StorSimple 1200 の Azure File Sync への移行
StorSimple 1200 シリーズは、オンプレミスのデータ センターで実行される仮想アプライアンスです。 このアプライアンスから Azure File Sync 環境にデータを移行できます。 Azure File Sync は、StorSimple アプライアンスの移行先となる、既定の戦略的な長期 Azure サービスです。 この記事では、Azure File Sync への移行を成功させるために必要な背景知識と移行手順について説明します。
注意
StorSimple サービス (8000 および 1200 シリーズと StorSimple Data Manager 用の StorSimple デバイス マネージャーを含む) がサポート終了に達しました。 StorSimple のサポート終了は、2019 年に Microsoft ライフサイクル ポリシーと Azure のお知らせのページで発表されました。 追加の通知がメールで送られ、Azure portal と StorSimple の概要に関するページに掲示されました。 詳しくは、Microsoft サポートにお問い合わせください。
適用対象
| ファイル共有の種類 | SMB | NFS |
|---|---|---|
| Standard ファイル共有 (GPv2)、LRS/ZRS | ||
| Standard ファイル共有 (GPv2)、GRS/GZRS | ||
| Premium ファイル共有 (FileStorage)、LRS/ZRS |
Azure File Sync
Azure File Sync は、次の 2 つの主要なコンポーネントに基づく Microsoft のクラウド サービスです。
- ファイルの同期とクラウドを使った階層化。
- Azure のネイティブ ストレージとしてのファイル共有。SMB や file REST などの複数のプロトコルを介してアクセスできます。 Azure ファイル共有は、ネットワーク ドライブとしてネイティブにマウントできる Windows サーバー上のファイル共有に相当します。 属性、アクセス許可、タイムスタンプなどの重要なファイルの忠実性がサポートされています。 StorSimple とは異なり、クラウドに格納されているファイルとフォルダーを解釈するためにアプリケーションやサービスは必要ありません。 汎用のファイル サーバー データや一部のアプリケーション データをクラウドに格納するための、理想的で最も柔軟な方法です。
この記事では、移行手順を中心に説明します。 移行前に Azure File Sync について詳しく知りたい場合は、次の記事をお勧めします。
移行の目標
目標は、運用データの整合性と可用性を保証することです。 後者については、ダウンタイムを最小限に抑えて、通常のメンテナンス期間に収まるか、わずかに超えるだけで済むようにする必要があります。
StorSimple 1200 の Azure File Sync への移行パス
Azure File Sync エージェントを実行するには、ローカル Windows Server が必要です。 Windows サーバーは、2012R2 サーバー以降であれば使用できますが、理想的なのは Windows Server 2019 です。
代替の移行パスは多数あり、そのすべてを説明し、この記事でベスト プラクティスとして推奨されているルートと比較してそれらのリスクや欠点が大きい理由を説明しようとすると、記事があまりに長くなります。
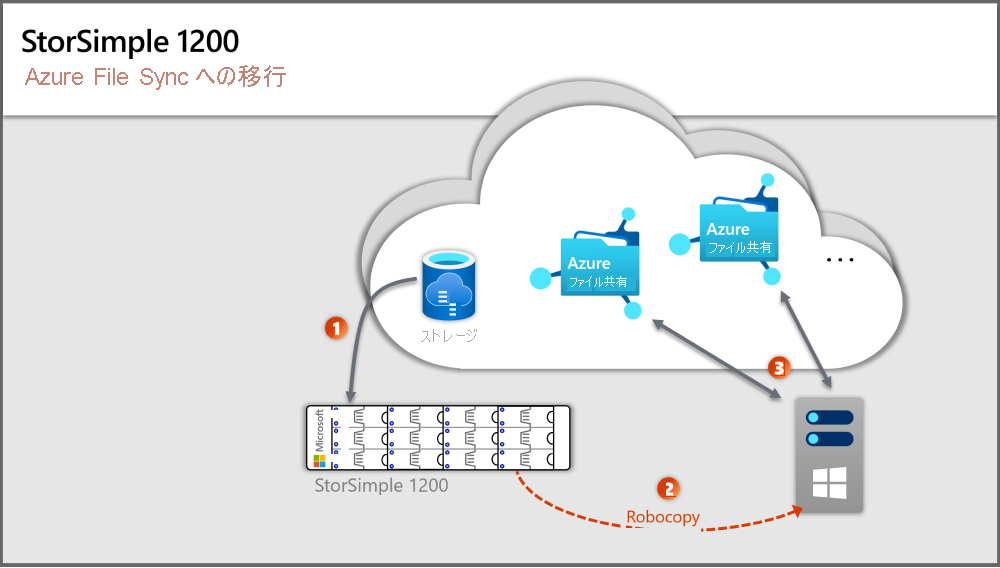
上の図は、この記事のセクションに対応する手順を示したものです。
手順 1:オンプレミスの Windows Server とストレージをプロビジョニングする
- 仮想マシンまたは物理サーバーとして、Windows Server 2019 (最低でも 2012R2) を作成します。 Windows Server フェールオーバー クラスターもサポートされています。
- 直接接続記憶域 (NAS ではなく DAS、NAS はサポートされていません) をプロビジョニングまたは追加します。 Windows Server 記憶域のサイズは、StorSimple 1200 仮想アプライアンスの利用可能な容量のサイズ以上である必要があります。
手順 2:Windows Server の記憶域を構成する
この手順では、StorSimple ストレージの構造 (ボリュームと共有) を Windows Server 記憶域の構造にマップします。 ストレージの構造を変更する場合は (ボリュームの数、データ フォルダーとボリュームの関連付け、現在の SMB/NFS 共有の上位または下位のサブフォルダー構造)、ここでこれらの変更を考慮する必要があります。 Azure File Sync の構成後にファイルとフォルダーの構造を変更するのは面倒であり、避ける必要があります。 この記事では、マッピングが 1:1 であると想定しているため、この記事の手順に従うときはマッピングの変更を考慮する必要があります。
- 運用データが、最終的に Windows Server のシステム ボリュームに格納されてはなりません。 システム ボリュームでは、クラウドを使った階層化はサポートされていません。 ただし、移行および StorSimple の代替環境としての継続的な運用には、この機能が必要です。
- StorSimple 1200 仮想アプライアンスと同じ数のボリュームを、Windows Server にプロビジョニングします。
- 必要な Windows Server の役割、機能、設定を構成します。 OS を安全で最新の状態に保つため、Windows Server の更新プログラムにオプトインすることをお勧めします。 同様に、Azure File Sync エージェントなど、Microsoft のアプリケーションを最新の状態に保つため、Microsoft Update にオプトインすることをお勧めします。
- 以下の手順を読む前に、フォルダーまたは共有を構成しないでください。
手順 3:最初の Azure File Sync クラウド リソースをデプロイする
この手順を完了するには、Azure サブスクリプションの資格情報が必要です。
Azure File Sync を構成するためのコア リソースは、"ストレージ同期サービス" と呼ばれます。 同じファイル セットを今すぐ、または今後同期するすべてのサーバーに対して、1 つのみをデプロイすることをお勧めします。 データを交換する必要のない個別のサーバー セットがある場合のみ、複数のストレージ同期サービスを作成します。 たとえば、同じ Azure ファイル共有を同期しないようにする必要があるサーバーがある場合です。 それ以外の場合は、1 つのストレージ同期サービスを使用することをお勧めします。
ストレージ同期サービスには、自分の場所に近い Azure リージョンを選択します。 他のすべてのクラウド リソースは、同じリージョンにデプロイする必要があります。 管理が簡単になるように、サブスクリプションに新しいリソース グループを作成し、同期リソースとストレージ リソースを格納します。
詳細については、「Azure File Sync のデプロイ」の記事にあるストレージ同期サービスのデプロイに関するセクションを参照してください。記事のこのセクションのみに従います。 後の手順に、この記事の他のセクションへのリンクがあります。
