チュートリアル:コードなしで機械学習モデルをトレーニングする
自動機械学習を使用してトレーニングする新しい機械学習モデルによって、Spark テーブルのデータをエンリッチすることができます。 Azure Synapse Analytics では、機械学習モデルを構築するためのトレーニング データセットとして使用する Spark テーブルをワークスペースで選択できます。この作業にコーディングは必要ありません。
このチュートリアルでは、Synapse Studio のコード不要のエクスペリエンスを使用して機械学習モデルをトレーニングする方法について説明します。 Synapse Studio は Azure Synapse Analytics の機能です。
手動でコーディングするのではなく、Azure Machine Learning の自動機械学習を使用します。 トレーニングするモデルの種類は、解決しようとしている問題によって異なります。 このチュートリアルでは、回帰モデルを使用して、ニューヨーク市のタクシーのデータセットからタクシー料金を予測します。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
警告
- 2023 年 9 月 29 日より、Azure Synapse では Spark 2.4 ランタイムの公式サポートが中止となります。 2023 年 9 月 29 日の後は、Spark 2.4 に関連するサポート チケットに対応しません。 Spark 2.4 のバグやセキュリティ修正のためのリリース パイプラインはありません。 サポート終了後の Spark 2.4 の利用は自己責任で行われます。 セキュリティと機能に関する潜在的な懸念があるため、使用停止を強くお勧めしています。
