この記事では、Azure Table Storage ソリューションの設計に役立つモデル化プロセスについて説明します。
複雑なシステムの設計において、ドメイン モデルの作成は重要なステップです。 通常は、モデル化プロセスを使用して各種エンティティとそれらの間のリレーションシップを特定します。これはビジネス ドメインについて理解し、システムの設計を伝えるための手段となります。 このセクションでは、ドメイン モデル内の一般的なリレーションシップの種類を Table service 向けの設計に変換する方法を中心に説明します。 論理データ モデルから物理的な NoSQL ベースのデータ モデルへのマッピング プロセスは、リレーショナル データベースの設計時に使われるプロセスとは異なります。 リレーショナル データベースの設計は、通常、冗長性を最小限に抑えるために最適化されたデータの正規化プロセスと、データベースの動作の実装方法を抽象化する宣言型クエリ機能があることを前提としています。
一対多のリレーションシップ
ビジネス ドメイン オブジェクトの間で一対多のリレーションシップが存在することはよくあります。たとえば、1 つの部署に多数の従業員が存在する場合などです。 特定のシナリオにおいて、長短それぞれあるものの、Table service に一対多のリレーションシップを実装する方法はいくつかあります。
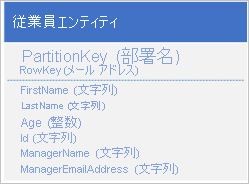
何万もの部署と従業員のエンティティがある大規模な多国籍企業または地域の企業の例を考えてみてください。各部署には多数の従業員が在籍しており、各従業員は 1 つの特定の部署に関連付けられています。 次のように、部署のエンティティと従業員のエンティティを分けて格納する方法もあります。

この例は、 PartitionKey 値に基づいて、各種類における暗黙の一対多のリレーションシップを示しています。 各部署に多数の従業員が存在する可能性があります。
この例は、部署エンティティと、同じパーティションに含まれる関連の従業員エンティティも示しています。 別のエンティティの種類として、別のパーティション、テーブル、またはストレージ アカウントを使うこともできます。
別の方法として、次の例に示すように、データを非正規化し、非正規化された部署データと共に従業員エンティティのみを格納する方法もあります。 このシナリオで部署のマネージャーの詳細を変更できるようにする必要がある場合は、この非正規化の方法は最適ではない可能性があります。部署内のすべての従業員を更新する必要が生じるためです。
詳細については、 このガイドで後述する 非正規化パターン を参照してください。
次の表に、上記で概要を示した一対多のリレーションシップを持つ従業員エンティティと部署エンティティを格納するアプローチについて、それぞれの長所と短所をまとめます。 また、各種操作をどの程度の頻度で実行する見込みかも検討する必要があります。コストの高い操作であっても、実行頻度が高くなければ設計に含めてもかまいません。
| アプローチ | 長所 | 短所 |
|---|---|---|
| エンティティの種類は別、パーティション、テーブルは同じ |
|
|
| エンティティの種類は別、パーティション、テーブル、ストレージ アカウントは別 |
|
|
| 単一のエンティティの種類への非正規化 |
|
|
*詳細については、「エンティティ グループ トランザクション」を参照してください
これらの選択肢のうちのどれを選ぶか、また、どの長所と短所の影響が最も大きいかは、アプリケーションのシナリオによって異なります。 たとえば、部署エンティティを変更する頻度、すべての従業員クエリに追加の部署情報が必要かどうか、パーティションまたはストレージ アカウントのスケーラビリティの制限までどのくらいあるのか、などがあります。
一対一のリレーションシップ
ドメイン モデルにはエンティティ間の一対一のリレーションシップが含まれることもあります。 Table service で一対一のリレーションシップを実装する必要がある場合は、2 つの関連するエンティティを取得する必要があるときにそれらをリンクする方法も選択する必要があります。 このリンクはキー値の規則に基づいて、各エンティティにおいて PartitionKey と RowKey 値形式で関連エンティティへのリンクを格納することで、明示的にも暗黙的にも成り得ます。 同じパーティションに関連エンティティを格納するかどうかの詳細については、 一対多のリレーションシップセクションを参照してください。
実装上の検討内容に応じて、Table service で一対一のリレーションシップを実装する必要が生じることもあります。
- ラージ エンティティを処理する (詳細については、「 ラージ エンティティ パターン」を参照してください)。
- アクセス制御を実装する (詳細については、共有アクセス署名でのアクセスの制御に関する記事を参照してください)。
クライアントでの結合
Table service でのリレーションシップのモデル化には何とおりかの方法があるものの、Table service を使う主な理由はスケーラビリティとパフォーマンスの 2 つであることを忘れないでください。 ソリューションのパフォーマンスとスケーラビリティを損なう多数のリレーションシップをモデル化しようとしていることに気が付いた場合は、そのすべてのデータ リレーションシップをテーブル設計に組み込む必要があるかどうかを確認する必要があります。 クライアント アプリケーションで必要な結合が実行されるようにすると、設計を簡素化し、ソリューションのスケーラビリティとパフォーマンスを向上させることができます。
たとえば、変更頻度の高くないデータが格納された小さなテーブルがある場合は、そのデータを取得した後でクライアント上にキャッシュできます。 そうすると、何度も同じデータを取得する必要がなくなります。 このガイドで見てきた例では、小規模な組織の部署のセットは小さく、変更頻度も低いことが多いので、データをクライアント アプリケーションでダウンロードしてからルックアップ データとしてキャッシュするのに適しています。
継承リレーションシップ
クライアント アプリケーションでビジネス エンティティを表す継承リレーションシップの一部を構成するクラスのセットを使用する場合は、それらのエンティティを Table service で簡単に保持できます。 たとえば、 人 が抽象クラスとなっているクライアント アプリケーションにはクラスセットが定義されている可能性があります。
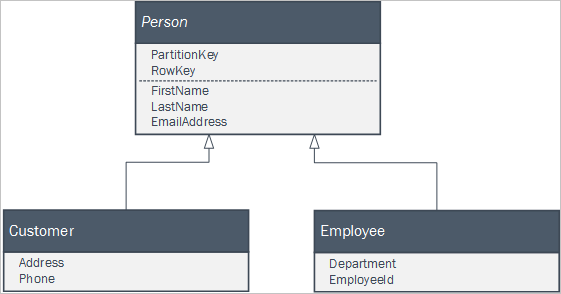
エンティティを次のように扱う 1 つの Person テーブルを使えば、2 つの具象クラスのインスタンスを Table service で維持できます。

クライアント コードの同じテーブル内の複数のエンティティ種類の詳細については、このガイドの後述のセクション 異種のエンティティ種類の使用 を参照してください。 クライアント コードでエンティティの種類を認識する方法の例が示されています。