手順 4:ローカル ボリュームとフォルダー構造を Azure File Sync および Azure ファイル共有リソースと一致させる
この手順では、必要な Azure ファイル共有の数を決定します。 1 つの Windows Server インスタンス (またはクラスター) では、最大 30 個の Azure ファイル共有を同期できます。
現在、SMB 共有としてユーザーとアプリに対してローカルに共有しているボリュームには、さらに多くのフォルダーが存在する場合があります。 このシナリオを理解する最も簡単な方法は、1:1 で Azure ファイル共有にマップするオンプレミスの共有を想像することです。 1 つの Windows Server インスタンスの共有数が 30 以下と十分に少ない場合は、1 対 1 のマッピングをお勧めします。
共有の数が 30 を超える場合、通常オンプレミスの共有を 1 対 1 で Azure ファイル共有にマッピングする必要はありません。 次のオプションを検討してください。
共有のグループ化
たとえば、人事 (HR) 部門に 15 個の共有がある場合、すべての HR データを 1 つの Azure ファイル共有に格納することを検討できます。 1 つの Azure ファイル共有にオンプレミスの共有を複数格納しても、ローカルの Windows Server インスタンスに通常の 15 個の SMB 共有を作成できます。 これは、単にこれらの 15 個の共有のルート フォルダーを共通フォルダーの下のサブフォルダーとして整理することを意味します。 その後、この共通フォルダーを Azure ファイル共有に同期します。 そうすることで、このオンプレミスの共有グループに必要なのは、クラウド内の 1 つの Azure ファイル共有のみとなります。
ボリュームの同期
Azure File Sync では、ボリュームのルートを Azure ファイル共有に同期することをサポートしています。 ボリューム ルートを同期した場合、すべてのサブフォルダーとファイルは同じ Azure ファイル共有に格納されます。
ボリュームのルートを同期することが常に最適なオプションであるとは限りません。 複数の場所に同期することには利点があります。 たとえば、そうすることで、同期スコープあたりの項目数を少なく抑えることができます。 Azure ファイル共有と Azure File Sync は、共有ごとに 1 億個の項目 (ファイルとフォルダ) を保持できるようテストされています。 ただし、ベスト プラクティスとしては、1 つの共有に保持する項目数は、2000 万から 3000 万個未満にすることをお勧めします。 Azure File Sync に含める項目数を少数に設定することは、ファイルの同期にとって有益というだけではありません。項目の数が少ないと、次のようなシナリオでも利点があります。
- クラウド コンテンツの初期スキャンの完了までの時間が短くなり、その結果、Azure File Sync 対応のサーバーに名前空間が表示されるまでの待機時間が短縮されます。
- Azure ファイル共有スナップショットからのクラウド側の復元が高速になります。
- オンプレミスサーバーのディザスター リカバリーが大幅にスピードアップされます。
- Azure ファイル共有 (同期以外) で直接行われた変更が、より高速に検出、同期されます。
ヒント
ファイルとフォルダーの数が不明な場合は、JAM Software GmbH の TreeSize ツールをぜひご利用ください。
デプロイ マップへの構造化アプローチ
後の手順でクラウド ストレージをデプロイする前に、オンプレミス フォルダーと Azure ファイル共有の間にマップを作成することが重要です。 このマッピングを行うと、プロビジョニングする Azure File Sync の "同期グループ" リソースの数と名称が通知されます。 同期グループは、Azure ファイル共有とサーバー上のフォルダーを連携させ、同期接続を確立します。
必要な Azure ファイル共有の数を決めるには、次の制限事項とベストプラクティスをレビューしてください。 そのことが、マップの最適化に役立ちます。
Azure File Sync エージェントがインストールされているサーバーは、最大 30 個の Azure ファイル共有と同期できます。
Azure ファイル共有は、ストレージ アカウント内にデプロイされます。 この配置により、このストレージ アカウントが、IOPS やスループットなどのパフォーマンス数のスケール ターゲットになります。
Azure ファイル共有をデプロイする際には、ストレージ アカウントの IOPS 制限に注意してください。 理想的には、ファイル共有をストレージ アカウントに 1:1 でマップする必要があります。 ただし、組織と Azure の両方からのさまざまな制限と制約により、これが常に可能とは限りません。 1 つのストレージ アカウントに 1 つのファイル共有のみをデプロイすることができない場合は、使用頻度が高い共有と低い共有を考慮し、最もアクティブなファイル共有が同じストレージ アカウントに一緒にデプロイされないようにしてください。
Azure ファイル共有をネイティブで使用する Azure にアプリをリフトする場合は、Azure ファイル共有のパフォーマンスをさらに上げる必要があります。 将来的にでもこのように使用することが考えられる場合は、1 つの標準の Azure ファイル共有を独自のストレージ アカウントに作成するのが最善です。
1 つの Azure リージョンにつき、1 サブスクリプションあたりのストレージ アカウント数は 250 に制限されています。
ヒント
この情報を考慮して、ボリューム上の複数のトップレベル フォルダーを共通の新しいルート ディレクトリにグループ化することがしばしば必要になります。 次に、この新しいルート ディレクトリと、その中にグループ化したすべてのフォルダーを、1 つの Azure ファイル共有に同期します。 この手法を使用すると、サーバーあたり 30 個の Azure ファイル共有同期の制限内に抑えることができます。
共通のルートの下でのこのグループ化は、データへのアクセスにはいっさい影響しません。 ACL はそのまま維持されます。 今ここで共通のルートに変更したローカル サーバー フォルダー上に必要共有パス (SMB 共有や NFS 共有など) がある場合に限り、その調整が必要となります。 それ以外の変更はありません。
重要
Azure File Sync の最も重要なスケール ベクターは、同期が必要な項目 (ファイルとフォルダー) の数です。 詳細については、「Azure File Sync のスケール ターゲット」を確認してください。
ここでのベストプラクティスは、同期スコープあたりの項目数を少なくしておくことです。 これは、フォルダーを Azure ファイル共有にマッピングする際に考慮する必要がある重要な要素です。 Azure File Sync は、共有ごとに 1 億個の項目 (ファイルとフォルダー) を使用して検証済みです。 ただし、多くの場合、1 つの共有に保持する項目数は、2000 万から 3000 万個未満にすることをお勧めします。 これらの数値を超え始めた場合は、名前空間を複数の共有に分割します。 これらの数値をほぼ下回っている場合、複数のオンプレミスの共有を同じ Azure ファイル共有にグループ化することを続行できます。 この方法により、拡大する余地が得られます。