- Apache Spark 2.4 の非推奨プロセスの一環として、Azure Synapse Analytics の AutoML も非推奨になることをお知らせします。 これには、ロー コード インターフェイスととコードを介して AutoML 試用版を作成するために使用される API の両方が含まれます。
- AutoML 機能は Spark 2.4 ランタイムを通じて排他的に使用できました。
- AutoML 機能を引き続き利用したいお客様には、Azure Data Lake Storage Gen2 (ADLSg2) アカウントにデータを保存することをお勧めします。 そこから、Azure Machine Learning (AzureML) を介して AutoML エクスペリエンスにシームレスにアクセスできます。 この回避策の詳細については、こちらを参照してください。
前提条件
- Azure Synapse Analytics ワークスペース。 Azure Data Lake Storage Gen2 ストレージ アカウントが既定のストレージとして構成されていることを確認します。 必ず、Data Lake Storage Gen2 ファイル システムの Storage Blob データ共同作成者として作業してください。
- Azure Synapse Analytics ワークスペースの Apache Spark プール (バージョン 2.4)。 詳細については、クイックスタート: Synapse Studio を使用したサーバーレス Apache Spark プールの作成に関するページを参照してください。
- Azure Synapse Analytics ワークスペースの Azure Machine Learning のリンクされたサービス。 詳細については、「クイック スタート:Azure Synapse Analytics での Azure Machine Learning のリンクされたサービスの新規作成。
Azure portal にサインインする
Azure portal にサインインします。
トレーニング データセットの Spark テーブルを作成する
このチュートリアルには Spark テーブルが必要です。 次のノートブックで作成します。
ノートブック Create-Spark-Table-NYCTaxi- Data.ipynb をダウンロードします。
ノートブックを Synapse Studio にインポートします。
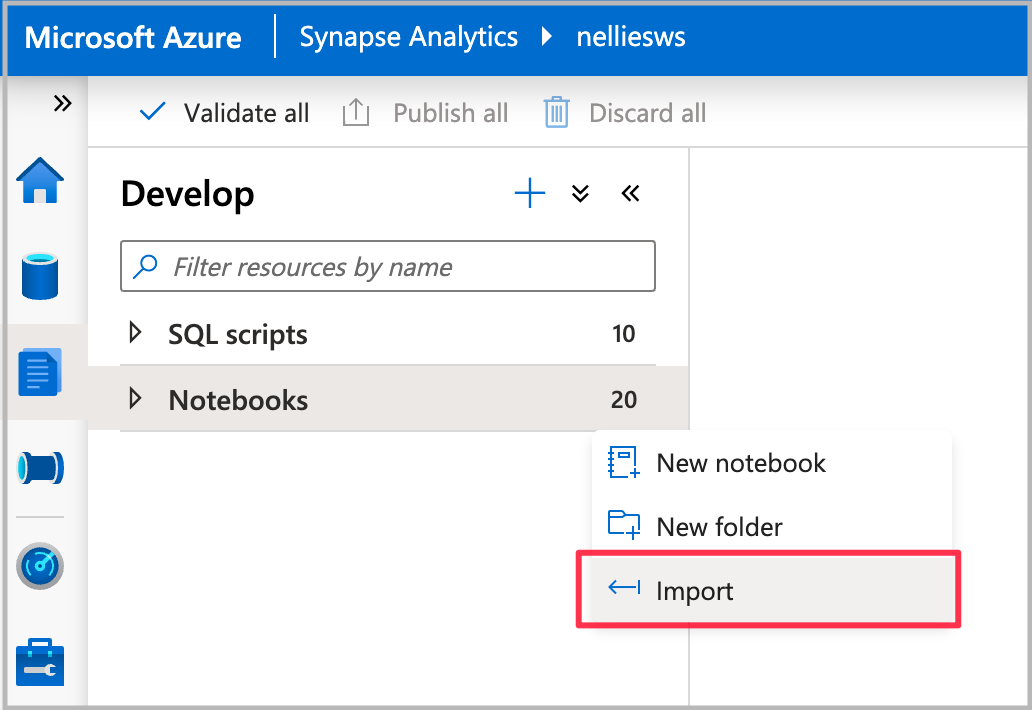
使用する Spark プールを選択し、 [すべて実行] を選択します。 この手順により、開いているデータセットからニューヨークのタクシー データが取得され、既定の Spark データベースに保存されます。

ノートブックの実行が完了すると、既定の Spark データベースの下に新しい Spark テーブルが表示されます。 [データ] から nyc_taxi という名前のテーブルを探します。
