Azure Synapse Analytics には、データの取り込み、変換、モデル化、分析、配布に役立つさまざまな分析エンジンが用意されています。 Apache Spark プールには、オープン ソースのビッグ データ コンピューティング機能が用意されています。 Synapse ワークスペースに Apache Spark プールを作成した後は、分析分析を高速化するためにデータを読み込み、モデル化、処理、および分散できます。
このクイックスタートでは、Azure portal を使用して Synapse ワークスペースに Apache Spark プールを作成する方法について説明します。
Von Bedeutung
Spark インスタンスの課金は、使用しているかどうかに関係なく、分単位で日割り計算されます。 Spark インスタンスの使用が完了したら、必ずシャットダウンするか、短いタイムアウトを設定してください。 詳細については、この記事の「 リソースのクリーンアップ 」セクションを参照してください。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
[前提条件]
- Azure サブスクリプションが必要です。 必要であれば、無料の Azure アカウントを作成してください
- Synapse ワークスペースを使用します。
Azure portal にサインインする
Azure ポータル にサインインする
Synapse ワークスペースに移動します
Synapse ワークスペースに移動します。ここでは、検索バーにサービス名 (またはリソース名を直接) 入力して、Apache Spark プールを作成します。
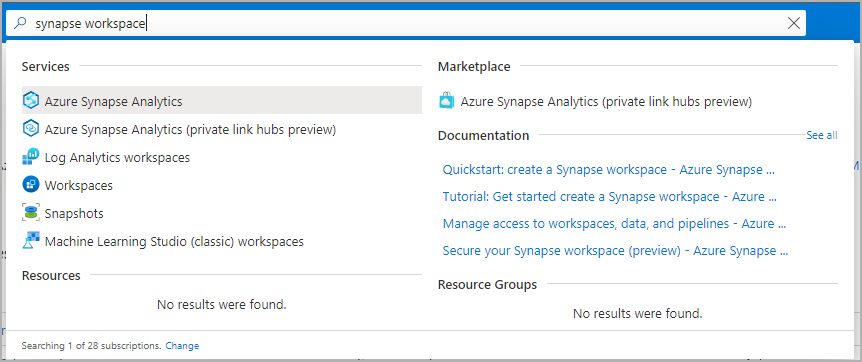
ワークスペースの一覧から、開きたいワークスペースの名前(または名前の一部)を入力してください。 この例では、contosoanalytics という名前のワークスペースを使用します。
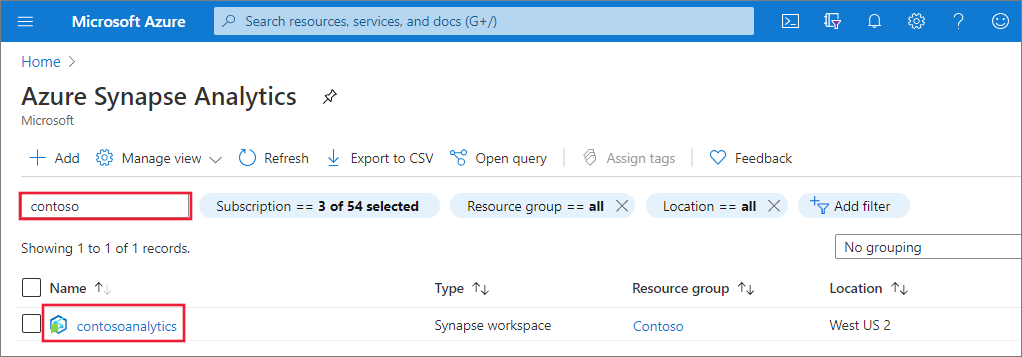


新しい Apache Spark プールを作成する
Apache Spark プールを作成する Synapse ワークスペースで、[ 新しい Apache Spark プール] を選択します。
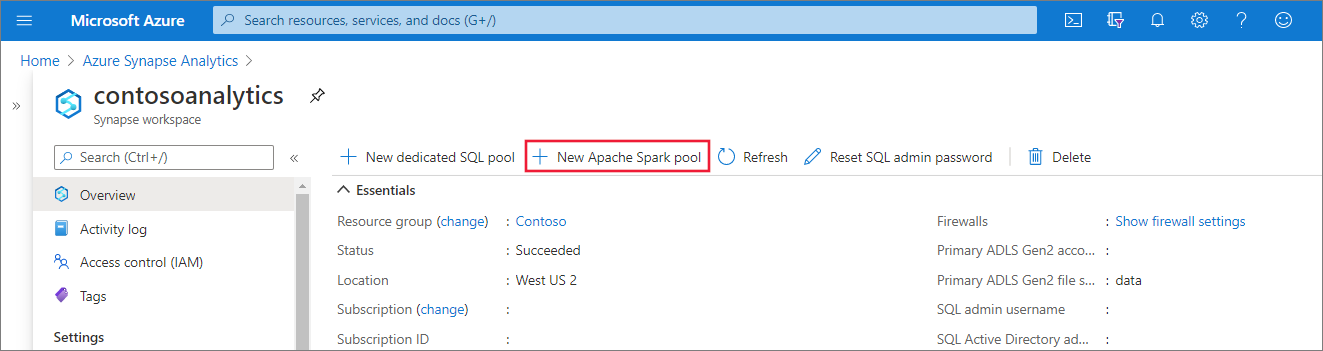
次の詳細を基本情報タブに入力してください。
設定 推奨値 説明 [Apache Spark pool name](Apache Spark プール名) 有効なプール名 ( contososparkなど)これは、Apache Spark プールの名前です。 ノード サイズ Small (4 vCPU / 32 GB) (S (4 vCPU/32 GB)) このクイックスタートの費用を抑えるために、サイズを最小に設定してください。 自動スケーリング 障害者 このクイック スタートでは自動スケールは必要ありません [Number of nodes](ノードの数) 5 小さいサイズを使用して、このクイック スタートのコストを制限する ![Apache Spark プールの作成フローの Azure portal の [基本] タブのスクリーンショット。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-02.png)