状況によっては、一連のフォルダーが同じ Azure ファイル共有に論理的に同期される可能性があります (前述の新しい共通のルート フォルダーのアプローチを使用します)。 ただし、1 つの Azure ファイル共有ではなく 2 つに同期されるように、フォルダーを再グループ化することをお勧めします。 このアプローチを使用すると、ファイル共有あたりのファイルとフォルダーの数をサーバー間に分散させることができます。 オンプレミスの共有を分割し、より多くのオンプレミス サーバー間で同期させることもできます。これにより、追加のサーバーごとに 30 を超える Azure ファイル共有と同期することができます。
ファイル同期の一般的なシナリオと考慮事項
| # | 同期シナリオ | サポートされています | 考慮事項 (または制限事項) | 解決策 (または対処法) |
|---|---|---|---|---|
| 1 | 複数のディスク/ボリュームと複数の共有があるファイル サーバーと、同じターゲット Azure ファイル共有 (統合) | いいえ | ターゲットの Azure ファイル共有 (クラウド エンドポイント) は、1 つの同期グループとの同期のみをサポートします。 同期グループは、登録済みサーバーごとに 1 つのサーバー エンドポイントのみをサポートします。 |
1) 最初に、1 つのディスク (そのルート ボリューム) を、ターゲットの Azure ファイル共有と同期させます。 最大のディスク/ボリュームから始めると、オンプレミスのストレージ要件に対応できます。 クラウドの階層化を構成して、すべてのデータをクラウドに階層化します。これにより、ファイル サーバーのディスク領域を解放します。 他のボリューム/共有から、同期中の現在のボリュームにデータを移動します。 すべてのデータがクラウドに階層化/移行されるまで、手順を 1 つずつ続行します。 2) 一度に 1 つのルート ボリューム (ディスク) をターゲットにします。 クラウドの階層化を使用して、すべてのデータをターゲットの Azure ファイル共有に階層化します。 同期グループからサーバー エンドポイントを削除し、次のルート ボリューム/ディスクを含むエンドポイントを再作成し、同期させます。このプロセスを繰り返します。 注: エージェントの再インストールが必要になる場合があります。 3) 複数のターゲット Azure ファイル共有を使用することをお勧めします (パフォーマンス要件に基づいて同じまたは異なるストレージ アカウント) |
| 2 | 1 つのボリュームと複数の共有があるファイル サーバーと、同じターゲット Azure ファイル共有 (統合) | はい | 登録済みサーバーごとの複数のサーバー エンドポイントを、同じターゲット Azure ファイル共有と同期させることはできません (上記と同じ) | 複数の共有または最上位フォルダーを保持しているボリュームのルートを同期させます。 詳しくは、共有のグループ化の概念に関するページと「ボリュームの同期」を参照してください。 |
| 3 | 複数の共有、ボリューム、またはこれらの両方があるファイル サーバーと、1 つのストレージ アカウントの複数の Azure ファイル共有 (1 対 1 の共有マッピング) | はい | 1 つの Windows Server インスタンス (またはクラスター) では、最大 30 個の Azure ファイル共有を同期できます。 ストレージ アカウントは、パフォーマンスのためのスケール ターゲットです。 IOPS とスループットは、ファイル共有間で共有されます。 同期グループあたりのアイテム (ファイルとフォルダー) の数は、1 つの共有あたり 1 億個以内にします。 理想的には、1 つの共有あたり 2 千万または 3 千万個未満にするのが最適です。 |
1) 複数の同期グループを使用します (同期グループの数 = 同期させる先の Azure ファイル共有の数)。 2) このシナリオでは、一度に 30 個の共有のみを同期させることができます。 そのファイル サーバーに 30 を超える共有がある場合は、共有のグループ化の概念に関するページと「ボリュームの同期」を使用して、ソースのルート フォルダーまたは最上位フォルダーの数を減らします。 3) オンプレミスで追加の File Sync サーバーを使用し、それらのサーバーにデータを分割/移動して、ソース Windows サーバーの制限事項に対処します。 |
| 4 | 複数の共有、ボリューム、またはこれらの両方があるファイル サーバーと、異なるストレージ アカウントの複数の Azure ファイル共有 (1 対 1 の共有マッピング) | はい | 1 つの Windows Server インスタンス (またはクラスター) を、最大 30 個の Azure ファイル共有と同期させることができます (同じまたは異なるストレージ アカウント)。 同期グループあたりのアイテム (ファイルとフォルダー) の数は、1 つの共有あたり 1 億個以内にします。 理想的には、1 つの共有あたり 2 千万または 3 千万個未満にするのが最適です。 |
上記と同じ方法 |
| 5 | 1 つのルート ボリュームまたは共有がある複数のファイル サーバーと、同じターゲット Azure ファイル共有 (統合) | いいえ | 同期グループでは、別の同期グループで既に構成されているクラウド エンドポイント (Azure ファイル共有) を使用できません。 同期グループでは、異なるファイル サーバーでサーバー エンドポイントを使用できますが、ファイルは区別できません。 |
"上記のシナリオ # 1 のガイダンスと、一度に 1 つのファイル サーバーをターゲットにする場合の追加の考慮事項に従ってください。" |
マッピング テーブルを作成する

前述の情報を使用して、必要な Azure ファイル共有の数を決定し、既存のデータのどの部分がどの Azure ファイル共有に格納されるかを判断します。
必要に応じて参照できるように、自分の考えを記録しておく表を作成します。 一度に多数の Azure リソースをプロビジョニングするときは、マッピング計画の詳細がおろそかになりがちなので、情報が整理された状態を維持することが重要です。 次の Excel ファイルをダウンロードして、マッピングの作成に役立つテンプレートとして使用します。

|
名前空間マッピング テンプレートをダウンロードします。 |
手順 5:Azure ファイル共有をプロビジョニングする
Azure ファイル共有は、Azure ストレージ アカウントのクラウドに格納されます。 ここでは、また別のレベルのパフォーマンスに関する考慮事項が適用されます。
高度にアクティブな共有 (多くのユーザーやアプリケーションによって使用される共有) がある場合、2 つの Azure ファイル共有がストレージ アカウントのパフォーマンス制限に達する可能性があります。
ベスト プラクティスは、それぞれ 1 つのファイル共有を持つストレージ アカウントをデプロイすることです。 アーカイブ共有がある場合、またはそれらの中での日常のアクティビティが少ないことが予想される場合は、複数の Azure ファイル共有を同じストレージ アカウントにプールすることができます。
