Azure Synapse Analytics のインテリジェント キャッシュ
インテリジェント キャッシュは、バックグラウンドでシームレスに動作し、データをキャッシュして、ADLS Gen2 データ レイクから読み取るときの Spark の実行を高速化します。 また、基盤のファイルに対する変更を自動的に検出し、キャッシュ内のファイルを自動的に更新して、最新のデータを提供します。キャッシュ サイズが上限に達すると、キャッシュ内の最も読み取られていないデータが自動的に解放されて、より新しいデータのための領域が確保されます。 この機能により、Parquet ファイルに使用できるキャッシュに格納されているファイルの後続の読み取りのパフォーマンスが最大 65%、CSV ファイルでのパフォーマンスが最大 50% 向上して、総保有コストが削減されます。
データ レイクからファイルまたはテーブルに対してクエリを実行すると、Synapse の Apache Spark エンジンからリモート ADLS Gen2 ストレージが呼び出されて基盤のファイルが読み取られます。 Spark エンジンは、同じデータを読み取るクエリ要求が実行されるたびにリモート ADLS Gen2 ストレージを呼び出す必要があります。 この冗長なプロセスにより、合計処理時間に待機時間が追加されます。 Spark が提供するキャッシュ機能では、待機時間を最小化して全体的なパフォーマンスを向上させるために、手動でキャッシュの設定と解放を行う必要があります。 ただし、基盤のデータが変更された場合に、古いデータが残ってしまう可能性があります。
Synapse インテリジェント キャッシュでは、各 Spark ノードに割り当てられたキャッシュ ストレージ領域内で各読み取りが自動的にキャッシュされることで、このプロセスが簡素化されます。 ファイルに対する要求が行われるたびに、ファイルがキャッシュに存在するかどうかが検査され、リモート ストレージからのタグが比較されてファイルが古くないかどうかが判別されます。 ファイルが存在しない場合またはファイルが古い場合は、Spark によってファイルが読み取られてキャッシュに格納されます。 キャッシュがいっぱいになると、より新しいファイルを格納できるように、最終アクセス時刻の最も古いファイルがキャッシュから削除されます。
Synapse キャッシュはノードごとに 1 つ用意されます。 中規模のノードを使用している場合に、1 つの中規模ノードで 2 つの小規模な Executor を実行すると、その 2 つの Executor は同じキャッシュを共有します。
キャッシュを有効または無効にする
キャッシュ サイズは、各 Apache Spark プールで使用可能な合計ディスク サイズの割合に基づいて調整できます。 キャッシュは既定で無効に設定されますが、スライダー バーを 0 (無効) からキャッシュ サイズの目的の割合に動かすだけで簡単に有効にすることができます。 使用可能なディスク領域の少なくとも 20% が、データ シャッフル用に予約されます。 シャッフルが大量に発生するワークロードでは、キャッシュ サイズを最小限に抑えるか、キャッシュを無効にすることができます。 50% のキャッシュ サイズから始め、必要に応じて調整することをお勧めします。 ワークロードが、シャッフルや RDD キャッシュのためにローカル SSD に大量のディスク領域を必要とする場合は、ストレージ不足によるエラーの発生を抑えるために、キャッシュ サイズを縮小することを検討してください。 使用可能なストレージの実際のサイズと各ノードのキャッシュ サイズは、ノード ファミリとノード サイズによって異なります。