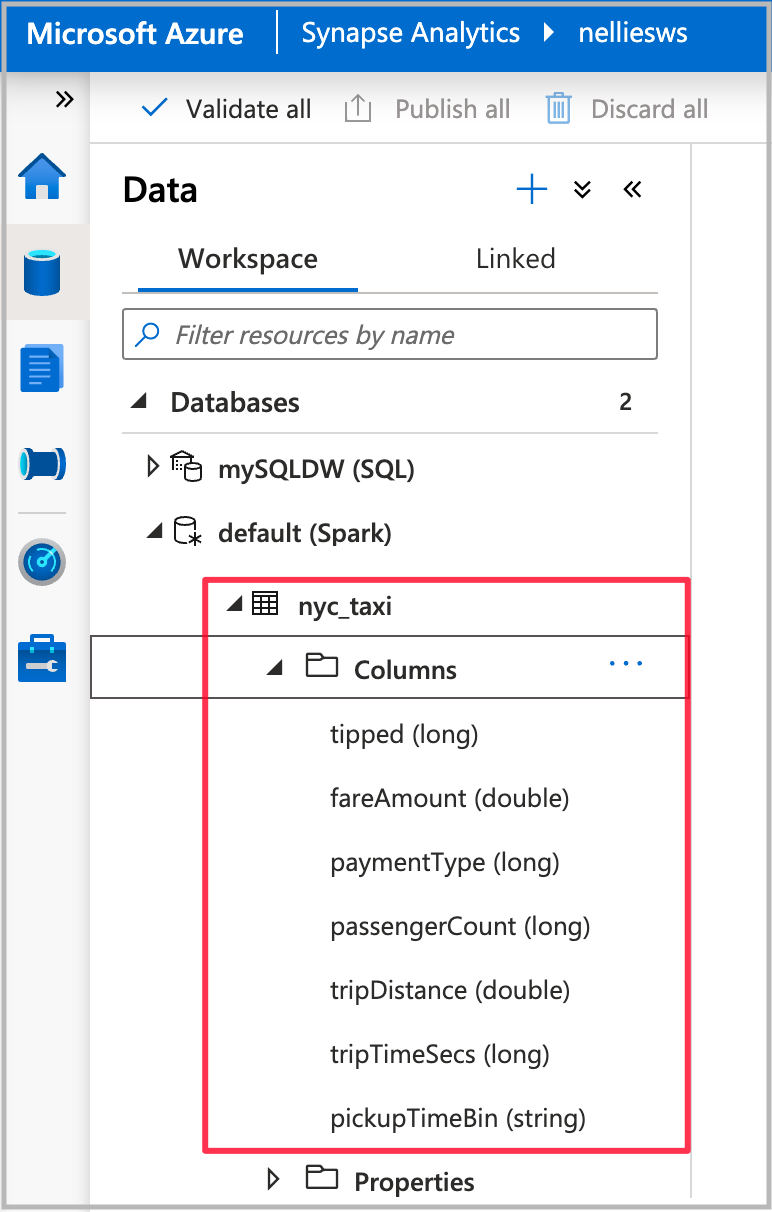
自動機械学習ウィザードを開く
ウィザードを開くには、前の手順で作成した Spark テーブルを右クリックします。 [機械学習]>[新しいモデルのトレーニング] の順に選択します。
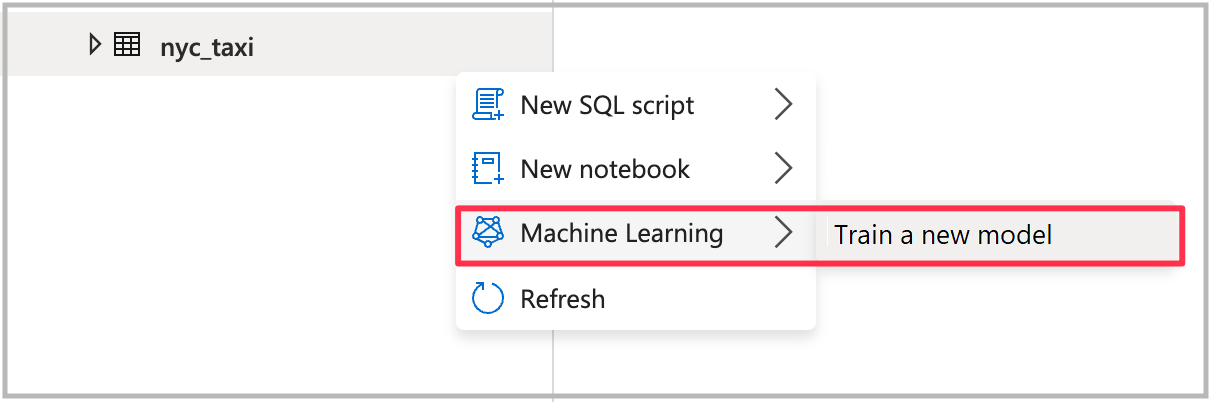
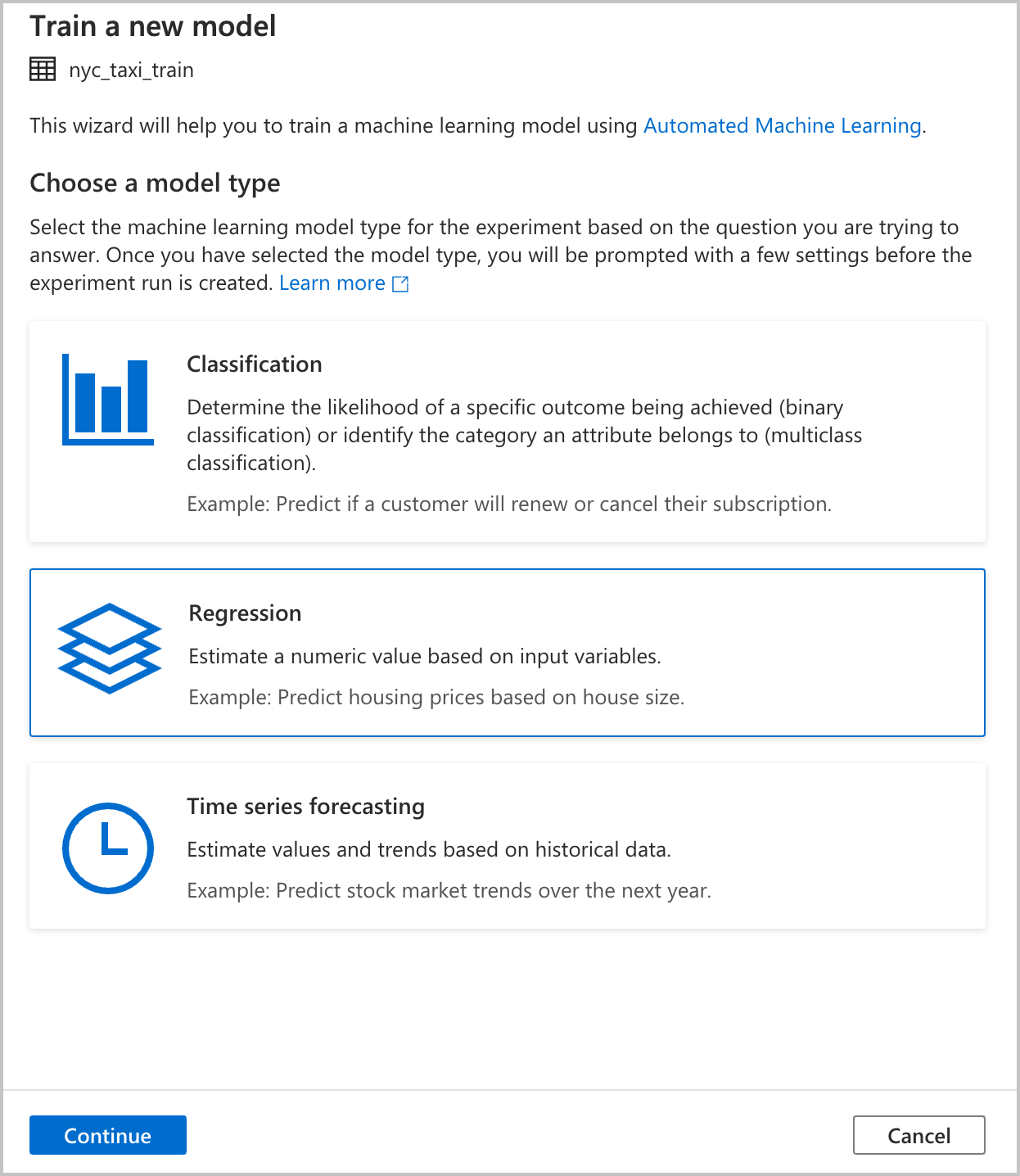
モデルの種類の選択
答えようとしている質問に基づいて、実験の機械学習モデルの種類を選択します。 予測しようとしている値は数値 (タクシー料金) なので、ここでは [回帰] を選択します。 その後 [続行] を選択します。
実験を構成する
Azure Machine Learning での自動機械学習の実験実行を作成するための構成の詳細を指定します。 この実行により、複数のモデルがトレーニングされます。 実行が成功すると、最適なモデルが Azure Machine Learning モデル レジストリに登録されます。
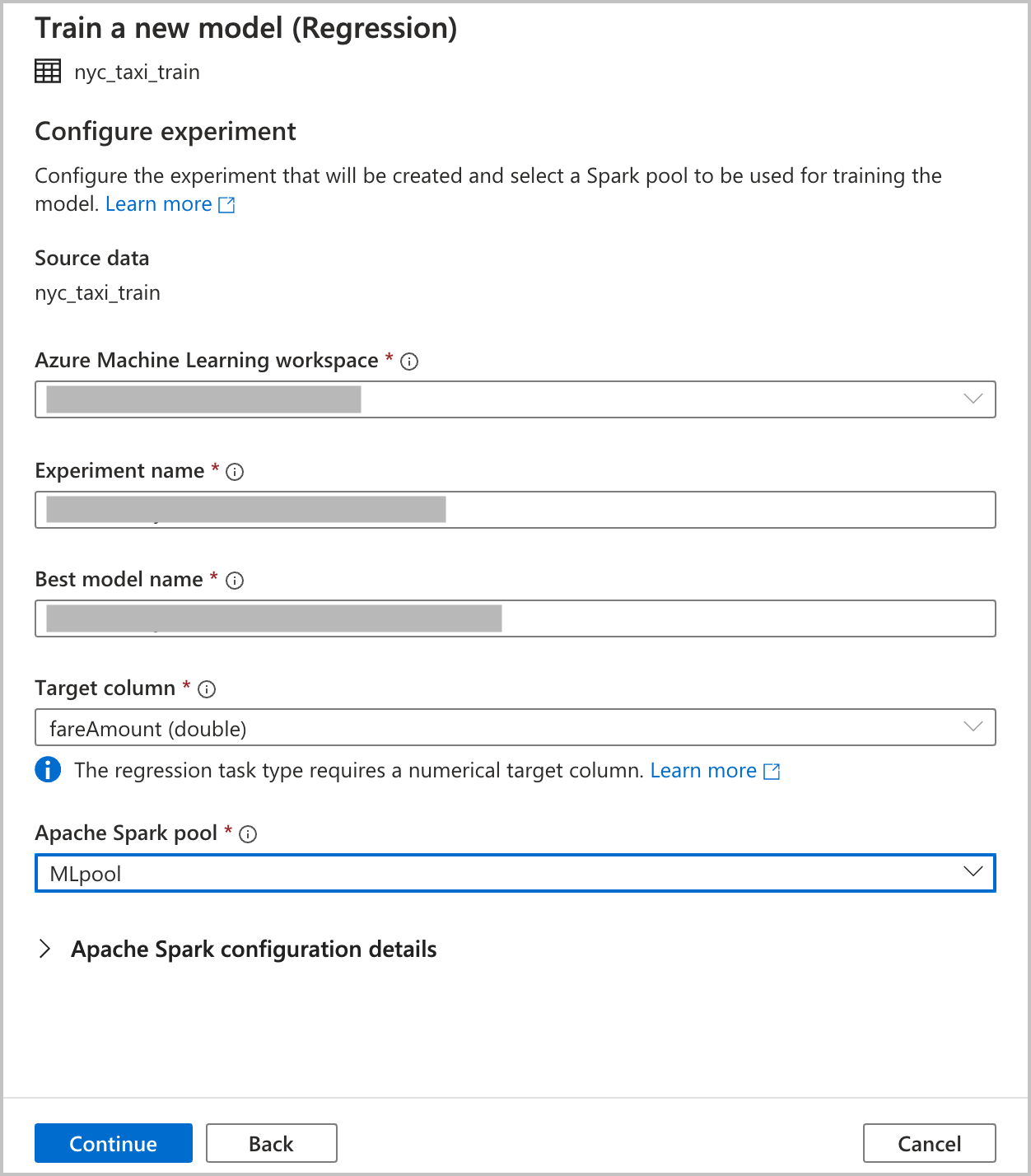
Azure Machine Learning ワークスペース: 自動機械学習の実験の実行を作成するには、Azure Machine Learning ワークスペースが必要です。 また、リンクされたサービスを使用して、Azure Synapse Analytics ワークスペースを Azure Machine Learning ワークスペースにリンクする必要があります。 すべての前提条件を満たしたら、この自動実行に使用する Azure Machine Learning ワークスペースを指定できます。