これらの考慮事項は、Azure File Sync より、(Azure VM 経由での) クラウドへの直接アクセスの場合によりいっそう当てはまります。これらの共有で Azure File Sync のみを使用する場合は、いくつかのものを 1 つの Azure ストレージ アカウントにグループ化するのが適切です。
共有のリストを作成してある場合は、各共有を、それらが配置されるストレージ アカウントにマップする必要があります。
前のフェーズで、共有の適切な数を決定しました。 この手順では、ファイル共有へのストレージ アカウントのマッピングを行いました。 次に、適切な数の Azure ファイル共有が含まれている適切な数の Azure ストレージ アカウントをデプロイします。
ご利用の各ストレージ アカウントのリージョンが、いずれも同じであり、既にデプロイしているストレージ同期サービス リソースのリージョンと一致していることを確認します。
注意事項
上限が 100 TiB の Azure ファイル共有を作成する場合、その共有で使用できるのは、ローカル冗長ストレージまたはゾーン冗長ストレージの冗長オプションのみとなります。 100 TiB のファイル共有を使用する場合は、事前にご自分のストレージ冗長のニーズを検討してください。
既定では、Azure ファイル共有は引き続き 5 TiB の上限で作成されます。 大きなファイル共有を作成するには、「Azure ファイル共有を作成する」の手順に従ってください。
ストレージ アカウントをデプロイする際のもう 1 つの考慮事項は、使用する Azure ストレージの冗長性です。 詳細については、「Azure Storage 冗長オプション」を参照してください。
ご利用のリソースの名前も重要です。 たとえば、人事部の複数の共有を Azure ストレージ アカウントにグループ化する場合は、そのストレージ アカウントに適切な名前を指定する必要があります。 同様に、使用する Azure ファイル共有に名前を付けるときは、オンプレミスの対応するものに使用したのと同じような名前を使用する必要があります。
Storage アカウントの設定
ストレージ アカウントには多くの構成を行います。 ストレージ アカウントの構成には、次のチェックリストを使用する必要があります。 たとえば、移行の完了後にネットワーク構成を変更できます。
- 大型ファイルの共有: 有効 - 大きなファイルを共有すると、パフォーマンスが向上し、共有に最大 100 TiB を格納できます。
- ファイアウォールと仮想ネットワーク: 無効 - IP 制限を構成したり、ストレージ アカウントの特定の VNET へのアクセスに制限したりしません。 ストレージ アカウントのパブリック エンドポイントは、移行中に使用されます。 Azure VM からのすべての IP アドレスを許可する必要があります。 移行後は、ストレージ アカウントでファイアウォール規則を構成するのが最善です。
- プライベート エンドポイント: サポートされている - プライベート エンドポイントを有効にできますが、パブリック エンドポイントは移行に使用され、引き続き使用できる必要があります。
手順 6:Windows Server のターゲット フォルダーを構成する
前の手順では、同期トポロジのコンポーネントを決定するすべての側面を検討しました。 この時点で、アップロード用のファイルを受信するようにサーバーを準備します。
それぞれが独自の Azure ファイル共有に同期するすべてのフォルダーを作成します。 前に説明したフォルダー構造に従うようにすることが重要です。 たとえば、複数のローカル SMB 共有をまとめて 1 つの Azure ファイル共有に同期する場合は、それらをボリューム上の共通のルート フォルダーの下に配置する必要があります。 ここで、このターゲット ルート フォルダーをボリューム上に作成します。
プロビジョニングした Azure ファイル共有の数は、この手順で作成したフォルダーの数に、ルート レベルで同期するボリュームの数を加えたものと一致している必要があります。
手順 7:Azure File Sync エージェントをデプロイする
このセクションでは、Azure File Sync エージェントをご利用の Windows Server インスタンスにインストールします。
デプロイ ガイドでは、 [Internet Explorer セキュリティ強化の構成] を無効にする必要があることが説明されています。 このセキュリティ対策は、Azure File Sync には該当しません。これをオフにすると、Azure への認証が問題なく行えるようになります。
PowerShell を開きます。 次のコマンドを使用して必須の PowerShell モジュールをインストールします。 プロンプトが表示されたら、完全なモジュールと NuGet プロバイダーを必ずインストールしてください。
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
サーバーからインターネットへの接続で問題が発生した場合は、この段階で解決する必要があります。 Azure File Sync は、インターネットへの任意の使用可能なネットワーク接続を使用します。 インターネットに接続するためにプロキシ サーバーを要求することもサポートされています。 今すぐにマシン全体のプロキシを構成することも、エージェントのインストール中に Azure File Sync だけが使用するプロキシを指定することもできます。
プロキシを構成することが、このサーバーに対してファイアウォールを開く必要があることを意味する場合は、その方法を採用しても問題ありません。 サーバー インストールの終了時、サーバー登録が完了した後に、選択したリージョン用に Azure File Sync が通信する必要がある Azure 内の正確なエンドポイント URL を示すネットワーク接続レポートが示されます。 このレポートには、なぜ通信が必要なのかも示されています。 このレポートを使用して、このサーバーのファイアウォールを特定の URL にロック ダウンできます。
また、ファイアウォール全体を開かない、より保守的なアプローチを採用することもできます。 代わりに、上位レベルの DNS 名前空間と通信するようサーバーを制限できます。 詳細については、「Azure File Sync のプロキシとファイアウォールの設定」をご覧ください。 ご自分のネットワークのベスト プラクティスに従ってください。
サーバーのインストール ウィザードの終了時に、サーバーの登録ウィザードが開きます。 以前からご利用のストレージ同期サービスの Azure リソースにサーバーを登録します。
最初にインストールする必要がある PowerShell モジュールを含め、これらの手順については、デプロイ ガイドで詳しく説明されています。Azure File Sync エージェントのインストール。
最新のエージェントを使用してください。 Microsoft ダウンロード センターからダウンロードできます。Azure File Sync エージェント。
インストールとサーバーの登録が正常に完了したら、この手順が正常に完了したことを確認できます。 Azure portal のストレージ同期サービス リソースに移動します。 左側のメニューで、 [登録済みサーバー] に移動します。 ご利用のサーバーがそこに一覧表示されます。
手順 8:同期を構成する
