ブロック BLOB ストレージ アカウントに格納されているデータに対してクエリを実行することで、時間的制約のある分析情報をより迅速に抽出できます。 エグゼクティブは、ダッシュボードに表示されるデータが Standard 汎用 v2 アカウントではなく Premium ブロック BLOB ストレージ アカウントから取得される場合に、はるかに迅速にダッシュボードを読み込むことができます。
1 つのシナリオでは、アナリストは、何百万ものデバイスからのテレメトリ データをすばやく分析して、製品の使い方をよりよく理解し、製品リリースの決定を行う必要がありました。 データを SQL データベースに格納することは、コストがかかります。 コストを削減し、クエリ可能なセキュリティを向上するために、Azure Data Lake Storage 対応の Premium ブロック BLOB ストレージ アカウントを使用し、Presto と Spark で計算を実行して Hive テーブルから分析情報を生成しました。 このように、めったにアクセスされないデータでも、頻繁にアクセスされるデータが持つ計算能力とすべて同じ計算能力を持ちます。
SQL の秒未満のパフォーマンスと Presto の外部ストレージへの 1 秒あたりの入出力操作数 (IOP) の間のギャップを埋めるには、特に小さな Optimized Row Columnar (ORC) ファイルを処理する場合に、一貫性とスピードが重要です。 Data Lake Storage と一緒に使用する場合の Premium ブロック BLOB ストレージ アカウントは、このシナリオで、Standard 汎用 v2 アカウントの 3 倍のパフォーマンスの向上が繰り返し実証されています。 クエリは、コンピューティング マシンにローカルと感じるほど高速に実行されました。
別のケースでは、パートナーは、セキュリティ ソリューションから生成されたログを格納してクエリを実行しています。 ログは Databricks を使用して生成され、次に Data Lake Storage 対応 Premium ブロック BLOB ストレージ アカウントに格納されます。 エンド ユーザーは、Azure Data Explorer を使用して、このデータに対してクエリを実行して検索しています。 この種類のアカウントを選択することで、安定性を高め、対話型クエリのパフォーマンスを向上させています。 さらに、ライフ サイクル管理 Delete Action ポリシーを数日に設定しており、これはコストを削減するのに役立ちます。 このポリシーにより、データが永久に保持されることを防ぎます。 代わりに、データは不要になると削除されます。
データ処理パイプライン
ほぼすべての業界で、企業はデータを処理する必要があります。 複数のソースからの生データは、ユーザーの意思決定に役立つデータ ダッシュボードなどのツールでのダウンストリームの使用に役立つように、クレンジングして処理する必要があります。
データを処理する場合に、処理速度が常にトップの懸念事項になるとは限りませんが、一部の業界ではそれが必要です。 たとえば、金融サービス業界の企業は、多くの場合、可能な限り確実かつ最も迅速な方法でデータを処理する必要があります。 不正を検出するために、それらの企業はさまざまなソースからの入力を処理し、顧客に対するリスクを特定し、すばやいアクションを起こす必要があります。
場合によっては、パートナーが複数の Standard Storage アカウントを使用してさまざまなソースのデータを格納していることがわかりました。 さらに、このデータの一部が Data Lake Storage 対応 Premium ブロック BLOB ストレージ アカウントに移動され、そこでデータ処理アプリケーションによって新しく到着するデータが頻繁に読み取られます。 このアカウントのディレクトリ一覧の呼び出しは、そうでなければ Standard 汎用 v2 アカウントで実行する場合よりもはるかに高速で、はるかに一貫して実行されました。 アカウントによって提供される速度と一貫性により、新しいデータが常にダウンストリーム処理システムで迅速に使用できるようになりました。 これは、潜在的なセキュリティ リスクを迅速にキャッチして対応するのに役立ちました。