新しい Spark プールに対してキャッシュを有効にする
新しい Spark プールを作成するときに、[additional settings](追加の設定) タブにある [Intelligent Cache](インテリジェント キャッシュ) スライダー を目的のサイズまで動かして機能を有効にすることができます。

既存の Spark プールに対してキャッシュを有効/無効にする
既存の Spark プールの場合は、選択した Apache Spark プールの [Scale settings](スケールの設定) で、スライダーを 0 より大きい値に動かして有効にするか、スライダーを 0 に動かして無効にします。
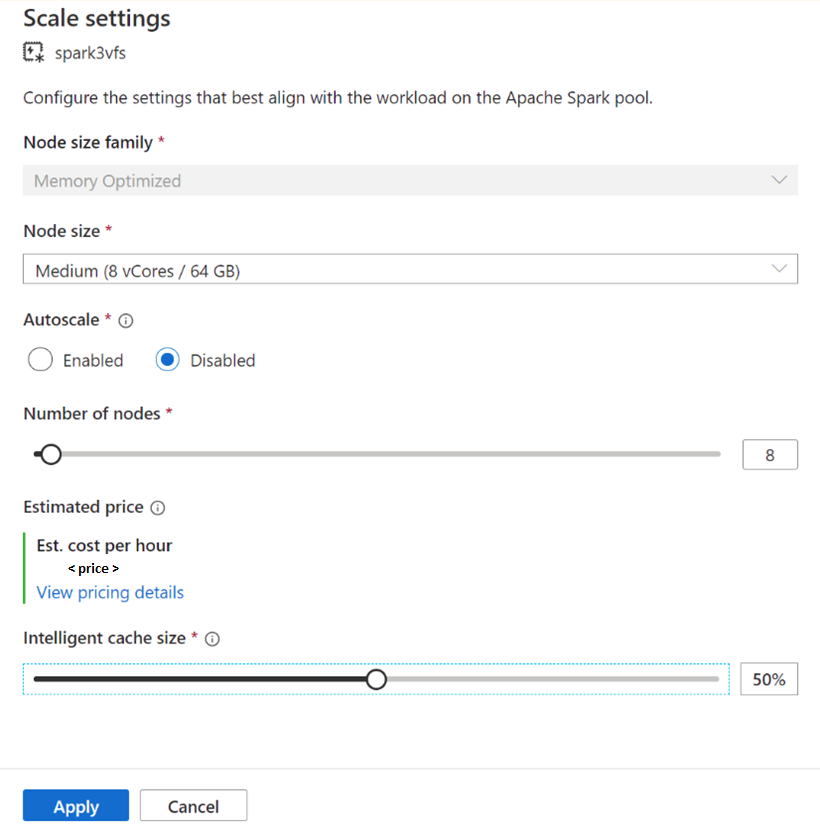
既存の Spark プールのキャッシュ サイズを変更する
プールにアクティブなセッションがある場合にプールのインテリジェント キャッシュ サイズを変更するには、強制的に再起動する必要があります。 Spark プールにアクティブなセッションがある場合は、[Force new settings](新しい設定を強制) が表示されます。 チェック ボックスをオンにして [適用] を選択すると、セッションが自動的に再起動されます。

セッション内でキャッシュを有効/無効にする
セッション内でインテリジェント キャッシュを簡単に無効にするには、ノートブックで次のコードを実行します。
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
有効にするには以下を実行します。
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
インテリジェント キャッシュを使用すべき場合とそうでない場合
この機能は、次の場合にメリットをもたらします。
ワークロードで同じファイルを複数回読み取る必要があり、かつファイルがキャッシュに収まるサイズである。
ワークロードでデルタ テーブル、Parquet ファイル形式、CSV ファイルが使用される。
Azure Synapse で Apache Spark 3 以降を使用している。
次の場合は、この機能を使うメリットはありません。
ファイルの先頭が削除される可能性があり、後続のクエリでリモート ストレージからデータを再フェッチする必要があるために、キャッシュ サイズを超えるファイルを読み取っている。 この場合、インテリジェント キャッシュを使うメリットはなく、キャッシュ サイズやノード サイズを増やす必要があります。
ワークロードで大量のシャッフルが必要である。この場合は、ストレージ領域の不足によってジョブが失敗しないように、インテリジェント キャッシュを無効にして使用可能な領域を解放します。
Spark 3.1 プールを使用していて、プールを最新バージョンの Spark にアップグレードする必要がある。
詳細情報
Apache Spark の詳細については、次の記事を参照してください。
- Apache Spark とは
- Apache Spark の主要概念
- Azure Synapse Runtime for Apache Spark 3.2
- Apache Spark プールのサイズと構成
Spark セッション設定の構成については、以下を参照してください。
次のステップ
Apache Spark プールは、データの読み込み、モデル化、処理、および配布が可能なオープンソースのビッグデータのコンピューティング機能を提供し、より迅速な分析洞察を実現します。 Spark ワークロードを実行するためにこれを作成する方法の詳細については、次のチュートリアルを参照してください。