実験名: 実験名を指定します。 自動機械学習の実行を送信するときは、実験名を指定します。 実行に関する情報は、Azure Machine Learning ワークスペースでその実験に保存されます。 このエクスペリエンスでは、新しい実験が既定で作成され、提案された名前が生成されますが、既存の実験の名前を指定することもできます。
Best model name(最適なモデル名) : 自動実行での最適なモデルの名前を指定します。 最適なモデルにはこの名前が付けられ、この実行の後に、Azure Machine Learning モデル レジストリに自動的に保存されます。 自動機械学習の実行によって、多数の機械学習モデルが作成されます。 後の手順で選択する主要メトリックに基づいて、それらのモデルを比較し、最適なモデルを選択できます。
ターゲット列: モデルをトレーニングする際の予測対象です。 予測するデータを含むデータセットの列を選択します。 このチュートリアルでは、ターゲット列として数値列の
fareAmountを選択します。Spark プール: 自動実験実行に使用する Spark プールを指定します。 指定したプールに対して計算が実行されます。
Spark configuration details(Spark 構成の詳細) : Spark プールに加えて、セッション構成の詳細を指定するオプションもあります。
[続行] をクリックします。
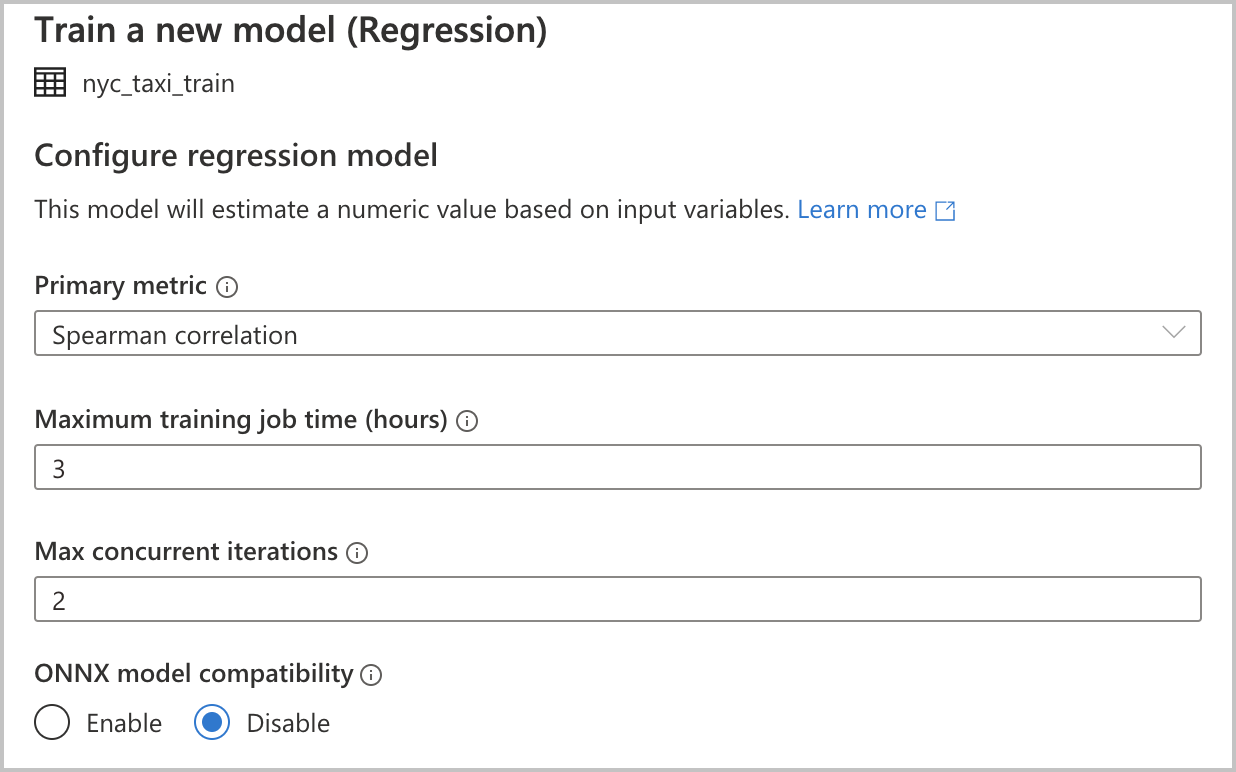
モデルを構成する
前のセクションで、モデルの種類として [回帰] を選択したので、次の構成を使用できます (これらは [分類] のモデルの種類でも使用できます)。
Primary metric(主要メトリック) : モデルのパフォーマンスを測定するメトリックを入力します。 このメトリックを使用して、自動実行で作成されたさまざまなモデルを比較し、パフォーマンスが最も高いモデルを特定します。
トレーニング ジョブ時間 (時間単位) :実験でモデルを実行してトレーニングするときの最大時間 (時間単位) を指定します。 1 未満の値 (0.5 など) を指定することもできます。
コンカレント イテレーションの最大数:並列で実行するイテレーションの最大数を選択します。
ONNX model compatibility(ONNX モデルの互換性) : このオプションを有効にすると、自動機械学習によってトレーニングされたモデルが ONNX 形式に変換されます。 これは、モデルを Azure Synapse Analytics SQL プールでのスコアリングに使用する場合に特に関連します。
これらの設定にはすべて、カスタマイズできる既定値があります。
実行を開始する
必須の構成がすべて完了したら、自動実行を開始できます。 [Create run](実行の作成) を選択して実行を直接作成できます。これにより、コードを使用せずに実行が開始されます。 代わりにコードを使用する場合は、 [Open in notebook](ノートブックで開く) を選択できます。これにより、実行を作成するコードを含むノートブックが開くので、コードを表示して、自分で実行を開始できます。

