Important
Azure Synapse Analytics データ エクスプローラー (プレビュー) は、2025 年 10 月 7 日に廃止されます。 この日以降、Synapse Data Explorer で実行されているワークロードは削除され、関連付けられているアプリケーション データは失われます。 Microsoft Fabric の Eventhouse に移行 することを強くお勧めします。
Microsoft Cloud Migration Factory (CMF) プログラムは、お客様が Fabric に移行できるように設計されています。 このプログラムは、顧客に無料でハンズオン キーボード リソースを提供します。 これらのリソースは、定義済みの合意されたスコープで、6 ~ 8 週間割り当てられます。 顧客の指名は、Microsoft アカウント チームから受け入れられるか、CMF チームに ヘルプの要求 を送信することによって直接受け入れられます。
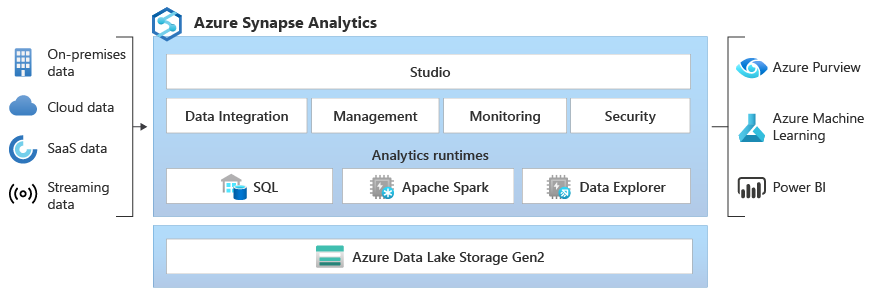
Azure Synapse Data Explorer では、ログとテレメトリ データから分析情報を引き出す対話型クエリ エクスペリエンスをお客様に提供します。 既存の SQL および Apache Spark 分析ランタイム エンジンを補完するために、Data Explorer 分析ランタイムは、強力なインデックス作成テクノロジを使用して効率的なログ分析用に最適化され、テレメトリ データでよく見られるフリー テキストと半構造化データのインデックスを自動的に作成します。
詳細については、次のビデオを参照してください。
Azure Synapse Data Explorer が一意になる理由
簡単なインジェスト - Data Explorer には、コードなし/低コード、高スループットのデータ インジェスト、リアルタイム ソースからのデータのキャッシュのための組み込みの統合が用意されています。 データは、Azure Event Hubs、Kafka、Azure Data Lake などのソース、Fluentd/Fluent Bit などのオープン ソース エージェント、さまざまなクラウドとオンプレミスのデータ ソースから取り込むことができます。
複雑なデータ モデリングなし - データ エクスプローラーを使用すると、複雑なデータ モデルを構築する必要はなく、複雑なスクリプトを使用する前にデータを変換する必要もありません。
インデックスのメンテナンスなし - クエリのパフォーマンスのためにデータを最適化するためのメンテナンス タスクは必要なく、インデックスのメンテナンスも必要ありません。 Data Explorer を使用すると、すべての生データをすぐに使用できるため、ストリーミングデータと永続データに対して高パフォーマンスおよび高コンカレンシークエリを実行できます。 これらのクエリを使用して、ほぼリアルタイムのダッシュボードとアラートを作成し、運用分析データを残りのデータ分析プラットフォームに接続できます。
データ分析の民主化 - Data Explorer は、Sql の表現力と能力を Excel のシンプルさを提供する直感的な Kusto クエリ言語 (KQL) を使用して、セルフサービスのビッグ データ分析を民主化します。 KQL は、データ エクスプローラーのクラス最高のテキスト インデックス作成テクノロジを利用して効率的なフリーテキスト検索と正規表現検索を行い、trace\text データと JSON 半構造化データ (配列や入れ子構造を含む) をクエリするための包括的な解析機能を活用することで、生のテレメトリと時系列データを探索するために高度に最適化されています。 KQL では、モデル スコアリングに対するエンジン内 Python 実行サポートを使用して、複数の時系列を作成、操作、分析するための高度な時系列サポートが提供されます。
ペタバイト規模の実証済みテクノロジ - Data Explorer は、コンピューティング リソースとストレージを備えた分散システムであり、個別にスケーリングでき、ギガバイトまたはペタバイト単位のデータに対する分析が可能です。
統合 - Azure Synapse Analytics は、データ エクスプローラー、Apache Spark、SQL エンジン間のデータ間の相互運用性を提供し、データ エンジニア、データ サイエンティスト、データ アナリストが、データ レイク内の同じデータに簡単かつ安全にアクセスして共同作業できるようにします。
Azure Synapse データ エクスプローラーを使用する場合
データ エクスプローラーを、ほぼリアルタイムのログ分析と IoT 分析ソリューションを構築するためのデータ プラットフォームとして使用します。