Von Bedeutung
Apache Spark プールで使用できる名前には特定の制限があります。 名前は、文字または数字のみを含み、15 文字以下である必要があります。さらに、文字で始まり、予約語を含まず、ワークスペース内で一意である必要があります。
[ 次へ: 追加の設定] を選択し、既定の設定を確認します。 既定の設定は変更しないでください。
![[追加設定] タブが選択されている [Create Apache Spark pool]\(Apache Spark プールの作成\) ページを示す Azure portal のスクリーンショット。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-03.png)
[次へ: タグ] を選択します。 Azure タグの使用を検討します。 たとえば、リソースを作成したユーザーを識別する "Owner" または "CreatedBy" タグ、このリソースが運用や開発などの環境にあるかどうかを識別する "Environment" タグなどです。詳細については、「Azure リソースの名前付けおよびタグ付けの戦略を作成する」を参照してください。
![Apache Spark プール作成フローの Azure portal のスクリーンショット - [追加設定] タブ。](media/quickstart-create-apache-spark-pool/create-spark-pool-03-tags.png)
[Review + create](レビュー + 作成) を選択します。
前に入力した内容に基づいて詳細が正しく表示されていることを確認し、[ 作成] を選択します。
![Apache Spark プール作成フローの Azure portal のスクリーンショット - [設定の確認] タブ。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-05.png)
この時点で、リソースのプロビジョニング フローが開始され、完了したことを示します。
![Azure portal のスクリーンショット。[概要] ページに [デプロイが完了しました] というメッセージが表示されています。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-06.png)
プロビジョニングが完了すると、ワークスペースに戻ると、新しく作成された Apache Spark プールの新しいエントリが表示されます。
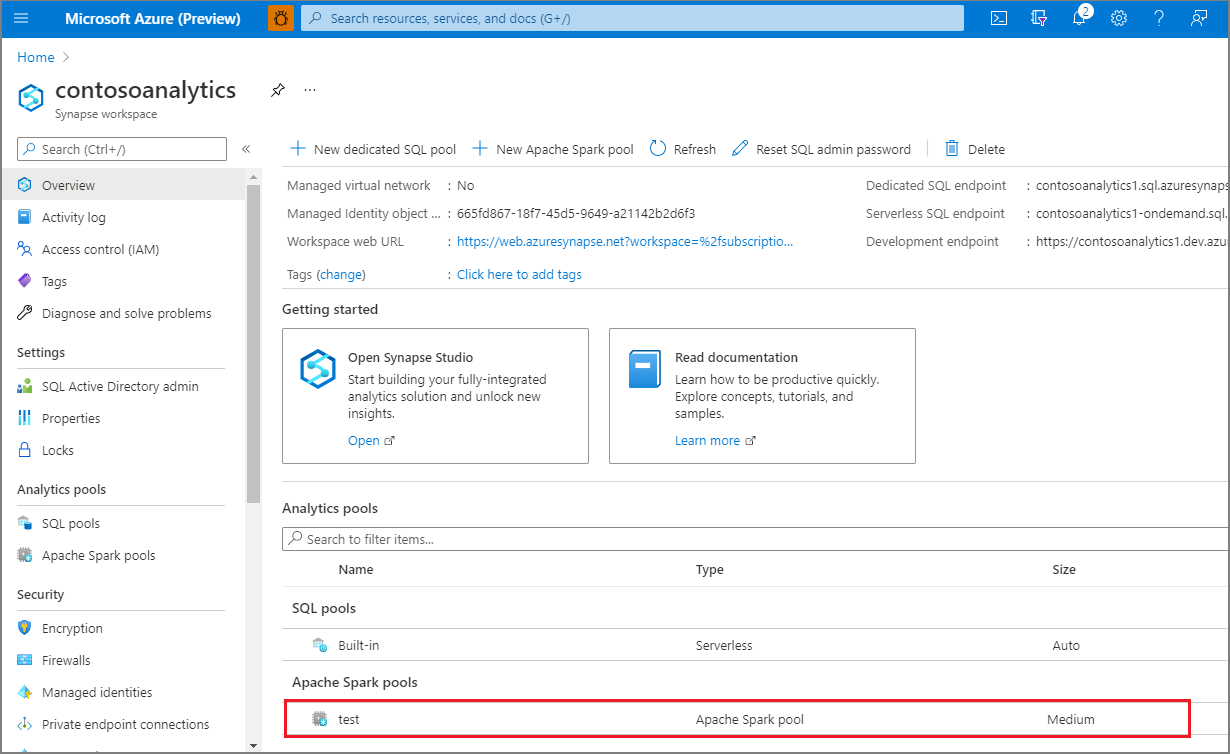
この時点で、リソースは実行されません。Spark の料金はかかりません。作成する Spark インスタンスに関するメタデータを作成しました。