このステップでは、前の手順で Windows Server インスタンスに設定したすべてのリソースとフォルダーを結び付けます。
- Azure portal にサインインします。
- ストレージ同期サービスのリソースを見つけます。
- 各 Azure ファイル共有のストレージ同期サービス リソース内に新しい "同期グループ" を作成します。 Azure File Sync の用語では、Azure ファイル共有は、同期グループの作成と共に記述する同期トポロジの "クラウド エンドポイント" になります。 同期グループを作成する際に、ここで同期するファイルのセットを認識できるように、わかりやすい名前を付けます。 名前が一致する Azure ファイル共有を参照していることを確認します。
- 同期グループを作成すると、同期グループの一覧にその行が表示されます。 名前 (リンク) を選択して、同期グループの内容を表示します。 [クラウド エンドポイント] の下に Azure ファイル共有が表示されます。
- [サーバー エンドポイントの追加] ボタンを見つけます。 プロビジョニングしたローカル サーバー上のフォルダーは、この "サーバー エンドポイント" のパスになります。
警告
クラウドを使った階層化を必ず有効にしておきます。 これは、StorSimple クラウド ストレージのデータの合計サイズを格納するのに十分な領域がローカル サーバーにない場合に必要です。 移行のために一時的に、階層化ポリシーをボリューム空き領域 99% に設定します。
同期グループ作成の手順と、すべての Azure ファイル共有とサーバーの場所に対するサーバー エンドポイントとしての一致するサーバー フォルダーの追加の手順を繰り返します。これは、同期用に構成するために必要です。
手順 9:ファイルをコピーする
基本的な移行方法は、StorSimple 仮想アプライアンスから Windows Server への RoboCopy と、Azure ファイル共有への Azure File Sync です。
Windows Server ターゲット フォルダーへの最初のローカル コピーを実行します。
- 仮想 StorSimple アプライアンス上で最初の場所を特定します。
- Windows Server 上で、既に Azure File Sync が構成されている対応するフォルダーを特定します。
- RoboCopy を使用してコピーを開始します
次の RoboCopy コマンドを実行すると、StorSimple Azure Storage からローカル StorSimple にファイルが呼び出された後、Windows Server のターゲット フォルダーに移動されます。 Windows Server によってそれが Azure ファイル共有に同期されます。 ローカル環境の Windows Server ボリュームがいっぱいになると、クラウドを使った階層化により、既に正常に同期されているファイルの階層化が開始されます。 クラウドを使った階層化により、StorSimple 仮想アプライアンスからのコピーを続けるのに十分な領域が生成されます。 クラウドを使った階層化では、1 時間に 1 回、同期されたものが確認されて、ボリューム空き領域 99% になるようにディスク領域が解放されます。
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Switch | 説明 |
|---|---|
/MT:n |
Robocopy をマルチスレッドを実行できるようにします。 n の既定値は 8 です。 スレッドの最大数は 128 です。 スレッド数が多いと使用可能な帯域幅を飽和させるのに役立ちますが、スレッド数が多ければ必ず移行が速くなるというわけではありません。 Azure Files を使ったテストでは、8 から 20 の間で、最初のコピー実行のパフォーマンスのバランスが取れていることが示されています。 後続 /MIR の実行は、使用可能なコンピューティングと使用可能なネットワーク帯域幅の影響を徐々に受けます。 後続の実行では、スレッド数の値をプロセッサのコア数およびコアあたりのスレッド数とより厳密に一致させます。 実稼働サーバーに存在する可能性のある他のタスク用にコアを予約する必要があるかどうかを検討してください。 Azure Files を使ったテストでは、最大 64 スレッドで良好なパフォーマンスが得られますが、プロセッサがそれらを同時に維持できる場合のみです。 |
/R:n |
最初の試行でコピーに失敗したファイルの最大再試行回数です。 Robocopy では、実行中にファイルが完全にコピーに失敗するまで n 回試行します。 実行のパフォーマンスを最適化することができます。過去にタイムアウトの問題で失敗したと思われる場合は、2 または 3 の値を選んでください。 これは、WAN リンク上でより一般的である可能性があります。 ファイルが使用中であったためにコピーに失敗したと思われる場合は、[再試行しない] または 1 の値を選びます。 数秒後に再試行しても、ファイルの使用中の状態が変更されるのに十分な時間がない場合があります。 ファイルを開いているユーザーまたはアプリには、さらに時間がかかることがあります。 このような場合、ファイルがコピーされていないことを受け入れ、その後に予定されている Robocopy の実行のいずれかで試行すれば、最終的にファイルを正常にコピーするのに成功する可能性があります。 これにより、再試行のタイムアウトを過ぎてもファイルが開いているために、最終的にコピー失敗の大部分を占めることになる多数の再試行で長引かせることなく、現在の実行をより短時間で完了することができます。 |
/W:n |
前の試行時に正常にコピーされなかったファイルのコピーを試行する前に、RoboCopy が待機する時間を指定します。 n は再試行の間の待機時間 (秒数) です。 /W:n は、多くの場合、/R:n と共に使用されます。 |
/B |
バックアップ アプリケーションが使用するのと同じモードで Robocopy を実行します。 このスイッチを使用すると、現在のユーザーがアクセス許可を持っていないファイルを、Robocopy によって移動できます。 バックアップのスイッチは、管理者特権のコンソールまたは PowerShell ウィンドウで Robocopy コマンドを実行する場合によって異なります。 Azure Files に Robocopy を使用する場合は、ストレージ アカウントのアクセス キーとドメイン ID のどちらを使用して Azure ファイル共有をマウントするかを確認します。 そうしないと、エラー メッセージが直感的でなくなり、問題解決につながらないことがあります。 |
/MIR |
(ソースをターゲットにミラーリング。) RoboCopy でソースとターゲット間の差分のみをコピーします。 空のサブディレクトリがコピーされます。 変更された、またはターゲットに存在しない項目 (ファイルまたはフォルダー) がコピーされます。 ターゲットに存在する一方でソースには存在しない項目は、ターゲットから消去 (削除) されます。 このスイッチを使用する場合は、ソースとターゲットのフォルダー構造を正確に一致させます。 "一致" とは、正しいソースおよびフォルダー レベルから、コピー先の一致するフォルダー レベルにコピーすることを意味します。 その場合にのみ、"キャッチ アップ" コピーを正常に実行することができます。 ソースとターゲットが一致しない場合に /MIR を使用すると、大規模な削除と再コピーが行われます。 |