オンプレミス、クラウド、およびサードパーティのデータ ソース間でログとイベント データを統合して関連付けます。
AI 運用体験 (パターン認識、異常検出、予測など) を高速化します。
コストを節約し、生産性を向上させるために、インフラストラクチャ ベースのログ検索ソリューションを置き換えます。
IoT データ用の IoT 分析ソリューションを構築します。
内部および外部の顧客にサービスを提供するための分析 SaaS ソリューションを構築します。
データ エクスプローラー プールのアーキテクチャ
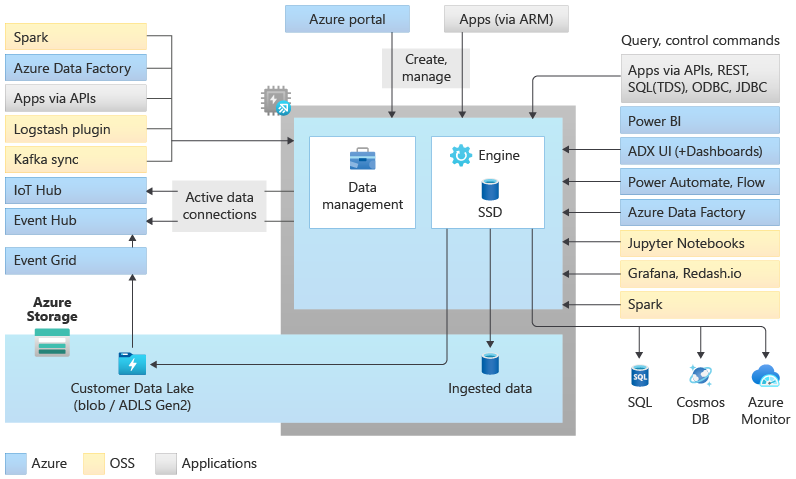
データ エクスプローラー プールでは、コンピューティング リソースとストレージ リソースを分離してスケールアウト アーキテクチャを実装します。 これにより、各リソースを個別にスケーリングし、たとえば、同じデータに対して複数の読み取り専用コンピューティングを実行できます。 データ エクスプローラー プールは、自動インデックス作成、圧縮、キャッシュ、分散クエリの提供を担当するエンジンを実行する一連のコンピューティング リソースで構成されます。 また、バックグラウンド システム ジョブを担当するデータ管理サービスを実行する 2 つ目のコンピューティング リソースセットと、管理およびキューに置かれたデータ インジェストがあります。 すべてのデータは、圧縮された列形式を使用してマネージド BLOB ストレージ アカウントに保持されます。
Data Explorer プールでは、コネクタ、SDK、REST API、およびその他の管理された機能を使用してデータを取り込むための豊富なエコシステムがサポートされています。 アドホック クエリ、レポート、ダッシュボード、アラート、REST API、SDK にデータを使用するさまざまな方法が用意されています。
Azure 上のログおよび時系列分析に最適な分析エンジンである Data Explore には、さまざまな独自の機能があります。
次のセクションでは、主な差別化要因について説明します。
フリー テキストおよび半構造化データ インデックス作成により、ほぼリアルタイムの高パフォーマンスおよび高同時クエリが可能
Data Explorer では、半構造化データ (JSON) と非構造化データ (フリー テキスト) のインデックスが作成されます。これにより、この種類のデータに対して実行中のクエリが適切に実行されます。 既定では、すべてのフィールドはデータ インジェスト中にインデックスが作成され、低レベルのエンコード ポリシーを使用して特定のフィールドのインデックスを微調整または無効にするオプションが使用されます。 インデックスのスコープは 1 つのデータ シャードです。
インデックスの実装は、次のようにフィールドの型によって異なります。
| フィールド タイプ | インデックス作成の実装 |
|---|---|
| ストリング | エンジンは、文字列列値の逆用語インデックスを作成します。 各文字列値が分析され、正規化された用語に分割され、レコード序数を含む論理位置の順序付きリストが用語ごとに記録されます。 結果として得られる並べ替えられた用語とその関連する位置のリストは、不変の B ツリーとして格納されます。 |
|
数値 DateTime TimeSpan |
エンジンは、単純な範囲ベースの前方インデックスを構築します。 インデックスには、各ブロック、ブロックのグループ、およびデータ シャード内の列全体の最小値/最大値が記録されます。 |
| 動的 | インジェスト プロセスでは、プロパティ名、値、配列要素など、動的な値内のすべての "アトミック" 要素が列挙され、インデックス ビルダーに転送されます。 動的フィールドには、文字列フィールドと同じ逆用語インデックスがあります。 |
これらの効率的なインデックス作成機能を使用すると、Data Explore を使用して、高パフォーマンスおよび高コンカレンシー クエリでほぼリアルタイムでデータを使用できるようになります。 システムは、パフォーマンスをさらに向上させるためにデータ シャードを自動的に最適化します。
Kusto 照会言語
KQL には、Azure Monitor Log Analytics と Application Insights、Microsoft Sentinel、Azure Data Explorer、およびその他の Microsoft オファリングを迅速に導入する大規模で成長しているコミュニティがあります。 この言語は読みやすい構文で適切に設計されており、単純なワンライナーから複雑なデータ処理クエリへのスムーズな移行を提供します。 これにより、Data Explorer は、豊富な Intellisense サポートと、テレメトリ データを迅速に探索するために SQL で使用できない集計、時系列、およびユーザー分析用の豊富な言語コンストラクトと組み込み機能を提供できます。