![Apache Spark プールの作成フローの Azure portal の [基本] タブのスクリーンショット。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-02.png#lightbox)
![[追加設定] タブが選択されている [Create Apache Spark pool]\(Apache Spark プールの作成\) ページを示す Azure portal のスクリーンショット。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-03.png#lightbox)
![Apache Spark プール作成フローの Azure portal のスクリーンショット - [追加設定] タブ。](media/quickstart-create-apache-spark-pool/create-spark-pool-03-tags.png#lightbox)
![Apache Spark プール作成フローの Azure portal のスクリーンショット - [設定の確認] タブ。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-05.png#lightbox)
![Azure portal のスクリーンショット。[概要] ページに [デプロイが完了しました] というメッセージが表示されています。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-06.png#lightbox)

リソースをクリーンアップする
次の手順では、ワークスペースから Apache Spark プールを削除します。
Warnung
Apache Spark プールを削除すると、ワークスペースから分析エンジンが削除されます。 プールに接続することはできなくなり、この Apache Spark プールを使用するすべてのクエリ、パイプライン、ノートブックは機能しなくなります。
Apache Spark プールを削除する場合は、次の手順を行います。
- ワークスペースの [Apache Spark プール] ウィンドウに移動します。
- 削除する Apache Spark プール (この場合は contosospark) を選択します。
-
を選択して、を削除します。
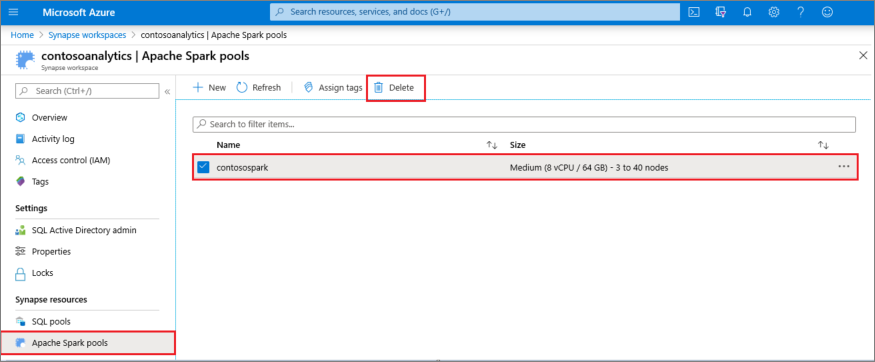
- 削除を確認し、[ 削除 ] ボタンを選択します。
![選択した Apache Spark プールを削除するための [確認] ダイアログの Azure portal のスクリーンショット。](media/quickstart-create-apache-spark-pool/create-spark-pool-portal-10.png)
- プロセスが正常に完了すると、Apache Spark プールはワークスペース リソースの一覧に表示されなくなります。