/IT |
特定のミラー シナリオで、忠実性が維持されることを保証します。 たとえば、Robocopy を 2 回実行する間に、ファイルで ACL の変更と属性の更新があった場合、非表示とマークされます。 /IT を使用しない場合、ACL の変更が Robocopy で見逃されて、ターゲットの場所に転送されない可能性があります。 |
/COPY:[copyflags] |
ファイル コピーの忠実性。 既定値:/COPY:DAT。 コピー フラグ: D = データ、A = 属性 T = タイムスタンプ、S = セキュリティ = NTFS ACL O = 所有者情報、U= D監査情報。 監査情報を Azure ファイル共有に格納することはできません。 |
/DCOPY:[copyflags] |
ディレクトリのコピーの忠実性。 既定値:/DCOPY:DA。 コピーフラグ: D = データ A = 属性、T = タイムスタンプ。 |
/NP |
各ファイルとフォルダーのコピーの進行状況を表示しないよう指定します。 進行状況を表示すると、コピーのパフォーマンスが大幅に低下します。 |
/NFL |
ファイル名をログに記録しないことを指定します。 コピーのパフォーマンスを向上させます。 |
/NDL |
ディレクトリ名をログに記録しないことを指定します。 コピーのパフォーマンスを向上させます。 |
/XD |
除外するディレクトリを指定します。 ボリュームのルートで Robocopy を実行する場合、隠しフォルダー System Volume Information を除外することを検討してください。 設計どおりに使用した場合、そこにあるすべての情報は、この正確なシステム上の正確なボリュームに固有であり、オンデマンドで再構築することができます。 この情報をコピーしても、クラウドや、データを別の Windows ボリュームにコピー バックするときには役に立ちません。 この内容を放置しておくことは、データ損失と見なさないようにする必要があります。 |
/UNILOG:<file name> |
状態を Unicode 形式でログ ファイルに書き込みます。 (既存のログを上書きします)。 |
/L |
テスト実行の場合のみ ファイルは一覧表示されるだけです。 コピーも削除もされず、タイム スタンプも付きません。 コンソール出力には /TEE とよく使用されます。 テスト結果を適切に文書化するには、サンプル スクリプトのフラグ (/NP、/NFL、/NDL など) の削除が必要になる場合があります。 |
/LFSM |
階層型ストレージを持つターゲットの場合のみ。 移行先がリモート SMB 共有の場合はサポートされません。 RoboCopy を "低空き領域モード" で動作するよう指定します。このスイッチは、RoboCopy が完了する前にローカル容量が不足する可能性がある、階層型ストレージを持つターゲットにのみ有効です。 これは、Azure File Sync のクラウドの階層化が有効なターゲットで使用するために特別に追加されました。 これは、Azure File Sync とは別に使用できます。このモードでは、ファイルのコピーによって宛先ボリュームの空き領域が "床" 値よりも小さくなるたびに、Robocopy が一時停止します。 この値は /LFSM:n のフラグ形式で指定できます。 パラメーター n は、ベース 2: nKB、nMB、またはnGB で指定します。 明示的な床値を示さずに /LFSM を指定した場合、床は宛先ボリュームのサイズの 10% に設定されます。 低空き領域モードは、/MT、/EFSRAW または /ZB では利用できません。 /B のサポートは Windows Server 2022 で追加されました。 詳細 (関連するバグと回避策に関する詳細を含みます) については、以下の「Windows Server 2022 と RoboCopy LFSM」セクションを参照してください。 |
/Z |
慎重に使用する 再起動モードでファイルをコピーします。 このスイッチは、ネットワーク環境が不安定な場合にのみ、使用することをお勧めします。 追加のログ記録が原因で、コピーのパフォーマンスが大幅に低下します。 |
/ZB |
慎重に使用する 再起動モードを使用します。 アクセスが拒否された場合、このオプションではバックアップ モードが使用されます。 このオプションでは、チェックポイント処理が原因で、コピーのパフォーマンスが大幅に低下します。 |
重要
Windows Server 2022 の使用をお勧めします。 Windows Server 2019 を使う場合、最新のパッチ レベルまたは少なくとも OS 更新プログラム KB5005103 がインストールされていることを確認してください。 特定の RoboCopy シナリオに対する重要な修正プログラムが含まれています。
RoboCopy コマンドを初めて実行するときは、ユーザーとアプリケーションがまだ StorSimple のファイルとフォルダーにアクセスしていて、それを変更する場合があります。 RoboCopy があるディレクトリを処理し、次のディレクトリに移動した後、ソースの場所 (StorSimple) のユーザーがファイルを追加、変更、または削除し、現在の RoboCopy の実行では処理されない可能性があります。 問題はありません。
最初の実行では、データの大部分がオンプレミスに戻され、Windows Server に移動された後、Azure File Sync 経由でクラウドにバックアップされます。これには、次の条件によっては時間がかかることがあります。
- ダウンロードの帯域幅
- StorSimple クラウド サービスの呼び出し速度
- アップロードの帯域幅
- いずれかのサービスによって処理される必要がある項目 (ファイルとフォルダー) の数
最初の実行が完了した後、コマンドを再度実行します。
2 回目に転送する必要があるのは、前回の実行以降に発生した変更だけなので、処理は短時間で完了します。 それらの変更は、最近のものなので、まだ StorSimple のローカル環境に存在する可能性があります。 その場合、クラウドから呼び出す必要が減るため、さらに時間が短縮されます。 この 2 回目の実行の間に、まだ新しい変更が蓄積される可能性があります。
完了までにかかる時間が、許容されるダウンタイムになるまで、このプロセスを繰り返します。
ダウンタイムが許容できるものと見なされ、StorSimple の場所をオフラインにする準備ができたら、ここでそれを行います。たとえば、ユーザーがフォルダーにアクセスできないように SMB 共有を削除するか、StorSimple 上のこのフォルダーの内容が変更されないようにするための適切な手順を実行します。
最後に 1 回 RoboCopy ラウンドを実行します。 これにより、漏れている可能性があるすべての変更が取得されます。 この最後の手順にかかる時間は、RoboCopy のスキャンの速度に依存します。 前回の実行にかかった時間を測定することで、(ダウンタイムに相当する) 時間を見積もることができます。
Windows Server フォルダーに共有を作成し、必要に応じて、その共有を指すように DFS-N のデプロイを調整します。 StorSimple SMB 共有と同じ共有レベルのアクセス許可を設定してください。