モノのインターネット(IoT)
IoT は、日常生活の重要な部分になっています。 IoT は、車の動きを追跡し、照明を制御し、健康を監視するために使用されます。 また、産業用アプリケーションもあります。 たとえば、企業は IoT を使用して、スマート ファクトリ プロジェクトを可能にし、農業生産を改善し、石油掘削装置で予知保全のために使用します。 Premium ブロック BLOB ストレージ アカウントによって、これらのシナリオに大きな価値が加わります。
鉱業のパートナーがいます。 Data Lake Storage を使用してプレミアムブロックBLOBストレージアカウントを有効にし、HDInsight (HBase) と組み合わせて、非常に負荷の高いプロファイルで複数のマイニング機器タイプから時系列センサーデータを収集します。 Premium ブロック BLOB ストレージは、高いサンプル レートのインジェストに対するニーズを満たすのに役立ちました。 さらに、Premium ブロック BLOB ストレージは大量の書き込みトランザクションを実行するワークロード用にコスト最適化されていますが、このワークロードでは (1 秒あたり数万単位で) 多数の小さな書き込みトランザクションが生成されるため、コスト効率にも優れています。
機械学習
多くの場合、機械学習モデルをトレーニングするには、大量のデータを処理する必要があります。 この処理を完了するために、コンピューティング マシンを長時間実行する必要があります。 ストレージ コストと比較して、コンピューティング コストは通常、請求額のはるかに大きな割合を占めるので、コンピューティング マシンの実行時間の短縮によって、大幅な節約につながる可能性があります。 Premium ブロック BLOB ストレージを使用して得られる待機時間の短縮によって、この時間と請求額を大幅に削減できます。
Spark クラスターにデータ処理パイプラインをデプロイして、機械学習のトレーニングと推論を実行しているパートナーがいます。 Spark テーブル (parquet ファイル) とチェックポイントを Premium ブロック BLOB ストレージ アカウントに格納しています。 Spark チェックポイントによって、多数の入れ子になったファイルやフォルダーを作成できます。 それらのディレクトリ リスティング操作は、待機時間の短い Premium ブロック BLOB ストレージ アカウントと、Data Lake Storage で使用できる階層データ構造を組み合わせたため、高速です。
また、IoT と機械学習が交差するユース ケースがある半導体業界のパートナーもいます。 製造工場のマシンに接続されている IoT デバイスは、半導体のウェハーの画像を取得し、それらをアカウントに送信します。 システムでは、ディープ ラーニング推論を使用して、プロダクションに問題がある場合や、アクションを実行する必要がある場合に、オンプレミスのマシンに通知できます。 画像を迅速かつ確実に読み込み、処理する必要があります。 Data Lake Storage 対応 Premium ブロック BLOB ストレージ アカウントを使用すると、これを可能にするのに役立ちます。
リアルタイム ストリーミング分析
対話型分析をほぼリアルタイムでサポートするには、システムで大量のデータを取り込んで処理し、そのデータをダウンストリーム システムで使用できるようにする必要があります。 Data Lake Storage 対応 Premium ブロック BLOB ストレージ アカウントを使用することは、こうした種類のシナリオに最適です。
メディアやエンターテイメント業界の企業は、イベントを放送する際に、短時間で大量のログとテレメトリ データを生成できます。 一部のパートナーは、ストリーミングのために複数のコンテンツ配信ネットワーク (CDN) パートナーに依存しています。 どの CDN パートナーにトラフィックを割り当てるかについて、ほぼリアルタイムで決断を下す必要があります。 そのため、データの取り込み後、数秒でクエリを実行するためにデータを使用できるようにする必要があります。 この迅速な意思決定を促進するために、Premium ブロック BLOB ストレージ内の格納データを使用し、そのデータを Azure Data Explorer (ADX) で処理します。 ストレージにアップロードされるテレメトリはすべて ADX で変換されるため、オペレーターやエグゼクティブがすばやく確実にクエリを実行できる使い慣れた形式で格納できます。