Note
前のセクションで、モデルの種類として [時系列の予測] を選択した場合は、追加の構成を行う必要があります。 また、予測では、ONNX モデルの互換性はサポートされていません。
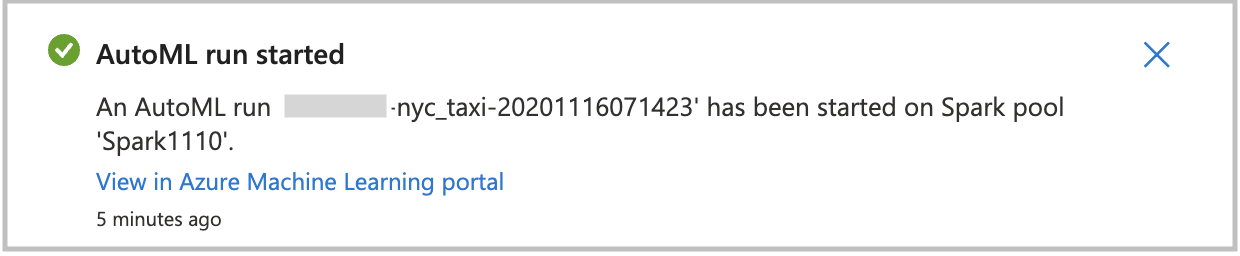
実行を直接作成する
自動機械学習の実行を直接開始するには、 [Create Run](実行の作成) を選択します。 実行が開始されることを示す通知が表示されます。 その後、成功を示す別の通知が表示されます。 Azure Machine Learning で通知内のリンクを選択して状態を確認することもできます。
ノートブックを使用して実行を作成する
ノートブックを生成するには、 [Open In Notebook](ノートブックで開く) を選択します。 これにより、設定を追加したり、自動機械学習の実行のコードを変更することができます。 コードを実行する準備ができたら、 [すべて実行] を選択します。

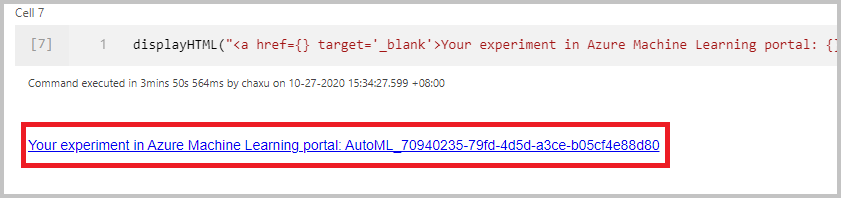
実行を監視する
実行が正常に送信されたら、ノートブックの出力に、Azure Machine Learning ワークスペースでの実験実行へのリンクが表示されます。 リンクを選択すると、Azure Machine Learning で自動実行を監視できます。