これで、共通のルートまたはボリュームへの共有または共有のグループの移行は完了しました。 (同じ Azure ファイル共有に移行する必要があるとマップして決定した内容によります)。
これらの複数のコピーを並行して実行することができます。 一度に 1 つの Azure ファイル共有のスコープを処理することをお勧めします。
警告
StorSimple から Windows Server にすべてのデータを移動したら、移行は完了です。Azure portal ですべての同期グループに戻り、クラウドを使った階層化ボリュームの空き領域の割合の値を、キャッシュの使用に適したもの (20% など) に調整します。
クラウドを使った階層化ボリュームの空き領域ポリシーはボリューム レベルで動作し、複数のサーバー エンドポイントがそこから同期する可能性があります。 1 つのサーバー エンドポイントでも空き領域を調整し忘れた場合、同期では最も制限の厳しい規則が引き続き適用され、99% の空きディスク領域が確保されて、ローカル キャッシュが期待どおりに実行されなくなります。 アクセス頻度の低いアーカイブ データのみが含まれるボリューム用の名前空間のみを使用することを目的としている場合を除きます。
トラブルシューティング
最も可能性の高い問題は、Windows Server 側で "ボリュームがいっぱい" になったために RoboCopy コマンドが失敗することです。 その場合は、アップロード速度よりダウンロード速度の方が速い可能性があります。 クラウドを使った階層化は 1 時間ごとに動作し、同期されたローカル環境の Windows Server ディスクから内容が退避されます。
同期を進行させ、クラウドを使った階層化にディスク領域を解放させます。 これは、Windows Server のエクスプローラーで確認できます。
Windows Server に十分な空き容量がある場合は、コマンドを再実行すると問題が解決されます。 このような状況が発生しても壊れるものは何もなく、安心して進めることができます。 コマンドを再実行する不便さだけが唯一の影響です。
他の Azure File Sync の問題が発生することもあります。 発生した場合は、Azure File Sync のトラブルシューティング ガイドを参照してください。
指定された RoboCopy 実行の速度と成功率は、複数の要因によって決まります。
- ソース ストレージとターゲット ストレージの IOPS
- ソースとターゲットの間で使用可能なネットワーク帯域幅
- 名前空間内のファイルとフォルダーを迅速に処理する機能
- RoboCopy 実行間の変更の数
- コピーする必要があるファイルのサイズと数
IOPS と帯域幅に関する考慮事項
このカテゴリでは、ソース ストレージ、ターゲット ストレージ、およびそれらを接続するネットワークの能力を考慮する必要があります。 達成可能な最大スループットは、これら 3 つのコンポーネントのうち、最も低速なものによって決まります。 最大能力に応じた最適な転送速度をサポートするようにネットワーク インフラストラクチャが構成されていることを確認してください。
注意事項
多くの場合、可能な限り高速にコピーすることが望ましいですが、他のビジネス クリティカルなタスクに使用されることの多いローカル ネットワークと NAS アプライアンスの使用状況を考慮してください。
可能な限り高速にコピーすることは、移行によって使用可能なリソースを独占するリスクがある場合には望ましくない可能性があります。
- ご使用の環境において移行を実行する最適なタイミングを考慮します (日中、時間外、または週末)。
- また、RoboCopy の速度を調整するための Windows Server のネットワーク QoS も考慮してください。
- 移行ツールのための不要な作業を行わないようにします。
RoboCopy では、/IPG:n スイッチを指定することでパケット間の遅延を挿入できます。ここで n は、RoboCopy パケット間の間隔をミリ秒単位で測定します。 このスイッチを使用すると、IO が制限されたデバイスと過密したネットワーク リンクの両方でリソースの独占を回避できます。
/IPG:n は、ネットワーク帯域幅を特定の Mbps に正確に調整するためには使用できません。 代わりに Windows Server のネットワーク QoS を使用してください。 RoboCopy では、すべてのネットワーク ニーズに関して SMB プロトコルに完全に依存します。 SMB を使用する理由は、RoboCopy がネットワーク スループット自体に影響を与えることができないためですが、使用速度が低下する可能性はあります。
同様の考えが、NAS で観察される IOPS にも当てはまります。 NAS ボリュームのクラスター サイズ、パケット サイズ、およびその他のさまざまな要因が、観察される IOPS に影響します。 多くの場合、パケット間の遅延を導入することが、NAS の負荷を制御する最も簡単な方法です。 たとえば、約 20 ミリ秒 (n = 20) からその数値の倍数まで、複数の値をテストします。 遅延を導入すると、他のアプリが期待どおりに動作できるようになったかどうかを評価できます。 この最適化戦略により、ご使用の環境内で最適な RoboCopy 速度を見つけることができます。
処理速度
RoboCopy では、指し示されている名前空間を走査し、各ファイルとフォルダーをコピーに対して評価します。 すべてのファイルは、最初のコピー中およびキャッチアップ コピー中に評価されます。 たとえば、同じソースおよびターゲット ストレージ場所に対して RoboCopy/MIR の実行が繰り返されます。 これらの繰り返される実行は、ユーザーとアプリのダウンタイムを最小限に抑え、移行されるファイルの全体的な成功率を向上させるために役立ちます。
多くの場合、既定で帯域幅を移行における最も制限の厳しい要因と見なしています。実際にそのとおりだと考えられます。 ただし、名前空間を列挙する機能により、小さなファイルを含む大規模な名前空間の場合は、コピーの合計時間に与える影響がはるかに大きくなる可能性があります。 他のすべての変数は同じままという前提で、1 TiB 分の小さなファイルをコピーする時間は、1 TiB 分の少数で大きなファイルをコピーする時間よりもはるかに長いということを考慮します。 そのため、多数の小さなファイルを移行する場合は、転送が遅くなる可能性があります。 これは予想される現象です。
この違いの原因は、名前空間内を通過するために必要な処理能力です。 RoboCopy では、/MT:n パラメーターを使用したマルチスレッド コピーがサポートされます。ここで n は、使用するスレッドの数を表します。 そのため、RoboCopy 専用のマシンをプロビジョニングする場合は、プロセッサ コアの数と、それらが提供するスレッド数との関係を考慮します。 最も一般的なのは、コアあたり 2 つのスレッドです。 マシンのコア数とスレッド数は、指定する必要のあるマルチスレッド値 /MT:n を決定するための重要なデータ ポイントです。 また、特定のマシンで並列実行する予定の RoboCopy ジョブの数も考慮します。
スレッドが多くなるほど、1 TiB 分の小さなファイルは、スレッドが少ない場合よりも高速にコピーされます。 一方、1 TiB 分の大きなファイルにリソースを追加投資しても、相応のメリットは得られない場合があります。 スレッド数が多いと、ネットワーク経由で大きなファイルを同時により多くコピーしようとします。 この追加のネットワーク アクティビティによって、スループットまたはストレージ IOPS による制約を受ける可能性が高くなります。