データは、複数の Premium パフォーマンス BLOB Storage アカウントにアップロードされます。 各アカウントは、Event Grid およびイベント ハブに接続されます。 ADX では Blob Storage からデータが取得され、データを正規化するために必要な変換が実行されます (zip ファイルの圧縮解除や JSON から CSV への変換など)。 その後、ADX と、Grafana に表示されるダッシュボードを通じて、データをクエリに使用できるようになります。 Grafana ダッシュボードは、オペレーター、エグゼクティブ、その他のユーザーによって使用されます。 お客様は元のログを Premium パフォーマンス ストレージに保持するか、汎用 v2 ストレージ アカウントにコピーします。そこで、それらを長期間の保持と将来の分析のためにホットアクセス層またはクール アクセス層に格納できます。
Premium の概要
まず、お気に入りの BLOB ストレージ機能が Premium ブロック BLOB ストレージ アカウントと互換性があることを確認してから、アカウントを作成します。
注
既存の Standard 汎用 v2 ストレージ アカウントを Premium ブロック BLOB ストレージ アカウントに変換することはできません。 Premium ブロック BLOB ストレージ アカウントに移行するには、Premium ブロック BLOB ストレージ アカウントを作成し、データを新しいアカウントに移行する必要があります。
Blob ストレージ機能の互換性を確認する
一部の BLOB ストレージ機能はまだサポートされていないか、Premium ブロック BLOB ストレージ アカウントでは部分的にしかサポートされていません。 Premium を選択する前に、「Azure ストレージ アカウントにおける Blob Storage 機能のサポート」という記事を確認し、使用する予定の機能がお使いのアカウントで完全にサポートされているかどうかを判断してください。 機能のサポートは常に拡張されているため、この記事の更新について定期的に確認してください。
新しいストレージ アカウントを作成する
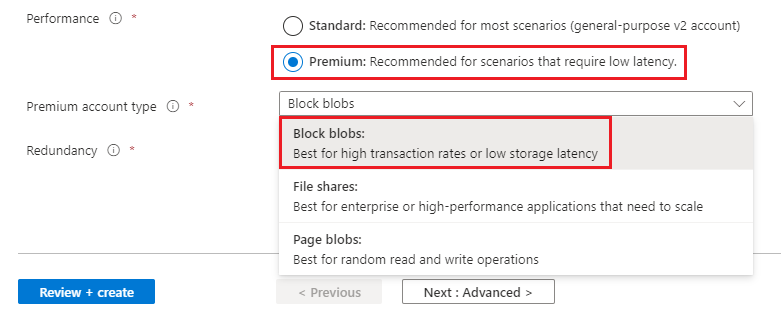
Premium ブロック BLOB ストレージ アカウントを作成するには、アカウントを作成するときに、[Premium] パフォーマンスのオプションと [ブロック BLOB] アカウントの種類を選択してください。
注
一部の BLOB ストレージ機能はまだサポートされていないか、Premium ブロック BLOB ストレージ アカウントでは部分的にしかサポートされていません。 Premium を選択する前に、「Azure ストレージ アカウントにおける Blob Storage 機能のサポート」という記事を確認し、使用する予定の機能がお使いのアカウントで完全にサポートされているかどうかを判断してください。 機能のサポートは常に拡張されているため、この記事の更新について定期的に確認してください。
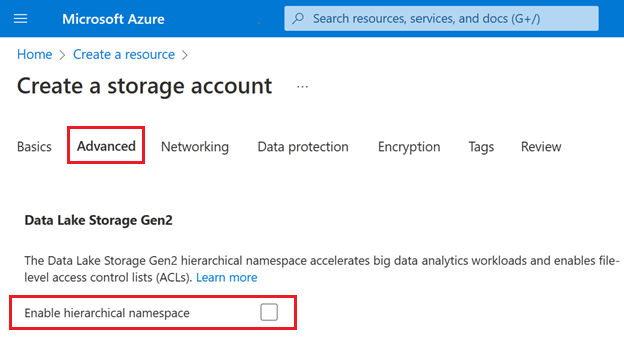
ストレージ アカウントを分析に使用する場合は、Premium ブロック BLOB ストレージ アカウントと共に Azure Data Lake Storage を使用することを強くお勧めします。 Azure Data Lake Storage の機能をロック解除するには、[ストレージ アカウントの作成] ページの [詳細設定] タブで [階層型名前空間] 設定を有効にします。
次の図は、 [ストレージ アカウントの作成] ページのこの設定を示しています。
詳細なガイダンスについては、「ストレージ アカウントを作成する」を参照してください。