空のターゲットへの最初の RoboCopy 中、または多数の変更されたファイルを使用した差分実行中に、ネットワーク スループットによって制限される可能性があります。 最初の実行では、スレッド数を多くしてください。 スレッド数が多いと、コンピューター上で現在使用可能なスレッドを超えても、使用可能なネットワーク帯域幅が飽和状態になります。 後続の/MIR の実行は、アイテムを処理することによって徐々に影響を受けます。 差分実行の変更が少ないほど、ネットワーク経由でのデータ転送が減少します。 ネットワーク リンク上で移動する機能よりも、名前空間項目を処理する機能によって速度が向上するようになりました。 後続の実行では、スレッド数の値をプロセッサのコア数およびコアあたりのスレッド数と一致させます。 実稼働サーバーに存在する可能性のある他のタスク用にコアを予約する必要があるかどうかを検討してください。
ヒント
経験則: 最初の RoboCopy 実行ではより高遅延のネットワークのデータを大量に移動するため、スレッド カウントをオーバープロビジョニングすることでメリットが得られます (/MT:n)。 その後の実行ではコピーされる差異が少なくなり、おそらくは、ネットワーク スループット制約からコンピューティング制約に移行するでしょう。 こうした状況では多くの場合、RoboCopy のスレッド数をマシンで実際に利用できるスレッドに合わせることがお勧めです。 そのシナリオでのオーバープロビジョニングはプロセッサのコンテキスト移動を増やす場合があり、おそらくコピーが遅くなるでしょう。
不要な作業の回避
名前空間の大規模な変更は避けてください。 ディレクトリ間でのファイルの移動、プロパティの大規模な変更、アクセス許可 (NTFS ACL) の変更などです。 特に ACL の変更は、フォルダー階層の下位にあるファイルに対して変更が連鎖的に影響することが多いため、大きな影響を及ぼす可能性があります。 次のような影響が考えられます。
- ACL の変更によって影響を受けた各ファイルおよびフォルダーを更新する必要があるため、RoboCopy ジョブの実行時間が長くなる
- 以前に移動したデータを再利用するには、再コピーが必要になる場合がある。 たとえば、ファイルが既にコピーされた後にフォルダー構造が変更される場合、より多くのデータをコピーする必要があります。 RoboCopy ジョブでは、名前空間の変更を "再生" できません。 次のジョブで、古いフォルダー構造へ以前に転送されたファイルを削除し、新しいフォルダー構造でファイルを再度アップロードする必要があります。
もう 1 つの重要な側面は、RoboCopy ツールを効果的に使用することです。 推奨される RoboCopy スクリプトでは、エラー用のログ ファイルを作成して保存します。 コピー エラーは発生する可能性があります。それが普通です。 多くの場合、これらのエラーによって、RoboCopy などのコピー ツールを複数ラウンド実行することが必要になります。 最初の実行 (NAS からファイル、サーバーから Azure ファイル共有、など)。 コピーされなかったファイルをキャッチして再試行するための /MIR スイッチを使用した 1 回以上の追加実行。
特定の名前空間スコープに対して RoboCopy を複数ラウンドを実行する準備を整えておく必要があります。 後続の実行は、コピー対象が少なくなるので迅速に完了しますが、名前空間の処理速度によって次第に制約されます。 複数ラウンドを実行する場合は、RoboCopy の特定の実行で非合理的にすべてをコピーしようとしないようにすることで、各ラウンドを高速化できます。 これらの RoboCopy スイッチにより、大きな違いがもたらされる可能性があります。
/R:nn = 失敗したファイルのコピーを再試行する頻度/W:nn = 再試行を待機する秒数
/R:5 /W:5 が合理的な設定ですが、自由に調整できます。 この例では、失敗したファイルは 5 回再試行され、再試行間の待機時間は 5 秒です。 それでもファイルのコピーに失敗した場合は、次の RoboCopy ジョブで再試行されます。 多くの場合、使用中であることまたはタイムアウトの問題が原因で失敗したファイルは、最終的にこの方法でコピーされる可能性があります。
Windows Server 2022 と RoboCopy LFSM
RoboCopy スイッチ /LFSM を使用すると、"ボリュームがいっぱい" というエラーで RoboCopy ジョブが失敗することを回避できます。 ファイルのコピーによってコピー先ボリュームの空き領域が "底" 値を下回るたびに、RoboCopy が一時停止します。
RoboCopy は Windows Server 2022 で使用します。 このバージョンの RoboCopy にのみ、重要なバグ修正と、スイッチをほとんどの移行で必要な追加フラグと互換性のあるものにする機能が含まれています。 たとえば、/B フラグとの互換性などです。
/B を使用すると、バックアップ アプリケーションで使用するのと同じモードで RoboCopy が実行されます。 このスイッチを使用すると、現在のユーザーがアクセス許可を持っていないファイルを、RobocCopy によって移動できます。
通常、RoboCopy は、コピー元、コピー先、または 3 台目のマシンで実行できます。
重要
/LFSM を使用する場合は、Windows Server 2022 ターゲット Azure File Sync サーバーで RoboCopy を実行する必要があります。
また、/LFSM を使用する場合にはコピー先に UNC パスではなく、ローカル パスを使用する必要もあることに注意してください。 たとえば、コピー先パスとして、\\ServerName\FolderName などの UNC パスではなく、E:\Foldername を使用する必要があります。
注意事項
Windows Server 2022 で現在利用できる RoboCopy のバージョンにはバグがあり、ファイルごとのエラー数をカウントするために一時停止が発生します。 次の回避策を適用してください。
お勧めの /R:2 /W:1 フラグを使用すると、/LFSM によって生じる一時停止が原因でファイルが失敗する可能性が高くなります。 この例では、/LFSM によって一時停止が発生したために 3 回の一時停止後にコピーされなかったファイルがあると、RoboCopy では間違ってそのファイルを失敗とします。 これに対する回避策は、/R:n と /W:n により大きい値を使用することです。 良い例は /R:10 /W:1800 (それぞれ 30分 の 10 回の再試行) です。 これにより、コピー先ボリュームに領域を作成する時間を Azure File Sync 階層化アルゴリズムに与えることになります。
このバグは修正されましたが、修正はまだ一般公開されていません。 修正プログラムの提供と展開方法に関する最新情報については、この段落を確認してください。
Note
まだ質問があるか、問題が発生していますか。
その場合は、 にご連絡ください
にご連絡ください
関連するリンク
移行に関するコンテンツ:
Azure File Sync のコンテンツ: